

DADA: 一种具有自适应瓶颈和双对抗解码器的通用时间序列异常检测器《Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders》(时间序列、异常检测、预训练、信息瓶颈、双解码器梯度反转层对抗训练)
今天2025年3月11日,欠了一堆博客没写,实验跑了一部分,实验结果分析还没写完,什么都不管了,打算先看看论文,好久没好好看论文了,罪过罪过,ICLR 2025的论文都出来了,我的论文还遥遥无期,加油吧。
GitHub:https://github.com/decisionintelligence/DADA
ICLR 2025 Poster的论文。
虽然会议还没开,先凑着热乎看一看。
还是我看英文原文,然后再整段翻译(翻译器翻的,可能会调整一下,但不多),然后写点个人的理解和疑问。
摘要
(断断续续的看,现在2025年3月17日,今天必须给我看完.)
时间序列异常检测在广泛的应用中发挥着重要作用。现有的方法需要为每个数据集训练一个特定的模型,在不同的目标数据集上表现出有限的泛化能力,从而阻碍了在训练数据稀缺的各种情况下的异常检测性能。针对这一问题,我们提出构建一个通用的时间序列异常检测模型,该模型在广泛的多领域数据集上进行预训练,随后可应用于多种下游场景。不同领域的时间序列数据差异巨大,这给构建这样一个通用模型带来了两个主要挑战:(1) 在一个统一的模型中满足针对不同数据集的适当信息瓶颈的不同要求;(2) 能够区分多种正常和异常模式,这两者对于在各种目标场景中进行有效的异常检测至关重要。为了应对这两个挑战,我们提出了一种具有自适应瓶颈和双对抗解码器(DADA)的通用时间序列异常检测器,它可以根据不同的数据灵活选择瓶颈,并明确加强对正常和异常序列的清晰区分。我们在不同领域的九个目标数据集上进行了广泛的实验。在对多领域数据进行预训练后,DADA 作为这些数据集的零点异常检测器,与那些为每个特定数据集量身定制的模型相比,仍然取得了具有竞争力甚至更优越的结果。代码可在 https://github.com/decisionintelligence/DADA 上获取。
1 引言
随着技术的不断进步和各种传感器的广泛应用,时间序列数据在现实世界的许多场景中无处不在(Anandakrishnan 等人,2017 年;Cook 等人,2020 年;Kieu 等人,2022 年;Tian 等人,2024 年;Pan 等人,2023 年)。有效检测时间序列数据中的异常有助于及时发现潜在问题,并采取必要措施确保系统正常运行,从而避免可能的经济损失和安全威胁(Yang 等,2021 年)。例如,在网络安全领域,及时发现异常网络流量可以防止服务中断(Dong 等,2023a;Wang & Zhu,2022);在医疗保健领域,发现异常对预防疾病至关重要(Wang 等,2023b;Salem 等,2021)。
基于深度学习的异常检测方法(Xu 等,2022;Su 等,2019;Donghao & Wang Xue,2024)因其强大的数据表示能力,最近取得了显著的成功。然而,现有的时间序列数据异常检测方法通常需要针对不同的数据集构建和训练特定的模型(Cook 等,2020;Wang 等,2023a;Campos 等,2022;Yang 等,2023)。虽然这些方法在每个特定数据集上都表现出良好的性能,但它们在不同目标场景中的泛化能力却很有限(Zhang 等人,2023 年)(问题提出)。在某些场景中,没有足够的数据或资源进行特定的模型训练,例如,数据收集因数据稀缺、时间和人力成本或用户隐私问题而受阻。因此,现有方法在实践中的可行性可能会受到很大限制。针对这一问题,我们提出了构建通用时间序列异常检测(GTSAD)模型的建议。如图 1 所示,通过在多来源、多领域的大型时间序列数据上对模型进行预训练,可以鼓励模型从更丰富的时间信息中学习异常检测能力,从而有可能减轻特定领域模式的过度拟合,学习到更具普适性的模式和模型。这样,该模型就能有效地应用于各种下游场景。然而,构建通用异常检测模型仍面临以下两大挑战。
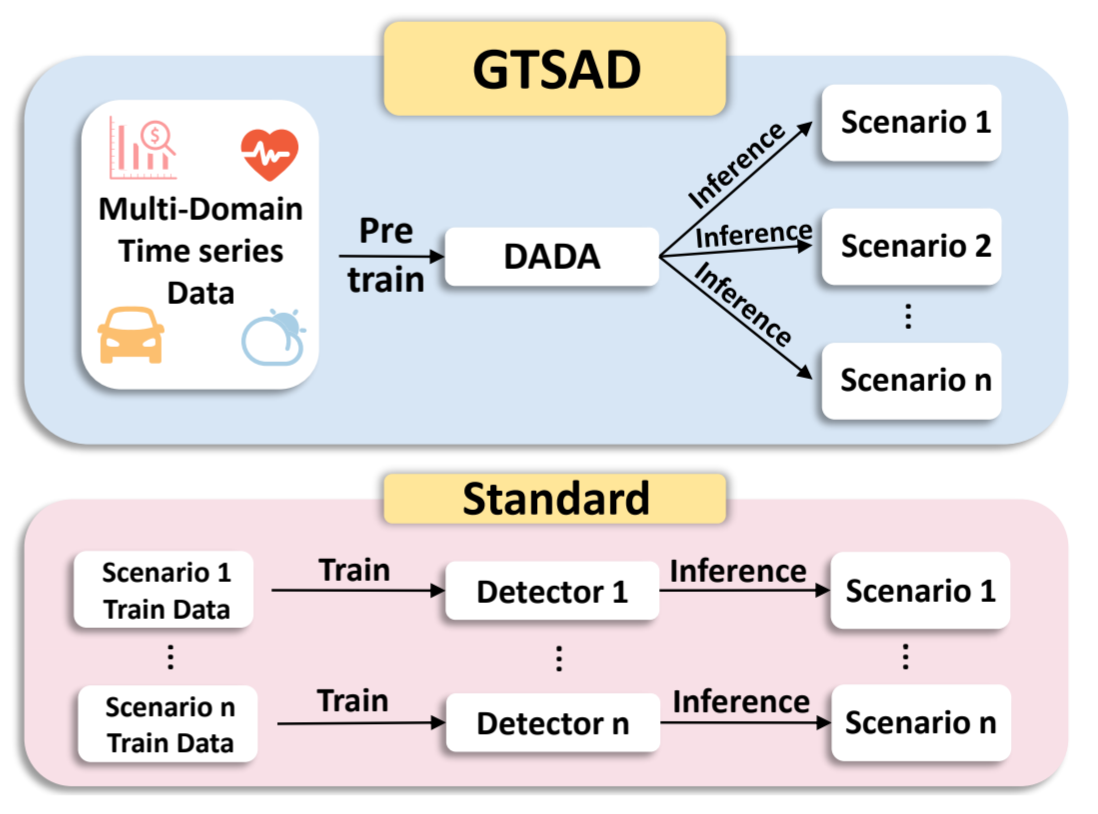
图 1:一般时间序列异常检测(GTSAD)和针对各种情况训练特定检测器的标准方法。
首先,大规模时间序列数据来自多个来源和领域,信息密度各不相同,这就提出了在一个统一模型中满足针对不同数据集的适当信息瓶颈的多样化要求的挑战。由于异常数据本身的稀缺性,现有的异常检测方法强调用自动编码器准确捕捉正常数据的特征(Chalapathy & Chawla,2019)。信息瓶颈被认为是压缩原始数据内在信息与高保真重构之间的权衡(Kawaguchi 等人,2023 年)。大的瓶颈可以准确地重建原始数据,但可能导致模型拟合出与正常模式无关的不必要噪声。相反,小瓶颈可以紧凑地压缩内在信息,但可能导致多种正常模式的丢失和重建效果不佳(Wang 等人,2023a)(很好,但现在开始是我的了)。现有的异常检测方法通常会针对每个场景调整固定的内部信息瓶颈,在面对数据分布、周期性和噪声水平差异显著的多域时间序列数据时,表征能力不够灵活,泛化能力不足(刘等,2024a),难以很好地适应下游场景。
其次,异常在多域中的不同表现形式对正常模式和多样化异常模式的稳健区分提出了另一个重大挑战。一个能够进行一般异常检测的模型不仅需要清楚地了解来自不同领域的时间序列数据中的特定正常模式,还需要明确划分不同正常模式和异常模式之间的决策边界。现有的异常检测方法通常基于单类分类假设,只学习每个特定领域时间序列数据中的正常模式,缺乏对异常的明确区分。同时,由于正常和异常模式在不同领域的分布会发生变化,因此仅仅学习辨别特定领域的正常和异常模式并不具有足够的通用性。因此,他们可能难以区分一般时间序列中的正常和异常模式,因为在一般时间序列中,多领域数据具有不同的异常表现,正常和异常模式之间的判定界限也更为复杂。
在本文中,我们提出了一种带有自适应瓶颈和双对抗解码器(DADA)的新型通用时间序列异常检测器。对于第一个挑战,我们从动态瓶颈的角度考虑了模型的泛化能力,并引入了自适应瓶颈模块,以增强从多域数据中学习正常时间序列模式的能力。我们采用瓶颈将特征压缩到潜空间,而潜空间的大小可以体现多域数据的不同信息密度(Wang 等,2023a)。为了满足分歧数据对不同信息瓶颈的要求,我们建立了一个瓶颈池,其中包含不同潜空间大小的各种瓶颈。然后,我们进一步提出了一种数据自适应机制,以便根据输入数据的独特重构要求灵活选择适当的内部大小。为了应对第二个挑战,我们提出了双对抗解码器模块,该模块与编码器协同工作,扩大正常模式和异常模式之间的稳健区分,其中正常解码器学习正常模式,以准确重建正常序列,而异常解码器则从异常时间序列中学习不同的异常模式。通过注入代表更常见异常模式的噪声,我们可以防止模型过度拟合特定领域的异常模式,因为不同领域的异常模式可能各不相同。我们为编码器和异常解码器设计了一种关于重建异常序列的对抗训练机制,在多域训练过程中学习正常时间序列和常见异常之间的明确决策边界,从而提高不同场景下的异常检测能力。我们的主要贡献概述如下:
- 我们提出了具有自适应瓶颈和双对抗解码器的新型通用时间序列异常检测器 DADA。通过在多领域时间序列数据上进行预训练,我们实现了 “一模多用 ”的目标,即一个模型无需特定领域的训练就能高效地对各种目标场景进行异常检测。
- 自适应瓶颈的提出首次从时间序列异常检测的动态瓶颈角度考虑了模型的泛化能力,自适应地解决了多域数据的灵活重构要求。
- 所提出的双对抗解码器以对抗训练的方式明确放大了正常时间序列和常见异常之间的决策边界,从而提高了不同场景下的通用异常检测能力。
- 我们的模型可作为零次时间序列异常检测器,与专门针对每个数据集训练的最先进模型相比,它在各种下游数据集上都能实现具有竞争力或更优越的性能。
2 相关工作
时间序列异常检测。时间序列异常检测方法主要分为非学习方法、经典学习方法和深度学习方法 Zhao 等人(2022 年)。非学习方法包括基于密度的方法(Breunig 等人,2000 年)和基于相似性的方法(Yeh 等人,2016 年),前者通过分析聚类中数据点的分布密度来确定哪些数据点是异常的,后者则将与大多数序列明显不同的序列标记为异常。经典学习方法(Liu 等人,2008 年)使用仅由正常数据组成的训练数据集来分类测试数据是否与正常数据相似(Scholkopf¨ 等人,1999 年)。深度学习方法主要包括基于重构的方法和基于预测的方法。基于重构的方法压缩原始输入数据,然后尝试重构这种表示,异常数据往往难以正确重构(赵等人,2022;吴等人,2025)。经典方法包括使用 AE(Campos 等人,2022 年;Krizhevsky 等人,2012 年)、VAE(Park 等人,2018 年;Li 等人,2021b)或 GAN(Li 等人,2019 年;Schlegl 等人,2019 年),以及最近非常成功地使用transformer架构(Chen 等人,2022 年;Hu 等人,2024 年)。基于预测的方法(Pang 等人,2022 年)使用过去的观测结果来预测当前值,并将预测结果与实际值之间的差异作为异常标准。与这些需要为每个数据集建立一个模型的方法不同,我们的方法主要是通过在多域时间序列数据上进行预训练来构建一个通用的时间序列异常检测模型,它可以有效地应用于各种目标数据集。
时间序列预训练模型。时间序列预训练受到广泛关注。一些研究开发了针对时间序列的通用训练策略。PatchTST(Nie 等人,2023 年)和 SimMTM(Dong 等人,2023 年b)采用了 BERT 式掩码预训练。InfoTS(Luo等人,2023年)和TS2Vec(Yue等人,2022年)利用数据增强视图之间的对比学习。此外,一些研究还将大型语言模型重新用于时间序列任务(Gruver 等人,2023 年),如 GPT4TS(Zhou 等人,2023 年)。最近,出现了具有zero-shot预测能力的新型时间序列预训练模型(Garza & Canseco,2023;Woo 等人,2024;Liu 等人,2024a;Dooley 等人,2023;Liu 等人,2024b;Gruver 等人,2023),即使不在目标数据集上进行训练,这些模型也能表现出不俗的性能。尽管如此,支持zero-shot的时间序列异常检测模型仍然匮乏。现有的异常检测预训练方法必须在目标数据集上进行训练。与以往的方法不同,在多域数据集上进行预训练的 DADA 专为时间序列异常检测而设计,在各种目标场景下的zero-shot异常检测中表现出色,从而填补了这一领域的空白。
3 方法
给定时间序列![]() 包含 T 个连续观测值,其中 C 为数据维度。时间序列异常检测输出
包含 T 个连续观测值,其中 C 为数据维度。时间序列异常检测输出![]() ,其中
,其中![]() 表示某一时间 t 的观测值
表示某一时间 t 的观测值![]() 是否异常。在本文中,我们将重点建立一个通用的时间序列异常检测模型,该模型在 M 个多域时间序列数据集
是否异常。在本文中,我们将重点建立一个通用的时间序列异常检测模型,该模型在 M 个多域时间序列数据集![]() 上进行预训练,其中每个数据集
上进行预训练,其中每个数据集![]() 具有
具有![]() 变量和
变量和![]() 时间点。然后,预训练模型可用于目标下游数据集
时间点。然后,预训练模型可用于目标下游数据集![]() 的异常检测,无需任何微调。来自不同领域的时间序列具有不同数量的变量。因此,我们利用通道独立性将模型扩展到不同领域(Nie 等人,2023;Yang 等人,2023;Goswami 等人,2024;Liu 等人,2024b;Wang 等人,2024)。具体来说,一个 C 变量时间序列被处理成 C 个独立的单变量时间序列。
的异常检测,无需任何微调。来自不同领域的时间序列具有不同数量的变量。因此,我们利用通道独立性将模型扩展到不同领域(Nie 等人,2023;Yang 等人,2023;Goswami 等人,2024;Liu 等人,2024b;Wang 等人,2024)。具体来说,一个 C 变量时间序列被处理成 C 个独立的单变量时间序列。
3.1 总体结构
我们提出的 DADA 是一种具有自适应瓶颈和双对抗解码器的新型通用时间序列异常检测器。如图 2 所示,DADA 采用基于掩码的重构架构对时间序列进行建模。在预训练阶段,我们利用正常序列(没有时间点被标记为异常)和异常序列(包含噪声扰动)。正常和异常时间序列同时输入 DADA。patch和互补掩码模块将每个序列映射为掩码patch嵌入(一个问题,是片段之内进行掩码还是片段之间进行掩码?应该是片段内,但是不确定。),并将其输入编码器以提取时间特征。DADA 通过动态选择合适的瓶颈大小,对多域时间序列数据采用自适应瓶颈。最后,采用双对抗解码器重建正常和异常序列。在推理阶段,异常解码器被移除,DADA 采用多个互补掩码生成多对掩码patch嵌入。重建值的方差作为异常得分,其中正常数据可以稳定重建。
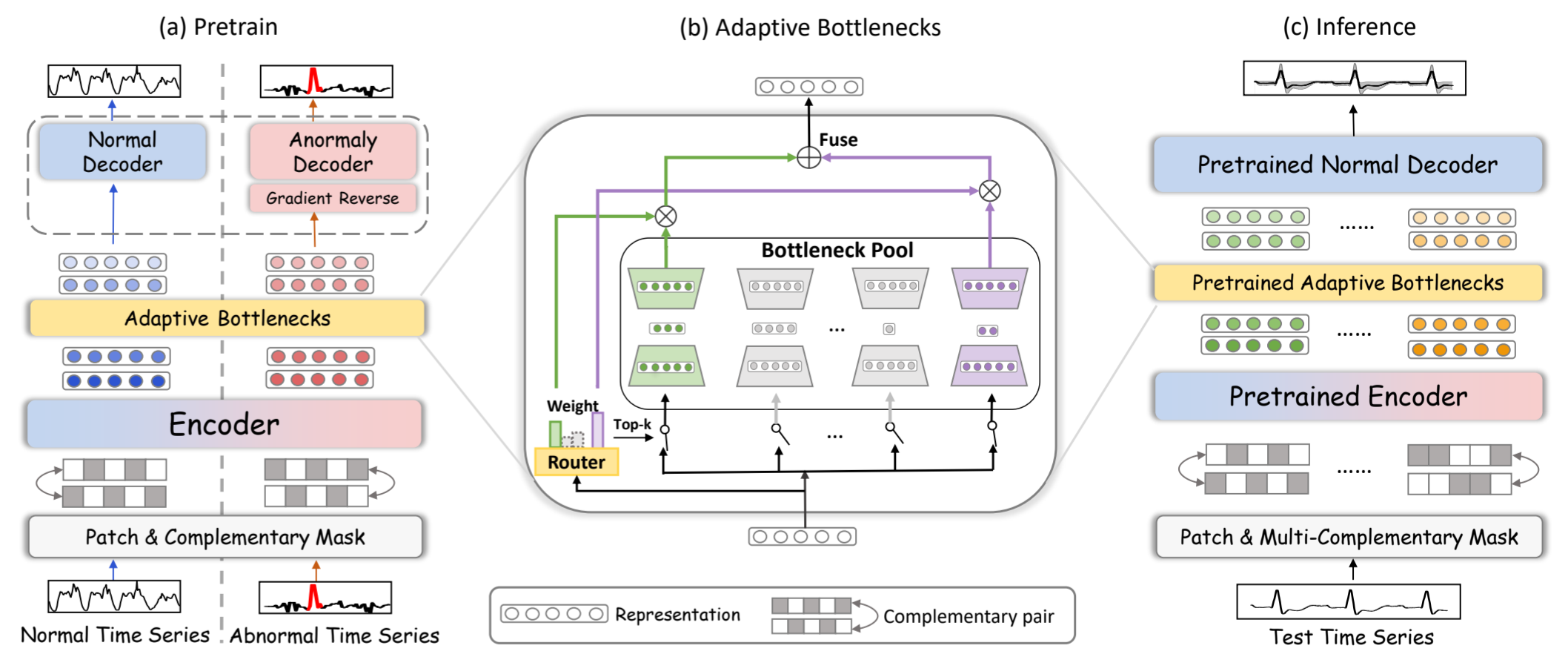
图 2:(a)预训练阶段的工作流程。DADA 主要由 Patch和互补掩码、编码器、自适应瓶颈和双对抗解码器组成。(b) 自适应瓶颈的结构。(c) 推理阶段的工作流程。
3.2 互补掩码建模
时间序列掩码建模利用未掩码部分重建掩码部分,以捕捉未掩码部分与掩码部分之间的正常时间依赖关系。高重建误差表明存在偏离正常行为的异常情况。在本文中,我们采用互补掩码策略,生成一对掩码位置互补的掩码序列,它们相互重建,以进一步捕捉全面的双向时间依赖性。首先,我们使用patch embedding将单变量输入时间序列划分为 P 个patch,每个patch的维度为 d,表示为![]() 。实践证明,用patches划分时间序列数据非常有助于捕捉每个patch内的局部信息和学习不同patches间的全局信息,从而实现对复杂时间模式的捕捉(聂等人,2023;杨等人,2023)。然后,我们沿时间维度随机掩码一部分patches,生成一个掩码序列,形式化为
。实践证明,用patches划分时间序列数据非常有助于捕捉每个patch内的局部信息和学习不同patches间的全局信息,从而实现对复杂时间模式的捕捉(聂等人,2023;杨等人,2023)。然后,我们沿时间维度随机掩码一部分patches,生成一个掩码序列,形式化为![]() ,其中
,其中![]() 为掩码,⊙为元素相乘。同时,我们根据掩码 M 生成另一个对
为掩码,⊙为元素相乘。同时,我们根据掩码 M 生成另一个对![]() 进行补充的掩码时间序列,形式化为
进行补充的掩码时间序列,形式化为![]() 。然后,我们根据
。然后,我们根据![]() 重构掩码部分
重构掩码部分![]() ,反之亦然。这样,模型就能充分利用所有数据点来捕捉全面的双向时间依赖关系。最后,我们合并互补的重建结果。将重构过程表示为 Recon(-) = Decoder(AdaBN(Encoder(-))),它将输入通过编码器、AdaBN 和解码器,以获得重构结果。AdaBN 和解码器详见第 3.3 节和第 3.4 节。最终重构结果
,反之亦然。这样,模型就能充分利用所有数据点来捕捉全面的双向时间依赖关系。最后,我们合并互补的重建结果。将重构过程表示为 Recon(-) = Decoder(AdaBN(Encoder(-))),它将输入通过编码器、AdaBN 和解码器,以获得重构结果。AdaBN 和解码器详见第 3.3 节和第 3.4 节。最终重构结果![]() 的计算公式为:
的计算公式为:
![]()
3.3 自适应瓶颈
如前所述,DADA 在多域时间序列数据集上进行预训练,并应用于广泛的下游场景。这就要求 DADA 具备从多领域时间序列数据集中学习可泛化表征的能力,这些数据集在数据分布、噪声水平等方面存在显著差异(Woo 等人,2024 年),并表现出不同的瓶颈偏好。潜空间的大小可视为模型的内部信息瓶颈(Wang 等,2023a)。瓶颈过大可能会导致模型拟合不必要的噪声,而瓶颈过小可能会导致丢失多样化的正常模式。现有方法(Campos 等人,2022 年;Su 等人,2019 年;Sakurada & Yairi,2014 年)使用的固定瓶颈方法泛化能力差,无法检测到跨领域的异常。因此,我们创新性地从动态瓶颈的角度考虑模型的泛化能力,提出了集成自适应路由器和瓶颈池的自适应瓶颈模块(AdaBN),为多域时间序列动态分配合适的瓶颈,增强了模型的泛化能力,使其能够直接应用于各种目标场景。
瓶颈池。我们将特征压缩到不同的潜空间,以实现不同信息密度的信息瓶颈。为了适应多域时间序列数据的不同要求,我们配置了 B 个不同大小的瓶颈池![]() ,每个瓶颈池可以将特征压缩到维度为 d i 的不同大小的潜空间中。经过掩码的时间序列输入编码器可以生成相应的表示
,每个瓶颈池可以将特征压缩到维度为 d i 的不同大小的潜空间中。经过掩码的时间序列输入编码器可以生成相应的表示![]() ,其中 d r 表示表示的维度。每个瓶颈的过程可形式化为:
,其中 d r 表示表示的维度。每个瓶颈的过程可形式化为:
![]()
![]() 表示将表示 z 压缩到潜空间
表示将表示 z 压缩到潜空间![]() 的网络,其中 d i 是第 i 个瓶颈 BN i (-) 的潜空间维度,且 d i < d r。
的网络,其中 d i 是第 i 个瓶颈 BN i (-) 的潜空间维度,且 d i < d r。![]() 从
从![]() 的潜在空间中恢复表示 z(为什么压缩之后还要再恢复回来?个人理解:1.特征先降维再升维,可以实现信息过滤与特征抽象,将输入的高维特征表示压缩到低维空间,形成一个信息瓶颈,通过降维,模型被强制学习数据的核心特征与关键信息,而舍弃冗余或非关键信息,这种方式有助于获得更为鲁棒的特征表示。2.压缩——恢复的过程使得模型在适配不同数据集时,能够在信息压缩的程度上动态调整,更灵活地处理不同复杂度的数据。3.而且降维后再升维,可以避免模型简单地记忆输入数据,而是促使模型学习更加泛化的特征表示。在压缩后重建回原始维度,使得模型能够从压缩表示中捕捉原始数据的重要结构与模式,而非简单重现输入,从而进一步提升泛能能力。4.压缩后的低维特征空间对异常数据通常更加敏感,因为异常数据难以用压缩后的特征表示有效地重构回原始空间。因此,压缩后再恢复的过程本质上可以作为一种特征空间重构误差,显著放大异常与正常数据的差异,有利于提高异常检测性能。总结:压缩空间再恢复回去的本质,是为了构建一个有效的信息瓶颈,帮助模型学到泛化能力强且对异常敏感的特征表示)。(正常序列下,模型应该能从瓶颈空间准确恢复原序列,这说明瓶颈空间中保存了重要的正常模式信息。当输入序列出现异常时,压缩空间(瓶颈)将会对异常模式进行强烈压缩,导致解码时无法精确恢复原序列。这种恢复误差(重构误差)正是异常检测的依据。)
的潜在空间中恢复表示 z(为什么压缩之后还要再恢复回来?个人理解:1.特征先降维再升维,可以实现信息过滤与特征抽象,将输入的高维特征表示压缩到低维空间,形成一个信息瓶颈,通过降维,模型被强制学习数据的核心特征与关键信息,而舍弃冗余或非关键信息,这种方式有助于获得更为鲁棒的特征表示。2.压缩——恢复的过程使得模型在适配不同数据集时,能够在信息压缩的程度上动态调整,更灵活地处理不同复杂度的数据。3.而且降维后再升维,可以避免模型简单地记忆输入数据,而是促使模型学习更加泛化的特征表示。在压缩后重建回原始维度,使得模型能够从压缩表示中捕捉原始数据的重要结构与模式,而非简单重现输入,从而进一步提升泛能能力。4.压缩后的低维特征空间对异常数据通常更加敏感,因为异常数据难以用压缩后的特征表示有效地重构回原始空间。因此,压缩后再恢复的过程本质上可以作为一种特征空间重构误差,显著放大异常与正常数据的差异,有利于提高异常检测性能。总结:压缩空间再恢复回去的本质,是为了构建一个有效的信息瓶颈,帮助模型学到泛化能力强且对异常敏感的特征表示)。(正常序列下,模型应该能从瓶颈空间准确恢复原序列,这说明瓶颈空间中保存了重要的正常模式信息。当输入序列出现异常时,压缩空间(瓶颈)将会对异常模式进行强烈压缩,导致解码时无法精确恢复原序列。这种恢复误差(重构误差)正是异常检测的依据。)
自适应路由器。由于潜空间的信息容量与数据的信息密度不匹配,不加区别地使用瓶颈池中的所有瓶颈会降低模型性能。理想的模型会根据时间序列数据的内在属性动态分配适当的瓶颈。因此,我们引入了自适应路由器(Adaptive Router),这是一种动态分配策略,可以为每个时间序列灵活选择瓶颈大小(先通过自适应路由器,选择瓶颈大小,然后再去用瓶颈池),以满足灵活的重建要求。如图 2(b) 所示,自适应路由器采用路由函数,根据表征从瓶颈池中生成每个瓶颈的选择权重。为了避免重复选择某些瓶颈,导致相应的瓶颈重复更新,而忽略其他可能合适的瓶颈,我们添加了噪声项来增加随机性。我们得到路由函数 R(z) 的总公式为:
![]()
其中,![]() 是用于生成权重的可学习矩阵,B 是瓶颈的数量,Softplus 是激活函数(用于确保输出为正数(正的尺度),因此噪声项的影响始终为正,且可训练。
是用于生成权重的可学习矩阵,B 是瓶颈的数量,Softplus 是激活函数(用于确保输出为正数(正的尺度),因此噪声项的影响始终为正,且可训练。![]() ,用于确保权重计算的平滑性和非线性)。R(z) 将表示 z 映射到 B 个瓶颈的选择权重。为了鼓励模型更新关键瓶颈,我们选择了权重最高的 k 个瓶颈,将其索引集合记为 K:(公式(4)即权重归一化公式,计算出的权重R(z)通常需要进行归一化处理,以确保它们的和为1。可以通过softmax函数实现,所以公式(4)其实是满足softmax函数的。)(动态调整的好处可以适应不同数据集的需求,满足不同数据集的偏好:不同的数据集可能对瓶颈大小有不同的偏好。例如,某些数据集可能需要较大的瓶颈来保留足够的信息,而另一些数据集可能只需要较小的瓶颈即可。避免固定瓶颈的局限性:固定瓶颈大小的模型在不同数据集上的表现不够稳定,而自适应瓶颈能够根据数据集的特点动态调整,从而在各个数据集上都能取得更优的效果。)
,用于确保权重计算的平滑性和非线性)。R(z) 将表示 z 映射到 B 个瓶颈的选择权重。为了鼓励模型更新关键瓶颈,我们选择了权重最高的 k 个瓶颈,将其索引集合记为 K:(公式(4)即权重归一化公式,计算出的权重R(z)通常需要进行归一化处理,以确保它们的和为1。可以通过softmax函数实现,所以公式(4)其实是满足softmax函数的。)(动态调整的好处可以适应不同数据集的需求,满足不同数据集的偏好:不同的数据集可能对瓶颈大小有不同的偏好。例如,某些数据集可能需要较大的瓶颈来保留足够的信息,而另一些数据集可能只需要较小的瓶颈即可。避免固定瓶颈的局限性:固定瓶颈大小的模型在不同数据集上的表现不够稳定,而自适应瓶颈能够根据数据集的特点动态调整,从而在各个数据集上都能取得更优的效果。)
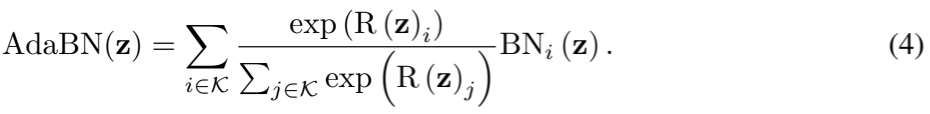
3.4 双对抗解码器
正常时间序列的重构。如公式 (1) 所示,每个输入序列 X 都会被重构为结果![]() 。为了实现异常检测的目标,我们从正常时间序列的重构中学习正常模式。如图 3 所示,我们使用特征提取器
。为了实现异常检测的目标,我们从正常时间序列的重构中学习正常模式。如图 3 所示,我们使用特征提取器![]() 和正常解码器
和正常解码器![]() ,参数
,参数
![]() 和
和![]() 表示用于重建正常序列的模型部分。G 包括 patch 和互补掩码模块、编码器和自适应瓶颈。解码器
表示用于重建正常序列的模型部分。G 包括 patch 和互补掩码模块、编码器和自适应瓶颈。解码器![]() 使用自适应瓶颈的输出来重建序列。我们通过最小化正常序列的重建误差来学习正常时间序列模式:
使用自适应瓶颈的输出来重建序列。我们通过最小化正常序列的重建误差来学习正常时间序列模式:
![]()
其中,Nn 是正态训练序列的数量。![]() 是第 i 个正态序列,
是第 i 个正态序列,![]() 是相应的重建结果。
是相应的重建结果。

图 3:正常数据和异常数据的前向和后向传播。
重建异常时间序列。然而,仅仅学习捕捉正常模式不足以检测新场景中的异常。作为一种通用的时间序列异常检测模型,该模型将面对具有多种异常表现形式的多领域数据,而有些模式可能只针对某一领域,无法进行跨领域泛化,这就使得决策边界变得更加复杂。因此,我们需要明确增强模型对正常模式和一些常见异常模式的判别能力。我们将代表常见异常模式的带有噪声扰动的异常序列纳入预训练阶段,并提出了一种对抗训练阶段,它能使正常序列的重构误差最小化,而使异常序列的重构误差最大化(特征提取器学习到的特征应具有泛化性,尤其要能清晰地区分正常模式和异常模式。正常解码器的目标:从特征空间中尽可能准确地重建正常模式,作用:引导特征提取器学习正常模式相关的特征。异常解码器的目标:学会从特征空间重建出异常模式,与正常模式形成清晰区别。但是又不希望特征提取器去帮助异常解码器,否则特征提取器将学习到异常的模式,导致特征对异常不敏感,模型泛化性下降。为了解决这个问题,引入了GRL梯度反转层。梯度反转层的加入,使得特征提取器在反向传播过程中,刻意与异常解码器对抗。通过反转梯度,使得特征提取器尽可能避免学习异常模式的特征表示,而异常解码器则尝试客服这个阻力区捕获异常模式。)。简单地放大异常序列的重构误差会混淆特征提取器 G,从而无法学习正常模式。为了解决这个问题,我们引入了参数为 θ a 的异常解码器![]() 进行对抗训练,以约束模型并鼓励特征提取器
进行对抗训练,以约束模型并鼓励特征提取器![]() 学习正常模式特征。我们寻求特征提取器的参数θ g,使异常数据的重构损失最大化,从而使表征尽可能少地包含异常信息,同时寻求异常解码器的参数θ a,使异常数据的重构损失最小化,从而学习异常模式。异常序列的重构损失可形式化为:
学习正常模式特征。我们寻求特征提取器的参数θ g,使异常数据的重构损失最大化,从而使表征尽可能少地包含异常信息,同时寻求异常解码器的参数θ a,使异常数据的重构损失最小化,从而学习异常模式。异常序列的重构损失可形式化为:
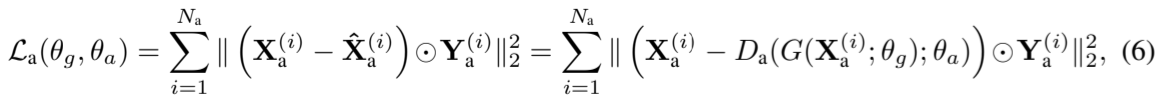
其中,![]() 是异常训练序列的数量,
是异常训练序列的数量,![]() 和
和![]() 表示第 i 个异常序列及其异常标签。我们的方法并不严格要求标注数据。为了减少对人工标注数据的依赖,并避免对特定异常模式的过度拟合,我们通过异常注入的方式生成具有更常见异常模式的异常数据。有关异常注入的更多详情,请参阅附录 A.3。
表示第 i 个异常序列及其异常标签。我们的方法并不严格要求标注数据。为了减少对人工标注数据的依赖,并避免对特定异常模式的过度拟合,我们通过异常注入的方式生成具有更常见异常模式的异常数据。有关异常注入的更多详情,请参阅附录 A.3。
模型训练。如前所述,总体优化目标是寻求使公式 (6) 最大化的特征提取器参数![]() ,同时寻求使公式 (6) 最小化的异常解码器参数
,同时寻求使公式 (6) 最小化的异常解码器参数![]() 。此外,我们还寻求最小化公式 (5)。如图 3 所示,我们在 G 和
。此外,我们还寻求最小化公式 (5)。如图 3 所示,我们在 G 和![]() 之间使用了梯度反转层(GRL)(Ganin & Lempitsky,2015 年)(GRL梯度反转层广泛应用于领域对抗训练和迁移学习中来实现对抗训练的情况,是一种在领域适应和对抗训练中常用的技术,其核心思想是在特征提取器和判别器之间插入一个特殊层,使得在反向传播时梯度方向取反,从而实现对抗训练。梯度反转层在前向传播过程中不做任何改变,输出即输入,而在反向传播(即梯度计算)过程中,会对经过该层的梯度直接乘以一个负数(通常为-1),从而使得特征提取器和判别器的训练目标相反。也就是说,梯度反转层只在反向传播时改变梯度符号,正向传播则没有任何效果。梯度反转层的作用:1.使神经网络在学习时,刻意忽略或无法学习特定特征(如领域特征)。2.让网络变得对某些输入特征或潜在因素不敏感,以获得领域无关的特征表示。也满足作者的目的,希望网络学习一种跨领域泛化的表征。)。GRL 会改变
之间使用了梯度反转层(GRL)(Ganin & Lempitsky,2015 年)(GRL梯度反转层广泛应用于领域对抗训练和迁移学习中来实现对抗训练的情况,是一种在领域适应和对抗训练中常用的技术,其核心思想是在特征提取器和判别器之间插入一个特殊层,使得在反向传播时梯度方向取反,从而实现对抗训练。梯度反转层在前向传播过程中不做任何改变,输出即输入,而在反向传播(即梯度计算)过程中,会对经过该层的梯度直接乘以一个负数(通常为-1),从而使得特征提取器和判别器的训练目标相反。也就是说,梯度反转层只在反向传播时改变梯度符号,正向传播则没有任何效果。梯度反转层的作用:1.使神经网络在学习时,刻意忽略或无法学习特定特征(如领域特征)。2.让网络变得对某些输入特征或潜在因素不敏感,以获得领域无关的特征表示。也满足作者的目的,希望网络学习一种跨领域泛化的表征。)。GRL 会改变![]() 的梯度,将其乘以 -λ,然后传递给 G。也就是说,编码器
的梯度,将其乘以 -λ,然后传递给 G。也就是说,编码器![]() 的损失偏导数被替换为
的损失偏导数被替换为![]() (异常解码器试图通过梯度告诉特征提取器如何重建异常模式,但是GRL将这个梯度取负数,就会迫使特征提取器朝相反的方向优化,也就是特征提取器将难以生成异常模式相关的特征。)(梯度反转层的优势:强制特征提取器学习泛化特征(正常模式相关), 避免过拟合于异常。实现正常与异常模式之间的清晰特征分界线。提升模型跨领域泛化能力,泛化到未见过的异常模式。),在梯度下降过程中,不同优化目标的参数会朝着所需的方向移动,从而避免了两次单独优化的需要。最后,我们的目标可以形式化为:
(异常解码器试图通过梯度告诉特征提取器如何重建异常模式,但是GRL将这个梯度取负数,就会迫使特征提取器朝相反的方向优化,也就是特征提取器将难以生成异常模式相关的特征。)(梯度反转层的优势:强制特征提取器学习泛化特征(正常模式相关), 避免过拟合于异常。实现正常与异常模式之间的清晰特征分界线。提升模型跨领域泛化能力,泛化到未见过的异常模式。),在梯度下降过程中,不同优化目标的参数会朝着所需的方向移动,从而避免了两次单独优化的需要。最后,我们的目标可以形式化为:
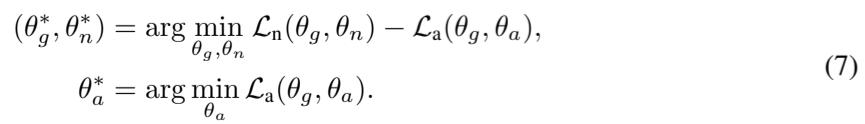
异常标准。在推理阶段,模型会为单个序列生成多对互补的掩码序列,并输出多个重构序列。正常数据点可以稳定重构,重构值较为接近。相反,异常数据点的重建比较困难,而且往往更不稳定。因此,我们利用同一时间点重建值的方差作为异常得分。按照现有的工作(Wang 等人,2023a;Su 等人,2019),我们运行 SPOT(Siffer 等人,2017)得到阈值δ,如果一个时间点的异常得分大于δ,则该时间点被标记为异常点。
4 实验
4.1 实验设置
数据集。我们使用莫纳什(Godahewa 等人,2021 年)数据中心的一个子集和 12 个异常检测任务数据集(Li 等人,2021a;Jacob 等人,2021 年;Ren 等人,2019 年;Roggen 等人,2010 年;Cui 等人,2016 年;Thill 等人,2020 年;Moody & Mark,2001 年;Greenwald 等人,1990 年;Laptev 等人,2015 年)进行预训练。预训练数据集包含约 4 亿个时间点,错综复杂地代表了广泛的领域。为了证明我们方法的有效性,我们评估了五个广泛使用的基准数据集: SMD(Su 等人,2019 年)、MSL(Hundman 等人,2018 年)、SMAP(Hundman 等人,2018 年)、SWaT(Mathur & Tippenhauer,2016 年)、PSM(Abdulaal 等人,2021 年)和 NeurIPS-TS(包括 CICIDS、Creditcard、GECCO 和 SWAN)(Lai 等人,2021 年)。我们还在附录 C.2 中对 UCR(Wu & Keogh,2023 年)进行了评估。用于评估的下游数据集均未包含在预训练数据集中。有关预训练数据集和评估数据集的更多详情,请参阅附录 A。
基线。我们将我们的模型与 19 个基线模型进行了综合评估比较,其中包括基于线性变换的模型: OCSVM (Scholkopf¨ et al., 1999), PCA (Shyu et al., 2003);基于密度估计的方法:HBOS (Goldstein & Dengel, 2012),LOF (Breunig et al., 2000);基于离群值的方法:IForest (Liu et al., 2000),LOF (Breunig et al., 2000): IForest (Liu et al., 2008), LODA (Pevny,´ 2016);基于神经网络的模型: AutoEncoder(AE)(Sakurada & Yairi,2014)、DAGMM(Zong 等人,2018)、LSTM(Hundman 等人,2018)、CAE-Ensemble(Campos 等人,2022)、BeatGAN(Zhou 等人,2019)、OmniAnomaly(Omni)(Su 等人、 2019), Anomaly Transformer (A.T.) (Xu et al., 2022), MEMTO (Song et al., 2024), DCdetector (Yang et al., 2023), D3R (Wang et al., 2023a), GPT4TS (Zhou et al., 2023), ModernTCN (donghao & wang xue, 2024), SensitiveHUE (Feng et al., 2024)。为了确保比较的公平性,我们在所有基线中采用了相同的设置,包括指标和阈值协议,这也是异常检测中的常见做法。
度量标准。许多现有方法使用点调整(PA)来调整检测结果。然而,最近的研究表明,PA 可能会导致错误的性能评估(Huet 等人,2022 年)。即使一个异常区段中只有一个点被正确检测到,PA 也会假定模型已正确检测到整个区段,这是不合理的(Wang 等人,2023a)。为了克服这个问题,我们使用了基于隶属度的 F1 分数(F1)(Huet 等人,2022 年),该分数最近已被广泛使用(Wang 等人,2023a;Yang 等人,2023 年)。该分数考虑了预测异常与地面实况异常事件之间的平均定向距离,以计算附属精度(P)和召回率(R)。由于精确度和召回率受阈值的影响很大,只关注其中一个阈值无法对模型进行全面评估,因此异常检测需要平衡这两个指标。因此,我们更关注 F1 分数,如广泛应用于异常检测的 Yang 等人(2023 年);Xu 等人(2022 年)。我们还采用了 AUC ROC(AUC)指标(Wang 等人,2023a;Campos 等人,2022)。更多实施细节见附录 B。所有结果均以百分比表示。最佳结果以粗体表示,次佳结果以下划线表示。
4.2 主要结果
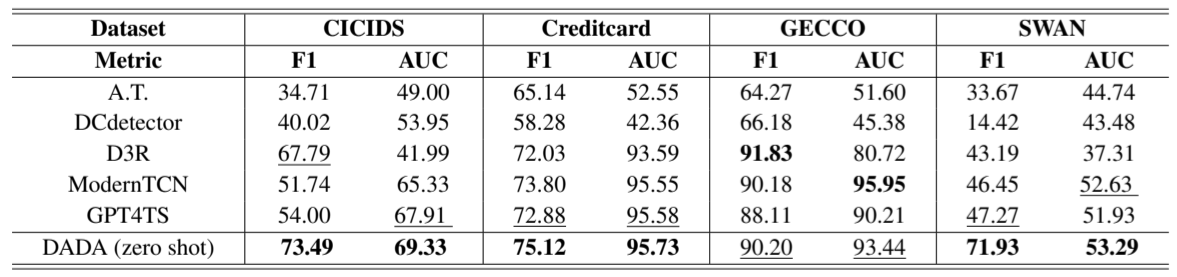
每个评估数据集都有一个训练集和一个测试集。标准基准方法在训练集上进行训练,并在相应的测试集上进行测试。与此不同,我们的模型 DADA 遵循的是 “zero-shot ”协议。在多领域数据集上对模型进行预训练后,它不在下游训练集上进行训练,而是直接在下游测试集上进行测试。请注意,所有下游评估数据集都不包括在我们的预训练数据集中。如表 1 所示,在每个特定数据集中,与使用完整数据直接训练的基线相比,DADA 作为zero-shot检测器,在所有五个数据集中都取得了最先进的结果,这表明 DADA 从广泛的预训练数据中学会了一般检测能力,并能明确区分多种正常模式和异常模式。我们还在表 2 中对 NeurIPS-TS 基准上的 DADA 进行了评估,并与表 1 中所示的五种近期表现良好的方法进行了比较。可以看出,这些基准方法在不同的数据集上都无法取得一致的良好结果。然而,得益于大规模数据的预训练,DADA 在所有数据集上都取得了最佳或最具竞争力的结果,包括异常类型丰富的 NeurIPS-TS 数据集(Xu 等人,2022 年;Yang 等人,2023 年)。这证明了 DADA 对不同异常检测场景的卓越适应性。更多其他指标评估详情见附录 C。
表 1: 五个真实世界数据集的结果。
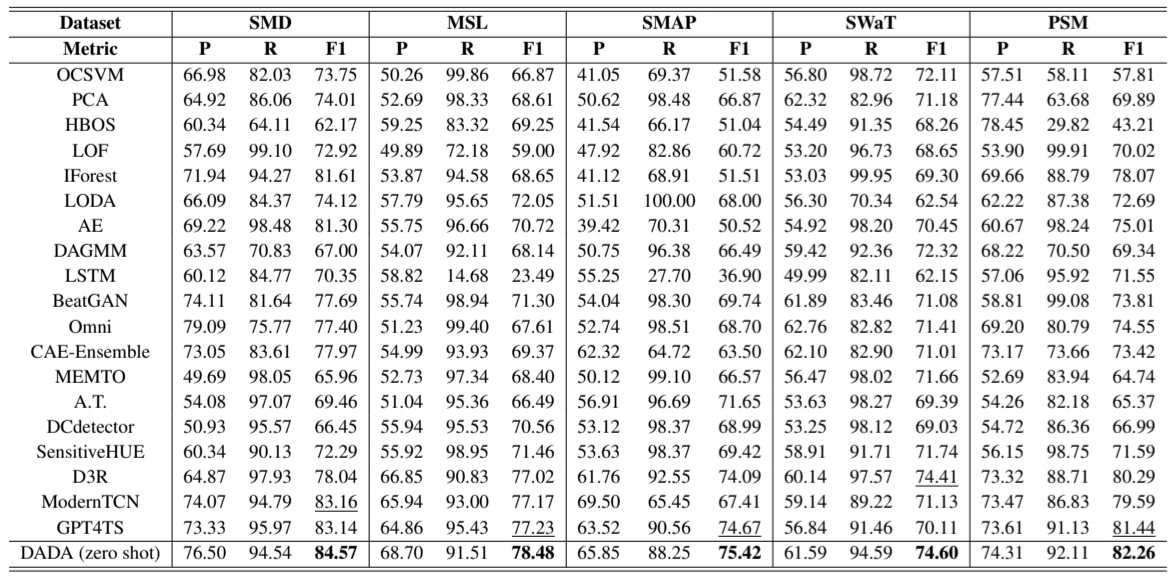
表 2: NeurIPS-TS 数据集的总体结果
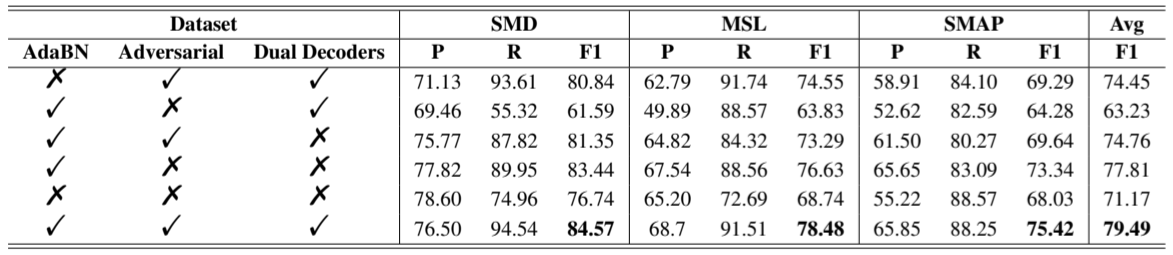
消融研究。如表 3 所示,我们进一步深入研究了各个组件对 DADA 在zero-shot设置下的性能的影响。首先,我们探讨了 AdaBN 模块的影响。第一行结果对多域数据集使用了单一固定瓶颈,消除了对各种瓶颈的自适应选择。去掉 AdaBN 模块后,结果显示下降了 5.04%。这强调了动态瓶颈对于多域预训练的重要性。我们还研究了双对抗解码器及其对抗机制的影响。第二行结果直接最大化了异常数据的重建误差,去除了对抗机制。第三行结果使用单一解码器重建正常时间序列和异常时间序列,第四行结果同时去除对抗机制并使用单一解码器。我们观察到,与 DADA 相比,w/o Adversarial 的性能下降了 16.26%(79.49%→63.23%),与第五行结果相比,下降了 7.89%(71.17%→63.23%),这表明需要与特征提取器对抗,当直接最大化异常时间序列时,异常解码器可以通过生成任意的重建结果来实现这一目标,并削弱编码器对正常模式的建模能力。此外,使用单个解码器同时处理正常和异常时间序列会导致zero-shot性能下降,因此有必要使用双解码器。
表 3:消融研究。我们研究了自适应瓶颈、对抗训练和双解码器的影响。所有结果均以百分比表示,最佳结果以粗体表示。
4.3 模型分析
我们分析了自适应瓶颈和多域预训练的有效性,并将异常得分可视化。我们还进行了其他分析实验,结果见附录 D 和附录 E。
利用下游数据进行微调。如图 4 所示,我们进一步展示了在不同数据稀缺程度下,在下游数据集上对 DADA 进行微调的结果。经过预训练后,该模型具有很强的泛化能力,并表现出良好的zero-shot异常检测性能。将模型应用于下游数据集,进一步学习特定领域的模式,可以进一步提高模型的检测能力。经过微调后,模型在 MSL 上的性能从 78.48% 提高到 79.90%,在 SMD 上的性能从 84.57% 提高到 85.50%。
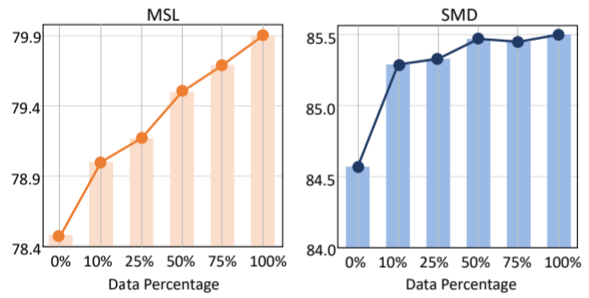
图 4:不同数据百分比下微调 DADA 的结果。
自适应瓶颈分析。为了验证 AdaBN 的有效性,我们移除了 AdaBN 模块,并采用了固定的瓶颈大小。如图 5(左)所示,我们观察到不同的瓶颈大小在不同的下游场景中表现出不同的偏好,同时也在某些场景中引入了明显的缺点,例如,瓶颈大小为 32 的模型在 Creditcard 上达到了 74.81%,而在 MSL 上仅为 67.56%。然而,采用自适应瓶颈动态分配适当瓶颈的 DADA 始终优于使用单一瓶颈的模型,这进一步证实了我们方法的有效性。我们还在附录 E 中直观展示了每个数据集选择不同自适应瓶颈大小的比例。
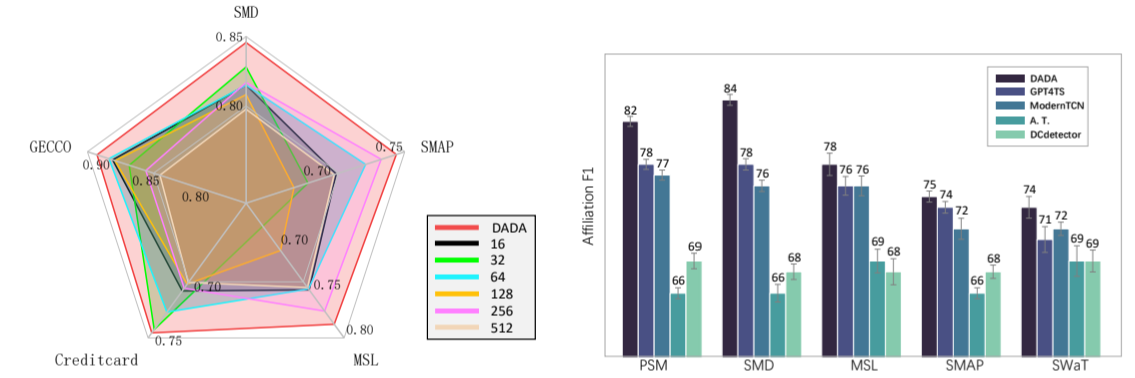
图 5:模型分析。(左)使用 AdaBN 的 DADA 与使用单一瓶颈的 DADA 的比较。 右)在多域数据集上预训练基线模型,然后将其作为目标数据集上的zero-shot检测器进行评估。
多域预训练分析。我们进一步评估了多域预训练后基线的zero-shot性能。采用与 DADA 相同的设置,这些模型首先在多域数据集上进行了广泛的预训练,然后在目标数据集上进行了zero-shot评估。从图 5(右)中可以看出,这些基线模型无法有效地从多域数据集中提取泛化能力,因此在目标数据集上也无法取得令人满意的结果。这表明,虽然多域预训练很重要,但如果没有适当的方法,仅仅使用多域数据集仍然无法获得理想的泛化能力。相比之下,DADA 配备了为一般异常检测任务定制的独特自适应瓶颈和双对抗解码器模块,显示出强大的多域预训练和一般检测能力。
可视化分析。为了进一步说明 DADA 中各模块的功效,我们随机抽取长度为 100 的时间片段进行可视化分析。图 6 展示了给定时间段内每个时间戳的异常得分和地面实况标签。DADA 去掉 AdaBN(W/O AdaBN)后,模型不能很好地适应多域数据的正常模式,误报率较高。移除双解码器(W/O Dual Decoders)后,模型在正常数据和异常数据之间的判定边界变得模糊,误报率变得更高。DADA(我们的)表明,DADA 不仅检测精度高,而且误报率也较低,这证明了它在时间序列异常检测方面的卓越性能。
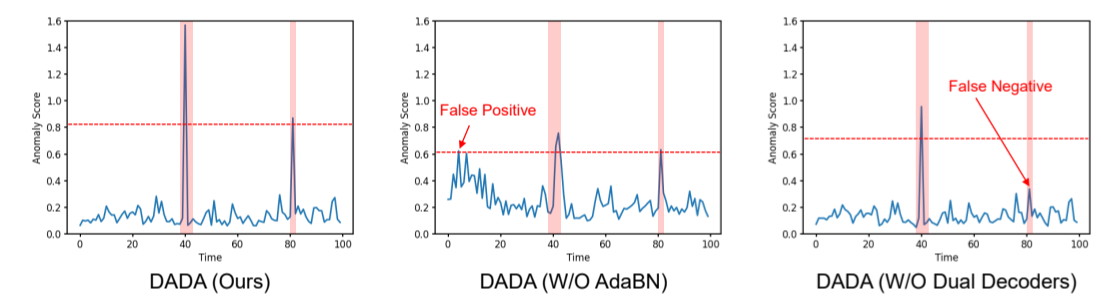
图 6:PSM 数据集异常得分的可视化。粉色区间表示ground truth异常,蓝色线条表示相应模型得出的异常分数。红色水平虚线表示阈值。任何异常分数超过该阈值的时间戳都会被识别为异常。
5 结论
本文提出了一种新型通用时间序列异常检测模型 DADA。通过在广泛的多领域数据集上进行预训练,DADA 随后无需微调即可应用于多种下游场景。我们提出了自适应瓶颈,以便在一个统一的模型中满足不同数据集对信息瓶颈的不同要求。我们还提出了双对抗解码器,以明确加强正常和异常模式之间的清晰区分。大量实验证明,作为一种zero-shot检测器,DADA 与那些为每个特定数据集量身定制的模型相比,仍能取得具有竞争力甚至更优越的结果。
(现在是2025年3月19日,20:18,大概看完了,但是有的没看明白,还要理解一下。)
(3月20日,没什么问题了。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号