DBA MongoDB 分片集群
架构探究
架构图
MongoDB分片集群与MySQL中的水平分表类似。
以下是一个较为完美的分片集群部署策略图:
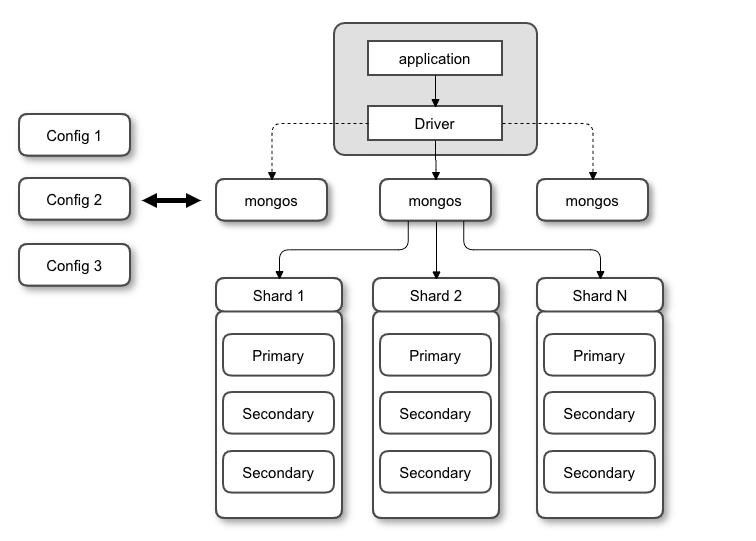
集群组成
名词解释:
- mongos :路由节点,提供集群单一入口,转发application的请求至所有分片节点上,上图中3个分片节点均是为了保证高可用又做了复制集
- config :配置节点,存储分片的配置策略,如分片开始位置,分片结束位置等
- shard :分片节点,以复制集为单位,对于分片节点来说,横向扩展最大可支持1024个,每个分片节点上的数据不允许重复,所有分片在一起才能完整的进行工作
分片集群由多个分片节点+配置节点+路由节点构成,特点如下:
-
分片集群对application是透明的,没有任何特殊处理
-
且对于数据来说会有自动均衡策略
-
如果要对分片集群进行扩容,可在线上直接进行扩容而无需下线
-
MongoDB当前提供3种分片方式
分片相关
分片策略
分片策略如下:
- 基于范围,范围查询性能良好,侧重于读的性能,但是可能造成数据分布不均匀
- 基于Hash,数据分布均匀,侧重于写的性能,但是范围查询效率低
- 基于zones / tag,适用于大范围的全球性业务
基于范围分片的图示:

基于Hash分片的图示:

基于Zones:

分片计算
如何计算当前业务需要多少个分片?下面是计算法则:
- 使用存储数据总量 / 单个服务器可挂载的容量 如:8TB / 2TB = 4
- 使用工作集的大小 / 单个服务器的内容容量*0.6(不可能全部占满) 如:400GB / (256G * 0.6) = 3
- 使用最高并发总数 / 单个服务器平均并发量*0.7(一个复制集群是有损耗的) 如:3000 / (9000 * 0.7) = 6
最终的分片数量采取3个结果中的最大值: max(4, 3, 6) = 6
对于分片的数据来说,每个分片节点的数据量都不应该超过3TB
对于分片的索引来说,必须保证常用的索引字段能够存放至内存中(查看文档索引,结合物理内存大小做计算)
分片名词
一些分片中常见的概念性名词,概念由小到大:
- 片键 shard key :文档中的一个字段,由于MongoDB的分片类似于水平分表,所以我们必须指定拆分的字段列
- 文档 doc :包含shard key的一行数据(对应到关系型数据库中,一个文档就是一行记录)
- 块 Chunk : 一个块包含多个文档,每个块的大小为64MB
- 分片 Shard : 一个分片节点中包含多个块,没有大小限制,但应该尽量保证单个分片的数据量在3TB下
- 集群 Cluster : 一个分片集群中包含多个分片节点,通常情况下一个分片集群也必须是一个复制集群(保证高可用)
片键选择
在选择片键时,要遵循以下几点原则,为了方便描述我均采用关系型数据库的概念来举例:
- 取值基数大:如果对一个表来说,水平拆分时如果按照gender字段进行拆分,那么即使拆分成多个表,单表的数据量级依旧很大,最好的选择是根据id进行拆分
- 取值分布均匀:如果对一个学生表来进行水平拆分,片键选择是年龄,年龄的基数虽然可以达到1-100,但是要注意业务场景,学生表的主要数据年龄为12-16岁(中学),这依然会造成单表的数据量级大的问题
- 片键应该利于分散写,集中读:如果片键选择不合理,对于写来说则可能造成写入的数据的Chunk块先到第一个分片节点中,发现位置不对再向第二个分片节点进行迁移的情况,造成性能损耗,多做了无用功。而对于读来说则可能会导致扫描所有分片节点的操作,不能准确定位,造成查询效率低的问题
以下用几种情况来举例MongoDB中片键的选择案例,这里与关系型数据库有较大的差异,建议不要做横向对比。
举例1,按照_id进行范围分片:
-
从基数的角度来看,使用_id进行分片,因为_id不会重复,所以是合理的
-
从写的角度看,由于_id总是递增的,新插入的数据总会到达最后的一个分片节点,是合理的
-
从读的角度看,用于MongoDB的_id与MySQL的id不同,因此没有人会用_id作为查询条件,这可能导致会扫描所有分片节点,读的性能极低,是不合理的
举例2,按照phone进行hash分片:
- 从基数的角度来看,phone永远不会重复,是合理的
- 从写的角度来看,使用hash分片,能够准确的将数据插入到对应的分片节点中,是合理的
- 从读的角度来看,使用phone作为查询条件虽然可以很快的拿出单个用户的数据,但是对于范围查询来讲效率会偏慢,这是不合理的
举例3,按照用户的id(不是_id)和phone进行分片:
- 从基数的角度来看,phone与用户id不会重复,是合理的
- 从写的角度来看,和上面一样,是合理的
- 从读的角度来看,无论是使用用户id或者phone进行读取,都能较快的拿出数据,是合理的
集群搭建
搭建环境
3台Centos7.3的虚拟机,4核心8GB的RAM
geekdemo1:Shard 1 Primary 27010、Shard 2 Primary 27011、Config 1 27019、mongos 27017
geekdemo2:Shard 1 Sencondary 27010、Shard 2 Sencondary 27011、Config 2 27019
geekdemo3:Shard 1 Sencondary 27010、Shard 2 Sencondary 27011、Config 3 27019
集群规划表示:
| member1 | member2 | member3 | member4 | member5 | member6 | |
|---|---|---|---|---|---|---|
| shard1 | √ | √ | √ | |||
| shard2 | √ | √ | √ | |||
| config | √ | √ | √ | |||
| mongos | √ | √ | √ |
域名解析
在 3 台虚拟机上分别执行以下 3 条命令,注意替换实际 IP 地址
echo “192.168.1.1 geekdemo1 member1.example.com member2.example.com” >> /etc/hosts
echo “192.168.1.2 geekdemo2 member3.example.com member4.example.com” >> /etc/hosts
echo “192.168.1.3 geekdemo3 member5.example.com member6.example.com” >> /etc/hosts
分片目录
在各服务器上创建数据目录,我们使用 /data,请按自己需要修改为其他目录:
-
在 member1/member3/member5 上执行以下命令:
mkdir -p /data/shard1 mkdir -p /data/config -
在 member2/member4/member6 上执行以下命令:
mkdir -p /data/shard2 mkdir -p /data/mongos
复制集
创建第一个分片用的复制集,在 member1/member3/member5 上执行以下命令::
mongod –bind_ip 0.0.0.0 –replSet shard1 –dbpath /data/shard1 –logpath /data/shard1/mongod.log –port 27010 –fork –shardsvr –wiredTigerCacheSizeGB 1
初始化第一个分片复制集:
mongo --host member1.example.com:27010
rs.initiate({
_id: "shard1",
"members":[
{
"_id": 0,
"host":"member1.example.com:27010"
},
{
"_id": 1,
"host":"member3.example.com:27010"
},
{
"_id": 2,
"host":"member5.example.com:27010"
}
]
});
创建config server复制集,在 member1/member3/member5 上执行以下命令:
mongod –bind_ip 0.0.0.0 –replSet config –dbpath /data/config –logpath /data/config/mongod.log –port 27019 –fork –configsvr –wiredTigerCacheSizeGB 1
初始化config server复制集:
mongo --host member1.example.com:27019
rs.initiate({
_id: "config",
"members":[
{
"_id": 0,
"host":"member1.example.com:27019"
},
{
"_id": 1,
"host":"member3.example.com:27019"
},
{
"_id": 2,
"host":"member5.example.com:27019"
}
]
});
分片配置
在第一台机器geekdemo1上搭建mongos,指向config server:
mongos --bind_ip 0.0.0.0 --logpath /data/mongos/mongos.log --port 27017 --fork --configdb config/member1.example.com:27019,member3.example.com:27019,member5.example.com:27019
链接到mongos,添加分片:
mongo --host member1.example.com:27017
mongos> sh.addShard("shard1/member1.exmple.com:27010,member3.exmple.com:27010,member5.exmple.com:27010");
链接到mongos,创建分片集合创建分片表:
mongo --host member1.example.com:27017
mongos> sh.status();
mongos> sh.enableSharding("foo")
mongos> sh.shardCollection("foo.bar", {_id:"hashed"})
mongos> sh.status();
## 插入测试数据
use foo
for(var i = 0; i< 1000; i++){
db.bar.insert({i:i});
}
分片扩展
原来只有1个分片节点,现在要做2个。
在 member2/member4/member5 上执行以下命令:
mongod –bind_ip 0.0.0.0 –replSet shard2 –dbpath /data/shard2 –logpath /data/shard2/mongod.log –port 27011 –fork –shardsvr –wiredTigerCacheSizeGB 1
初始化第二个分片复制集:
mongo --host member2.example.com:27011
rs.initiate({
_id: "shard2",
"members":[
{
"_id": 0,
"host":"member2.example.com:27011"
},
{
"_id": 1,
"host":"member4.example.com:27011"
},
{
"_id": 2,
"host":"member6.example.com:27011"
}
]
});
加入第2个分片,链接mongos,添加分片:
mongo --host member1.example.com:27017
mongos> sh.addShard("shard2/member2.exmple.com:27011,member4.exmple.com:27011,member6.exmple.com:27011");
mongos> sh.status();
其他阅读
由于集群搭建我并没有实操,而是直接按照极客时间中的步骤进行复制粘贴。
所以如果你对分片集群的搭建有什么疑惑,还可以访问这个链接:点我跳转

 浙公网安备 33010602011771号
浙公网安备 33010602011771号