
树分治(五)——链分治之长链剖分
 .
.
长链剖分
和重链剖分类似,所谓「长链剖分」,就是对每个点取子树内深度最大的一个子节点作为重儿子,其余作为轻儿子。借一下 oi-wiki 上的图:
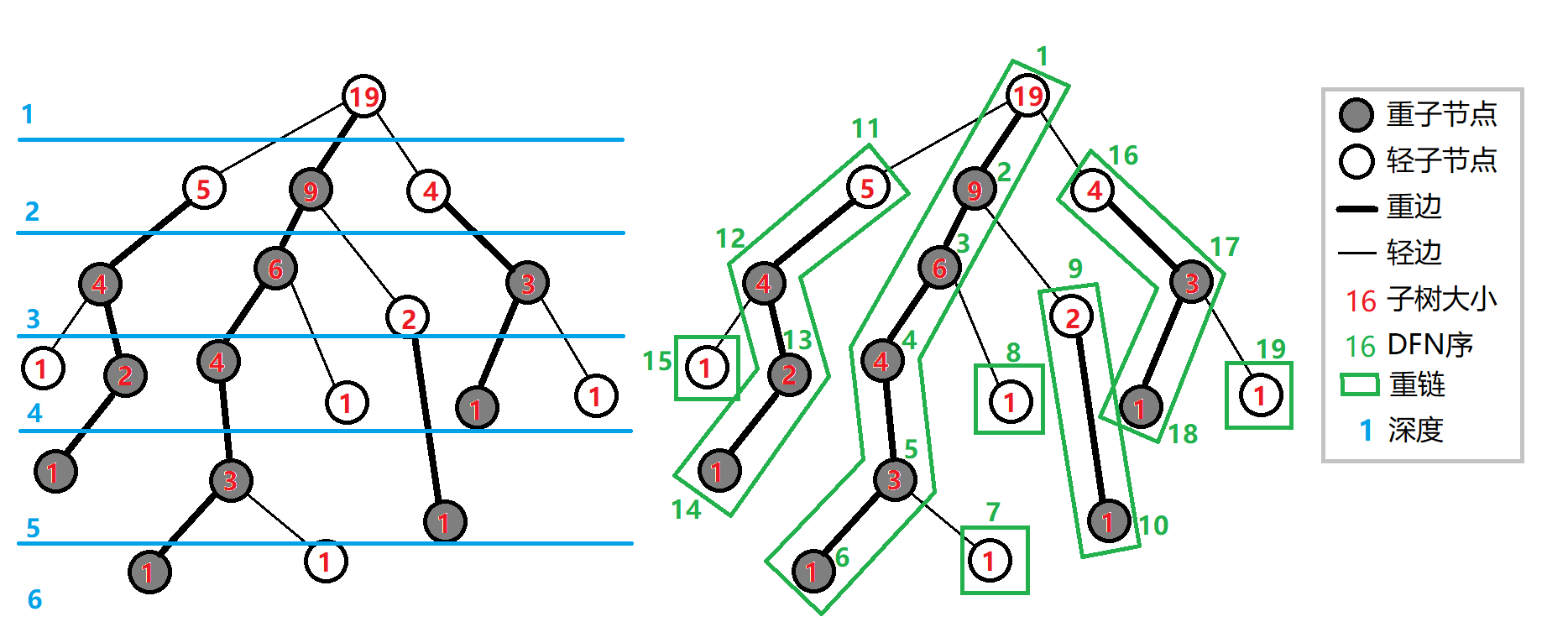
如图,我们每次取了最深的一个子节点作为重儿子,其余均为轻儿子。
相信这些应该很好明白。
重链剖分中一个节点到根的路径上最多有 \(O(\log n)\) 条轻边,那么长链剖分中是否有类似的性质呢?
其实也是有的。由于每次经过一条轻边意味着旁边那条链必然严格大于当前的链长,因此,如果经过了 \(k\) 条轻边,那么就至少要有 \(1+2+\cdots+k=O(k^2)\) 个节点。因此 \(n=O(k^2)\),从而 \(k=O(\sqrt{n})\)。
长链剖分求树上 \(k\) 级祖先
我们先证明一个引理:
\(\text{Lemma.}\) 对于节点 \(x\) 的 \(k\) 级祖先 \(p\),\(p\) 所在重链的长度必然大于等于 \(k\)。
\(\text{Proof.}\) 我们分两种情况讨论。
- 若 \(x\) 与 \(p\) 在一条重链内,显然成立。
- 否则说明 \(p\to x\) 的路径上有至少一次选重儿子时没有选到 \(x\) 这边,因此其一定选了更长的链,那么这条链的长度同样 \(\ge k\)。这就完成了证明。
我们定义 \(\text{Highbit}(x)=\lfloor\log_2 x\rfloor\) ,也就是 \(x\) 二进制位上最高的 \(1\) 的位置。
首先预处理 \(f(x,i)\) 表示 \(x\) 的 \(2^i\) 级祖先,这一步是 \(O(n\log n)\) 的。
接下来,记 \(r=2^{\text{Highbit}(x)}\),我们首先求出 \(x\) 的 \(r\) 级祖先 \(y\)。这一步可以用预处理出的信息做到 \(O(1)\)。
那么现在要求的就是 \(y\) 的 \(k-r\) 级祖先。设这个点为 \(p\)。
由引理可以知道 \(r\) 所在重链长度必然大于等于 \(r\)。
同时显然有 \(r>k-r\),因此我们可以预处理出来每条重链 \(L\) 链顶往上、往下数的 \(\text{Size}(L)\) 个节点(往下指的是往重儿子的方向走,你也可以认为存储的就是 \(L\) 中的所有节点),然后就可以通过 \(y\) 所在链的链顶直接查询到这个 \(k-r\) 级祖先 \(p\) 了。这里 \(\text{Size}(L)\) 指的是重链 \(L\) 的长度。
复杂度为 \(O(n\log n)-O(1)\),但是(至少据我所知)常数挺大而且并不是很常用=_=
长链剖分优化 DP
其实不算优化 DP 吧2333
例题:给定一棵 \(n\) 个节点的树以及一堆询问,每次会给出 \(x,j\),你需要求出来 \(x\) 子树内与 \(x\) 距离不超过 \(j\) 的节点个数。\(1\le n\le 10^6\)。
考虑简单 DP:\(f_{x,j}=[j=0]+\sum_{v\in\text{son}(x)}f_{v,j-1}\)。复杂度 \(O(n^2)\) 过不去。
可以用重链剖分优化,时间复杂度 \(O(n\log n)\)。
我们发现重链剖分的时候每次仍然暴力扫了一遍轻儿子中的所有节点,但是本题中实际需要更新的只有轻儿子所在子树的深度——具体来说,设 \(\text{Maxd}(u)\) 表示 \(u\) 子树内深度最大的点与 \(u\) 的距离,我们实际上对轻儿子需要更新的内容只有 \(O(\text{Maxd}(v))\) 这么多。而这些信息其实在 \(\text{DFS}\) 遍历轻儿子的时候已经算过了。
因此我们考虑每次计算一个节点的时候不要直接清空,而是专门开一片内存存下来这个轻儿子的信息,这样合并的时候就可以直接枚举 \(j\) 然后令 \(f_{u,j}\text{ += }f_{v,j-1}\)。
这时候重链剖分的劣势就体现出来了:比如这个点 \(u\) 有一个儿子底下挂了一个大扫把但是深度很小,你本来只需要一两次合并就能把它合并过来,但是在树上启发式合并里面你仍然跟个憨批一样把这些节点一个一个扫了过去。。
此时不难发现我们应该取 \(\text{Maxd}(v)\) 最大的儿子来继承,可以发现,这就是长链剖分。
清算一下复杂度:我们发现对于一个节点 \(u\),我们会先统计掉以 \(u\) 为链顶的那条长链,然后再暴力统计它的轻儿子。
可以发现每条长链恰好被统计了一次,因此总复杂度 \(O(n)\)。
为什么长链剖分是 \(O(n)\) 而重链剖分就要多个 \(\log\) 呢,看上去每个点到根的路径上有 \(O(\sqrt{n})\) 条轻边明明更劣啊??
我们可以把重链剖分理解为把每个子树以 \(O(\text{size}(x))\) 的代价合并进 \(y\),然后得到一个 \(O(\text{size}(x)+\text{size}(y))\) 的更大的东西。
以后的所有合并,\(\text{size}(x)\) 这一堆都要跟着一起合并,所以就有了“每个点被合并 \(O(\log n)\) 次”这种说法。
而长链剖分呢?对于一条长链 \(x\),我们以 \(O(\text{length}(x))\) 的代价合并进 \(y\),但是得到的东西仍然只有 \(O(\text{length}(y))\)!
也就是说,合并完之后 \(x\) 就被干掉了,相当于每条长链只会被算一次。所有长链和为 \(n\),那么复杂度就是 \(O(n)\)。
这样看来,之所以用长链剖分只是因为这里恰好和深度相关,并且一个信息合并之后不需要再次合并。
使用长剖是因为和深度相关,能用长剖还是因为第二条性质的存在。
讲一下怎么分配内存:网上大多数 blog 都用指针来写继承重儿子,虽然好写但是不好理解也无法处理某些题目=_=
其实数组分配内存还是蛮好写的:我们对每条长链,设链顶为 \(u\),给这一条长链分配 \([\text{DFN}(u),\text{DFN}(u)+\text{length}(u)-1]\) 这段空间。
然后剖分的时候注意一下令每条长链上 \(\text{DFS}\) 序连续就可以了。
长链剖分优化 DP - 例题
CF150E Freezing with Style Present 7.0
我们之前用点分治解决了这道题,但这题其实有长剖的简单做法。我们以这道题为例讲解长链剖分的实现方式。
首先套路地二分答案,然后链分治。枚举当前的 \(\text{LCA}\),设为 \(r\),那么需要选出来两个不同子树内的节点 \(x,y\) 构成一条路径。
仍然考虑简单萌萌 DP :\(f_{x,j}\) 表示 \(x\) 子树内深度为 \(\text{dep}(x)+j\) 的节点 \(y\) 中 \(\text{dist}(x,y)\) 的最大值。
那么 \(f_{x,j}=\max\{f_{v,j-1}+w(x,v)|v\in\text{son}(x)\}\)。这个形式要在继承的时候加一个 \(w(x,v)\),貌似不是很好长剖......?
其实完全没有问题!我们现在要求的是一个长链上的 \(\text{max}\),那么可以直接维护当前点 \(x\) 到链底的边权和 \(g_x\),然后把 \(f_{x,j}-g_x\) 插入线段树再正常比大小就行了。
当然你也可以直接区间修改=_=
我们对 \(r\) 的每个子树分别处理,同时维护一棵线段树来求区间最大值,同时维护单点的修改即可。复杂度 \(O(n\log ^2n)\)。
建议阅读代码:AC Code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号