实验5 文件应用编程
任务1
1_1
with open('data1_1.txt','r',encoding = 'utf-8') as f:
data = f.readlines()
n = 0
for line in data:
if line.strip('\n')=='':
continue
n+=1
print(f'共{n}行')
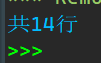
1_2
with open('data1_1.txt','r',encoding = 'utf-8') as f:
n=0
for line in f:
if line.strip('\n')=='':
continue
n+=1
print(f'共{n}行')
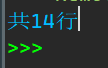
1_3
with open('data1_2.txt','r',encoding = 'utf-8') as f:
n=0
for line in f:
if line.strip() == '':
continue
n+=1
print(f'共{n}行')
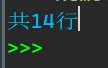
1_4
with open('data1_2.txt','r',encoding = 'utf-8') as f:
n=0
for line in f:
if line.isspace():
continue
n+=1
print(f'共{n}行')
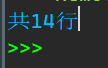
任务2
with open('data2.txt','r',encoding = 'utf-8') as f:
data = f.read().split('\n')
unique_line = []
for line in data:
if data.count(line) == 1:
unique_line.append(line)
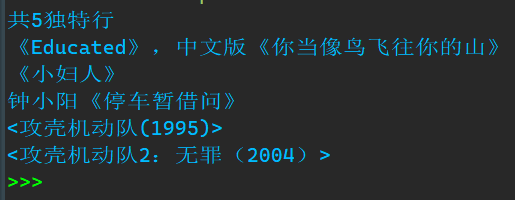
print(f'共{ len(unique_line) }独特行')
for i in unique_line:
print(i)
任务3
l1,l2,data1,data2,data3=[],[],[],[],[]
with open('data3.txt','r',encoding='utf-8') as f:
data=f.readlines()
for i in range(len(data)):
if i==0:
continue
else:
l1.append(round(float(data[i].strip('\n'))))
l2.append(float(data[i].strip('\n')))
l1.insert(0,'四舍五入后数据')
l2.insert(0,'原始数据')
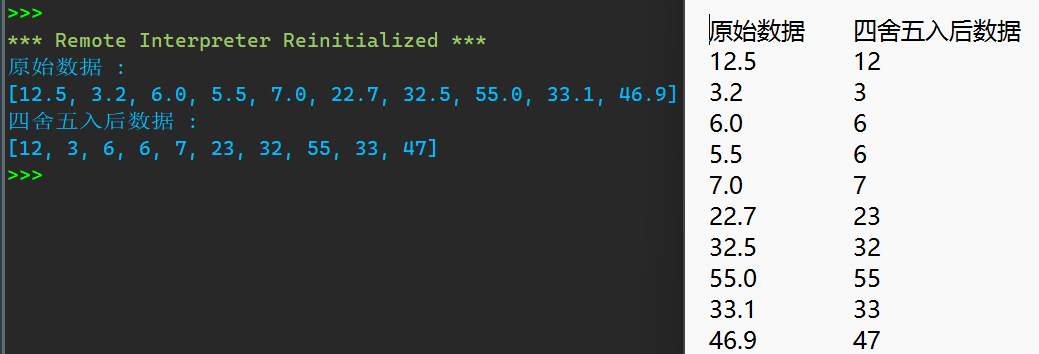
print(l2[0],':')
print(l2[1:])
print(l1[0],':')
print(l1[1:])
for i in l1:
data1.append(str(i))
for i in l2:
data2.append(str(i))
duiqi="{:10}\t{:10}"
with open('data3_processed.txt','w',encoding='utf-8') as f1:
f1.write(duiqi.format(data2[0],data1[0]))
f1.write('\n')
for i in range(1,len(l1)):
f1.write(duiqi.format(data2[i],data1[i]))
f1.write('\n')
任务4
del data[0]
data_new=[]
for line in data:
data_new.append(line.strip('\n'))
shunxu=[]
for line in data_new:
shunxu.append(line.split('\t'))
shunxu1=sorted(shunxu,key=lambda tup:tup[2])
x,tong,sheng=shunxu1[0][2],[],[]
for line in shunxu1:
if line[2]==x:
tong.append(line)
else:
sheng.append(line)
shunxu2=sorted(tong,key=lambda tup:tup[3],reverse=True)
for line in sheng:
shunxu2.append(line)
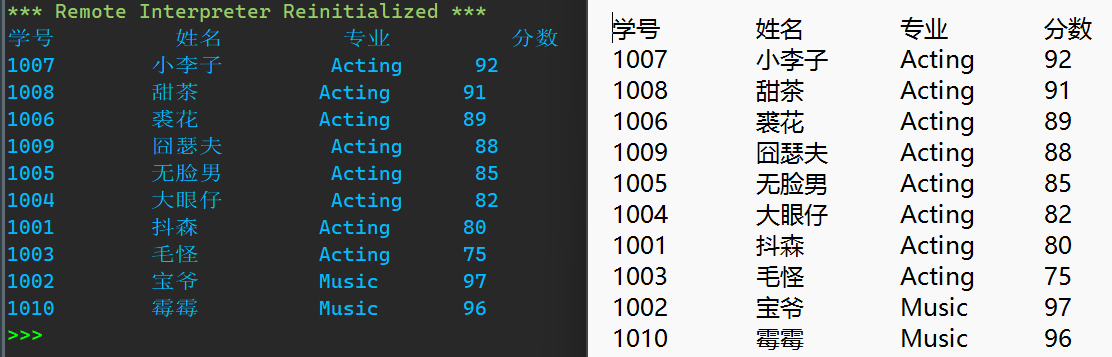
shunxu2.insert(0,['学号','姓名','专业','分数'])
duiqi="{:<10}\t{:<10}\t{:<10}\t{:<10}"
with open('data4_processed.txt','w',encoding='utf-8') as f1:
for line in shunxu2:
f1.write(duiqi.format(line[0],line[1],line[2],line[3]))
f1.write('\n')
for line in shunxu2:
print(duiqi.format(line[0],line[1],line[2],line[3]))
任务5
hangshu,dancishu,konggeshu,zifushu=0,0,0,0
with open('data5.txt','r',encoding='utf-8') as f:
for line in f:
hangshu+=1
danci=line.split()
dancishu+=len(danci)
zifushu+=len(line)
for i in line:
if i.isspace():
konggeshu+=1
konggeshu-=hangshu-1 #除最后一行,其余每行末尾都有一个换行符
with open('data5.txt','r',encoding='utf-8') as f1:
data=f1.readlines()
data1=[str(i+1) for i in range(hangshu)]
data2=[]
for i in range(hangshu):
data2.append(data1[i]+' '+data[i])
with open('data5_with_line_number.txt','w',encoding='utf-8') as f2:
f2.writelines(data2)
print(f'行数{hangshu}')
print(f'单词数{dancishu}')
print(f'空格数{konggeshu}')
print(f'字符数{zifushu}')

实验总结:
1.熟悉文件的操作 f.read()、f.readlines()、f.writelines()
2.对于文件的‘读’,打开一次文件,只能‘读’一次。(做任务5时发现)
3.统计单词数 words=line.split(),len(words)就是一行的单词数。
4.学会了在写入文件时用format格式控制处理对齐问题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号