

项目地址: https://github.com/Ni-Sun/SearchCraft
如果有用记得点个star
项目仅供参考
要求:
(一) 建立并实现文本搜索功能
◼ 利 用 / 调 用 开 源 搜 索 引 擎 Lucene(Apache Lucene - Welcome to Apache Lucene), ElasticSearch(Elasticsearch:官方分布式搜索和分析引擎 | Elastic) 或 者 Lemur(Lemur Project Home)实现文本搜索引擎。查阅相关资料,安装软件。
◼ 对经过预处理后的500个英文和中文文档/网页建立搜索并实现搜索功能。
◼ 通过上述软件对文档建立索引(Indexing),然后通过前台界面或者已提供的界 面,输入关键字,展示搜索结果。
◼ 前台可通过网页形式、应用程序形式、或者利用已有的界面工具显示。
◼ 实现英文搜索及中文搜索功能。
(二) 比较文档之间的相似度
◼ 通过余弦距离(Cosine Distance)计算任意两个文档之间的相似度,列出文档原文,并给出相似度值。
◼ 尝试实现一个文档查重程序。
(三) 对下载的文档,利用K-Means聚类算法进行聚类。
◼ 将下载的500个中文/英文文档聚为20个类,并显示聚类之后所形成的三个最大的类,及每个类中代表性的文档(即,离类中心最近的五个文档)。
◼ 将文档分别聚类成不同数量的类,如:5、10、25、50等,比较聚类结果的异同与变化。
◼ 距离计算公式,可采用余弦距离,也可用欧式距离。
功能
1. 网页爬取与预处理
- 网页爬取:支持爬取网页的 HTML 内容,并对其进行解析和处理。
- 多线程支持:通过多线程技术提升爬取效率。
- 语言支持:兼容中英文网站的爬取和处理。
- 动态限速:根据爬取情况动态调整爬取速度,降低被封禁的风险。
- 智能队列管理:实现队列的智能补充和管理机制。
- 反爬策略:支持代理配置,绕过常见的反爬机制。
- 内容备份:自动保存原始网页内容(如:
xxx_org.txt)。 - 文本预处理:
- 删除特殊字符并统一大小写。
- 中文分词处理。
- 删除中英文停用词。
- 英文文本支持 Porter Stemming 词干提取。
- 简化文档生成:
- 英文文档处理后保存为简化文件(如:
xxx_e.txt)。 - 中文文档处理后保存为简化文件(如:
xxx_c.txt)。
- 英文文档处理后保存为简化文件(如:
- 错误处理:记录爬取失败的 URL,并优雅地处理无法访问的网页。
2. 搜索引擎功能
- 索引构建:
- 基于Elasticsearch建立倒排索引
- 支持中英文混合检索
- 搜索特性:
- 关键词匹配搜索
- 分页结果展示(默认100条)
- 显示URL、语言、抓取时间等元数据
3. 文档分析功能
-
相似度计算:
- 余弦相似度计算文档相似度
- 文档查重功能(可调阈值)
-
文档聚类:
- K-Means聚类算法(支持余弦/欧式距离)
- 多聚类数对比分析(5/10/20/25/50类)
- 自动展示最大五个类簇及代表文档
技术栈
1. 后端框架
- Flask - Web应用框架
- Elasticsearch - 搜索引擎
- scikit-learn - 机器学习库(用于聚类和相似度计算)
2. 爬虫相关
- requests - HTTP请求库
- requests-html - 支持JavaScript渲染的请求库
- beautifulsoup4 - HTML解析
- fake_useragent - 随机User-Agent生成
3. 自然语言处理
- jieba - 中文分词
- nltk - 自然语言处理工具包
- scikit-learn - TF-IDF向量化
4. 开发工具
- elasticsearch-head - ES管理界面
- kibana - 数据可视化工具
项目依赖
python软件包
# 核心依赖
flask==2.0.1
elasticsearch==7.17.0
scikit-learn==1.0.2
# 爬虫相关
requests==2.26.0
requests-html==0.10.0
beautifulsoup4==4.9.3
fake-useragent==0.1.11
# 自然语言处理
jieba==0.42.1
nltk==3.6.3
# 工具库
numpy==1.21.2
pandas==1.3.3
还需要安装elasticsearch, elasticsearch-head, kibana, 相关安装及学习使用可以参考 从 0 到 1 学习 elasticsearch ,这一篇就够了! 讲得很详细
API接口
| 端点 | 方法 | 参数 | 功能 |
|---|---|---|---|
/api/search |
GET | q=关键词 | 执行搜索 |
/api/cluster |
GET | n_clusters=聚类数 | 文档聚类 |
/api/similar/<doc_id> |
GET | threshold=阈值 | 查找相似文档 |
/api/duplicates |
GET | threshold=阈值 | 查找重复文档 |
目录结构
SearchCraft/
├── analysis/ # 文档分析模块
│ ├──templates
│ │ └──index.html # 前端界面
│ ├── app.py # Flask应用主入口
│ ├── routes.py # 路由处理
│ ├── search_service.py # 搜索服务实现
│ ├── document_store.py # 文档存储和管理
│ └── utils.py # 工具函数
│
├── spider/ # 爬虫模块
│ ├── spider.py # 爬虫核心逻辑
│ ├── main.py # 爬虫主程序入口
│ ├── configs.py # 爬虫配置
│ ├── file_manager.py # 文件管理工具
│ ├── general.py # 通用工具函数
│ ├── text_processor.py # 文本处理工具
│ ├── es_client.py # Elasticsearch客户端
│ ├── stopwords.txt # 停用词表
│ ├── link_finder.py # 链接解析工具
│ └── domain.py # 域名解析工具
│
├── crawler/ # 爬取数据存储(结构化存储)
│ ├── zh/ # 中文网站
│ │ └── [website]/ # 具体网站域名目录(如:baidu.com)
│ │ └── downloads/
│ │ ├── original/ # 原始抓取文件(_org.txt)
│ │ └── processed/ # 清洗后中文内容(_c.txt)
│ └── en/ # 英文网站
│ └── [website]/ # 具体网站域名目录(如:wikipedia.org)
│ └── downloads/
│ ├── original/ # 原始抓取文件(_org.txt)
│ └── processed/ # 清洗后英文内容(_e.txt)
│
├── img/ # 项目图片资源
├── venv/ # Python虚拟环境
├── README.md # 项目说明文档
└── .gitignore # Git忽略文件
配置
配置要爬取哪些网站在 configs.py 中修改
部分网页较好爬取,爬取失败率较低, 爬取速度较快; 部分网页不好爬取,爬取失败率较高, 爬取速度较慢(可能会存在 有acb_org.txt文件, 但是没有abc_c.txt文件 的情况)
有的网站无法爬取, 如非必要, 可以换个网站爬取
注意, 部分英文网站可能需要挂代理才能爬
运行
- 首先在elasticsearch安装目录下的bin目录下, 运行elasticsearch.bat(双击即可运行)
- 然后在elasticsearch-head的安装目录下, 命令行运行
npm start(调试需要, 用于Web界面查看数据) - 再在kibana的安装目录下的bin目录下, 运行kibana.bat(双击即可运行)(调试需要, 用于高级数据可视化/分析)
以上都是前置要求, 如果不需要调试, 只是运行代码, 那么可以只启动elasticsearch.bat - 运行爬虫模块 spider/main.py , 爬取网站获取数据, 并建立elasticsearch索引
- 启动分析服务 analysis/app.py
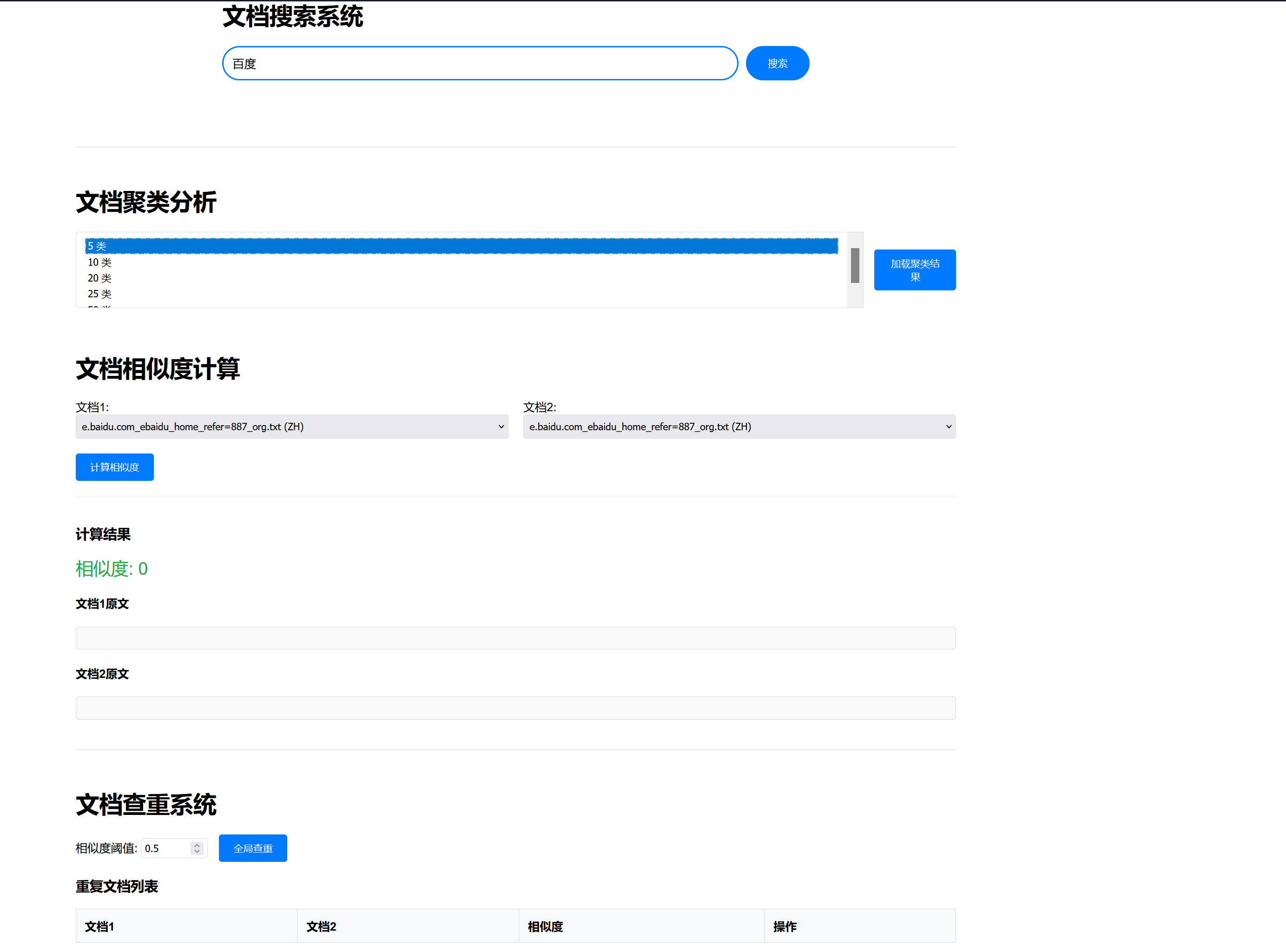
- 访问web界面 http://127.0.0.1:5000/应该显示类似下面的界面
![在这里插入图片描述]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号