fastapi
FastAPI 框架快速学习
概述
FastAPI 是一个用于构建 API 的现代、高性能 Python Web 框架,基于 Starlette(ASGI Web 服务器)和 Pydantic(数据验证与序列化)。
核心特性:
- ✅ 极高性能:得益于 Starlette 和 Pydantic,性能与 NodeJS 和 Go 相当。
- ✅ 高效开发:自动交互式文档 + 类型提示支持,提升开发速度 200–300%。
- ✅ 更少错误:类型系统减少约 40% 的人为错误。
- ✅ 生产就绪:自动生成 OpenAPI 文档,支持认证、中间件、依赖注入等完整生态。
- ✅ 异步原生:全面支持
async/await,轻松处理高并发场景。
一、快速开始
安装与基础使用
pip install fastapi uvicorn
from fastapi import FastAPI
app = FastAPI(docs_url=None, # 禁用 Swagger UI(/docs)
redoc_url=None, # 禁用 ReDoc(/redoc)
)
@app.get("/")
async def root():
return {"message": "Hello World"}
# 直接运行
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="127.0.0.1", port=8000, reload=True)
运行后访问:
http://127.0.0.1:8000—— API 端点http://127.0.0.1:8000/docs—— 自动交互式 Swagger UI 文档http://127.0.0.1:8000/redoc—— ReDoc 风格文档
💡 提示:
uvicorn.run()中的reload=True仅用于开发环境,生产环境应关闭。
自定义swagger的js与css
访问docs需要加载js和css,有时候访问公网的cdn会比较卡,导致页面经常无法使用.
自定义js和css的路径需要下面4个操作
# main.py
from fastapi import FastAPI
from fastapi.staticfiles import StaticFiles
from fastapi.openapi.docs import get_swagger_ui_html
from contextlib import asynccontextmanager
# 如果你有 lifespan,保留它
@asynccontextmanager
async def lifespan(app: FastAPI):
# 启动逻辑
yield
# 关闭逻辑
app = FastAPI(
title="Young",
description="Young主页",
# 1:禁用默认 /docs
docs_url=None,
redoc_url=None, # 可选:如果你也想自定义 Redoc
lifespan=lifespan,
)
# 2. 挂载静态文件
app.mount("/static", StaticFiles(directory="static"), name="static")
# 3. 自定义 /docs 路由
@app.get("/mydocs", include_in_schema=False)
async def custom_swagger_ui_html():
return get_swagger_ui_html(
openapi_url=app.openapi_url,
title=app.title + " - Swagger UI",
# 4. 下载好swagger-ui-bundle.js和swagger-ui.css存放到下面的静态文件路径中
swagger_js_url="/static/js/swagger-ui-bundle.js",
swagger_css_url="/static/css/swagger-ui.css",
)
二、路径操作
支持多种 HTTP 方法
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id: int):
return {"item_id": item_id}
@app.post("/items/")
async def create_item(item: dict):
return {"item": item}
@app.put("/items/{item_id}")
async def update_item(item_id: int, item: dict):
return {"item_id": item_id, "updated_item": item}
@app.delete("/items/{item_id}")
async def delete_item(item_id: int):
return {"message": f"Item {item_id} deleted"}
路由分组与组织
# users.py —— 生产环境中写到单独 app 下的 urls 或 routers 中
from fastapi import APIRouter
user_router = APIRouter(prefix="/users", tags=["Users"])
@user_router.get("/")
async def get_users():
return [{"id": 1, "name": "John"}]
@user_router.get("/{user_id}")
async def get_user(user_id: int):
return {"id": user_id, "name": "John"}
# main.py
from fastapi import FastAPI
app = FastAPI()
app.include_router(user_router)
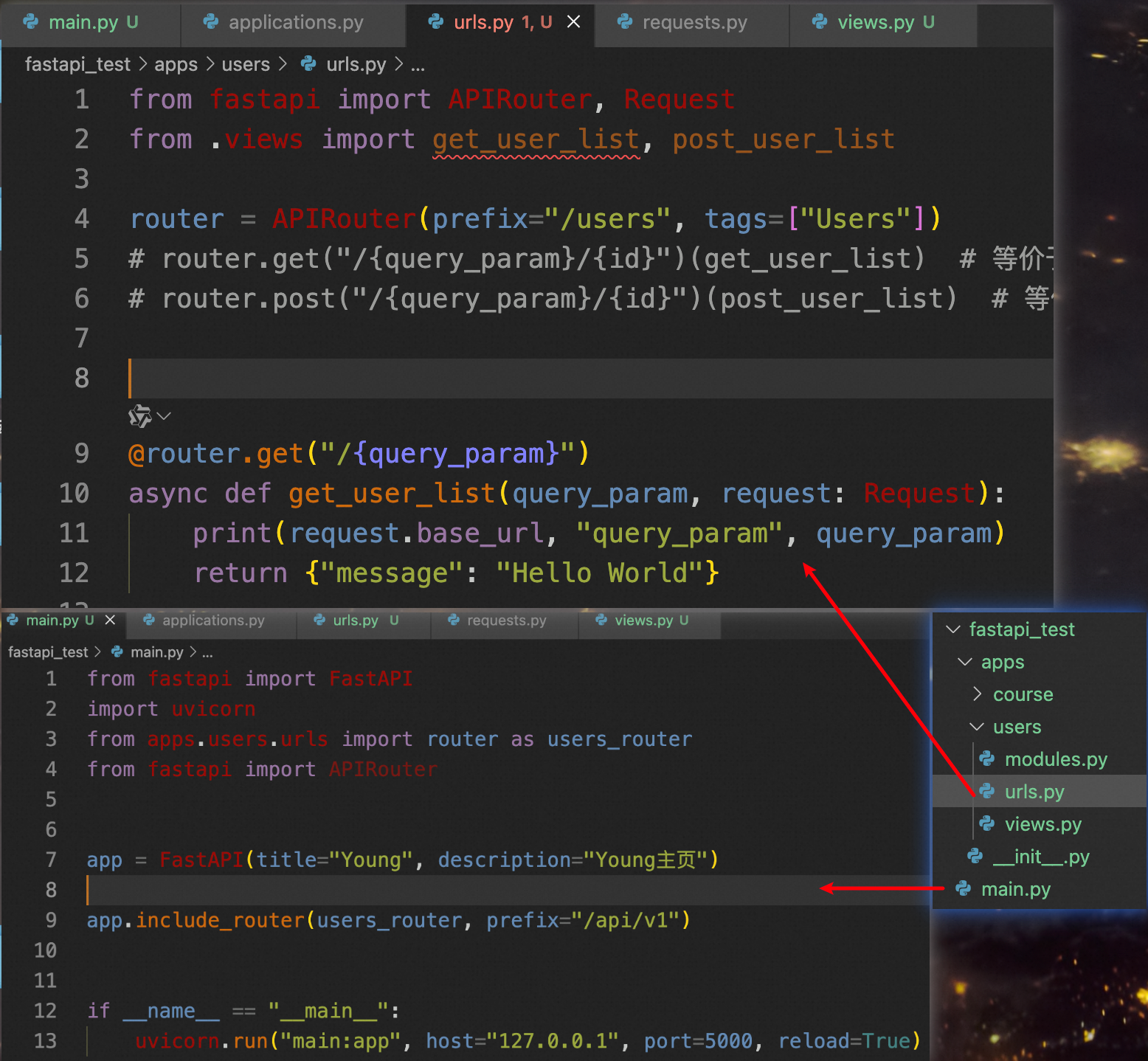
路由视图的2种写法
推荐用这种和django的写法类似

写法2,路由装饰器在视图函数上
这种将路由和视图写在一起
三、请求处理
路径参数与查询参数
from typing import Optional
from fastapi import Query
@app.get("/users/{user_id}")
async def read_user(
user_id: int, # 路径参数
skip: int = 0, # 查询参数,有默认值
limit: Optional[int] = 10, # 可选查询参数
search: Optional[str] = None # 可选搜索参数
):
return {"user_id": user_id, "skip": skip, "limit": limit, "search": search}
#除了上面的类型校验,还可以用Query进行校验
#Query 是一个用于声明和校验查询参数(query parameters)的工具。它属于 FastAPI 的 依赖注入系统 和 数据校验机制 的一部分,底层基于 Pydantic。
@app.get("/items/")
def read_items(
q: str = Query(
default=None, # default=..., 必填和默认值互斥
min_length=3,
max_length=50,
regex=r"^[a-zA-Z0-9_]+$",
title="swagger文档的标题栏",
description="swagger文档的详情介绍栏",
),
limit: int = Query(default=10, ge=1, le=100)
):
return {"q": q, "limit": limit}
请求体与 Pydantic 模型
from pydantic import BaseModel, EmailStr
from typing import List, Optional
class Item(BaseModel):
name: str
description: Optional[str] = None
price: float
tags: List[str] = []
class User(BaseModel):
email: EmailStr
password: str
@app.post("/items/")
async def create_item(item: Item):
return item
@app.post("/users/")
async def create_user(user: User):
# 密码应该哈希处理,这里仅为示例
return {"email": user.email, "message": "User created"}
Pydantic 字段校验
| 装饰器 | 作用 | 是否参与输入 | 是否参与输出 | 典型用途 |
|---|---|---|---|---|
| @field_validator | 字段验证/预处理 | ✅ 是 | ❌ 否 | 类型转换、范围检查 |
| @model_validator(mode='before') | 模型预处理 | ✅ 是 | ❌ 否 | 数据清洗、补全 |
| @model_validator(mode='after') | 模型后验证 | ✅ 是 | ❌ 否 | 跨字段校验 |
| @computed_field | 计算属性(只读) | ❌ 否 | ✅ 是 | 输出衍生字段(如 area, full_name) |
| @field_serializer | 自定义字段输出 | ❌ 否 | ✅ 是 | 格式化时间、隐藏字段 |
| @model_serializer | 自定义整个模型输出 | ❌ 否 | ✅ 是 | 包装成 {status, data} 结构 |
from pydantic import BaseModel, field_validator, model_validator
from pydantic import computed_field, field_serializer, model_serializer
from datetime import timezone, timedelta
class UserCreate(BaseModel):
password: str
confirm_password: str
@field_validator("confirm_password",mode='before')
@classmethod
def passwords_match(cls, v, info):
if "password" in info.data and v != info.data["password"]:
raise ValueError("两次密码不一致")
return v
@model_validator(mode='after') # after是模型后验证
def passwords_match(self):
if self.password != self.confirm_password:
raise ValueError("两次密码不一致")
return self
# tortoise不会自动转时区,可以在序列化中实现
BEIJING_TZ = timezone(timedelta(hours=8))
class Log(BaseModel):
timestamp: datetime
# 控制某个字段如何被 .model_dump() 或 model_dump_json() 输出。
@field_serializer('timestamp')
def serialize_ts(self, value: datetime):
return value.astimezone(BEIJING_TZ).strftime('%Y-%m-%d %H:%M:%S')
class Rectangle(BaseModel):
width: float
height: float
#通常是基于其他字段计算而来。
@computed_field
@property
def area(self) -> float:
return self.width * self.height
@computed_field
@property
def is_square(self) -> bool:
return self.width == self.height
from pydantic import model_serializer
class UserOut(BaseModel):
username: str
roles: list[str]
@model_serializer
def serialize(self):
return {
"status": 200,
"detail": self.model_dump()
}
# 调用 user_out.model_dump() 会直接返回:
{
"status": 200,
"detail": {
"username": "alex",
"roles": ["admin"]
}
}
字段定义模式(模式总结)
以下是 Python + Pydantic + 框架开发中常见的 字段定义模式,每种都有固定语法结构。
✅ 模式 1:【普通字段】基本 Pydantic 字段定义
class User(BaseModel):
name: str
age: int = 30
- ✅ 语法结构:
field_name: type = default_value # 可选 - 🔧 用途:定义数据模型的字段
- 📌 特点:支持类型推断、校验、序列化
✅ 模式 2:【带描述的字段】使用 Field(...)
class CarAccountInput(BaseModel):
a: str = Field(..., description="账号名称", min_length=2)
b: str = Field(default="", description="车信息")
- ✅ 语法结构:
field_name: type = Field(default, description="...", **metadata) - 🔧 用途:添加元数据(用于生成 OpenAPI/Swagger/Tool Schema)
- 📌 特点:
...表示必填;default表示可选
✅ 模式 3:【类变量】框架级配置属性(如 args_schema, name)
class MyTool(BaseTool):
name: str = "my_tool"
description: str = "这是一个工具"
args_schema: Type[BaseModel] = CarAccountInput
- ✅ 语法结构:
attr_name: type_annotation = value - 🔧 用途:不是实例字段,而是类级别的配置项
- 📌 特点:简单的理解args_schema这个变量应该是一个类,而不是字段,简化写法args_schema = CarAccountInput,这个简化写法会忽略校验,比如不会校验是否是BaseModel的子类,不严谨
✅ 模式 4:【带 reducer 的状态字段】LangGraph 特有写法
from langgraph.graph.message import add_messages
class State:
messages: Annotated[Sequence[BaseMessage], add_messages]
- ✅ 语法结构:
field_name: Annotated[type, reducer_func] - 🔧 用途:告诉 LangGraph 如何合并状态更新
- 📌 特点:
Annotated是 Python 标准库typing.Annotated- 第一个参数是类型,第二个是元数据(这里是 reducer 函数)
✅ 模式 5:【泛型字段】复杂结构定义
from typing import List, Optional
class BatchInput(BaseModel):
users: List[User]
note: Optional[str] = None
- ✅ 语法结构:
field: List[SomeModel] field: Optional[str] field: Dict[str, int] - 🔧 用途:定义嵌套结构
- 📌 特点:Pydantic 自动递归校验
✅ 模式 6:【动态类变量】用于运行时注入(高级)
class ApiTool(BaseTool):
base_url: str = "https://api.example.com"
def __init__(self, base_url: str, **kwargs):
super().__init__(**kwargs)
self.base_url = base_url # 动态设置
- ✅ 语法结构:
class_attr: type = default # 或通过 __init__ 动态赋值 - 🔧 用途:创建可配置的工具实例
- 📌 特点:适合多租户、不同环境调用
总结:常见语法模式一览表
| 模式 | 典型写法 | 用途 | 是否 Pydantic 原生? |
|---|---|---|---|
| 1. 普通字段 | name: str |
数据建模 | ✅ 是 |
| 2. 带描述字段 | name: str = Field(..., description="...") |
API 文档生成 | ✅ 是 |
| 3. 类变量配置 | name: str = "tool"args_schema: Type[BaseModel] = Model |
工具元信息 | ❌ 否(LangChain 约定) |
| 4. Annotated reducer | messages: Annotated[List[Msg], add_messages] |
状态合并 | ❌ 否(LangGraph 约定) |
| 5. 泛型结构 | users: List[User] |
嵌套数据 | ✅ 是 |
| 6. 动态属性 | self.base_url = url in __init__ |
可配置工具 | ✅ 半原生 |
Pydantic 字段校验自定义输出orm输出格式
我们再输出的字段中需要自定义输出的内容,受限在basemodel子类中定义 from_attributes = True
class UserOut(BaseModel):
status_code: int = 400
id: int
username: str
email: str
created_at: datetime
@field_serializer("created_at")
def serialize_datetime(self, value: datetime | None) -> str | None:
if value is None:
return None
return value.strftime("%Y-%m-%d %H:%M:%S")
# 新版本写法
model_config = {"from_attributes": True} # 支持从 ORM 对象(如 Tortoise)转换
# 老版本写法 已废弃
class Config:
from_attributes = True # Tortoise 兼容 ORM Mode v1版本使用orm_mode=True
class status(BaseModel):
status_code: int = 400
reason: str = ""
response: Union[UserOut, str] = ""
额外知识
Pydantic 在创建模型时会自动读取class Config,虽然 class Config 仍然支持,但 Pydantic v2 更推荐使用 model_config 字典
某些配置也比较实用
model_config = ConfigDict(
from_attributes=True, # 替代 orm_mode
str_strip_whitespace=True,
extra='forbid'
)
比如 str_strip_whitespace 自动去除字符串字段前后的空白字符(空格、制表符、换行等)
extra 是控制模型如何处理 “额外字段”(即定义中没有的字段)一共有allow,ignore,forbid三种模式 默认是ignore 忽略处理,不抛异常也不获取该字段
然后获取到了orm对象
# 这里ret是orm的查询对象
ret = await User.filter(id=query_id).get()
final_ret = status(status_code=200, response=UserOut.model_validate(ret))
输出结果如下
{
"status_code": 200,
"reason": "",
"response": {
"status_code": 400,
"id": 1,
"username": "Young",
"email": "Young@sina.com",
"created_at": "2025-09-13 22:27:13"
}
}
Pydantic 的序列化和反序列化
model_dump() 和 model_validate() 是 Pydantic v2 中两个核心但用途完全相反的方法,分别用于 序列化(输出) 和 反序列化(输入)。
一句话总结
| 方法 | 方向 | 作用 | 类比 |
|---|---|---|---|
model_validate(data) |
外部数据 → Pydantic 模型 | 验证 + 解析输入(如请求体、数据库对象) | “加载”、“解析” |
model_dump() |
Pydantic 模型 → Python 原生数据 | 序列化输出(如返回 JSON、存日志) | “导出”、“转字典” |
详细对比
model_validate(data)—— 输入处理(反序列化)
- 用途:把外部数据(dict、ORM 对象、JSON 等)转换成一个 合法的 Pydantic 模型实例
- 会做:
- 类型检查(如
"123"→int) - 字段验证(如长度、范围、正则)
- 默认值填充
- 自定义验证器(
@field_validator)
- 类型检查(如
- 输入类型:
dict- ORM 对象(需启用
from_attributes=True) - 其他具有属性的对象
- 输出:
YourModel的实例
💡 如何在输入时忽略某些字段?
Pydantic 默认会忽略输入中模型未定义的字段(即“额外字段”),前提是模型配置为extra='ignore'(这是默认行为)。
如果你希望显式禁止额外字段,可设model_config = ConfigDict(extra='forbid');若想保留并动态处理,可用extra='allow'。
但注意:无法在model_validate()调用时临时忽略某个已定义字段的输入——因为字段一旦定义,就会参与验证。
若某字段不应从外部传入(如仅内部计算),应将其设为init=False并提供默认值或通过其他方式赋值。
使用场景
- 接收 HTTP 请求体(FastAPI 自动调用)
- 从数据库 ORM 对象构建 Pydantic 模型
- 解析配置文件、JSON 字符串等
示例
from pydantic import BaseModel, ConfigDict
class User(BaseModel):
model_config = ConfigDict(extra='ignore') # 默认行为,可省略
name: str
age: int
# 输入包含多余字段 'role',会被自动忽略
data = {"name": "Alice", "age": "30", "role": "admin"}
user = User.model_validate(data)
print(user) # name='Alice' age=30 (无 role)
model_dump()—— 输出处理(序列化)
- 用途:把 Pydantic 模型实例转换成 纯 Python 数据结构(通常是 dict),便于 JSON 序列化
- 会做:
- 转换为原生类型(
datetime→ ISO 字符串) - 包含
@computed_field字段 - 排除 exclude 字段(可选)
- 支持模式(如
mode='json'处理非 JSON 安全类型)
- 转换为原生类型(
- 输入:Pydantic 模型实例(
self) - 输出:
dict(或 JSON-safe dict)
💡 如何在输出时过滤某些字段?
有三种常用方式:
- 调用时排除:使用
model_dump(exclude={'password', 'secret_key'})- 字段级配置:在字段定义时设置
Field(exclude=True),该字段默认不会出现在model_dump()输出中- 组合控制:结合
include和exclude实现精细控制(如只输出部分字段)注意:
exclude不影响@computed_field,除非显式排除其名称。
使用场景
- 返回 API 响应(FastAPI 自动调用)
- 记录日志
- 存入缓存(如 Redis)
- 转为 JSON 字符串前的中间步骤
示例
from pydantic import BaseModel, Field, computed_field
from datetime import datetime
class User(BaseModel):
name: str
age: int
password: str = Field(exclude=True) # 默认不输出
created_at: datetime
@computed_field
@property
def is_adult(self) -> bool:
return self.age >= 18
user = User(name="Alice", age=30, password="secret123", created_at=datetime.now())
# 默认 dump:password 被排除
print(user.model_dump())
# {'name': 'Alice', 'age': 30, 'created_at': ..., 'is_adult': True}
# 显式排除更多字段
print(user.model_dump(exclude={'is_adult'}))
# {'name': 'Alice', 'age': 30, 'created_at': ...}
# 只包含指定字段
print(user.model_dump(include={'name', 'is_adult'}))
# {'name': 'Alice', 'is_adult': True}
对比示例(完整流程)
from pydantic import BaseModel, Field, ConfigDict, computed_field
from datetime import datetime
class User(BaseModel):
model_config = ConfigDict(extra='ignore')
name: str
age: int
password: str = Field(exclude=True) # 输出时自动隐藏
created_at: datetime
@computed_field
@property
def is_adult(self) -> bool:
return self.age >= 18
# 1. 输入:外部数据 → 模型(验证 + 解析)
raw_data = {
"name": "Bob",
"age": "25",
"password": "123456",
"created_at": "2025-01-01T10:00:00Z",
"extra_field": "ignored" # 被忽略(因 extra='ignore')
}
user = User.model_validate(raw_data) # ✅ 成功,age 被转为 int
# 2. 输出:模型 → 字典(序列化,自动排除 password)
output = user.model_dump()
print(output)
# {
# 'name': 'Bob',
# 'age': 25,
# 'created_at': datetime(2025, 1, 1, 10, 0, tzinfo=timezone.utc),
# 'is_adult': True ← computed_field 自动包含!
# }
# 手动进一步排除 computed 字段
safe_output = user.model_dump(exclude={'is_adult'})
# password 仍不会出现(因 Field(exclude=True))
# 转 JSON(FastAPI 内部会做这一步)
import json
json_response = json.dumps(output, default=str)
总结表格
| 特性 | model_validate(data) |
model_dump() |
|---|---|---|
| 方向 | 外部 → 模型 | 模型 → 外部 |
| 输入 | dict / ORM 对象 / etc. | self(模型实例) |
| 输出 | 模型实例 | dict |
| 是否验证 | ✅ 是 | ❌ 否(只输出) |
| 是否转换类型 | ✅ 是(如 str→int) | ✅ 是(如 datetime→str) |
是否包含 @computed_field |
❌ 否 | ✅ 是 |
| FastAPI 用途 | 解析请求体 | 序列化响应体 |
| 忽略/过滤字段方式 | 通过 model_config.extra 控制额外字段行为 |
通过 exclude= 参数或 Field(exclude=True) |
表单数据处理
需要提前安装:pip install python-multipart
from fastapi import Form
@app.post("/login/")
async def login(username: str = Form(...), password: str = Form(...)):
return {"username": username}
文件上传
from fastapi import UploadFile, File
from typing import List
@app.post("/upload/")
async def upload_file(file: UploadFile = File(...)):
return {"filename": file.filename}
@app.post("/upload-multiple/")
async def upload_multiple_files(files: List[UploadFile] = File(...)):
return {"filenames": [file.filename for file in files]}
⚠️ 重要说明:
File(...)会将文件直接读入内存,不适合大文件上传。- 推荐使用
UploadFile对象进行流式写入,避免内存溢出。
@app.post("/upload-stream/")
async def upload_stream(file: UploadFile = File(...)):
with open(f"uploads/{file.filename}", "wb") as f:
while chunk := await file.read(8192): # 每次读取 8KB
f.write(chunk)
return {"filename": file.filename, "status": "uploaded"}
四、响应处理
响应模型与过滤
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
description: str | None = None
price: float
tax: float = 10.5
tags: list[str] = []
items = {
"foo": {"name": "Foo", "price": 50.2},
"bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2},
"baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []},
}
@app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True)
async def read_item(item_id: str):
return items[item_id]
✅
response_model_exclude_unset=True:仅返回实际设置的字段,忽略默认值。
五、数据库集成(Tortoise ORM + Aerich)
5.1 安装依赖
# 核心 ORM
pip install tortoise-orm
# 异步数据库驱动(任选其一)
pip install aiosqlite # SQLite(推荐开发)
pip install asyncpg # PostgreSQL
pip install asyncmy # MySQL(性能优于 aiomysql)
# 数据库迁移工具
pip install aerich
5.2 多 App 的 Tortoise ORM 配置(3 个 apps 示例)
假设项目结构如下:
project/
├── main.py
├── config.py
├── apps/
│ ├── user/
│ │ └── models.py
│ ├── blog/
│ │ └── models.py
│ └── product/
│ └── models.py
└── migrations/
✅ config.py 中的配置(支持多 app)
# config.py
TORTOISE_ORM = {
"connections": {
# 开发环境:SQLite
"default": "sqlite://db.sqlite3",
# 生产环境(示例):
# "default": "postgres://user:password@localhost:5432/myapp_prod"
},
"apps": {
"user": {
"models": ["apps.user.models", "aerich.models"], # 必须包含 aerich.models
"default_connection": "default",
},
"blog": {
"models": ["apps.blog.models"],
"default_connection": "default",
},
"product": {
"models": ["apps.product.models"],
"default_connection": "default",
},
},
}
✅ 关键说明:
- 每个 app 可以拥有自己的模型模块,但通常共用一个数据库连接(
default_connection)。aerich.models只需在一个 app 中声明即可(建议放在第一个 app,如user),否则会报重复表错误。- 如果你希望不同 app 使用不同数据库(分库),可为每个 app 配置不同的
connection名称。
5.3 注册到 FastAPI 并确保优雅关闭
✅ main.py
# main.py
from fastapi import FastAPI
from config import TORTOISE_ORM
from tortoise.contrib.fastapi import register_tortoise
app = FastAPI(title="My Multi-App FastAPI")
# 注册 Tortoise ORM 到 FastAPI
register_tortoise(
app,
config=TORTOISE_ORM,
generate_schemas=False, # 由 Aerich 控制建表,禁止自动建表
add_exception_handlers=True,
)
✅
register_tortoise自动处理了以下事情:
- 启动时调用
Tortoise.init()- 关闭时自动调用
Tortoise.close_connections(),确保连接安全释放- 添加数据库异常处理器(如 IntegrityError → HTTP 422)
因此,无需手动编写 startup/shutdown 事件,除非有特殊需求。
5.4 全局使用模型
在任意地方(如路由、服务层)直接导入模型即可使用:
# apps/user/routes.py
from apps.user.models import User
from apps.blog.models import Blog
async def get_user_with_blogs(user_id: int):
return await User.get(id=user_id).prefetch_related("blogs")
Tortoise ORM 在 init 后会自动注册所有模型,全局可用。
5.5 Aerich 迁移:生产环境修改表名/字段
Aerich 基于模型差异生成迁移脚本,支持重命名表、字段、添加索引等操作。
步骤 1:初始化 Aerich(首次)
aerich init -t config.TORTOISE_ORM
aerich init-db
会在项目根目录生成
aerich.ini和migrations/目录。
步骤 2:修改模型(例如重命名字段)
假设原 User 模型:
# apps/user/models.py
class User(Model):
id = fields.IntField(pk=True)
name = fields.CharField(max_length=50) # 要改成 username
修改为:
class User(Model):
id = fields.IntField(pk=True)
username = fields.CharField(max_length=50) # 字段名变更
步骤 3:生成迁移脚本
aerich migrate --name rename_user_name_to_username
对应django的makemigrations
Aerich 会检测到字段名变化,自动生成包含
ALTER TABLE ... RENAME COLUMN的迁移脚本(PostgreSQL/MySQL 支持,SQLite 有限支持)。
步骤 4:应用迁移(生产环境执行)
aerich upgrade
对应django的migrate
步骤 5:迁移回滚
aerich downgrade [version] 这里的version是指migration文件下的历史迁移文件的第一个索引
比如文件下有如下几个历史变更记录
0_init.py
1_add_email.py
2_rename_user.py
那么version就是这里面开头的数字 0,1,2
所有的历史迁移记录在数据库中是存在aerich这个表中
🔁 补充:常用 Aerich 命令详解
| 命令 | 说明 |
|---|---|
aerich init -t config.TORTOISE_ORM |
初始化迁移系统,指定配置路径 |
aerich migrate --name your_migration_name |
生成新的迁移脚本(基于模型变更) |
aerich upgrade |
应用所有未执行的迁移 |
aerich downgrade |
回滚最近一次迁移 |
aerich downgrade -n 2 |
回滚最近 2 次迁移 |
aerich history |
查看所有迁移历史(按时间顺序) |
aerich heads |
查看当前最新迁移版本(HEAD) |
aerich current |
显示当前数据库所处的迁移版本 |
aerich merge |
合并多个分支迁移(高级用法,较少使用) |
💡 回滚注意事项:
downgrade依赖迁移文件中的downgrade()函数是否正确实现。- 若你手动编辑过迁移脚本,请务必同步维护
downgrade()逻辑,否则回滚可能失败或数据丢失。
5.6 分库配置示例:不同 App 使用不同数据库
有时业务需要将用户数据与商品数据分离到不同数据库(如读写分离、微服务拆分等),Tortoise ORM 支持多连接(multi-connection)。
✅ 配置示例:config.py
# config.py
TORTOISE_ORM = {
"connections": {
# 用户库(PostgreSQL)
"user_db": "postgres://user:pass@localhost:5432/user_service",
# 博客库(MySQL)
"blog_db": "mysql://bloguser:blogpass@db.host:3306/blog_service",
# 商品库(SQLite,仅用于演示)
"product_db": "sqlite://products.sqlite3",
},
"apps": {
"user": {
"models": ["apps.user.models", "aerich.models"],
"default_connection": "user_db",
},
"blog": {
"models": ["apps.blog.models"],
"default_connection": "blog_db",
},
"product": {
"models": ["apps.product.models"],
"default_connection": "product_db",
},
},
}
✅ 模型定义(无需改动)
各 app 的模型代码保持不变,例如:
# apps/user/models.py
from tortoise.models import Model
from tortoise import fields
class User(Model):
id = fields.IntField(pk=True)
username = fields.CharField(max_length=50)
Tortoise 会根据 default_connection 自动将 User 表创建在 user_db 中。
✅ Aerich 迁移分库支持
Aerich 默认只管理一个连接。若需对多个数据库分别迁移,需为每个库单独初始化:
# 初始化用户库迁移
aerich init -t config.TORTOISE_ORM --app user
# 初始化博客库迁移(需指定不同目录,避免冲突)
mkdir migrations_blog
aerich init -t config.TORTOISE_ORM --app blog --location ./migrations_blog
⚠️ 注意:Aerich 当前(v0.7+)对多数据库迁移支持较弱,官方推荐每个数据库独立维护一套迁移目录和配置。生产中若需强分库,可考虑:
- 为每个服务部署独立的 FastAPI + 独立数据库 + 独立 Aerich 配置
- 或使用 Alembic(SQLAlchemy)等更成熟的多库迁移方案
5.7 常见问题与最佳实践
| 问题 | 解决方案 |
|---|---|
aerich.models 重复注册 |
只在一个 app 的 models 列表中包含它 |
SQLite 不支持 RENAME COLUMN |
生产环境避免使用 SQLite;或接受 Aerich 的“重建表”策略 |
| 多数据库(分库) | 在 connections 中定义多个连接,每个 app 指定 default_connection |
| 迁移失败回滚 | 使用 aerich downgrade,确保 downgrade() 函数正确实现 |
✅ 总结:关键配置清单
- ✅
TORTOISE_ORM中每个 app 独立配置模型路径 - ✅ 仅一个 app 包含
"aerich.models" - ✅ 使用
register_tortoise(..., generate_schemas=False)禁用自动建表 - ✅ 用
aerich migrate+aerich upgrade管理结构变更 - ✅ 生产环境优先选择 PostgreSQL / MySQL,避免 SQLite 限制
- ✅ 分库时为每个 app 指定不同的
default_connection - ✅ Aerich 多库迁移需手动管理多个迁移目录
📌 最后提醒:Aerich 的迁移能力依赖于底层数据库的 DDL 支持。对于重命名表/字段这类操作,请务必在非 SQLite 环境中进行,或提前备份数据。
5.8 模型定义与级联规则
from tortoise.models import Model
from tortoise import fields
from tortoise.fields.relational import ReverseRelation
class User(Model):
id = fields.IntField(pk=True)
username = fields.CharField(max_length=50, unique=True)
email = fields.CharField(max_length=100, null=True)
created_at = fields.DatetimeField(auto_now_add=True)
# 这不是实际的字段,而是 类型提示(type hint),用于告诉 IDE 或类型检查器(如 mypy):User 实例可以通过 .blogs 访问其关联的 Blog 对象集合。
# 是一个“虚拟”的属性,由 Blog.author 的 related_name 动态生成。可以省略,但是不建议省略,便于编译时/开发时的类型提示,帮助代码提示和类型检查。
blogs: ReverseRelation["Blog"]
comments: ReverseRelation["Comment"]
class Blog(Model):
id = fields.IntField(pk=True)
title = fields.CharField(max_length=200)
content = fields.TextField(null=True)
created_at = fields.DatetimeField(auto_now_add=True)
# 外键 + 级联规则 Blog.author 这是 正向关系(forward relation),表示 Blog 模型有一个外键字段 author,指向 User 模型。
# related_name="blogs":为反向关系指定名称,即从 User 查找其所有博客时,使用 .blogs 属性。
author: fields.ForeignKeyRelation[User] = fields.ForeignKeyField(
"models.User",
related_name="blogs",
on_delete=fields.CASCADE # 删除用户时,级联删除其博客
)
comments: ReverseRelation["Comment"]
tags: fields.ManyToManyRelation["Tag"]
class Comment(Model):
id = fields.IntField(pk=True)
content = fields.TextField()
created_at = fields.DatetimeField(auto_now_add=True)
user: fields.ForeignKeyRelation[User] = fields.ForeignKeyField(
"models.User", related_name="comments", on_delete=fields.SET_NULL, null=True
)
blog: fields.ForeignKeyRelation[Blog] = fields.ForeignKeyField(
"models.Blog", related_name="comments", on_delete=fields.CASCADE
)
级联规则说明:
CASCADE:主表删除,从表记录也删除。SET_NULL:主表删除,从表外键设为NULL(需null=True)。RESTRICT:阻止删除。SET_DEFAULT:设为默认值。
5.9 ORM 查询:select_related 与 prefetch_related
select_related 通常用于 外键 / 一对一 / 一对多(从多查一)
prefetch_related 可用于 所有关系,尤其是多对多
场景:避免 N+1 查询问题
# ❌ 错误:N+1 查询
users = await User.all()
for user in users:
print(user.username)
for blog in user.blogs: # 每次循环都查一次数据库
print(blog.title)
# ✅ 正确:使用 prefetch_related
users = await User.all().prefetch_related("blogs")
for user in users:
print(user.username)
for blog in user.blogs:
print(blog.title)
多级关联预加载
# 预加载用户 → 博客 → 评论
users = await User.all().prefetch_related("blogs__comments")
for user in users:
for blog in user.blogs:
for comment in blog.comments:
print(f"{user.username} 的博客 {blog.title} 有评论:{comment.content}")
多对多预加载
# 查询带标签的博客
blogs = await Blog.all().prefetch_related("tags")
for blog in blogs:
print(f"Blog: {blog.title}")
for tag in blog.tags:
print(f" Tag: {tag.name}")
select_related vs prefetch_related
| 方法 | 用途 | 适用场景 |
|---|---|---|
select_related |
JOIN 查询,返回单个对象 | 外键一对一/多对一 |
prefetch_related |
分两次查询,合并结果 | 多对多、反向外键 |
# select_related 示例
blog = await Blog.get(id=1).select_related("author")
print(blog.author.username)
5.10 Tortoise ORM CRUD 示例
当然可以,下面提供了一个关于 Tortoise ORM 的 CRUD 操作的简要演示示例。这个例子将展示如何使用 create, filter, get, update, delete, annotate 和 aggregate 等方法。
假设我们有一个简单的博客应用,其中包含两个模型:User 和 BlogPost。
模型定义
# apps/blog/models.py
from tortoise import fields, models
class User(models.Model):
id = fields.IntField(pk=True)
username = fields.CharField(max_length=50, unique=True)
email = fields.CharField(max_length=100, null=True)
class BlogPost(models.Model):
id = fields.IntField(pk=True)
title = fields.CharField(max_length=200)
content = fields.TextField()
created_at = fields.DatetimeField(auto_now_add=True)
author = fields.ForeignKeyField("models.User", related_name="posts")
Meta配置
在使用 Tortoise ORM(最新版 ≥ 0.20+) 进行数据库操作时,除了定义字段(fields),模型的 Meta 内部类是控制表结构、索引、约束、连接等行为的关键配置入口。合理使用 Meta 可以显著提升查询性能、保证数据一致性,并适配不同数据库特性。
以下是对 Meta 中常用属性的详细说明,包括含义、使用场景和配置示例。
✅ 1. table: str
- 含义:指定数据库中对应的表名。
- 默认值:模型类名转为小写(如
UserModel→usermodel)。 - 使用场景:
- 需要自定义表名(如符合公司命名规范)
- 与遗留数据库表对接
- 示例:
class Meta: table = "access_keys" # 表名为 access_keys 而非 accesskey
✅ 2. unique_together: Union[Tuple[str, ...], List[Tuple[str, ...]]]
- 含义:定义多字段联合唯一约束(composite unique constraint)。
- 使用场景:
- 确保多个字段组合全局唯一(如
(email, tenant_id)) - 替代单字段
unique=True的局限性
- 确保多个字段组合全局唯一(如
- 示例:
class Meta: unique_together = ("access_key", "secret_key") # 或多个联合唯一 # unique_together = [ # ("user_id", "role"), # ("email", "org_id") # ]
💡 数据库会自动创建唯一索引,插入重复组合将抛出
IntegrityError。
✅ 3. indexes: List[Index]
- 含义:显式定义数据库索引(普通索引、唯一索引、函数索引等)。
- 使用场景:
- 对非主键字段加速查询(如
status,created_at) - 创建复合索引(多列)
- 需要更精细控制索引类型(如
partial条件索引)
- 对非主键字段加速查询(如
- 依赖:需从
tortoise.indexes导入索引类。 - 示例:
# 老版本导入
from tortoise.indexes import Index, UniqueIndex
class Meta:
indexes = [
Index(fields=("area", "created_at")), # 普通复合索引
UniqueIndex(fields=("access_key",)), # 等价于 unique=True
Index(fields=("created_at",), name="idx_created"), # 自定义索引名
]
# 新版本可以直接在Meta里使用,无需显示导入
indexes = [
("regionid", "projectid"), # 相当于 Index(fields=["regionid", "projectid"])
]
# 唯一约束(相当于 UniqueIndex)
unique_together = (
("instanceid", "regionid"), # 联合唯一
)
⚠️ 注意:
unique_together是UniqueIndex的语法糖,两者不要重复定义。
✅ 4. abstract: bool
- 含义:标记该模型为抽象基类,不会创建实际表。
- 使用场景:
- 定义公共字段(如
created_at,updated_at) - 多个模型继承相同结构
- 定义公共字段(如
- 示例:
class TimestampMixin: created_at = fields.DatetimeField(auto_now_add=True) updated_at = fields.DatetimeField(auto_now=True) class Meta: abstract = True class AccessKey(TimestampMixin, Model): access_key = fields.CharField(max_length=100) # 实际表包含 created_at, updated_at + access_key
✅ 5. schema: Optional[str]
- 含义:指定数据库 Schema(如 PostgreSQL 的 schema 名)。
- 使用场景:
- 多租户架构(每个租户一个 schema)
- 组织复杂数据库结构
- 示例(PostgreSQL):
class Meta: schema = "tenant_a" # 表将创建在 tenant_a.access_keys
🔒 注意:SQLite / MySQL 不支持 schema,此参数会被忽略。
✅ 6. manager: str
-
含义:指定用于该模型的连接别名(对应
TORTOISE_ORM["apps"][...]["models"]中的连接名)。 -
使用场景:
- 多数据库连接(如读写分离、分库)
-
示例:
# tortoise_config.py TORTOISE_ORM = { "connections": { "default": "sqlite://db.sqlite3", "readonly": "sqlite://readonly.db" }, "apps": { "models": { "models": ["myapp.models"], "default_connection": "default" } } } # model.py class AccessKey(Model): ... class Meta: manager = "readonly" # 此模型所有查询走 readonly 连接
✅ 7. ordering: List[str]
-
含义:定义默认排序规则,影响
.all()、.filter()等查询结果顺序。 -
使用场景:
- 希望列表按时间倒序、名称升序等默认展示
-
语法:
"field"→ 升序(ASC)"-field"→ 降序(DESC)
-
示例:
class Meta: ordering = ["-created_at", "area"] # 先按创建时间倒序,再按区域升序
✅ 8. extra_kwargs: Dict[str, Any]
- 含义:传递数据库特定的额外参数(较少使用)。
- 使用场景:
- 设置 MySQL 表引擎(如
InnoDB) - PostgreSQL 表空间等
- 设置 MySQL 表引擎(如
- 示例(MySQL):
class Meta: extra_kwargs = { "mysql_engine": "InnoDB", "mysql_charset": "utf8mb4" }
💡 重要提示:修改
Meta后(尤其是unique_together、indexes),必须生成并执行数据库迁移(如使用aerich),否则变更不会生效!
aerich migrate --name add_composite_unique
aerich upgrade
增加(Create)
创建新用户和博客文章:
async def create_user_and_post():
# 创建用户
user = await User.create(username="john_doe", email="john@example.com")
# 创建博客文章
post = await BlogPost.create(title="My First Post", content="Hello World!", author=user)
print(f"Created user: {user.username}")
print(f"Created post: {post.title} by {post.author.username}")
其他创建方式:
- 使用
.save()手动保存实例:
async def create_with_save():
user = User(username="jane_doe", email="jane@example.com")
await user.save() # 显式保存
post = BlogPost(title="Another Post", content="Hi there!", author=user)
await post.save()
- 批量创建(
bulk_create):
async def bulk_create_posts():
user = await User.get(username="john_doe")
posts = [
BlogPost(title=f"Post {i}", content=f"Content {i}", author_id=user.id)
for i in range(1, 6)
]
await BlogPost.bulk_create(posts)
查询(Filter/Get)
查询特定用户的博客文章或根据条件查找文章:
async def get_posts_by_user(user_id: int):
# 获取指定用户的全部文章
posts = await BlogPost.filter(author_id=user_id).all()
for post in posts:
print(post.title)
async def find_post_by_title(title_part: str):
# 查找标题中包含特定字符串的文章
posts = await BlogPost.filter(title__icontains=title_part).all()
for post in posts:
print(post.title)
其他查询方式:
- 获取单个对象(
.get()vs.first()):
# .get():若不存在会抛出 DoesNotExist 异常
post = await BlogPost.get(id=1)
# .first():安全获取,不存在返回 None
post = await BlogPost.filter(id=1).first()
- 关联预加载(避免 N+1 问题):
posts = await BlogPost.all().prefetch_related("author")
user = await User.get(id=1).prefetch_related("posts")
- 排序与分页:
# 按创建时间倒序,取前5篇
posts = await BlogPost.all().order_by("-created_at").limit(5)
更新(Update)
更新已存在的博客文章:
async def update_post(post_id: int, new_title: str, new_content: str):
# 更新博客文章
post = await BlogPost.get(id=post_id)
post.title = new_title
post.content = new_content
await post.save()
print(f"Updated post: {post.title}")
其他更新方式:
- 直接批量更新(不加载对象):
async def update_post_directly(post_id: int, new_title: str):
count = await BlogPost.filter(id=post_id).update(title=new_title)
print(f"Updated {count} post(s)")
- 条件批量更新多个记录:
# 更新某作者所有文章的标题前缀(需在应用层拼接)
await BlogPost.filter(author_id=1).update(title="【更新】" + F('title'))
# 注意:Tortoise 目前不支持字段表达式拼接,通常需先查后改
删除(Delete)
删除博客文章或用户:
async def delete_post(post_id: int):
# 删除博客文章
post = await BlogPost.get(id=post_id)
await post.delete()
print(f"Deleted post with ID: {post_id}")
async def delete_user(user_id: int):
# 删除用户及其所有文章
user = await User.get(id=user_id).prefetch_related('posts')
for post in user.posts:
await post.delete()
await user.delete()
print(f"Deleted user with ID: {user_id}")
其他删除方式:
- 直接批量删除(推荐用于高性能场景):
async def delete_all_posts_by_author(author_id: int):
deleted_count = await BlogPost.filter(author_id=author_id).delete()
print(f"Deleted {deleted_count} posts")
- 级联删除(应用层实现):
# 先删关联数据,再删主对象
await BlogPost.filter(author_id=user_id).delete()
await User.filter(id=user_id).delete()
聚合(Aggregate)与注解(Annotate)
统计博客文章数量或计算平均长度:
from tortoise.functions import Count, Avg, Length
async def count_posts_per_user():
# 统计每个用户的博客文章数
users_with_posts_count = await User.all().annotate(posts_count=Count('posts'))
for user in users_with_posts_count:
print(f"User {user.username} has written {user.posts_count} posts.")
async def average_post_length():
# 计算所有博客文章的平均长度
avg_length = await BlogPost.annotate(avg_len=Avg(Length('content'))).first()
print(f"Average post length is {avg_length.avg_len}")
其他聚合方式:
- 多指标聚合:
from tortoise.functions import Sum, Max, Min
stats = await BlogPost.annotate(
total=Count("id"),
max_len=Max(Length("content")),
min_len=Min(Length("content"))
).first()
- 按条件分组统计(结合 filter):
# 统计活跃用户的帖子数(例如最近30天)
from datetime import datetime, timedelta
thirty_days_ago = datetime.now() - timedelta(days=30)
users = await User.filter(
posts__created_at__gte=thirty_days_ago
).annotate(recent_posts=Count("posts")).all()
Q与F
在 Tortoise ORM 中,聚合(Aggregate) 和 注解(Annotate) 是用于对查询结果进行统计、分组和增强字段的重要功能。它们通常配合 Q 对象(用于复杂条件过滤)和 F 表达式(用于引用模型字段)一起使用,实现更灵活的数据库查询逻辑。
1. Q 对象:构建复杂查询条件
✅ 正确导入方式(新版):
from tortoise.expressions import Q
Q 对象用于组合多个查询条件,支持逻辑运算(&、|、~),适用于 filter()、exclude() 等方法。
from tortoise.expressions import Q
from models import User
# 查询年龄大于 18 且城市为 "Beijing" 的用户
users = await User.filter(Q(age__gt=18) & Q(city="Beijing"))
# 查询年龄小于 18 或活跃状态为 False 的用户
users = await User.filter(Q(age__lt=18) | Q(is_active=False))
# 排除用户名为 admin 的用户
users = await User.exclude(Q(username="admin"))
💡 自 Tortoise ORM v0.19 起,
Q已从tortoise.query_utils移至tortoise.expressions。
2. F 表达式:引用字段进行计算或比较
✅ 正确导入方式(新版):
from tortoise.expressions import F
F 表达式允许你在查询中直接引用数据库字段,用于字段间比较、注解计算或原子更新。
from tortoise.expressions import F
from models import Product
# 查询库存大于销量的商品
products = await Product.filter(inventory__gt=F("sales"))
# 注解:计算剩余库存(inventory - sales)
products = await Product.annotate(
remaining=F("inventory") - F("sales")
).filter(remaining__gt=0)
3. 聚合函数(Aggregate Functions)
聚合函数仍从 tortoise.functions 导入:
from tortoise.functions import Count, Sum, Avg, Max, Min
示例:
# 按城市统计用户数
city_stats = await User.annotate(
user_count=Count("id")
).group_by("city").values("city", "user_count")
4. 综合示例:Q + F + 聚合 + 注解
from tortoise.expressions import Q, F
from tortoise.functions import Sum
# 统计每个用户已支付订单总金额 > 1000 的记录
result = await Order.filter(
Q(status="paid")
).annotate(
total_paid=Sum("amount")
).group_by("user_id").having(
Q(total_paid__gt=1000)
).values("user_id", "total_paid")
5. 原子更新(使用 F)
from tortoise.expressions import F
# 安全地减少库存(数据库层面原子操作)
await Product.filter(id=1).update(inventory=F("inventory") - 1)
六、中间件(Middleware)
在 FastAPI 中,中间件(Middleware)用于在请求到达路由处理函数之前或响应返回客户端之前执行通用逻辑,例如日志记录、身份验证、CORS 处理、性能监控等。本文档详细说明 FastAPI 中间件的定义方式、调用顺序规则以及参数传递方法。
1. 中间件的定义与注册方式
FastAPI 支持两种主要方式来定义和注册中间件:
1.1 使用装饰器 @app.middleware("http")
适用于定义简单的函数式中间件。
from fastapi import FastAPI, Request
from starlette.responses import Response
app = FastAPI()
@app.middleware("http")
async def log_requests(request: Request, call_next):
print(f"→ 接收到请求: {request.url}")
response: Response = await call_next(request)
print(f"← 返回响应: 状态码 {response.status_code}")
return response
✅ 优点:简洁直观
❌ 缺点:无法复用、难以配置参数、不便于测试
1.2 使用 app.add_middleware() 方法
推荐方式,支持类式中间件(基于 BaseHTTPMiddleware 或 ASGI 协议),便于复用和配置。
示例:自定义类中间件
from fastapi import FastAPI
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.requests import Request
from starlette.responses import Response
class AuthMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request: Request, call_next):
if "Authorization" not in request.headers:
from starlette.responses import JSONResponse
return JSONResponse({"error": "Missing token"}, status_code=401)
response = await call_next(request)
return response
app = FastAPI()
app.add_middleware(AuthMiddleware)
示例:使用内置中间件(如 CORS)
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["https://example.com"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
✅ 优点:可复用、支持参数配置、结构清晰、易于测试
🔧 官方推荐使用add_middleware
2. 多个中间件的调用顺序
无论使用哪种方式注册,所有中间件最终都按注册顺序组成一个“洋葱模型”(Onion Model):
- 先注册的中间件在外层
- 后注册的中间件在内层
- 请求进入时:从外到内依次执行
- 响应返回时:从内到外依次执行
示例:混合注册多个中间件
app = FastAPI()
# 方式1:装饰器(最先注册)
@app.middleware("http")
async def middleware_a(request, call_next):
print("A →")
resp = await call_next(request)
print("A ←")
return resp
# 方式2:add_middleware(第二个注册)
app.add_middleware(LoggingMiddleware) # 假设已定义
# 方式3:add_middleware(第三个注册)
app.add_middleware(AuthMiddleware)
实际执行顺序(请求流程):
Request
→ middleware_a (A →)
→ LoggingMiddleware
→ AuthMiddleware
→ 路由处理函数
← AuthMiddleware
← LoggingMiddleware
← middleware_a (A ←)
→ Response
⚠️ 注意:
@app.middleware("http")的注册时机是在装饰器被解析时(即模块导入时),通常早于后续的app.add_middleware()调用。
最佳实践建议顺序:
- CORS / TrustedHost 等安全中间件(最外层)
- 日志 / 监控中间件
- 认证 / 权限中间件
- 业务自定义中间件(最内层)
3. 自定义中间件的参数传递方式
3.1 装饰器方式(@app.middleware)—— 不支持参数传递
函数式中间件签名固定为:
async def my_middleware(request: Request, call_next: Callable)
无法接收额外配置参数。如需配置,必须通过全局变量或设置模块间接实现(不推荐)。
3.2 add_middleware() 方式 —— 支持通过关键字参数传参
中间件类的 __init__ 方法可以接收除 app 之外的任意参数,这些参数通过 add_middleware() 的后续关键字参数传入。
示例:带参数的中间件
from starlette.middleware.base import BaseHTTPMiddleware
class CustomHeaderMiddleware(BaseHTTPMiddleware):
def __init__(
self,
app, # 必须保留,由 Starlette 自动传入
header_name: str = "X-Custom",
header_value: str = "Default"
):
super().__init__(app)
self.header_name = header_name
self.header_value = header_value
async def dispatch(self, request, call_next):
response = await call_next(request)
response.headers[self.header_name] = self.header_value
return response
注册时传参:
app.add_middleware(
CustomHeaderMiddleware,
header_name="X-API-Version",
header_value="v1.2.0"
)
✅ 所有关键字参数都会传递给
__init__(除了app,它由框架自动注入)
总结对比表
| 特性 | @app.middleware("http") |
app.add_middleware() |
|---|---|---|
| 定义形式 | 函数 | 类(推荐继承 BaseHTTPMiddleware) |
| 参数传递 | ❌ 不支持 | ✅ 支持(通过 **kwargs) |
| 复用性 | 差(绑定当前 app) | 高(可跨项目复用) |
| 测试友好度 | 低 | 高 |
| 注册顺序控制 | 弱(依赖代码位置) | 强(显式调用顺序) |
| 适用场景 | 简单临时逻辑 | 正式项目、复杂逻辑 |
推荐实践
- ✅ 优先使用
app.add_middleware()+ 类式中间件 - ✅ 将中间件定义在独立模块(如
middlewares/目录) - ✅ 在
main.py中统一注册所有中间件,明确顺序 - ✅ 利用参数化提高中间件灵活性
- ❌ 避免在中间件模块中
from main import app,防止循环导入
📚 参考文档:
七、高级特性
(原内容已完善,略作调整)
7.1 依赖注入
在编程中,“依赖”指的是一个函数或类需要另一个组件(如数据库连接、身份验证逻辑)才能正常工作。依赖注入(Dependency Injection, DI) 是一种设计模式,它允许我们将这些“依赖”从外部传递给函数,而不是在函数内部创建或硬编码它们。
FastAPI 的依赖注入系统非常强大,可以:
- 复用代码逻辑(如认证、分页)
- 自动解析依赖关系
- 提高代码可测试性和可维护性
- 实现权限控制、数据库连接管理等
### 代码示例与详细注释
```python
from fastapi import Depends, FastAPI, HTTPException, status
from typing import Optional
app = FastAPI()
# ========================
# 示例 1:复用公共查询参数
# ========================
def common_parameters(
q: Optional[str] = None, # 搜索关键词
skip: int = 0, # 分页:跳过前 skip 条
limit: int = 10 # 分页:最多返回 limit 条
):
"""
这是一个通用依赖函数,用于提取所有 API 中常见的查询参数。
优势:
- 避免在每个路由中重复声明相同的参数
- 统一处理分页、搜索逻辑
- 易于修改和维护
返回:
一个字典,包含所有提取出的参数
"""
return {"q": q, "skip": skip, "limit": limit}
@app.get("/items/")
async def read_items(commons: dict = Depends(common_parameters)):
"""
获取物品列表。
参数:
commons: 由 common_parameters() 返回的字典
工作流程:
1. 用户请求:GET /items/?q=book&skip=2&limit=5
2. FastAPI 自动调用 common_parameters(q="book", skip=2, limit=5)
3. 将返回值赋给 commons
4. 执行本函数
返回示例:
{
"message": "获取物品列表",
"data": [],
"params": {"q": "book", "skip": 2, "limit": 5}
}
"""
return {
"message": "获取物品列表",
"data": [], # 假设这是从数据库查出的数据
"params": commons
}
@app.get("/users/")
async def read_users(commons: dict = Depends(common_parameters)):
"""
获取用户列表。
复用相同的依赖函数,避免代码重复。
即使是不同业务的接口,只要参数相同,就可以共享依赖。
"""
return {
"message": "获取用户列表",
"data": [],
"params": commons
}
# ========================
# 示例 2:身份验证依赖
# ========================
def verify_token(token: str):
"""
模拟一个身份验证函数。
参数:
token (str): 客户端传入的令牌
逻辑:
- 如果 token 不是 "secret-token",则抛出 401 错误
- 否则返回 token(表示验证通过)
应用场景:
- 所有需要登录才能访问的接口
- 可替换为 JWT、OAuth2 等真实认证逻辑
"""
if token != "secret-token":
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="无效的令牌,请检查后重试",
headers={"WWW-Authenticate": "Bearer"},
)
return token # 可选:返回 token 供后续使用
@app.get("/secure-data/")
async def get_secure_data(user_token: str = Depends(verify_token)):
"""
只有通过身份验证的用户才能访问此接口。
当用户访问 /secure-data/?token=xxx 时:
1. FastAPI 提取 token 参数
2. 调用 verify_token(token=xxx)
3. 如果验证失败,直接返回 401
4. 如果成功,继续执行函数逻辑
优势:
- 所有需要认证的接口只需添加 `Depends(verify_token)`
- 认证逻辑集中管理,便于修改
"""
return {
"message": "安全数据已获取",
"user_token": user_token,
"detail": "你已通过身份验证"
}
7.2 后台任务
什么是后台任务?
在 Web 开发中,有些操作耗时较长(如发送邮件、生成报告、记录日志)。如果在请求处理过程中同步执行,会导致用户等待时间变长。
后台任务(Background Tasks) 允许你在响应发送给客户端之后,继续在后台执行某些操作。FastAPI 使用 BackgroundTasks 类来实现这一功能。
from fastapi import BackgroundTasks, FastAPI
from typing import Optional
app = FastAPI()
# ========================
# 定义后台任务函数
# ========================
def log_email_sent(email: str, message: str):
"""
模拟发送邮件后的日志记录。
参数:
email (str): 收件人邮箱
message (str): 邮件内容
说明:
这个函数不会阻塞主请求流程。
它会在主响应发送后由 FastAPI 自动调用。
应用场景:
- 发送确认邮件
- 记录用户行为日志
- 清理临时文件
- 同步数据到第三方服务
"""
print(f"【后台任务】已向 {email} 发送邮件,内容:{message}")
def generate_report(user_id: int):
"""
模拟为用户生成报告。
参数:
user_id (int): 用户唯一标识
说明:
生成报告可能需要几秒甚至几分钟。
使用后台任务可避免用户长时间等待。
"""
print(f"【后台任务】正在为用户 {user_id} 生成报告...")
# ========================
# 在路由中使用后台任务
# ========================
@app.post("/send-email/")
async def send_email(
email: str,
message: str,
background_tasks: BackgroundTasks
):
"""
发送邮件接口。
参数:
email (str): 收件人邮箱
message (str): 邮件内容
background_tasks (BackgroundTasks): FastAPI 提供的后台任务管理器
工作流程:
1. 接收请求,立即返回成功响应
2. 将 log_email_sent 函数添加到后台任务队列
3. 响应发送给客户端
4. 后台异步执行 log_email_sent 函数
用户体验:
用户无需等待日志写入完成即可看到“邮件发送成功”。
"""
# 模拟邮件发送(实际中可能是调用 SMTP 或第三方 API)
print(f"正在发送邮件到 {email}...")
# 将任务添加到后台任务队列
background_tasks.add_task(log_email_sent, email, message)
# 立即返回响应,不等待后台任务完成
return {"message": "邮件发送请求已接收", "status": "success"}
@app.get("/profile/{user_id}")
async def get_user_profile(user_id: int, background_tasks: BackgroundTasks):
"""
获取用户资料接口。
当用户访问个人资料时,后台自动为其生成最新报告。
参数:
user_id (int): 用户 ID
background_tasks (BackgroundTasks): 后台任务管理器
优势:
- 用户快速看到当前资料
- 报告在后台生成,下次访问时即可获取
"""
# 模拟从数据库获取用户资料
user_data = {"id": user_id, "name": "张三", "email": "zhangsan@example.com"}
# 添加后台任务:生成报告
background_tasks.add_task(generate_report, user_id)
return {
"message": "用户资料获取成功",
"data": user_data,
"note": "报告正在后台生成,稍后可查看"
}
7.3 静态文件与 Jinja2 模板
7.3.1 静态文件服务
FastAPI 可以使用 StaticFiles 类来提供静态文件服务(如 CSS、JavaScript、图片等)。
安装依赖:
pip install aiofiles
目录结构:
my_project/
├── main.py
├── static/
│ ├── css/
│ │ └── style.css
│ ├── js/
│ │ └── script.js
│ └── images/
│ └── logo.png
└── templates/
└── index.html
注册静态文件路由:
from fastapi import FastAPI
from fastapi.staticfiles import StaticFiles
app = FastAPI()
# 挂载静态文件目录
app.mount("/static", StaticFiles(directory="static"), name="static")
现在可以通过以下 URL 访问静态资源:
http://127.0.0.1:8000/static/css/style.csshttp://127.0.0.1:8000/static/js/script.jshttp://127.0.0.1:8000/static/images/logo.png
7.3.2 Jinja2 模板引擎
Jinja2 是一个现代、设计者友好的 Python 模板引擎,广泛用于 Web 开发中生成 HTML、XML 或其他标记语言。
安装依赖:
pip install jinja2
创建模板文件:
在 templates/ 目录下创建 index.html:
<!-- templates/index.html -->
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>{{ title }}</title>
<link rel="stylesheet" href="/static/css/style.css">
</head>
<body>
<h1>{{ title }}</h1>
<p>欢迎,{{ user.name }}!</p>
<h2>物品列表:</h2>
<ul>
{% for item in items %}
<li>{{ item.name }} - 价格:{{ item.price }} 元</li>
{% endfor %}
</ul>
{% if is_admin %}
<p><strong>您是管理员。</strong></p>
{% else %}
<p>您是普通用户。</p>
{% endif %}
<script src="/static/js/script.js"></script>
</body>
</html>
配置模板引擎:
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
from fastapi.responses import HTMLResponse
app = FastAPI()
# 初始化模板引擎
templates = Jinja2Templates(directory="templates")
# 示例数据
items = [
{"name": "笔记本电脑", "price": 5999},
{"name": "鼠标", "price": 99},
{"name": "键盘", "price": 299}
]
@app.get("/", response_class=HTMLResponse)
async def read_root(request: Request):
return templates.TemplateResponse(
request=request,
name="index.html",
context={
"title": "首页",
"user": {"name": "Alice"},
"items": items,
"is_admin": False
}
)
Jinja2 核心语法:
| 语法 | 说明 | 示例 |
|---|---|---|
{{ }} |
变量输出 | {{ name }} |
{% %} |
控制结构 | {% if condition %}...{% endif %} |
{# #} |
注释 | {# 这是注释 #} |
{% extends "base.html" %} |
模板继承 | 继承基础模板 |
{% block content %}{% endblock %} |
定义可替换块 | 在子模板中覆盖内容 |
模板继承示例:
<!-- templates/base.html -->
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>{% block title %}默认标题{% endblock %}</title>
<link rel="stylesheet" href="/static/css/style.css">
</head>
<body>
<header>
<h1>我的网站</h1>
</header>
<main>
{% block content %}{% endblock %}
</main>
<footer>
<p>© 2025 版权所有</p>
</footer>
</body>
</html>
<!-- templates/home.html -->
{% extends "base.html" %}
{% block title %}首页{% endblock %}
{% block content %}
<h2>欢迎光临</h2>
<p>这里是主页内容。</p>
{% endblock %}
过滤器(Filters):
Jinja2 提供了丰富的内置过滤器:
{{ name|upper }} <!-- 转大写 -->
{{ text|length }} <!-- 字符串长度 -->
{{ number|round(2) }} <!-- 保留两位小数 -->
{{ items|join(', ') }} <!-- 列表转字符串 -->
{{ content|safe }} <!-- 标记为安全 HTML(不转义) -->
八、异常捕获
可以考虑用第三方的apiexception
pip install apiexception
官网地址https://akutayural.github.io/APIException/
from fastapi import FastAPI, Request, HTTPException, status
from fastapi.exceptions import RequestValidationError
from fastapi.responses import JSONResponse
from pydantic import BaseModel
import logging
app = FastAPI()
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# -------------------------------
# 🔁 自定义异常类(可选)
# -------------------------------
class BizException(Exception):
"""业务逻辑异常"""
def __init__(self, message: str, code: int = 400):
self.message = message
self.code = code
class NotFoundException(Exception):
"""资源未找到"""
def __init__(self, resource: str = "资源"):
self.message = f"{resource}不存在"
self.code = 404
# -------------------------------
# 🛡️ 全局异常处理器
# -------------------------------
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request: Request, exc: RequestValidationError):
"""
处理请求体校验失败(Pydantic 验证错误)
"""
errors = []
for error in exc.errors():
errors.append({
"loc": error["loc"],
"type": error["type"],
"msg": error["msg"],
"input": str(error.get("input", ""))[:100] # 截断避免太大
})
logger.warning(f"Validation error on {request.url}: {errors}")
return JSONResponse(
status_code=status.HTTP_422_UNPROCESSABLE_ENTITY,
content={
"success": False,
"message": "请求数据格式错误,请检查输入字段。",
"code": 422,
"details": errors
}
)
@app.exception_handler(BizException)
async def biz_exception_handler(request: Request, exc: BizException):
"""
处理业务异常
"""
logger.info(f"BizException: {exc.message}")
return JSONResponse(
status_code=200 if exc.code == 200 else 400,
content={
"success": False,
"message": exc.message,
"code": exc.code
}
)
@app.exception_handler(NotFoundException)
async def not_found_exception_handler(request: Request, exc: NotFoundException):
"""
处理资源未找到
"""
return JSONResponse(
status_code=404,
content={
"success": False,
"message": exc.message,
"code": 404
}
)
@app.exception_handler(HTTPException)
async def http_exception_handler(request: Request, exc: HTTPException):
"""
捕捉 FastAPI 内部的 HTTPException(如 raise HTTPException(403))
"""
return JSONResponse(
status_code=exc.status_code,
content={
"success": False,
"message": exc.detail,
"code": exc.status_code
}
)
@app.exception_handler(Exception)
async def unhandled_exception_handler(request: Request, exc: Exception):
"""
⚠️ 兜底异常处理器:捕捉所有未处理的异常(如代码 bug、数据库错误等)
"""
logger.error(f"Unhandled exception at {request.url}", exc_info=True)
return JSONResponse(
status_code=500,
content={
"success": False,
"message": "服务器内部错误,请联系管理员。",
"code": 500,
"details": "Internal Server Error" if not app.debug else str(exc)
}
)
@app.post("/analyze")
async def analyze(data: dict):
if not data.get("alarm_type"):
raise BizException("告警类型不能为空", code=400)
return {"success": True, "data": "ok"}
九、生命周期
FastAPI 通过 ASGI 规范提供的 lifespan 机制,支持在应用启动和关闭时执行自定义逻辑。这是管理应用资源生命周期的核心方式,适用于数据库连接、模型加载、缓存初始化等场景。
1. lifespan 简介
- ✅
lifespan是 FastAPI 中唯一的生命周期管理机制。 - 它替代了早期版本中的
@app.on_event("startup")和@app.on_event("shutdown")。 - 基于 ASGI 的
lifespan协议,使用 异步上下文管理器 实现。 - 支持两个阶段:
- Startup:应用启动后、接收请求前。
- Shutdown:应用关闭前、所有请求处理完毕后。
⚠️ 注意:
lifespan不处理单个请求的生命周期(那是中间件的职责)。
2. 支持的生命周期阶段
| 阶段 | 是否支持 | 说明 |
|---|---|---|
| Startup | ✅ | 应用启动时执行初始化逻辑 |
| Shutdown | ✅ | 应用关闭时执行清理逻辑 |
| Request 开始 | ❌ | 使用中间件实现 |
| Request 结束 | ❌ | 使用中间件实现 |
| 异常发生 | ❌ | 使用异常处理器实现 |
3. 代码示例
方法一:使用 @asynccontextmanager(推荐)
from fastapi import FastAPI
from contextlib import asynccontextmanager
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@asynccontextmanager
async def lifespan(app: FastAPI):
# ✅ 启动阶段
logger.info("🚀 应用正在启动...")
print("✅ 数据库连接已建立")
print("✅ ML 模型已加载")
yield # 应用运行中
# ✅ 关闭阶段
logger.info("🛑 应用正在关闭...")
print("🧹 数据库连接已关闭")
print("🧹 清理临时文件")
# 创建应用并传入 lifespan
app = FastAPI(lifespan=lifespan)
@app.get("/")
def read_root():
return {"message": "Hello World"}
方法二:使用函数 + yield(简洁版)
from fastapi import FastAPI
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
async def lifespan(app: FastAPI):
logger.info("🚀 应用启动:初始化资源")
# 初始化逻辑(如连接数据库)
yield
logger.info("🛑 应用关闭:释放资源")
# 清理逻辑(如断开连接)
app = FastAPI(lifespan=lifespan)
方法三:异步加载大模型示例
from fastapi import FastAPI
from contextlib import asynccontextmanager
import asyncio
# 模拟异步加载模型
async def load_model():
print("⏳ 正在加载大模型...")
await asyncio.sleep(2)
print("✅ 大模型加载完成")
return {"model": "qwen3-4b", "status": "loaded"}
model = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global model
model = await load_model() # 启动时加载
yield
print("🧹 正在卸载模型...")
model = None # 关闭时清理
print("✅ 模型已卸载")
app = FastAPI(lifespan=lifespan)
@app.get("/predict")
async def predict():
return {"result": f"预测结果(使用模型:{model['model']})"}
4. 已废弃的方式(请勿使用)
# ❌ 已废弃!不要使用
@app.on_event("startup")
async def startup():
pass
@app.on_event("shutdown")
async def shutdown():
pass
FastAPI v0.99+ 起,官方推荐使用
lifespan替代on_event。
5. 与中间件的对比
| 功能 | lifespan |
中间件 |
|---|---|---|
| 应用启动/关闭 | ✅ | ❌ |
| 每个请求前后 | ❌ | ✅ |
| 异常处理 | ❌ | ✅ |
| 性能监控 | ❌ | ✅ |
| 认证/日志 | ❌ | ✅ |
✅
lifespan与中间件互补,分别处理应用级和请求级逻辑。
6. 实战建议
| 场景 | 推荐方式 |
|---|---|
| 数据库连接 | lifespan |
| 加载 ML 模型 | lifespan |
| 初始化缓存(Redis) | lifespan |
| 请求日志记录 | 中间件 |
| 身份认证 | 中间件或依赖项 |
| 错误监控 | 异常处理器 + 中间件 |
7. 总结
- ✅ FastAPI 只支持一个
lifespan函数。 - ✅ 支持
startup和shutdown两个阶段。 - ✅ 使用
@asynccontextmanager是最清晰、最推荐的方式。 - ✅ 避免使用已废弃的
on_event。 - ✅ 结合中间件,可构建完整生命周期管理方案。
通过合理使用 lifespan,你可以确保应用在启动时正确初始化资源,在关闭时优雅释放,提升系统的稳定性和可维护性。
十、任务调度
除了celery外,还有个新的模块叫TaskIQ
属于轻量级的,适配fastapi而生的任务调度模块
https://taskiq-python.github.io/
还有国产框架funboost
https://funboost.readthedocs.io/zh-cn/latest/articles/c4.html
APScheduler 使用详解
1. APScheduler 中的调度器(Scheduler)类型及适用场景
APScheduler 提供了多种调度器,适用于不同的编程模型和运行环境。以下是所有主要调度器及其使用场景:
✅ BlockingScheduler
- 特点:最简单的调度器,调用
start()后会阻塞当前线程,直到被中断。 - 适用场景:
- 独立脚本(如数据备份、日志清理);
- 不需要与其他服务共存的单任务程序;
- 测试或演示用途。
- 示例:
from apscheduler.schedulers.blocking import BlockingScheduler sched = BlockingScheduler() sched.add_job(my_job, 'interval', seconds=10) sched.start() # 程序在此处阻塞
✅ BackgroundScheduler
-
特点:在后台线程中运行,不阻塞主线程;基于
threading模块。 -
适用场景:
- 同步 Web 框架(如 Flask、Django);
- 普通 Python 脚本中需要后台定时任务;
- 项目中未使用 asyncio。
-
限制:
- 不能直接调用
async def函数; - 若在任务中强行使用
asyncio.run(),易引发跨线程/跨 loop 错误。
- 不能直接调用
-
并发控制与线程池配置:
- 默认使用
ThreadPoolExecutor执行任务; - 可通过
executors参数自定义线程池大小,控制最大并发数; - 示例:
from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.executors.pool import ThreadPoolExecutor executors = { 'default': ThreadPoolExecutor(max_workers=10) # 控制最大并发线程数为10 } scheduler = BackgroundScheduler(executors=executors) scheduler.add_job(sync_io_task, 'interval', seconds=5)
- 默认使用
-
总结:
✅
BackgroundScheduler适合用于多线程执行多个同步(def)函数的场景,尤其适用于 I/O 密集型任务(如 HTTP 请求、数据库查询)。通过配置ThreadPoolExecutor(max_workers=N)可精确控制并发线程数量。
✅ AsyncIOScheduler
- 特点:基于
asyncio事件循环,在同一个线程中以协程方式调度任务。 - 适用场景:
- 异步 Web 框架(如 FastAPI、aiohttp、Quart);
- 使用了异步数据库(TortoiseORM、SQLAlchemy async)、异步 HTTP 客户端(httpx)的项目;
- 需要在任务中使用
await。
- 优势:
- 原生支持
async def函数; - 与 asyncio 生态无缝集成;
- 非阻塞,高并发性能好。
- 原生支持
- 并发控制:
- 并发能力由 asyncio 事件循环天然支持;
- 实际并发上限受以下因素影响:
- 任务是否真正异步(避免同步 I/O 阻塞 loop);
- 是否使用
max_instances限制单个任务的并发实例数; - 若需调用同步函数,应使用
loop.run_in_executor(),此时可配置线程池控制其并发:from concurrent.futures import ThreadPoolExecutor sync_pool = ThreadPoolExecutor(max_workers=5) # 控制同步操作的并发线程数 async def async_job(): loop = asyncio.get_running_loop() result = await loop.run_in_executor(sync_pool, blocking_func, arg)
- 注意:
AsyncIOScheduler本身不提供“协程并发数”限制(因为协程开销极小),但可通过max_instances防止单个任务重入。
- 示例:
from apscheduler.schedulers.asyncio import AsyncIOScheduler import asyncio async def main(): sched = AsyncIOScheduler() sched.add_job(async_job, 'interval', seconds=30, max_instances=1) sched.start() await asyncio.sleep(3600) asyncio.run(main())
✅ TornadoScheduler
- 特点:专为 Tornado 异步框架设计,使用 Tornado 的 IOLoop。
- 适用场景:
- 基于 Tornado 的老项目;
- 需要与 Tornado 协程集成。
- 现状:Tornado 已支持 asyncio,新项目建议直接用
AsyncIOScheduler。
✅ TwistedScheduler
- 特点:基于 Twisted 异步网络框架。
- 适用场景:
- 使用 Twisted 构建的服务(如 Scrapy 分布式扩展);
- 遗留 Twisted 项目。
- 注意:Twisted 使用自己的事件循环,与 asyncio 不兼容。
📌 调度器选择总结:
- FastAPI / Starlette / aiohttp →
AsyncIOScheduler- Flask / Django / 同步脚本 →
BackgroundScheduler- 独立脚本无其他逻辑 →
BlockingScheduler- Tornado/Twisted 项目 → 对应专用 Scheduler
2. add_job 方法参数详解
add_job(func, trigger, ...) 是 APScheduler 添加任务的核心方法。除常见参数外,以下参数对高级控制至关重要:
✅ coalesce(bool,默认 True)
- 作用:当任务因系统卡顿错过多次执行时间时,是否将这些错过的执行“合并为一次”。
- 使用场景:
coalesce=True:适合幂等任务(如“检查状态”),避免堆积大量重复执行;coalesce=False:适合必须每次执行的任务(如“每分钟计费”),但可能因堆积导致雪崩。- 如果任务结束时发现有(比如卡了 3 分钟),由于 coalesce=True,只会再执行一次,而不是连续执行 3 次。
- 示例:
# 如果错过 5 次,只补 1 次 scheduler.add_job(job, 'interval', minutes=1, coalesce=True)
✅ next_run_time(datetime,可选)
- 作用:手动指定下一次执行的具体时间,覆盖 trigger 的默认计算。
- 使用场景:
- 任务首次启动需延迟;
- 从持久化 JobStore 恢复任务时指定下次运行时间;
- 动态调整调度计划。
- 示例:
from datetime import datetime, timedelta next_time = datetime.now() + timedelta(seconds=10) scheduler.add_job(job, 'interval', seconds=30, next_run_time=next_time)
✅ jobstore(str,默认 'default')
- 作用:指定任务存储到哪个 JobStore(任务持久化后端)。
- JobStore 类型:
MemoryJobStore(默认):任务仅在内存中,重启丢失;SQLAlchemyJobStore:存入数据库(如 SQLite、PostgreSQL);MongoDBJobStore、RedisJobStore等第三方实现。
- 使用场景:
- 需要任务持久化(服务重启后恢复)→ 配置数据库 JobStore;
- 多进程共享任务 → 使用 Redis/MongoDB JobStore。
- 示例:
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore jobstores = {'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')} scheduler = AsyncIOScheduler(jobstores=jobstores) scheduler.add_job(job, 'interval', seconds=30, jobstore='default')
✅ executor(str,默认 'default')
- 作用:指定任务由哪个 Executor 执行(决定任务运行在线程/进程/协程)。
- Executor 类型:
ThreadPoolExecutor:任务在线程池中运行(适合 I/O 密集);ProcessPoolExecutor:任务在进程池中运行(适合 CPU 密集);AsyncIOExecutor:仅用于AsyncIOScheduler,任务作为协程运行(自动使用,无需显式指定)。
- 使用场景:
- CPU 密集型任务(如图像处理)→
ProcessPoolExecutor; - 异步任务 →
AsyncIOScheduler自动使用协程。
- CPU 密集型任务(如图像处理)→
- 配置示例:
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor executors = { 'default': ThreadPoolExecutor(10), 'processpool': ProcessPoolExecutor(2) } scheduler = BackgroundScheduler(executors=executors) scheduler.add_job(cpu_job, 'interval', seconds=60, executor='processpool')
✅ replace_existing(bool,默认 False)
- 作用:当添加的 job
id已存在时,是否替换旧任务。 - 使用场景:
- 动态更新任务参数(如修改间隔时间);
- 避免重复注册导致
ConflictingIdError。
- 示例:
# 第二次调用会替换第一次的任务 scheduler.add_job(job, 'interval', seconds=30, id='my_job', replace_existing=True)
✅ trigger_args(说明)
- 说明:
trigger_args并非add_job的直接参数。实际是通过trigger参数传入。 - 正确用法:
trigger可为字符串(如'interval')或Trigger对象,其参数通过关键字传入。 - 示例(等价写法):
# 方式1:字符串 + 关键字参数 scheduler.add_job(job, 'interval', seconds=30) # 方式2:显式 Trigger 对象 from apscheduler.triggers.interval import IntervalTrigger trigger = IntervalTrigger(seconds=30) scheduler.add_job(job, trigger=trigger)
计划任务模式
APScheduler(Advanced Python Scheduler)提供了三种内置的触发器(trigger)类型:date、interval 和 cron。它们分别适用于一次性任务、固定间隔重复任务和类 crontab 的周期性任务。合理选择触发器类型并配合参数配置,可以有效避免任务堆积、重复执行或资源竞争等问题。
三种触发器的区别与使用场景
####### date:一次性任务
- 用途:在指定的某个时间点执行一次任务。
- 适用场景:
- 延迟执行(如 5 秒后发送通知)
- 定时清理(如今天 23:59 删除临时文件)
- 任务链式调度(上一个任务完成后安排下一个)
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from datetime import datetime, timedelta
scheduler = AsyncIOScheduler()
# 30 秒后执行一次
run_time = datetime.now() + timedelta(seconds=30)
scheduler.add_job(my_task, 'date', run_date=run_time, id='one_time_task')
⚠️ 注意:
date触发器只执行一次,不会自动重复。若需循环,需在任务函数内部再次调用add_job。
####### interval:固定间隔重复任务
- 用途:每隔固定时间(秒、分钟、小时等)执行一次。
- 适用场景:
- 心跳检测(每 10 秒上报状态)
- 轮询接口(每分钟拉取最新数据)
- 定期同步缓存
# 每 60 秒执行一次
scheduler.add_job(
task_poll_data,
'interval',
seconds=60,
id='poll_job'
)
🔥 关键问题:如果任务执行时间 超过间隔时间(如任务耗时 90 秒,但 interval=60 秒),默认会立即触发下一次(因 missed trigger),导致多个实例并发!
####### cron:类 crontab 的复杂周期任务
- 用途:按日历时间规则执行(类似 Linux crontab)。
- 适用场景:
- 每天凌晨 2 点生成日报
- 每周一上午 9 点发送周报
- 每月 1 号结算账单
# 每天 02:30 执行
scheduler.add_job(
generate_daily_report,
'cron',
hour=2,
minute=30,
id='daily_report'
)
# 每周一至周五 9:00 执行
scheduler.add_job(
send_morning_alert,
'cron',
day_of_week='mon-fri',
hour=9,
minute=0
)
📅 支持字段:
year,month,day,week,day_of_week,hour,minute,second。
高级配置:防止任务堆积与并发冲突
在实际使用中,尤其是 interval 和 cron 模式,任务可能因执行缓慢或阻塞而未完成,但下一次触发时间已到,导致多个实例同时运行。这可能引发:
- 数据重复处理
- 资源竞争(如数据库锁)
- 后端接口过载
####### 推荐配置参数
| 参数 | 作用 | 建议值 |
|---|---|---|
max_instances |
同一 job 最大并发实例数 | 1(禁止并发) |
coalesce |
是否合并错过的触发(missed triggers) | True(只补一次) |
misfire_grace_time |
允许任务延迟启动的最大宽容时间(秒) | 根据业务设定(如 10~60) |
####### 示例:安全的 interval 任务配置
scheduler.add_job(
task_get_soc_alerts_lists,
'interval',
seconds=60,
id='scan_soc_alerts',
max_instances=1, # ⚠️ 关键:禁止并发
coalesce=True, # 若错过多次,只执行一次
misfire_grace_time=10 # 允许最多延迟 10 秒启动
)
💡 行为说明:
- 如果任务正在运行,新的触发会被丢弃(因
max_instances=1)。- 如果任务结束时发现有 missed trigger(比如卡了 3 分钟),由于
coalesce=True,只会再执行一次,而不是连续执行 3 次。- 若任务结束时间距离下次计划时间已超过
misfire_grace_time,则直接跳过。
更彻底的方案:自调度 + 超时控制(推荐用于耗时不确定任务)
对于耗时不确定或可能卡死的任务(如调用大模型 API),建议放弃 interval,改用 date 自调度 + asyncio.wait_for 超时,从根本上避免并发和堆积。
####### 示例 Demo:带超时保护的自调度任务
from apscheduler.schedulers.asyncio import AsyncIOScheduler
from datetime import datetime, timedelta
import asyncio
scheduler = AsyncIOScheduler()
async def call_slow_ai_api():
"""模拟一个可能很慢的大模型调用"""
print(f"[{datetime.now()}] 🤖 开始调用 AI 接口...")
await asyncio.sleep(120) # 模拟 2 分钟响应
print(f"[{datetime.now()}] ✅ AI 响应完成")
async def task_with_timeout_and_reschedule():
try:
# 设置最大执行时间为 180 秒(3 分钟)
await asyncio.wait_for(call_slow_ai_api(), timeout=180.0)
except asyncio.TimeoutError:
print(f"[{datetime.now()}] ⚠️ 任务超时,已终止")
except Exception as e:
print(f"[{datetime.now()}] ❌ 任务出错: {e}")
finally:
# 无论成功/失败/超时,30 秒后安排下一次执行
next_run = datetime.now() + timedelta(seconds=30)
scheduler.add_job(
task_with_timeout_and_reschedule,
"date",
run_date=next_run,
id="ai_polling_task",
replace_existing=True # 防止重复添加
)
print(f"[{datetime.now()}] 🕒 已安排下次任务: {next_run}")
# 初始化:启动时立即执行第一次
def init_ai_task():
scheduler.add_job(
task_with_timeout_and_reschedule,
"date",
run_date=datetime.now(),
id="ai_polling_task",
replace_existing=True
)
✅ 优势:
- 永远只有一个任务实例在运行
- 即使卡死,3 分钟后自动超时释放
- 下次任务总是在上一次结束后 30 秒开始,而非固定时钟点
- 不依赖
max_instances等“事后拦截”机制,而是从调度逻辑上杜绝并发
查看当前任务及其运行状态
APScheduler 提供了丰富的 API 来查询、监控和管理任务。你可以获取所有已注册任务的列表、查看其下次运行时间等信息。
⚠️ 注意:APScheduler 不直接提供“任务是否正在运行”的实时状态(因为任务是异步协程或线程),但可通过以下方式间接判断或管理。
####### 查看所有已注册任务(含未执行、已暂停、待触发)
# 获取所有 job 对象
jobs = scheduler.get_jobs()
for job in jobs:
print(f"ID: {job.id}")
print(f" 函数: {job.func.__name__}")
print(f" 触发器: {job.trigger}")
print(f" 下次运行时间: {job.next_run_time}")
print(f" 最大实例数: {job.max_instances}")
print("-" * 40)
输出示例:
ID: ai_polling_task
函数: task_with_timeout_and_reschedule
触发器: DateTrigger...
下次运行时间: 2025-12-10 10:15:30.123456+08:00
最大实例数: 1
----------------------------------------
📌
next_run_time为None表示该任务是一次性任务且已执行完毕,或已被移除。
动态管理任务:暂停、删除、关闭
你可以根据任务 ID 对未开始的任务或未来将执行的任务进行操作。
⚠️ 无法强制终止“正在运行中的异步任务”(这是 asyncio 的限制),只能取消尚未开始的调度。
####### 删除(取消)一个任务(包括未来所有执行)
# 删除指定 ID 的任务(无论是否已运行)
scheduler.remove_job(job_id="ai_polling_task")
print("✅ 已取消任务 ai_polling_task")
####### 暂停/恢复整个调度器
# 暂停所有任务触发
scheduler.pause()
# 恢复调度
scheduler.resume()
💡 如果只想暂停某个任务,可先
remove_job(),需要时再重新add_job()。
####### 安全关闭正在运行的任务(协作式取消)
虽然 APScheduler 不能直接 kill 协程,但可通过保存 asyncio.Task 引用实现协作取消:
_ai_task_ref = None
async def task_with_cancellation_support():
global _ai_task_ref
try:
_ai_task_ref = asyncio.create_task(call_slow_ai_api())
await _ai_task_ref
except asyncio.CancelledError:
print("🛑 任务被外部取消")
raise
finally:
_ai_task_ref = None
# 在其他地方取消
async def cancel_ai_task():
global _ai_task_ref
if _ai_task_ref and not _ai_task_ref.done():
_ai_task_ref.cancel()
try:
await _ai_task_ref
except asyncio.CancelledError:
print("✅ 任务已成功取消")
综合 Demo:任务管理接口(FastAPI 示例)
from fastapi import FastAPI, HTTPException
app = FastAPI()
@app.get("/tasks")
async def list_tasks():
jobs = scheduler.get_jobs()
return [
{
"id": job.id,
"func": job.func.__name__,
"next_run": job.next_run_time.isoformat() if job.next_run_time else None,
"trigger": str(job.trigger)
}
for job in jobs
]
@app.delete("/tasks/{job_id}")
async def remove_task(job_id: str):
job = scheduler.get_job(job_id)
if not job:
raise HTTPException(status_code=404, detail="Task not found")
scheduler.remove_job(job_id)
return {"message": f"Task {job_id} removed"}
通过该接口,你可以:
GET /tasks:查看所有调度任务DELETE /tasks/ai_polling_task:动态取消某个任务
总结对比表
| 触发器 | 执行方式 | 是否重复 | 典型场景 | 并发风险 | 推荐防护措施 |
|---|---|---|---|---|---|
date |
单次,指定时间点 | ❌ 否 | 延迟执行、一次性提醒 | 低 | 无(或自调度控制) |
interval |
固定间隔 | ✅ 是 | 轮询、心跳 | 高(若任务慢) | max_instances=1, coalesce=True |
cron |
日历规则 | ✅ 是 | 定时报表、定时清理 | 中(若任务跨周期) | 同上 + 合理设置 misfire_grace_time |
合理选择触发器类型并配置防护参数,是构建稳定、可靠定时任务系统的关键。对于高不确定性任务,自调度 + 超时是最安全、最可控的实践方式。同时,结合 get_jobs()、remove_job() 等 API,可实现灵活的任务监控与动态管理。
附:历史问题整合摘要
Q: AsyncIOScheduler 和 BackgroundScheduler 有什么区别?
- 核心差异:前者基于 asyncio(协程),后者基于线程;
- AsyncIOScheduler 用于异步项目(FastAPI + TortoiseORM);
- BackgroundScheduler 用于同步项目(Flask/Django);
- 混用会导致跨 loop 错误。
Q: 任务执行时间 > 间隔时间会怎样?
- 默认会并发执行多个实例,导致重复处理;
- 解决方案:设置
max_instances=1防止重叠。
Q: 同步函数能否在 AsyncIOScheduler 中使用?
- 可以,但会阻塞事件循环;
- 正确做法:用
await loop.run_in_executor(None, sync_func, ...)包装。
Q: misfire_grace_time 作用?
- 允许任务在“错过计划时间”后的一段时间内仍被执行;
- 默认 1 秒,建议设为 5~30 秒以容忍短暂延迟。
Q: max_instances=1 是否必要?
- 是!即使只注册一次任务,若执行时间 > 间隔,
max_instances>1会导致并发; - 对非幂等任务(如标记“已发送”),必须设为 1。
Q: BackgroundScheduler 适合用于多线程执行多个同步函数的场景吗?
- ✅ 是的。它通过内置线程池并发执行多个
def函数,适合 I/O 密集型任务; - 可通过
ThreadPoolExecutor(max_workers=N)控制最大并发线程数; - 不适合 CPU 密集型任务(受 GIL 限制),此时应使用
ProcessPoolExecutor。
Q: 如何控制 AsyncIOScheduler 的并发?
- 协程本身轻量,无需限制数量;
- 但需注意:
- 使用
max_instances=1防止单个任务重入; - 同步 I/O 必须用
run_in_executor,并可配置线程池大小控制其并发; - 下游服务(如 API、DB)的 QPS 限制才是实际瓶颈。
- 使用
💡 最佳实践总结:
- 同步项目 →
BackgroundScheduler+ThreadPoolExecutor(max_workers=N)- 异步项目 →
AsyncIOScheduler+max_instances=1+misfire_grace_time=10- 同步 I/O 在异步中 →
await loop.run_in_executor(pool, func, ...)- 任务持久化 → 配置
SQLAlchemyJobStore- 动态更新任务 → 使用
replace_existing=True
最佳实践
-
项目结构:
my_project/ ├── main.py ├── routers/ │ ├── users.py │ └── items.py ├── models/ │ └── __init__.py ├── schemas/ │ └── user.py └── config.py -
配置管理:使用 Pydantic
BaseSettings。 -
安全:密码哈希、JWT 认证、CORS 控制。
-
测试:使用
TestClient编写单元测试。
参考资源
📌 注意:本文档基于 Pydantic V2 语法。V1 用户请注意:
model.dict()→model.model_dump()validator→field_validatorOptional[T]仍可用,但推荐使用T | None

 浙公网安备 33010602011771号
浙公网安备 33010602011771号