BUAA_OO_U3_Summary
BUAA_OO_U3_Summary
上次的目录放岔劈了,看看这次的怎么样
一 / 架构设计
1.0> 题目解析
翻译jml。
1.1> HW9
1.1.1> 关于JML
开始之前一定要先读手册!因为在本单元的作业中,只要一字不落的完全按照JML书写,就一定不会出现问题,否则,有极大概率会出现错误。当然,这里不是说照搬JML中描述的实现方式,which leads to TLE,而是说所有JML明确了的如何计算结果的方式不要自创(后文会有关于报应的描写)。
但其实连蒙带猜也可以做,只是效率低。
作为理解,翻译已有的思路来说,这次作业相较之前的6次作业,甚至于与pre作对比,是能称上简单二字的。作为理解一门新的模型语言,也很好入手,毕竟表达式的语法与本身java的语言相似,我们需要掌握的规格限制条件较为清晰。再加之在上机和training中对我们书写JML规格的能力的拷打,本次作业乃至本单元在理解JML上的挑战相较递归下降、多线程渺小了太多。
1.1.2> 关于异常
本单元中,我们需要不断的抛接异常。
一开始,拿到一份只需要填写各个接口的实现的代码时,本人对于异常的抛接产生了极大的误会,并浪费了大量时间研究如果消除idea里的各种报错。
其实原理很简单:调用者接,被调用者抛。
代码上讲,呈现这样的现象:
调用者:
public void caller() {
try {
callee();
} catch (Exception e) {
/* 异常处理 */
}
}
若该方法会抛出多个异常,则只会处理第一个,所以被调用者需要考量一下抛出异常的顺序。
被调用者:
public void callee() throws Exception {
if(/* 进入异常的条件 */) {
throw new Exception();
}
/* 正常处理 */
}
当进入异常处理后(也就是throw后),后面的代码都不会再被执行,这里也需要被调用者考虑顺序。
在本人的实现中,所有的异常抛出都被放在了方法的起始位置,即先把所有的异常都抛完,再去执行需要完成的任务,以免产生复杂的判断,同时维持代码的清晰结构,方便在debug的时候定位错误。
1.1.3> 关于数据结构
此作业需要我们实现一个判断两人是否有间接关系的功能。虽然BFS/DFS等一种搜索方法都可以实现这样的功能,只是时间代价较大,于是此处本人采取用按秩合并的路径压缩并查集来实现。
也就是说,这个并查集有两个优化之处(以免在特定数据下变成一条链,使并查集的查找退化为 \(O(n)\) 的)。
- 向上求索时:
public MyPerson find(MyPerson person) {
if (!fa.get(person).equals(person)) {
fa.put(person, find(fa.get(person)));
}
return fa.get(person);
}
这个递归是进行路径压缩的过程,他被包含在了查找根节点的过程中。在递归返回的过程节点会不断把父亲的父亲直接变为父亲,使得最后整棵树的高度最大为2。
但是由于本人对java数据结构的接触太少,而且不熟悉各种容器,所以写出来的代码比较丑。
- 兼收并蓄时:
MyPerson p1 = find(getPerson(id1));
MyPerson p2 = find(getPerson(id2));
if (rank.get(p1) <= rank.get(p2)) {
fa.put(p1, p2);
} else {
fa.put(p2, p1);
}
if (rank.get(p1).equals(rank.get(p2)) && !p1.equals(p2)) {
rank.replace(p2, rank.get(p2) + 1);
}
按秩合并的过程同样是为了压缩这棵树的高度。对于一棵已经很高了的树,我们肯定不希望它变得更高——这样递归查询的时间会变长,于是此时我们选择把矮小的树接到高挺的树上。只有当二者长度相同时,合并后的树的长度才会变长,而且变化量为1。
1.1.4> 代码构架
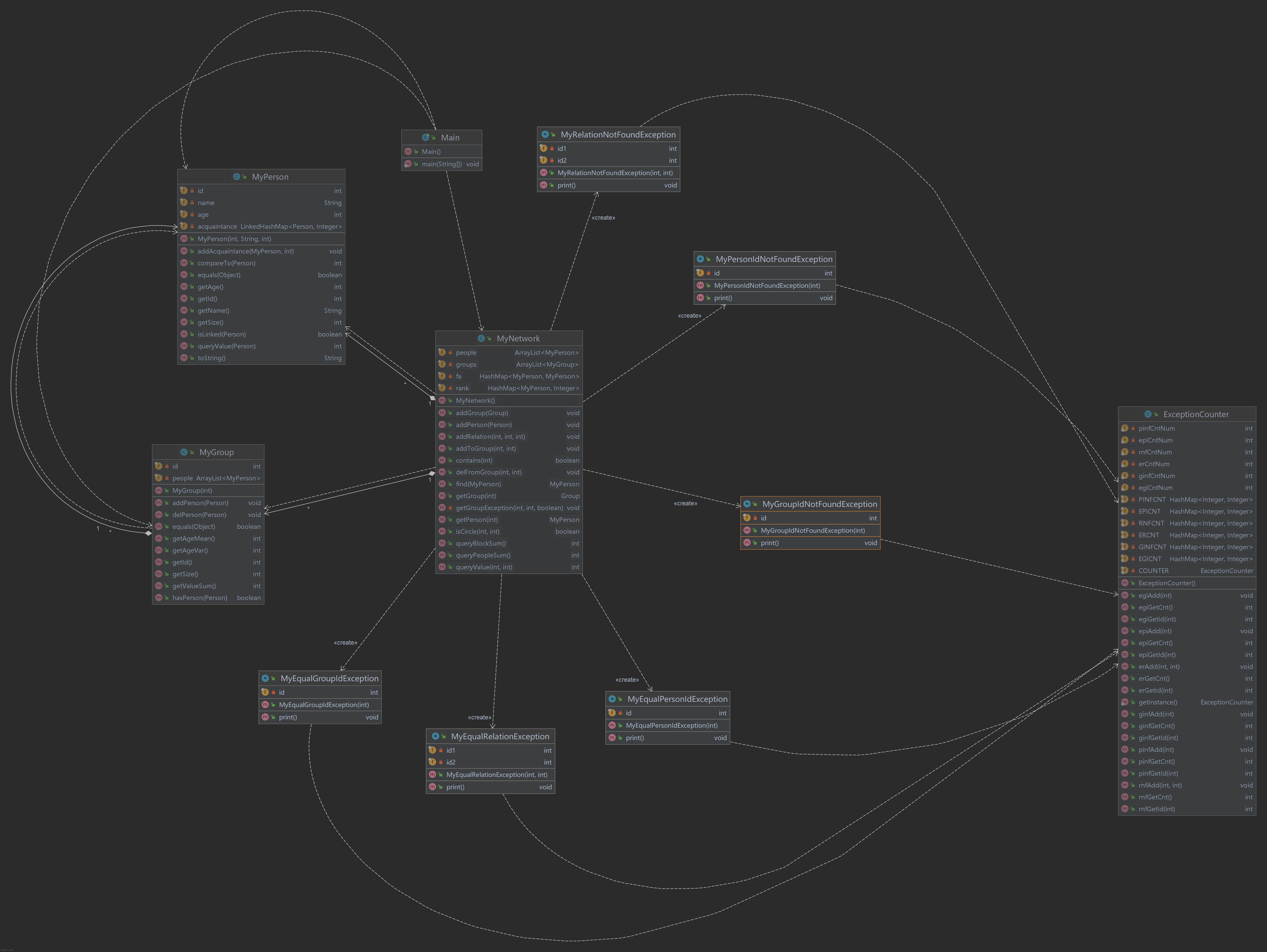
这次的作业除了按要求行事以外,没有拓展出任何新的类型,其中的所有方法也都是直接在为得到输出服务。没有什么新意,故不再展开。
主要分为处理异常的类(ExceptionCounter和各个Exception类)和负责完成搭建人际交往关系图的类(MyPerson / MyGroup / MyNetwork)。
1.2> HW10
依旧是翻译JML。
只不过这次需要增加获取最小生成树的功能了!
1.2.1> 迭代开发
同样的,这个单元的迭代开发也不需要再根据需求思考需要新增的功能,而是直接根据JML的约束写出最朴素的代码,然后再进行时间、空间上的优化。
1.2.2> 关于数据结构
对于QLC指令,经过第9次作业提交前的测试,能很快看懂这个JML规格的意思是让我们找到这个节点所在的连通块中的最小生成树。
本人一开始选用prim实现,后来优化为了堆优化实现的prim(然而两者长得很不相似),但其实这样的时间复杂度对于最后的结果影响不大——毕竟QLC指令的次数限制很严格,跑出来的差距可能也就只有1s左右。之所以选择堆优化的prim,除了处于复杂度的考量以外,同样还有对下一次作业是否会出现最短路的猜测(显然,猜对了),于是在这次作业便直接用链式前向星建好了图。
图,添加关系时加边即可。
MyNetwork:
定义建图需要的数组:
private static final int MAXN = 2000005;
private final HashMap<Integer, Integer> head = new HashMap<>();
private final int[] edge = new int[MAXN];
private final int[] next = new int[MAXN];
private final int[] weight = new int[MAXN];
private int idx = 0;
加边:
public void addEdge(int a, int b, int c) {
edge[idx] = b;
weight[idx] = c;
next[idx] = head.get(a);
head.put(a, idx++);
}
求最小生成树和后文的最短路需要的数组:
private final HashMap<Integer, Boolean> vis = new HashMap<>();
private final HashMap<Integer, Integer> dist = new HashMap<>();
private final PriorityQueue<Pair<Integer, Integer>> heap = new PriorityQueue<>(Comparator.comparing(Pair::getFirst));
1.2.3> 时间优化
最小生成树
从选取prim到堆优化prim已经是一个时间优化了,但这个不太注重全局过关注细节的蒟蒻却非要进行进一步的优化——如果整个连通块没有变化,就不需要重新求一遍最短路了,这是比较显然的优化方式。
这时又可以利用到并查集的优势。整个集合的最顶端的节点,不妨称为超级父亲,只有在两个集合合并的时候才可能发生变化。如果超级父亲变化了,那整个连通图一定变化了;如果超级父亲没有变化,但是发生了合并的操作,那整个连通图也一定变化了;如果超级父亲没有变化而且没有发生合并的操作,则连通图一定没有变化,之前的最小生成树依旧可以被使用。所以我们可以把这个最小生成树的答案绑定在整个连通块的超级父亲上,对应前文的三种情况,只需要将合并双方的超级父亲对应的答案标记为失效、失效、有效即可。
于是我选用了如下的HashMap来记录答案。由于没有负边权,所以这个字典也可以用来记录答案的有效性,因为失效可以用-1表示。
private final HashMap<Integer, Integer> lazyTag = new HashMap<>();
在合并两个分别以p1、p1为超级父亲的并查集时:
lazyTag.put(p1.getId(), -1);
lazyTag.put(p2.getId(), -1);
在堆优化的prim中,如果答案有效则直接返回:
if (lazyTag.get(tmp.getId()) != -1) {
return lazyTag.get(tmp.getId());
}
// prim
其间,本人也考虑过是否不需要跑prim,直接在合并的时候找到两个集合之间最小的边即可合并两个集合的答案。但是这样就会让复杂度变成 \(O(m \times log(m))\) 的(m为边数),当初选择prim就是因为感觉边数不可控,虽说不准数据会是稠密图还是稀疏图,但点数明确的给出了范围,所以涉及到点数的复杂度应该会更安全一些,这样合并的复杂度也不一定比再跑一次最新生成树低,所以舍弃了此想法。
其他指令
数据量比较大,而相较c来说,java又比较慢,所以需要关注一下超时的问题。实现困难+时间复杂度高的指令都已经被指导书约束了出现数量,在保证它们书写无误之后一定要去检查别的指令,一旦别的指令出现 \(O(n^2)\) 的时间复杂度,那恭喜你,一定会被卡成超时。
首先便是对于getValueSum的处理。按JML的做法,则需要通过:
/*@ ensures \result == (\sum int i; 0 <= i && i < people.length;
@ (\sum int j; 0 <= j && j < people.length &&
@ people[i].isLinked(people[j]); people[i].queryValue(people[j])));
@*/
这样的双重循环解决。规格虽如此,实现方法可以变更。由于getValueSum指令不限调用次数,时间复杂度又高,于是必须进行拆解。可惜本人意识到这个问题时已经进了互测并被hack了多次,只能在bug修复时调整方法。首先,我们直接对这个每个group对象维护一个valueSum属性,这个属性的变更发生在group中有关系发生变化时,即在以下三种情况中:该group添加person,该person与group中的一些人相互认识,需要加上各个关系的value;该group踢出该person,需要减去person与熟人之间的value;两个本不认识的person在进入同一个group之后被添加了关系,需要加上value。所以一个 \(O(n^2)\) 的方法就被拆解为了 \(O(n)\) 。
同样可以进行优化的还有getAgeMean和getAgeVar这样只涉及到算数的方法。但是本人考虑到 \(O(n)\) 的复杂度已经够用了,就没有再进行拆解,但是通过公式推导,在实现其他方案的同时维护答案,确实可以将这些方法的复杂度化简到 \(O(1)\) 。
1.2.4> 代码构架

同样的,此架构只是实现了所有需要实现的接口,其中只新增了一个泛型类Pair。但其实这个pair功能已经有包实现好了,即javafx.util.Pair,当时考虑到安装稍显麻烦于是动手自己写了一个。后来因为互测同房间内有人使用此库文件,故又将此库文件安顿到了环境中。可见造轮子这种事情,是没有必要的。
1.3> HW11
1.3.1> 迭代开发
翻译JML的约束。这次新增的规格主要是针对新的消息,所以主要任务就是新增message的子类,并实现各个规格。其中涉及到了最短路的实现。
1.3.2> 数据结构
建议在上一次作业中考虑到了建图的问题,并且采用了堆优化prim来求得最小生成树,所以尽在最小生成树的代码上改掉了松弛条件的判断(或者说,把树上的一条边长变成了路径长度),只需要两行就变成了spfa,感觉非常方便。如果当时没有对prim进行优化,也可以在保障时间复杂度的情况下,不需要用前向星建邻接表,直接用邻接矩阵就可以实现prim,并比较容易的改成dijkstra(这次作业保证了边权非负)。(所以此次作业的完成时间大概是所有oo作业中最短的。主要的时间花在了大量的对拍测试上。)
这里本人也考虑过像之前的最小生成树一样存储答案,但是感觉实现困难,而且在当前答案是否有效的判定上难以给出一个简便方法,所以没有做任何记忆化有关操作。
1.3.2> 代码构架
在HW10的基础上,增加了几个message类型以及他们的异常处理类,此外没有新建任何类,完全按照JML规格撰写。
二 / 测试设计
2.1> 评测
很可惜,多次查阅JUnit的使用方法,本人依旧没能学会如何利用其功能来做单元测试,所以依旧采用了python语言来写评测姬。对于这一单元,评测的主要思路便是再用python实现一遍java所做的事情。所以评测的内容也因为时间有限而未能完全覆盖,最后还是采用了多人对拍的方式进行测试。
主要运用了评测姬的部分是人与人的关系统计之处,比如isCircle,QLC等方法,对于所有的收发信息,群组管理,都是由对拍进行测试。
评测的基本思路是,人为操作下的随机。每条指令都是单独的函数,负责制造输入的命令和正确答案。指令的类型在被调用的时候人为确定该指令的执行数量和顺序,但是指令的具体内容,比如ap的人名、序号,都是在约定范围内随机生成的。敢于随机的原因是这次的代码有异常处理,所以每一行输出都能快速根据行数找到对应的输入,方便debug。
2.2> 对拍
对拍是非常省力的一个做法,即只需要提供输入数据,不需要提供答案。于是重任就落在了如何造有效数据的肩上。
首先,这个单元的程序大致可以分为三个部分:只考虑人与人的关系(加人,加关系,测试并查集的正确性,最小生成树和最短路的正确性等);只考虑group的存在(增删人,平均年龄等);加入Message,同时考虑人和group(这里又可以分为不同类别消息的测试,所以依旧是先分再合的思路,先测试单一种类的message,确保无误了再进行全面测试)。
本人一开始继承了之前评测机的写法,采用随机数进行覆盖,但是发现输出大部分都是各种异常处理(所以没有单独设置异常处理的测试,因为多跑几组随机的基本上异常处理就都覆盖了),对于指令正常行为的测试实在是有些低效,所以把每个指令的具体内容也变成了人为定义。于是数据强度就上来了,效果可见后文的捉虫部分。
本单元第二次作业的互测中,在本人的幡然醒悟下,也针对性的造了一些容易TLE的数据,同时将这种思路放在了第三次作业的测试中。
三 / 捉虫大战
3.1> 自己的问题总结
3.1.1> HW9
在第一次作业中,我的强测可谓惨死,但原因竟是——typo!在add to group的时候,把判断group id存不存在写成了判断person的id存不存在,是一个很明显的错误,但是中测和自己的评测(那个时候还是全盘随机,覆盖率太低了)都没能测出来。
但其中还隐藏了另一个错误,至今我仍未能复现出来,对于其错误的原因也没有很深刻的理解,再者手里只有一个最终被化简到6000行(但还是太长了)的强测数据8号,太难分析了。其表现是,如果使用TreeMap来存储并查集的父子关系,就会导致最后的。目前猜测的原因是,如果要使用TreeMap,必须重写Comparator方法,否则没有排序数,如果排序数一样,那就不能被插入进去。所以很有可能是由于本人没有重写Comparator也没有重写Hashcode的缘故,导致了哈希冲突,使得本应输出212的集合大小被算成了210。
> HW10
自测和强测并未发现错误,但是由于TLE问题被互测中Hack的很惨。
> HW11
自测发现红包金额算错了。原因在于没有完全按照JML的规格实现,而是用了自己意会后的思路进行了红包金额的发放。但是这个红包金额的计算方式真的充满怪异——比如群发一个9块钱的红包,发5个,实际上是不能发的,因为整除后相等于只能发5块钱的红包,最后发送者扣4块钱,群聊中每个人拿到一块钱。而本人的方法则直接把9块钱扣除了,然后每个人再加上一块钱——只能说老板亏得很惨。
第二个错误在于,sim的时候没有删除发出去的message,导致这个message后来又被发了一遍。
第三个错误是源于在处理sendMessage的时候没仔细看jml,于是在coldEmoji被删除后,那些用了被删除的表情包的待发送message还在队列里,等到要发出去的时候,从emoji列表中得到的是null,于是就报错了。
可见都是没有仔细阅读JML,从而导致的不符合规格的错误。
强测互测未被发现问题。
3.2> 互测他人问题总结
3.2.1> HW9
这次互测时令人崩溃的——因为本人的评测姬根本跑不到第二组数据,就会被各种奇怪的输出拦住。
- 对于equalRelationError的判定,由于本人出过问题,所以进行了一些hack工作:
ap 1 name1 1
ar 1 1 1
自己和自己一定是link的,这里是JML明确说明了的。所以这种情况还输出Ok的(两人次),输出er-1, 1-2, 1-2的,就是错误的。
- 输出有多余换行
输出方式:System.out.printf("%s-%d, %d-%d, %d-%d%n%n",···);
- 大家的qbs各有各的问题
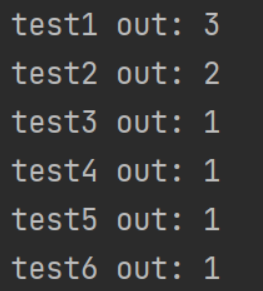
有的是没考虑孤立的点,有的是单纯算错了。
- NullPointerException
查阅代码,发现其中用了ArrayList<MyPerson> set1 = null;,后续又跟进了assert set1 != null;的语句。于是代码很听话的给它报了错。
- exception输出的id顺序错误
test6 out: er-1, 6-1, 1-1
- typo
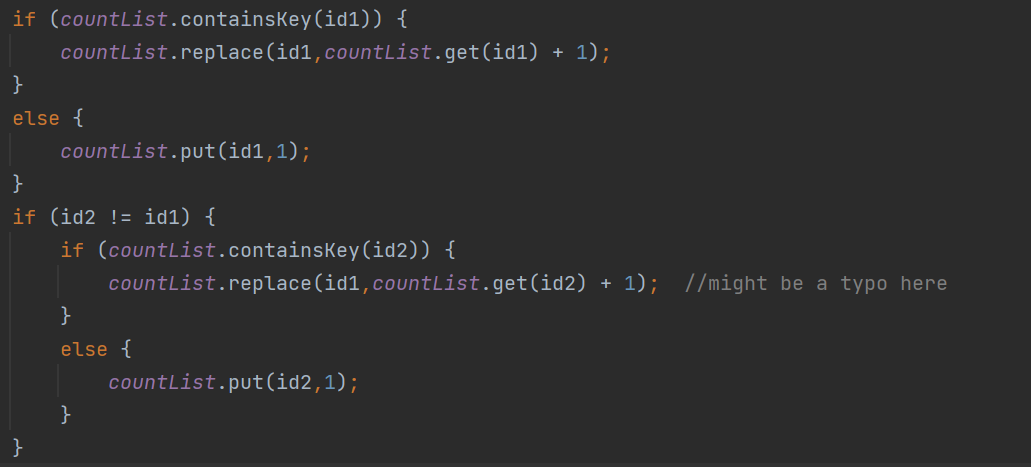
- qci出现死循环(代码没看懂所以总结不出错因)
3.2.2> HW10
-
有同志没有看到群组人数上限是1111
-
用自己会TLE的(包含大量qsv的)数据hack了3个人,可见忘记了这里还有个 \(O(n^2)\) 复杂度方法的不只我一人。
除此之外没有跑出什么新奇的错误了。
3.2.3> HW11
-
考虑到自己之前的红包钱数算错,于是也针对红包的收发进行了测试。果不其然,也有同学在这里栽了跟头。但是强测居然没有这样的数据也是一件令人费解的事。
-
deleteColdEmoji的错误
两人次,分别是nullPointerException和由于没删除抛出的错误异常信息。
- sim计算错误,具体代码未仔细阅读所以不太清楚具体错误在什么步骤。
所以总结来看,错误一共是两种类型:没有仔细看JML;删除方法选择不当导致指针飞了。
四 / Network扩展
假设出现了几种不同的Person:
Advertiser:持续向外发送产品广告
Producer:产品生产商,通过Advertiser来销售产品
Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等。请讨论如何对Network扩展,给出相关接口方法,并选择3个核心业务功能的接口方法撰写JML规格(借鉴所总结的JML规格模式)。
4.1> 市场营销
这里我们假设,只有发了广告的产品可以被销售出去,发的广告数量意味着产品可以被生产的数量。发放广告的数量设为AdvertiseNum,广告对应的商品为AdvertiseProduct,广告对应的id为AdvertisementId。每个Product都对应id,价格两个属性。
/*@ public normal_behavior
@ requires !(\exists int i; 0 <= i && i < advertisement.length; advertisement[i].equals(adv));
@ assignable advertisement;
@ ensures advertisement.length == \old(advertisement.length) + 1;
@ ensures (\forall int i; 0 <= i && i < \old(advertisement.length);
@ (\exists int j; 0 <= j && j < advertisement.length; advertisement[j] == (\old(advertisement[i]))));
@ ensures (\exists int i; 0 <= i && i < advertisement.length; advertisement[i] == advertisement);
@ also
@ public exceptional_behavior
@ signals (EqualAdvertisementIdException e) (\exists int i; 0 <= i && i < advertisement.length;
@ advertisement[i].equals(adv));
@*/
public /*@ pure @*/ int AddAdvertise(Advertisement adv) throws EqualAdvertisementIdException;
4.2> 查询销售额
这里,购买是指消费者通过广告商给相应生产者发购买消息。所以我们需要一个新的消息类型purchaseMessage,具有消费者id和生产者id两个属性,每当生产者收到这样一个消息,则产品减少一个,销售额增加一个,钱数增多,消费者则是钱数减少,拥有的产品增加。
于是要实现这个方法,需要在Network中对sendMessage进行增添:
/*@ public normal_behavior
@ requires ...
@ assignable ...
@ ...
@ ensures (\old(getMessage(id)) instanceof purchaseMessage) ==>
@ (\old(getMessage(id)).getPerson1().getMoney() ==
@ \old(getMessage(id).getPerson1().getMoney()) - ((purchaseMessage)\old(getMessage(id))).getMoney() &&
@ \old(getMessage(id)).getPerson2().getMoney() ==
@ \old(getMessage(id).getPerson2().getMoney()) + ((purchaseMessage)\old(getMessage(id))).getMoney());
@ ensures (\old(getMessage(id)) instanceof RedEnvelopeMessage) ==>
@ (\old(getMessage(id)).getPerson1().getProducts() ==
@ \old(getMessage(id).getPerson1().getProducts()).add(
((purchaseMessage)\old(getMessage(id))).getProduct()) &&
@ \old(getMessage(id)).getPerson2().getProducts() ==
@ \old(getMessage(id).getPerson2().getProducts()).delete( ((purchaseMessage)\old(getMessage(id))).getProduct()));
@ ...
@ also
@ public exceptional_behavior
@ signals ...
@*/
public void sendMessage(int id) throws
RelationNotFoundException, MessageIdNotFoundException, PersonIdNotFoundException;
4.3> 销售路径
这个不是很好处理,因为需要记录这个产品的路径。但是我们可以对产品这个对象进行记录,每个产品有自己的id,通过一个ArrayList属性记录整个过程中产品经手的personId即可。这个处理和Network无关,所以规格比较简单。
/*@ public normal_behavior
@ requires containsProduct(id);
@ ensures \result == getProduct(id).getRoute();
@ also
@ public exceptional_behavior
@ signals (ProductIdNotFoundException e) !containsProduct(id);
@*/
public /*@ pure @*/ List<Integer> queryProductRoute(int id) throws ProductIdNotFoundException;
五 / 心得体会
刚熬过电梯月,在远离了多线程之后,眼中、手下、键盘上,仿佛什么都清晰了一样。
或者说,有了规格的约束,要完成的任务变得更加清晰。它给好了框架,但不在意实现过程,给定了明确地起点,告诉大家预期结果,怎么走都是自由的。这是面向对象思想的体现,利用的高度抽象,清晰明确的展现需求,不考虑步骤而关注功能,不注重过程而关注行为*。这完全为解决问题提供了新的视角,也为本人对面向对象的理解更加深入。
但是关于JML的资料,从网上查找的情况来看,比较稀少,大部分查到的都是往届学长学姐的博客(笑),经常点开一看,标题是第三单元总结。不过对于此单元来说,下发的说明文档已经足够使用了。于是JML读起来变得简单了,但是真的自己手写JML,以蒟蒻这么多次经历来看,恐怕是难以把这个元器件的每个面的每个细节都描述清楚(——从而消除掉未定义的警告)。同时,此单元虽然前有training,后有各个博客的介绍,但本人依旧没能学会如何使用JUnit,这着实是一件憾事。
*Last Unit to go!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号