



数据降维(特征提取)和特征选择有什么区别?
Feature extraction和feature selection 都同属于Dimension reduction。要想搞清楚问题当中二者的区别,就首先得知道Dimension reduction是包含了feature selection这种内在联系,再在这种框架下去理解各种算法和方法之间的区别。
和feature selection不同之处在于feature extraction是在原有特征基础之上去创造凝练出一些新的特征出来,但是feature selection则只是在原有特征上进行筛选。Feature extraction有多种方法,包括PCA,LDA,LSA等等,相关算法则更多,pLSA,LDA,ICA,FA,UV-Decomposition,LFM,SVD等等。这里面有一个共同的算法,那就是鼎鼎大名的SVD。
SVD本质上是一种数学的方法, 它并不是一种什么机器学习算法,但是它在机器学习领域里有非常广泛的应用。
PCA的目标是在新的低维空间上有最大的方差,也就是原始数据在主成分上的投影要有最大的方差。这个是方差的解释法,而这正好对应着特征值最大的那些主成分。
有人说,PCA本质上是去中心化的SVD,这可以看出PCA内在上与SVD的联系。PCA的得到是先将原始数据X的每一个样本,都减去所有样本的平均值,然后再用每一维的标准差进行归一化。假如原始矩阵X的每一行对应着每一个样本,列对应着相应的特征,那么上述去中心化的步骤对应着先所有行求平均值,得到的是一个向量,然后再将每一行减去这个向量,接着,针对每一列求标准差,然后再把每一列的数据除以这个标准差。这样得到的便是去中心化的矩阵了。
我在整理相关文档的时候,有如下体会:
我们的学习是什么,学习的本质是什么?其实在我看来就是一种特征抽取的过程,在学习一门新知识的时候,这里一个知识点,那儿一个知识点,你头脑里一篇混乱,完全不知所云,这些知识点在你的大脑中也纯粹是杂乱无章毫无头绪的,这不正是高维空间里数据的特征么?最本质的数据完全湮没在太多太多的扰动中,而我们要做的就是提炼,从一堆毫无头绪的扰动中寻找到最本质的真理。
经过一段时间的摸索,你上升到了一个台阶,从这个台阶上去看原来所学到的知识点,你突然之间豁然开朗,原来TMD这些概念,这些知识点都TM是想通的。为什么你原来却从这些知识点中看不到任何联系呢?原因就在于你之前的维度太高,而你永远只能在这个杂乱无章的高维空间里窥探到真理的一些细枝末叶,本来在低维空间里相互联系的事物,由于你看到的是这些事物在各个方向各个领域里的一部分投影,你所学到的只是这些投影,那你如何仅仅依靠这些少量的投影以管窥豹呢?不可能的,所以你的知识只能是杂乱无章,毫无头绪的。但是,一旦你所拥有的投影越来越多,你所学到的知识点越来越多,你就逐渐拥有了依靠投影获取全貌的能力,这个时候你会发现,哇,原来过去的那些都是想通的。这就是高维空间里杂乱无章的知识点,经过降维后,回归到了最本质特征的全过程。
从今以后,你可以只拿着这个低维空间里的真理,摒弃掉以前学习到的任何细枝末叶的东西,然后在任何需要的时候,经过这个降维的逆算法去还原到你所学到的知识点。
那么,人与人之间的区别在哪里呢?那就是,对任何一个新领域的知识点建立一套降维工具的能力。
反观SVD,PCA,LSA等等,它们做的不正是这些么?比如在文本分类领域,最初始的数据是将文档表示成向量空间模型的一个矩阵,而这个矩阵所拥有的就是不同的词,这里一个词,那里一个词,对于我们人类来说,我们都已经拥有将不同词在低维空间上总结归纳的能力,知道这些词的联系和区别,但是对于计算机来说,它们怎么知道这些的联系呢?也就是它们根本还不拥有这些降维的能力,那么就要依靠我们人类告诉它们这个方法,这个工具就是SVD,其核心思想就是:将这些不同的词都映射到低维空间中去,在低维空间中去总结,去发现这些词的内在联系,一旦这些内在联系建立了,那么我们就知道了这些文档的内在联系了。这不正是高维空间里杂乱无章的数据经过降维工具之后获取到最本质的特征么。这正是特征抽取所要做的事情。
最后总结之:
1. 特征提取是从杂乱无章的世界中,去到更高层的世界去俯瞰原始世界,你会发现很多杂乱无章的物理现象中背后暗含的道理是想通的,这时候你想用一个更加普世的观点和理论去解释原先的理论,这个是特征提取要做的事情。
2. 而你仍呆在原始世界中,只是想对现有的“取其精华,去其糟粕”,这个是所谓特征选择。只是对现有进行筛选。
3. 特征提取和特征选择统称为降维。(Dimension Reduction)
上图:
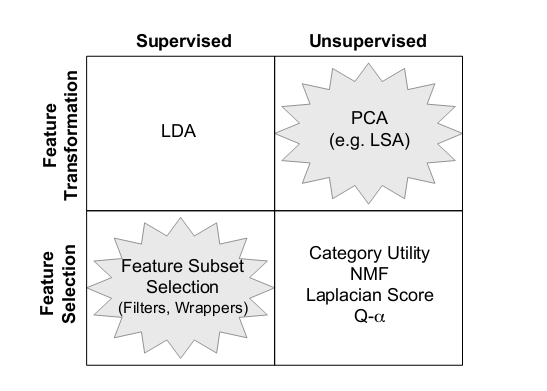
所以,你一定要在无监督文本上筛选特征,那么目前看来比较好的方法是放弃feature selection,而用feature extraction, 也就是上图中的feature transformation.
1. 如开头所提到的问题中的回答,最常见的特征类型是词汇/词语,利用Chi-squre进行特征选取,利用TFIDF作为特征权重。这也是搜索引擎和文本分类中最通用鲁棒的做法。
2. 对于短文本,如微博、查询词、社区问答系统中的提问问题等,利用基于词汇的特征向量空间计算相似度会面临比较严重的数据稀疏性问题,解决的方案是利用隐含主题模型等方法,建立词汇之间的相似度。具体方案可以参考2008年发表在WWW上的一篇论文:Learning to classify short and sparse text & web with hidden topics from large-scale data collections。需要注意的是,在LDA的原始论文中作者就尝试仅用文档主题来作为特征进行分类,但经验表明,仅用隐含主题的特征表示效果明显弱于使用词汇的特征表示方案。实用的做法是将两者相结合。
3. 2007年有研究者在IJCAI的论文中提出利用维基百科中的概念表示单词和文档,取得较好效果:Computing Semantic Relatedness Using Wikipedia-based Explicit Semantic Analysis。它的优点是可以做任意长度文本的特征表示,由于它将所有单词和文档都表示为维基百科词条数目长度的向量,因此具有较强的表达能力,但问题就是计算效率的问题。一个可行的解决方案是限制每个单词或文本只在几百万维的少数概念/词条上取值。
像微博这种短文本的分析,用什么方法提取特征比较好呢?
在短文本的主题模型有一些研究工作,我没有全面做过调研,自己了解的包括:
1. KDD 2014上来自Twitter团队的Large-Scale High-Precision Topic Modeling on Twitter,对Twitter数据上进行主题模型建模做了大量定制化工作。
2. WWW 2008上的Learning to classify short and sparse text & web with hidden topics from large-scale data collections,专门研究如何用主题模型帮助解决短文本类分类的稀疏性问题。
3. ECIR 2011上的Comparing twitter and traditional media using topic models提出TwitterLDA,假设每条短文本只属于一个隐含主题,属于专门针对短文本隐含主题建模所做的合理性假设。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号