

软工作业2-个人项目
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 完成首个个人项目论文查重程序 |
项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | 455 | 640 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 10 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 180 | 300 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 80 | 80 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 435 | 760 |
计算模块接口的设计与实现过程
一共6个类:
mian:主函数入口
GlobalData:静态存储全局变量,停用词列表,答案输出地址
FileUtil和SimHashUtil:工具类,FileUtil对文件进行预处理,SimHashUtil使用simhash算法对文章进行相似度检测
Article:实体类用于存储文章数据,流,编码等
GlobalConstant:静态常量,用于存储比特位数,分词大小,资源文件地址
关键函数流程:
SimHashUtil.simHash(List<List
FileUtil.readAndHandleFile(Article article, int chunkSize):获取传入的article流,对文章内容进行分段处理防止OOM,调用hanlpWordSegmentation(chunk, chunkSize)对文章进行分词,去除换行符停用词,转化同义词再对分好的词进行分段,调用SimHashUtil.simHash获取最终指纹
独到之处:
文章分段有效防止超大文本处理导致的oom
去除停用词,同义词统一转化极大提高对同义文本相似度判断精准度
分词分段对分词进行分段处理,提高精准度
性能分析
各函数执行一万次耗时占比
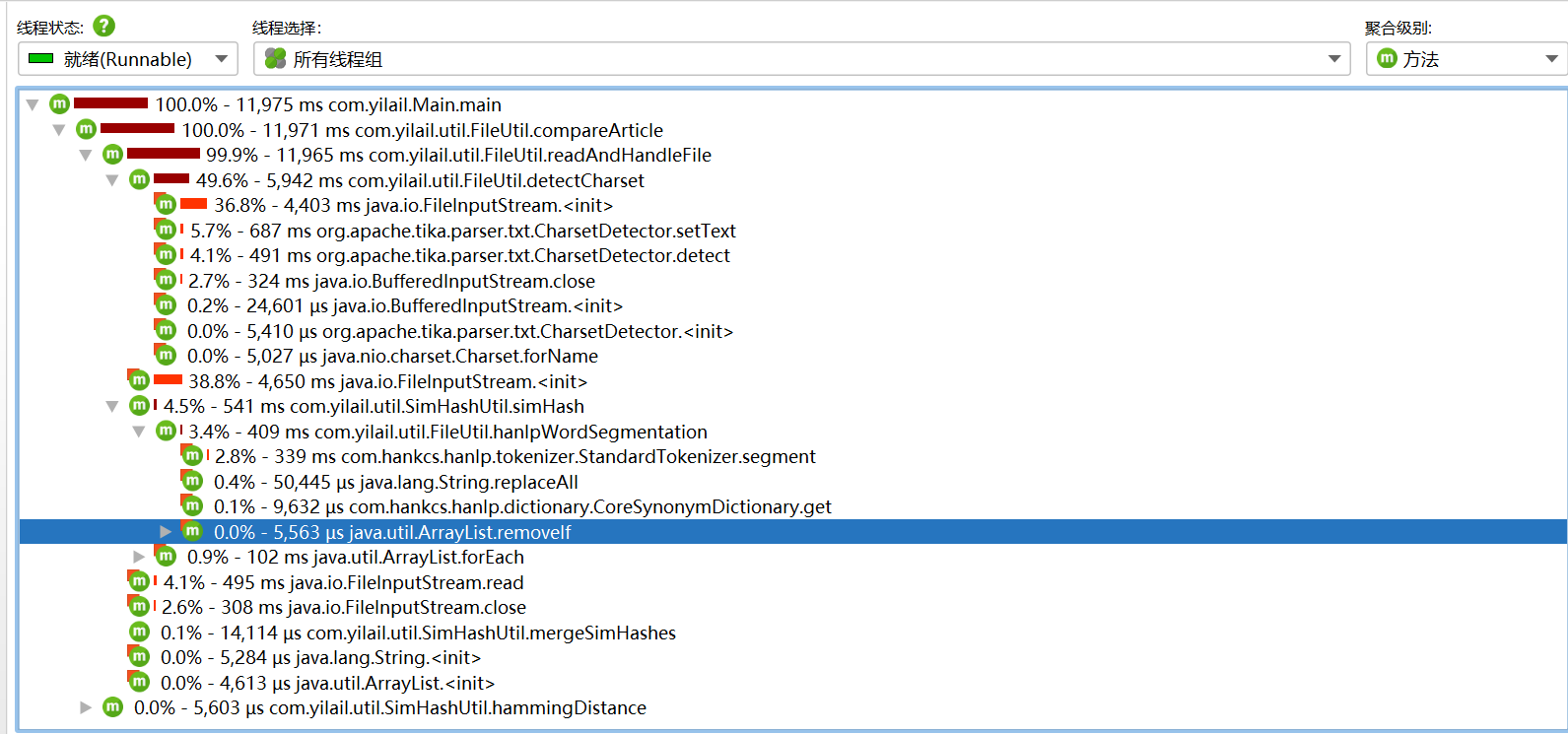
图中可知非库函数中io流耗时占比最大,因为每次处理文件都会读取两次io流
优化后占比
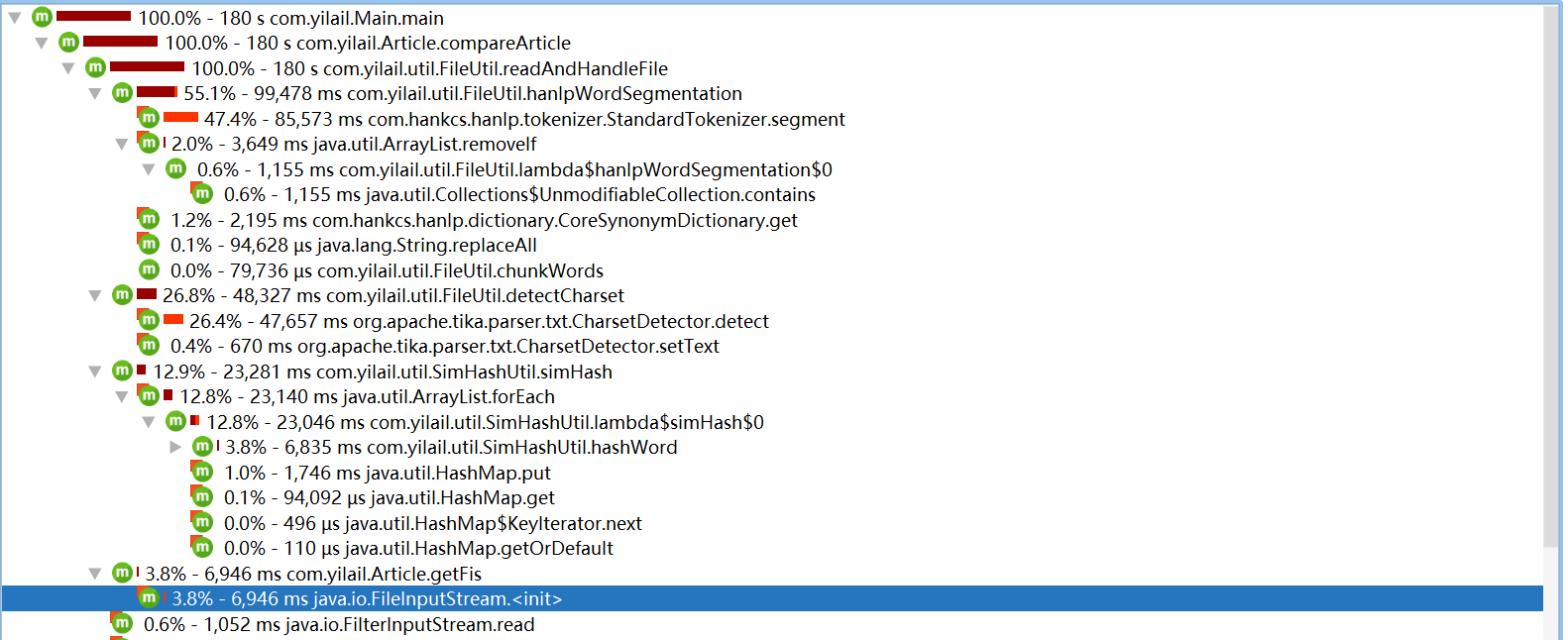
存储输入流,减少io次数,极大优化性能
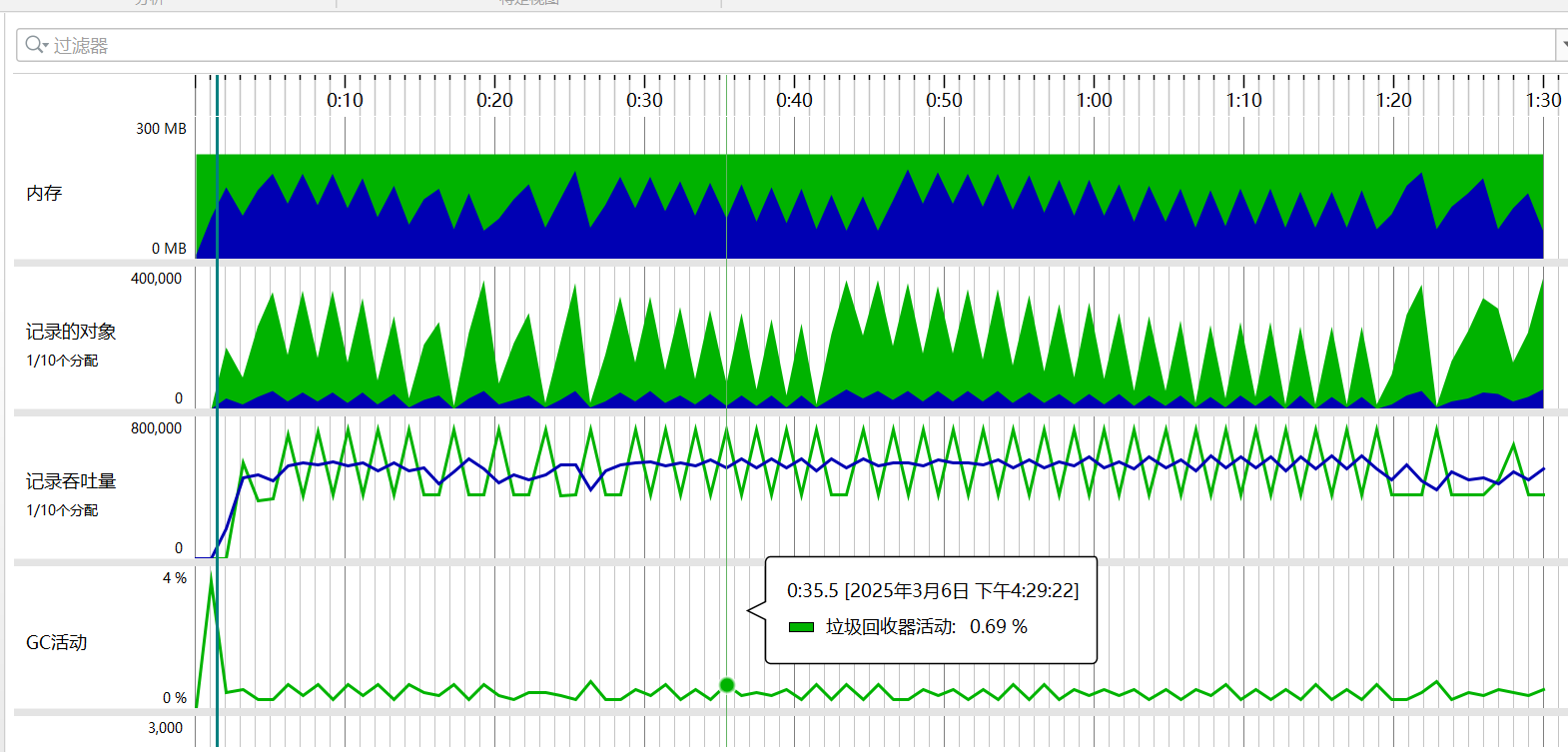
文章分段处理防止OOM
单元测试覆盖率
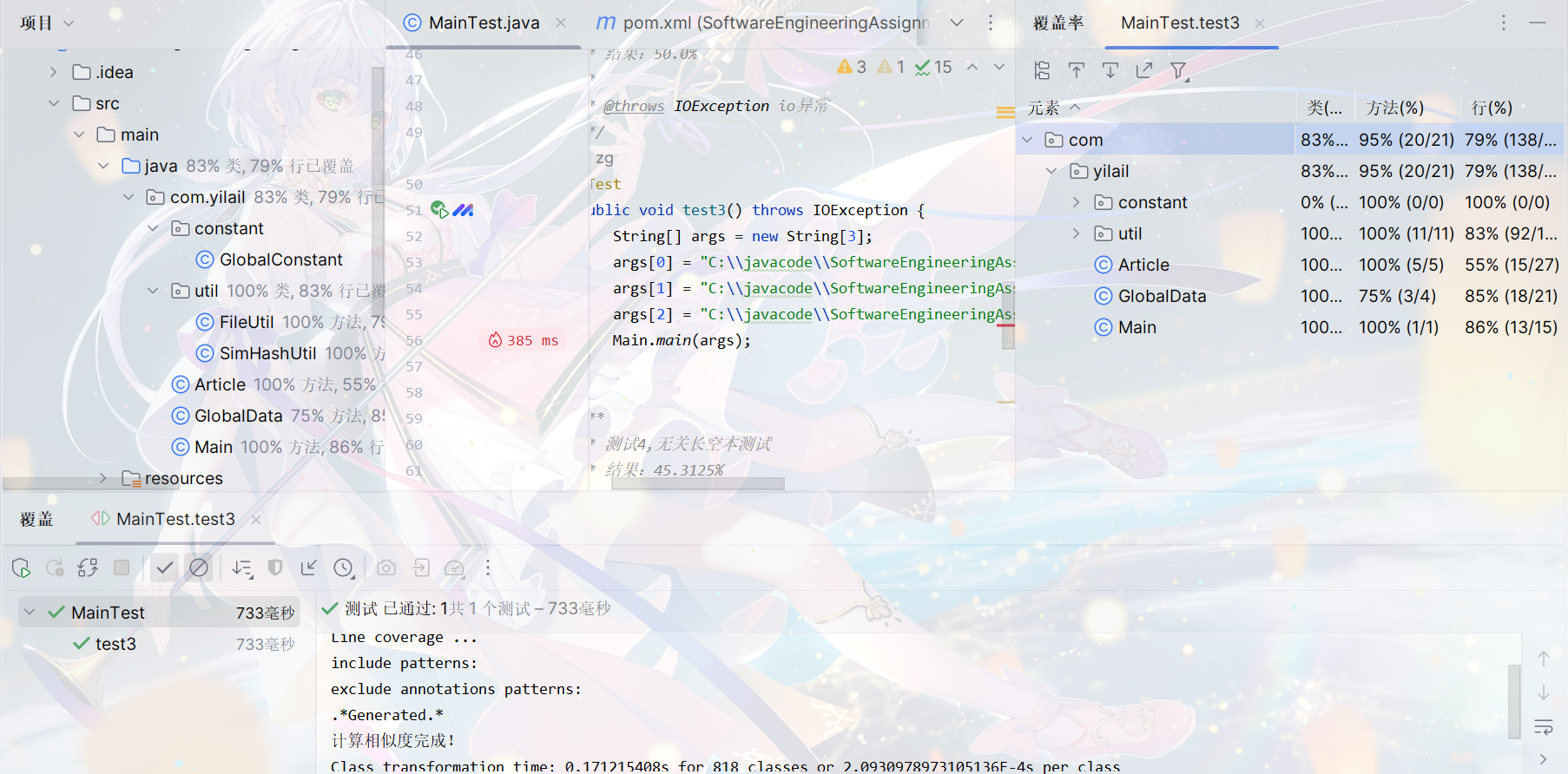
测试长短空文本各种情况
异常处理
停用词资源失效

传入文章文件不存在(答案文件同理)

文件编码格式错误



 浙公网安备 33010602011771号
浙公网安备 33010602011771号