
Elasticsearch的几种架构(ELK,EL,EF)性能对比测试报告
Elasticsearch的几种架构性能对比测试报告
1.前言
选定了Elasticsearch作为存储的数据库,但是还需要对Elasticsearch的基础架构做一定测试,所以,将研究测试报告输出如下。
2.日志系统架构的基础
2.1所需环境和依赖软件
1)Elasticsearch:分布式存储数据库,用于存储产生的日志,是架构和系统的核心所在。
2)Filebeat:轻量级日志收集器,可以自动将日志发送至Es或者logstash
3)Logstash:日志收集/清洗工具,将日志过滤,清洗后可以放入Es,并且可以减缓Es的访问压力,控制写入速度。
2.2日志系统架构的基本思想
日志系统中,读写功能应该是最重要和最需要优化的地方,在不断的有日志写进和读取的情况下,我们需要做到如下几点:
1)缓解Es的读写压力
2)降低日志系统资源占比
3)能够处理日志系统一般的异常情况(如宕机等)
4)提高日志系统的健壮性和可用性
3.日志架构的对比评测
3.1测试环境
|
机器环境 |
机器内存 |
机器CPU |
机器IP |
|
Centos7 |
6G |
4 |
10.0.6.244 |
|
Centos7 |
6G |
4 |
10.0.6.247 |
|
服务名 |
版本 |
包大小 |
|
Elasticsearch |
6.3.2 |
91M |
|
filebeat |
6.5.1 |
11M |
|
logstash |
6.5.1 |
161M |
3.2单纯的Elasticsearch 集群
不需要任何转发日志,缓存日志服务。直接接入Es的api写入日志,没有中间层,直接访问Es,读写都是如此。详细如下图:

直接通过封装好的Es_api进行数据读写,在上层将数据进行清洗或者是处理之后写入Es。
测试分别导入500,1000,10000条数据。
Elasticsearch占用资源和系统压力如下:
|
导入数据 |
Es占用内存 |
Es占用CPU |
导入时间 |
|
500条日志 |
22.3%(占用) |
2.3% |
1-3S |
|
1000条日志 |
22.6%(占用) |
2.3%-12% |
2-6S |
|
10000条日志 |
22.9%(占用) |
2.3%-40% |
9S |
适用场景:日志不多,但是需要分布式的系统,一万条数据存储的index大概是1.3M,两台机器就是2.6M。
优点:
方便,开箱可用,模块已经写好了,直接上就可以,不需要其他依赖。数据格式可控。输出方便。
缺点:
这种架构忽略了宕机和分片损坏的情况,如果宕机的话,Es选举节点时无法导入数据,这样会造成数据丢失。在机器资源不足的情况下,导入大规模数据的时候Es会卡死。需要在代码层做处理,例如分批导入或者设置最大的导入数据值,增加代码冗余量。
3.3 Elasticsearch 搭配 filebeat
什么是Filebeat:
Filebeat是一个日志收集器,Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者logstarsh中存放。
FIlebeat如何工作:
当你开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
通过filebeat的机制,将指定日志的log文件自动收集然后发送到Es中。中间不会直接对接Es接口,可以指定传输进Es的条数。可以指定日志。
详细逻辑如下图:

Filebeat可以将日志转发给logstash或者Es。
测试导入数据:
|
导入数据 |
Es占用内存 |
Es占用CPU |
Filebeats内存 |
导入时间 |
|
500条日志 |
22.3%(占用) |
2.3% |
1.32% |
1-2S |
|
1000条日志 |
22.6%(占用) |
2.3%-10% |
3.47% |
2-4S |
|
10000条日志 |
22.9%(占用) |
2.3%-20% |
6.7% |
7-12S |
适用场景:
数据量大,日志数量多,服务器资源有限的分布式日志系统。
原理和架构逻辑:
通过Filebeat这个日志生成器从指定的日志文件进行日志收集,收集到日志文件之后,将日志文件传输至logstash或者Elastaticsearch,并且FIlebeat有智能判断,可以断点续传,可以从上次断掉的位置继续接力传输,只要log文件在更新,那么Filebeat的传输将不会停止。
优点:
断点续传,直接输入Es,速度快,避免直接写入Es造成服务器压力过大,资源占用小,可以做简单的分类。可以指定每次传入条数等。
缺点:
不能进行数据清洗,数据杂乱,只能做简单的日志传输器用。
3.4 Elasticsearch 搭配logstash
什么是logstash:
Logstash 是一个轻量级、开源的服务器端数据处理管道,允许各种来源收集数据,进行动态转换,并将数据发送到希望的目标。它最常用作 Elasticsearch 的数据管道,Elasticsearch 是一个开源分析和搜索引擎。由于它与 Elasticsearch 紧密集成,具备强大的日志处理功能并提供 200 多个预构建的开源插件来索引数据,因此 Logstash 是将数据加载到 Elasticsearch 的常用工具。
Logstash的工作原理:
Logstash 内部也是管道的方式进行数据的搜集、处理、输出。在 Logstash 中,包括了三个阶段:
输入 input --> 处理 filter(不是必须的) --> 输出 output。
每个阶段都由很多的插件配合工作,比如 file、elasticsearch、redis 等等。
每个阶段也可以指定多种方式,比如输出既可以输出到 Elasticsearch 中,也可以指定到 stdout 在控制台打印。
Logstash的工作逻辑如下图:
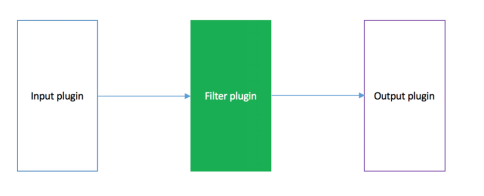
测试导入数据:
|
导入数据 |
Es占用内存 |
Es占用CPU |
logstash内存 |
导入时间 |
|
500条日志 |
23%(占用) |
1.0% |
11.4% |
1-2S |
|
1000条日志 |
23.2%(占用) |
2.3%-13% |
16.3% |
10-22S |
|
10000条日志 |
22.9%(占用) |
5%-32% |
17.2% |
30-33S |
Logstash优点:
1.可伸缩性
2.节拍应该在一组Logstash节点之间进行负载平衡。
3.建议至少使用两个Logstash节点以实现高可用性。
4.每个Logstash节点只部署一个Beats输入是很常见的,但每个Logstash节点也 可以部署多个Beats输入,以便为不同的数据源公开独立的端点。
5.弹性:Logstash持久队列提供跨节点故障的保护。对于Logstash中的磁盘级弹 性,确保磁盘冗余非常重要。
6.可过滤:对事件字段执行常规转换。可以重命名,删除,替换和修改事件中的 字段。可扩展插件生态系统,提供超过200个插件,以及创建和贡献自己的灵活 性。
Logstash缺点:
Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数 据丢失隐患。Logstash设置jvm小了启动很慢或者会启动失败。
3.5 Elasticsearch 搭配logstash和Filebeat
架构图如下所示:

这种架构在日志数据源和 Logstash(或 Elasticsearch) 中增加了 Beats 。Beats 集合了多种单一用途数据采集器,每款采集器都是以用于转发数据的通用库 libbeat 为基石,beat 所占的系统CPU和内存几乎可以忽略不计,libbeat平台还提供了检测机制,当下游服务器负载高或网络拥堵时,会自动降低发生速率。
流程图:
Filebeat将日志发送给Logstash进行分析和过滤,然后由Logstash转发给Elasticsearch。
优点:
全面,稳定,在网络阻塞的情况下可以很方便的处理问题,让日志不至于丢失。
缺点:
占用过大内存,消耗过多资源,Es+logstash加在一起消耗的资源过多,日志系统没有那么多数据量的话就可以不用搭建这套系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号