BUAAOS Lab2实验报告
Lab2实验报告
本次明确
实验要做的操作系统是32位的,按字节编址
采用链表来管理空闲内存空间
相同类型数据的指针相减得到的是其中间相差的该类型数据个数
对指针进行加的含义并非对地址进行加,而是加对应倍的指针类型数据大小。
操作系统运行在虚拟内存空间中,过程中使用的所有的地址都是虚拟地址。
物理内存与内核虚拟空间实际上就是简单的线性映射。
实验思考题
Thinking2.1 请思考cache用虚拟地址来查询的可能性,并且给出这种方式对访存带来的好处和坏处。另外,你能否能根据前一个问题的解答来得出用物理地址来查询的优势?
- 不同的程序可能拥有相同的虚拟地址,cache若利用虚拟地址来查询,那么根据虚拟地址与物理地址映射的计算参数,我们需要再给出虚拟地址的同时给出该程序的独特标记码,否则会造成访存错误;这样一来就增大了cache的复杂度,所以这种方法是可能的,但并不是可取的方案。
- 好处:不经过MMU中TLB的地址映射,若再cache中命中则大大节省了访存时间
- 坏处:要不增加了cache的复杂度,要不可能造成访存失败
- 用物理地址访存的优势:能够避免因不同程序有相同虚拟地址而造成的访存失败。
Thinking2.2 在我们的实验中,有许多对虚拟地址或者物理地址操作的宏函数(详见include/mmu.h ),那么我们在调用这些宏的时候需要弄清楚需要操作的地址是物理地址还是虚拟地址,阅读下面的代码,指出x是一个物理地址还是虚拟地址。
- x是一个虚拟地址,c程序中的地址均为虚拟地址。
Thinking2.3 我们在 include/queue.h 中定义了一系列的宏函数来简化对链表的操作。实际上,我们在 include/queue.h 文件中定义的链表和 glibc 相关源码较为相似,这一链表设计也应用于 Linux 系统中 (sys/queue.h 文件)。请阅读这些宏函数的代码,说说它们的原理和巧妙之处。
原理:宏函数在预处理的时候会将相应的位置替换成对应的宏,然后对其中的一些参数做替换。
具体宏代码解读:
-
#define LIST_HEAD(name, type) \ struct name{ \ struct type *lh_first; \ }该宏函数为定义链表头指针结构的函数,参数name为链表头指针名,参数type为链表节点的类型。
-
#define LIST_HEAD_INITIALIZER(head) {NULL}该宏函数将一个链表头指针指向一个空链表,用于初始化一个链表
-
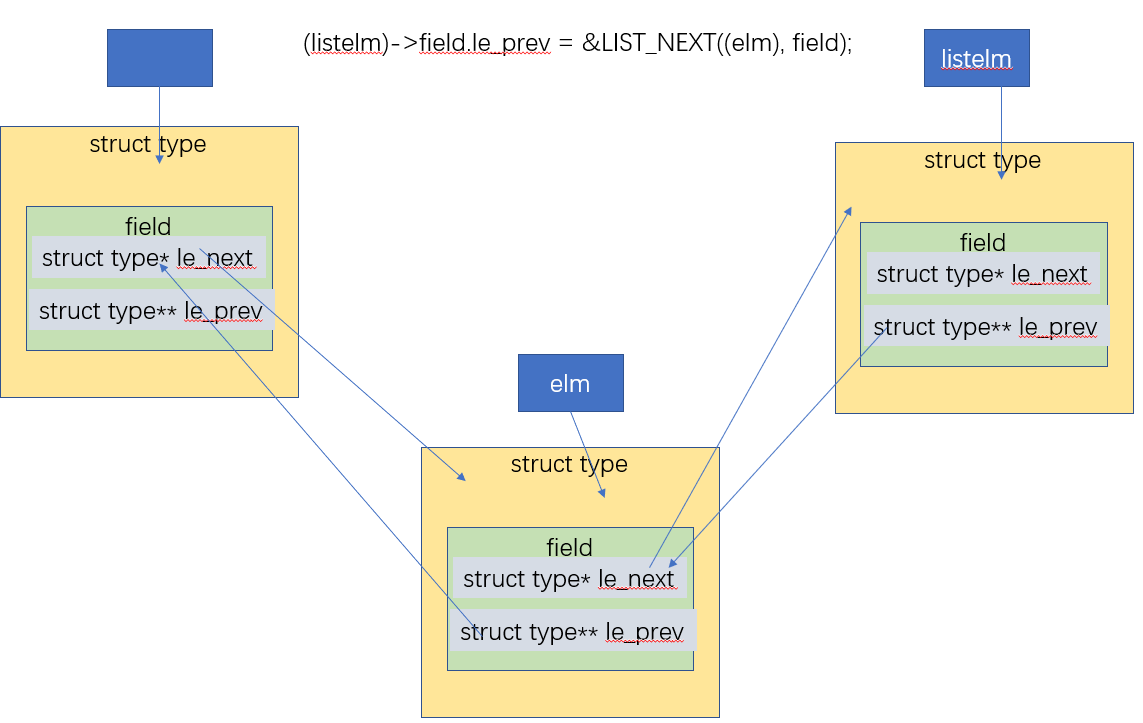
#define LIST_ENTRY(type) \ struct { \ struct type *le_next; \ struct type **le_prev; \ }定义了链表节点的link结构体,
le_prev为指向前一个节点结构体的link结构体中le_next指针的指针,le_next为指向下一个节点结构体的指针。这样方便我们进行对当前结构体的删除操作,只需使用*le_prev = le_next,就能够将当前节点与链表解除关系 -
#define LIST_EMPTY(head) ((head)->lh_first == NULL)链表是否为空,若为空返回1,否则返回0
-
#define LIST_FIRST(head) ((head)->lh_first)取出链表的第一个节点
-
#define LIST_FOREACH(var, head, field) \ for ((var) = LIST_FIRST((head)); (var); \ (var) = LIST_NEXT((var), field))遍历头指针为
head的链表中的全部节点,field为节点中的link的结构体 -
#define LIST_INIT(head) \ do{ \ LIST_FIRST((head)) = NULL; \ } while(0)为链表头指针初始化一个空链表
-
#define LIST_NEXT(elm, field) ((elm)->field.le_next)取出链表中当前节点的指向下一个节点的指针
-
#define LIST_REMOVE(elm, field) \ do{ \ if(LIST_NEXT((elm), field) != NULL) \ LIST_NEXT((elm), field)->field.le_prev = \ (elm)->field.le_prev; \ *(elm)->field.le_prev = LIST_NEXT((elm), field); \ }while(0)从链表中安全移除节点
elm -
#define LIST_INSERT_BEFORE(listelm, elm, field) \ do{ \ (elm)->field.le_prev = (listelm)->field.le_prev; \ LIST_NEXT((elm), field) = (listelm); \ *(listelm)->field.le_prev = (elm); \ (listelm)->field.le_prev = &LIST_NEXT((elm), field); \ }while(0)在链表中
listelm节点前面增加一个节点elm -
#define LIST_INSERT_HEAD(head, elm, field) \ do{ \ if((LIST_NEXT((elm), field) = LIST_FIRST((head))) != NULL) \ LIST_FIRST((head))->field.le_prev = &LIST_NEXT((elm), field);\ LIST_FIRST((head)) = (elm); \ (elm)->field.le_prev = &LIST_FIRST((head)); }while(0)在链表头加一个节点
-
#define TAILQ_HEAD(name, type) \ struct name{ \ struct type* tqh_first; \ struct type** tqh_last; \ }定义队列的头节点指针结构体,该结构体中
tqh_first为指向队首节点的指针,tqh_last为指向队尾节点 -
#define TAILQ_ENTRY(type) \ struct{ \ struct type* tqh_next; \ struct type** tqh_prev; \ }定义节点的link结构体,其中
tqh_next为指向下一个结构体的指针,tqh_prev为指向前一个结构体的link结构体中的tqh_next指针的指针。与上面链表定义类似
Thinking2.4 我们注意到我们把宏函数的函数体写成了 do { /* ... */ } while(0)的形式,而不是仅仅写成形如 { /* ... */ } 的语句块,这样的写法好处是什么?
-
辅助定义复杂的宏,避免引用时出错,保证调用该宏时,所有的语句都能在被调用处执行,例如如下宏定义:
#define DO() \ do1(); \ do2();若我们这样调用:
if(start) DO()那么,可能就会出现问题,
do2();在判断条件的控制域之外了,一定会被执行。 -
避免
;使用出现问题,使用上一个宏定义(可能有人习惯在写一个函数后面加上分号),若我们调用函数这样写:if(start) DO();这是我们习惯的写法,但是会编译报错,因为多了个分号……你可能会说定义宏的时候不要在最后加分号就好了呗,但是当我们定义一个复杂功能函数的宏函数时,很可能会在每一个语句后面都加一个分号,与其小心翼翼,不如使用一个规范的形式避免这种情况。
-
避免空宏引起的Warning
内核中由于不同架构的限制,很多时候会用到空宏,为避免编译时空宏报错,我们使用一个
do{} while(0)即可实现,但是这个我暂时没有接触到。
Thinking2.5 注意,我们定义的 Page 结构体只是一个信息的载体,它只代表了相应物理内存页的信息,它本身并不是物理内存页。 那我们的物理内存页究竟在哪呢?Page 结构体又是通过怎样的方式找到它代表的物理内存页的地址呢? 请你阅读 include/pmap.h 与 mm/pmap.c 中相关代码,并思考一下。
- 物理内存页存在物理内存中
- Page结构体通过与mips_vm_init()函数中初始化得到的
pages数组首地址做差,得到该页对应的物理页号,然后将物理页号左移12位就得到了其对应的物理内存页的首地址。该函数的实现为pmap.h头文件中的page2pa(struct Page *pp)。
Thinking2.6 请阅读 include/queue.h 以及 include/pmap.h, 将Page_list的结构梳理清楚,选择正确的展开结构(请注意指针)。
- C
Thinking2.7 在 mmu.h 中定义了 bzero(void *b, size_t) 这样一个函数,请你思考,此处的b指针是一个物理地址, 还是一个虚拟地址呢?
-
虚拟地址
-
原因解释:
mm/pmap.c文件中给出的
alloc()函数中使用了这一函数,通过阅读alloc()函数,我们能够注意到有这样几行代码:... alloced_mem = freemem; ... if(clear) { bzero((void *)alloced_mem, n); } ...这里面的指针为
alloced_mem,顺藤摸瓜我们能找到其原始值为freemem,分析这个freemem变量,他是一个静态变量,并且通过这段下面这段代码我们注意到,在第一次使用freemem对其进行了初始化,初始化为end的值。![image-20210405170607476]()
那么继续摸瓜,这个end是在tools/scse0_3.lds链接文件中赋值的,其值为0x80400000,这个值为我们在Lab1中加载内核之后设置的结束地址,是虚拟地址。

Thinking2.8 了解了二级页表页目录自映射的原理之后,我们知道,Win2k内核的虚存管理也是采用了二级页表的形式,其页表所占的 4M 空间对应的虚存起始地址为 0xC0000000,那么,它的页目录的起始地址是多少呢?
- $0xc0000000 + (0xc0000000 >> 12) << 2 = 0xc0300000$
Thinking2.9 注意到页表在进程地址空间中连续存放,并线性映射到整个地址空间,思考:是否可以由虚拟地址直接得到对应页表项的虚拟地址?上一节末尾所述转换过程中,第一步查页目录有必要吗,为什么?
- 可以。与一级页表相同,虚拟地址的前20位即为虚页号,页表基址+虚页号*页表项字节数即为对应页表项地址。
- 有必要,通过查询页目录能够判断其页表页是否存在,也能够更快地定位到相应页表项位置。
Thinking2.10 观察给出的代码可以发现,page_insert会默认为页面设置PTE_V的权限。请问,你认为是否应该将PTE_R也作为默认权限?并说明理由。
- 我认为不应该。PTE_V权限表示这个页面能否被修改,如果我们加载这个页面上只是为了能够读相关信息的话,开放这个权限没有必要,而且可能会造成这个页面的数据被修改。
Thinking 2.11 思考一下tlb_out汇编函数,结合代码阐述一下跳转到NOFOUND的流程?从MIPS手册中查找tlbp和tlbwi指令,明确其用途,并解释为何第10行处指令后有4条nop指令。
-
将需要查找的虚拟页号和相应的ASID数据传给
CP0_ENTRYHI寄存器,然后根据CP0_ENTRYHI寄存器中的数据在TLB中查找与其相对应的表项,将查找结果记录在CP0_INDEX寄存器中。再将CP0_INDEX寄存器中的数据与0比较,若小于0则说明在TLB中没查到对应的表项,跳转至NOFOUND标签处,恢复CP0_ENTRYHI的值,返回程序。 -
tlbp:在TLB转换表中查找与CP0_ENTRYHI寄存器数据相匹配的表项,并将表项索引记录在CP0_INDEX寄存器中,若未查到,将CP0_INDEX寄存器中的数据最高位置为1。 -
tlbwi:根据现在CP0_ENTRYHI、CP0_ENTRYLO0、CP0_ENTRYLO1、CP0_PAGEMASK寄存器来填写CP0_INDEX指定的TLB表项。 -
TLB查找匹配的表项后会将索引写入
CP0_INDEX寄存器,而下一条指令又需要读该寄存器,会产生写后读的冲突,所以需要等待四个时钟周期。
Thinking2.12 显然,运行后结果与我们预期的不符,va值为0x88888,相应的pa中的值为0。这说明我们的代码中存在问题,请你仔细思考我们的访存模型,指出问题所在。
- va2pa()函数的功能为返回虚拟地址的二级页表的物理地址,由于这里的虚拟地址不是4K的整数倍,因此得出的物理地址pa并非是该虚拟地址对应的实际的物理地址,而是这一物理页的首地址,所以读取这个地址的值并不能得出写入结果。
Thinking2.13 在X86体系结构下的操作系统,有一个特殊的寄存器CR4,在其中有一个PSE位,当该位设为1时将开启4MB大物理页面模式,请查阅相关资料,说明当PSE开启时的页表组织形式与我们当前的页表组织形式的区别。
- 当开启大物理页面模式时,页目录的表项中增加了一个新的标识(第7位,又称PS位Page Size),如果PS = 1, 则这个页目录项指向一个4MB的大物理页面,而PS = 0,则这个页目录项指向一个二级页表。所以在PS = 1 时,虚拟地址的低22位全部用来在大物理页面中寻址。在PS = 0时,寻址方式与二级页表相同。
实验难点
emmm感觉好多东西学完感觉也不是很难的,但当时觉得都挺难的,我就记录一下吧
物理内存管理中相关结构理解
记录页信息的的结构体
该结构体的形式扩展开来如下:
//头节点:
struct Page_list{
struct Page* lh_first;
}
//页面信息节点:(若是空闲页面则在链表中)
struct Page{
struct {
struct Page* le_next; //指向后一个页结构体节点的指针
struct Page** le_prev; //指向前一个页结构体节点的pp_link->le_next的指针
} pp_link;
u_short pp_ref; //记录该物理页面引用次数
}
链表的整体结构大抵如下图所示:(注意指针的指向)
这里的链表用于空闲页面的管理,其中每个节点都表示一个相应的空闲物理页表信息。
所有的物理页面都有各自的页面信息结构体,在实验要设计的操作系统中使用了一个结构体指针pages(当然也可以视为数组啦),根据物理页面的物理地址pa 将相应信息结构体按顺序存放在该指针开始的空间里,具体来讲就是:根据物理页面的物理地址pa计算出来物理页号ppn,那么其信息结构体就可以通过pages[ppn](这是个页虚拟地址)来进行访问喽!!
物理页号、页物理地址、页面信息结构体指针、页虚拟地址转换
在头文件中定义了几个函数和宏:
-
page2ppn(struct Page *pp)页面信息结构体指针(虚拟地址)$\rightarrow$ 物理页号
-
page2pa(struct Page *pp)页面信息结构体指针(虚拟地址)$\rightarrow$ 页物理地址
-
pa2page(u_long pa)页物理地址 $\rightarrow$ 页面信息结构体指针(虚拟地址)
-
page2kva(struct Page *pp)页面信息结构体指针(虚拟地址) $\rightarrow$ 页虚拟地址
-
PADDR(kva)内核虚拟地址 $\rightarrow$ 物理地址 ,直接最高位清零(- 0x80000000)
-
KADDR(pa)物理地址 $\rightarrow$ 内核虚拟地址,直接最高位置一(+0x80000000)
-
PTE_ADDR(pte)页表项值 $\rightarrow$ 页物理地址(不一定只有这一个功能$\Rightarrow$低12位都置0)
-
PDX(va)虚拟地址 $\rightarrow$ 页目录号
-
PTX(va)虚拟地址 $\rightarrow$ 页表索引
-
tlb_invalidate(pgdir, va)刷新TLB,TLB中存放页目录项
内存管理初始化流程
-
mips_detect_memory();
只是初始化几个内存的参数
maxpa内存大小basemem本实验与maxpa一致npage物理页数 $= maxpa\div$页大小
-
mips_vm_init();
为页目录、页结构体和envs分配了物理空间,并建立了页结构体PAGES虚拟内存空间和pages物理内存空间的页表映射关系,以及ENVS虚拟内存空间和envs物理内存空间的也表映射关系。
- 分配页目录页空间(4KB) : 虚拟内存空间中:0x80400000 ~ 0x80401000 ,对应物理空间为0x400000 ~0x401000 (直接PADDR就能算出)
- 分配页结构体空间(192KB):虚拟内存空间中:0x80401000 ~ 0x80431000,对应物理空间为PADDR(balabala)
- 将UPAGES虚存空间与pages物理空间建立页表映射关系
- 调用boot_map_segment(...)函数,页表页不存在
- 创建页表页,即给该物理页分配空间,虚拟内存空间中:0x80431000 ~ 0x80432000,物理地址PADDR(...),重新填写页表项
- 然后正常逐项建立页表映射关系
- 将UPAGES虚存空间与pages物理空间建立页表映射关系
- 分配envs空间(216KB):虚拟内存空间:0x80432000 ~ 0x80468000
- 将ENVS虚存空间与envs物理空间建立页表映射关系(同上)
- 调用boot_map_segment(...)函数,页表页不存在
- 创建页表页,即给该物理页分配空间,虚拟内存空间中:0x80468000 ~ 0x80469000,物理地址PADDR(...),重新填写页表项
- 然后正常逐项建立页表映射关系
- 将ENVS虚存空间与envs物理空间建立页表映射关系(同上)
-
page_init();
初始化页结构体,建立空闲页面管理的链结构体
- 把已经分配出去的物理内存页对应的页结构体的相关位(pp_ref)置为1
- 未分配的(pp_ref)置为0,并放在空闲页表链中。
页目录自映射
虚拟内存空间中的结构如图所示:
这部分的学习记录写在了博客里。
Pte //Page table entry 页表项
pgdir //Page directory 页目录
Pde //Page directory entry 页目录项
汇编代码的理解
几个宏函数的理解:
#define LEAF(symbol) \
.global symbol; \
.align 2; \
.type symbol, @function; \
.ent symbol, 0; \
symbol: .frame sp, 0, ra
#define END(function) \
.end function \
.size function, .-function
LEAF和END是汇编文件中常见的宏,在我们实验的操作系统汇编代码里几乎都有这两个宏作为文件的开头和结尾。LEAF被用来定义一个简单的例程,即不调用其他例程,其中几个伪指令的解读如下:
-
.globl symbol:声明symbol为全局变量,该变量名要包括在模块的符号表内,而且名字在整个程序范围内必须是唯一的 -
.align 2:按字对齐.align:Align next data item on specified byte boundary (0=byte, 1=half, 2=word, 3=double) -
.type symbol, @function:标识函数名称 -
.ent symbol, 0:标识函数的起始点 -
.end:指出函数结尾,用于调试 -
.size function, .-function:在函数表中,function和所用指令的字节数一同列出
协处理器CP0相关内容
- k0、k1通用寄存器由软件约定预留下来用于异常处理代码中
- 相关CPU指令
mtc0 s, <n>:把寄存器s中的数据传递给CP0寄存器<n>mfc0 d, <n>:把CP0寄存器<n>中的数据传递给寄存器d
TLB相关内容
TLB转换表中每一项含有一个页的虚拟地址(VPN即虚拟页号)和一个物理页地址(PFN即物理页帧号)。所以TLB中是直接拿虚拟页号来查找的,并且不是按照索引,而是逐项比较VPN,是一种内容寻址的存储器。当查找到相符的VPN,则取出PFN。(PFN与标志位一同存储一同返回,标志位能让操作系统指定某一页为只读或者指定某页的数据是否可以高速缓存)。
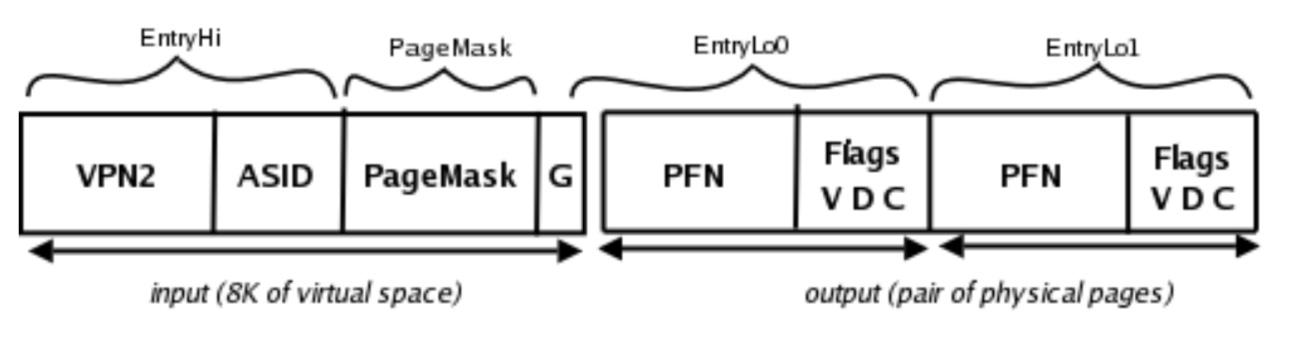
现代MIPS CPU大多采用双倍存储,每一个TLB项容纳一对相邻的虚拟页面对应的两个单独的物理地址。如图是一个TLB数据项:
TLB相关的CPU控制寄存器
-
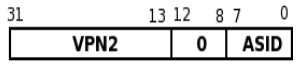
CP0_ENTRYHI(关键字域):记录VPN2和当前进程的ASID-
VPN2:32-13= 19位(低0-12都是0,略去无可厚非,第13位略去是为什么呢?因为我们上面说的双倍存储,所以在两个页面里选就成了) -
ASID:地址空间标识符,标识这个表项是属于哪一个进程的
![image-20210412204028166]()
-
-
CP0_ENTRYLO0/CP0_ENTRYLO1(输出域):![image-20210412203951451]()
ps:目前为止还用不到这些,等我日后总结吧
-
CP0_INDEX:TLB表项的索引

TLB控制指令
-
tlbwi:write TLB entry at index根据现在
CP0_ENTRYHI、CP0_ENTRYLO0、CP0_ENTRYLO1、CP0_PAGEMASK寄存器来写CP0_INDEX指定的TLB表项。 -
tlbp:TLB lookup搜索虚拟页号和ASID与当前
CP0_ENTRYHI中的值相匹配的TLB项,并把该项的索引保存到CP0_INDEX寄存器,若没有查到,则将CP0_INDEX寄存器最高位置1,这样就相当于一个负数,标识未查到。
心得体会
从写本次lab2课下实验的过程中就能明显感受到这次实验的难度陡然增大,搞懂(自我感觉的搞懂。。。可能只是一知半解吧)本次实验我大概用了30多个小时。感觉这一部分的填写并不难,因为助教给了详细的步骤说明,几乎每一行代码都有相应的提示,但是要搞懂整个的内存管理模型结构还是很耗费精力的(脑子疼wwww),即使到现在还是有一部分问题没有解决,希望在之后的代码能找到这些问题的答案,也希望下次的代码能读得顺利一些。
残留难点
- 自映射在哪里呢??内核虚拟空间中并没有页目录自映射。是之后会在用户空间里看到吗?
- TLB的建立过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号