
合成数据强化学习(Synthetic Data RL)的通用框架
基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。结合自动强化学习(RL)微调的结果显示,该方法在数学、医疗,科学,金融等多个基准上取得十几个点的绝对性能提升。在同等数据数量条件下,其效果不仅显著优于人工数据下的监督微调方法,更媲美甚至超越了人工数据下的RL方法。相关代码已在GitHub开源。
尽管如GPT-4和Gemini等基础模型已在通用语言理解方面设立了新的行业标杆 ,但它们在需要深度领域知识的专业领域中,其表现常常不尽如人意。
当面临数学、医学、法律及金融等专门任务时,这些模型时常表现不佳,因为这些领域高度依赖特定的专业知识。
传统上,为了让这些模型适应特定领域,最直接的方法是使用大规模的人类标注数据进行微调。然而,这一过程不仅成本高昂、耗时漫长,而且在许多实际应用场景中并不可行。
为了解决上述挑战,北京大学、MIT等机构的研究人员提出了「合成数据强化学习」(Synthetic Data RL)框架。这是一个简单而通用的框架,仅从一个任务定义出发,合成大量多样的领域特定样本,然后利用强化学习(RL)对模型进行微调。
三步走实现高效自适应学习
研究人员提出的合成数据强化学习框架由三个主要环节构成。
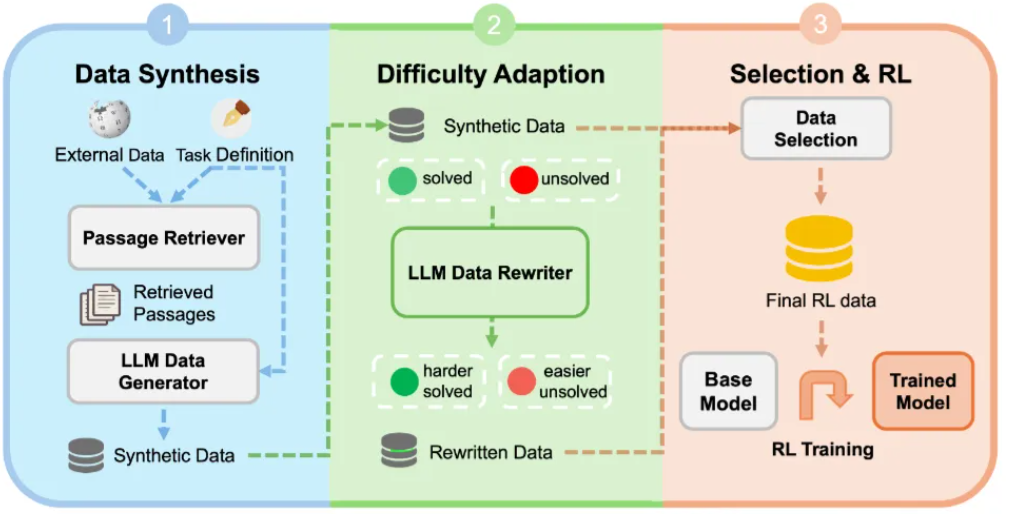
图1:三阶段方法框架图
如图1所示,
首先,系统通过知识引导的合成环节结合检索到的外部知识和任务特定模式,生成既有事实依据又与目标任务对齐的合成数据。
随后,在难度自适应环节,系统会根据模型的反馈来调整这些生成样本的复杂度,目的是创建一个难度均衡、避免过于简单或困难的数据集。
最后,在高潜力样本选择与强化学习环节,框架会精心挑选出高学习潜力的样本,并利用强化学习在这些样本上进行微调。
具体参见:
https://mp.weixin.qq.com/s/rjNQdHUCZ4YmvRNVveMQ8w

 浙公网安备 33010602011771号
浙公网安备 33010602011771号