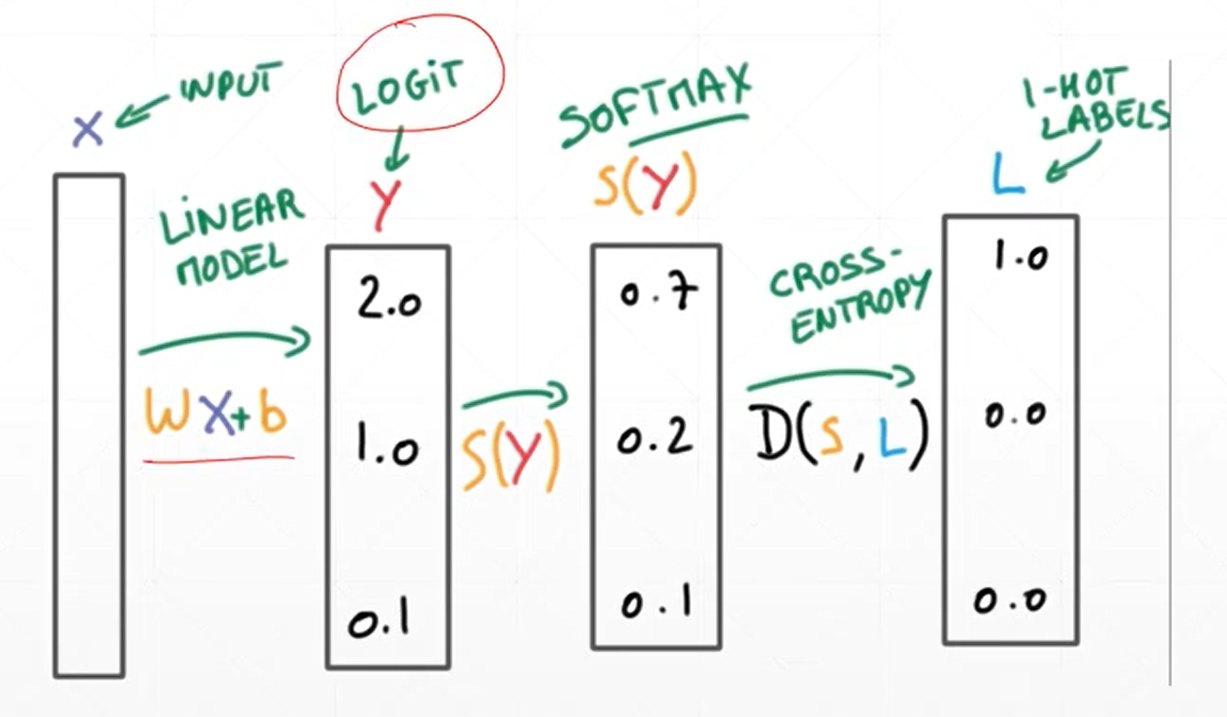
对于0-9的10分类任务神经网络搭建主要有两种方式:(1)底层原理实现方式和(2)调用函数搭建方式,整体的过程原理如下所示
![]()
(1)底层原理实现方式
import torch
import torch.nn.functional as F
a=torch.full([4],1/4)
print(a)
print(-1*a*torch.log2(a))
b=-1*a*torch.log2(a)
print(sum(b))
a=torch.tensor([0.1,0.1,0.1,0.7])
print(-1*a*torch.log2(a))
b=-1*a*torch.log2(a)
print(sum(b))
a=torch.tensor([0.001,0.001,0.001,0.997])
print(-1*a*torch.log2(a))
b=-1*a*torch.log2(a)
print(sum(b))
x=torch.randn(1,784)
w=torch.randn(10,784)
logits=x@w.t()
e1=F.cross_entropy(logits,torch.tensor([3]))
print(e1)
#cross_entropy函数=softmax+log+null_loss(for logits)
logits1=F.softmax(logits,dim=1)
pre_log=torch.log(logits1)
e2=F.nll_loss(pre_log,torch.tensor([3]))
print(e2)
#多元分类结果神经网络搭建
#导入原始数据
batch_size=200
import torch
from torch import nn #完成神经网络的构建包
from torch.nn import functional as F #包含常用的函数包
from torch import optim #优化工具包
import torchvision #视觉工具包
import matplotlib.pyplot as plt
#step1 load dataset 加载数据包
train_loader=torch.utils.data.DataLoader(
torchvision.datasets.MNIST("minist_data",train=True,download=True,transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
test_loader=torch.utils.data.DataLoader(
torchvision.datasets.MNIST("minist_data",train=True,download=False,transform=torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=False)
x,y=next(iter(train_loader))
print(x.shape,y.shape)
print(x)
print(y)
w1=torch.randn(200,784,requires_grad=True)
b1=torch.zeros(200,requires_grad=True)
w2=torch.randn(200,200,requires_grad=True)
b2=torch.zeros(200,requires_grad=True)
w3=torch.randn(10,200,requires_grad=True)
b3=torch.zeros(10,requires_grad=True)
#有效的初始化方式
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
def forward(x):
x=x@w1.t()+ b1
x=F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
epochs=10
learning_rate=1e-2
batch_size=200
global_step=0
optimizer=torch.optim.SGD([w1,b1,w2,b2,w3,b3],lr=learning_rate)
criteon=torch.nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data=data.view(-1,28*28)
logits=forward(data)
loss=criteon(logits,target)
global_step+=1
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx %100==0:
print(epoch,batch_idx,loss.item())
correct = 0
correct1=0
test_loss=0
for data,target in test_loader:
data =data.view(-1, 28 * 28)
logits = forward(data)
test_loss += criteon(logits, target).item()
pred =logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
pred1 = logits.argmax(dim=1) #测试的两种方法,均可使用,是等效的,结果输出一致
correct1 += pred.eq(target).sum()
total_num = len(test_loader.dataset)
total_num=torch.tensor(total_num)
acc =100.* correct / total_num
acc1=100.* correct1 / total_num
print("test.acc:{}%".format(acc)) # 输出整体预测的准确度
print("test.acc:{}%".format(acc1))
from visdom import Visdom
vis = Visdom()
vis.line([0.], [0.], win="train_loss", opts=dict(title="train loss"))
vis.line([test_loss], [global_step], win="train_loss", update="append")
(2)神经网络全连接层函数搭建
#全连接层的构建过程
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
net = MLP()
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss()
global_step=0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
global_step=global_step+1
data = data.view(-1, 28*28)
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
from visdom import Visdom
vis = Visdom()
vis.line([0.], [0.], win="train_loss", opts=dict(title="train loss"))
vis.line([loss.item()], [global_step], win="train_loss", update="append")
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
以上两种方式均可实现多分类任务,不过一般推荐使用第二章方式
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号