

Adaboost算法
Adaboost算法的R语言实现
具体说来,整个Adaboost迭代算法就3步:
( 1)初始化样本的权重:假如有N个样本,则每一个训练样本最开始时都被赋予相同的权重:1/N。
(2)重复以下步骤,直到达到停机条件:首先训练弱分类器,并不断更新样本权重。权重更新的依据如下:如果某个样本点被正确地分类,那么在构造下一个训练集中,它的权重就被降低;反之,如果某个样本点没有被正确地分类,那么它的权重就得到提高,然后,权重更新过的样本集被用于训练下一个分类器。分类器一般为同一种分类器,整个训练过程按照上述的依据,不断迭代地进行下去,直到达到预设的最大分类器个数。
( 3)将第(2)步训练得到的一系列弱分类器组合起来,同时对预测样本进行投票。根据每个弱分类器的准确率赋予每个弱分类器不同的权重,准确率高的分类器权重较大,其在最终的投票中起着较大的决定作用,而准确率低的分类器权重较小,其在最终的投票中起着较小的决定作用,这样,—系列弱分类器组合成强分类器。
#白酒数据集例子
#步骤1 数据集准备
url="http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv" data<-read.csv(url,sep=";",header=T) library(adabag) head(data)
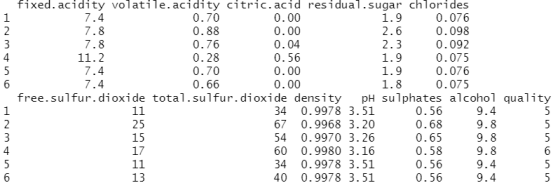
attach(data)
data$quality<-factor(data$quality,levels=c("3","4","5","6","7","8"),labels = c("A","B","C","D","E","F"))
#步骤2 准备参数,建立模型
l <- length(data[,1]) #获取数据集的长度 l
dim(data)
sub <- sample(1:l,2*l/3) #划分训练集和测试集,为2/3和1/3
mfinal<-100
maxdepth<-5
data.adaboost<-boosting(quality ~.,data=data[sub, ],mfinal=mfinal, coeflearn="Zhu",
control=rpart.control(maxdepth=maxdepth)) #以quality为label建立模型
解释:#mfinal 表示运行提升的迭代次数或要使用的树的数量,默认为 mfinal=100 次迭代。
#coeflearn设置权重更新系数为"Zhu"
#步骤3 模型预测
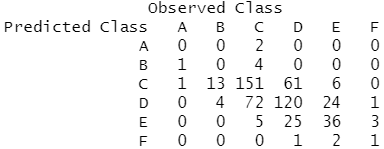
data.adaboost.pred<-predict.boosting(data.adaboost,newdata=data[-sub,]) data.adaboost.pred$confusion #混淆矩阵
data.adaboost.pred$error #错误率
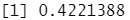
#步骤4 预测模型的比较
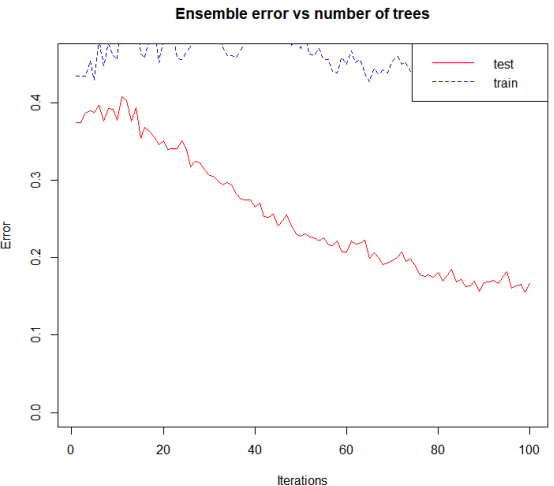
errorevol(data.adaboost,newdata=data[sub,])->evol.train errorevol(data.adaboost,newdata=data[-sub,])->evol.test plot.errorevol(evol.train,evol.test)
#鸢尾花数据集例子
require ( "adabag") train.idx<-sample ( 1 :nrow (iris) , 100)iris.train <-iris[train.idx, ] iris.test<- iris[-train.idx,] model<-boosting(Species~.,data=iris.train)
#为什么AdaBoost训练时间这么长呢?默认的迭代次数是100。你可以修改mfinal参数来改变迭代的次数;AdaBoost包含一系列的弱分类器。什么是弱分类器? Boosting 函数使用AdaBoost.M1算法,它是一种变异算法,集成了三种弱分类器:FindAttrTest、FindDecRule和C4.5.
resboost <- predict (object =model,newdata = iris.test,type = "class") resboost$confusion

本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15990939.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号