

聚类分析介绍
聚类分析
聚类分析是一种数据归约技术,旨在揭露一个数据集中观测值的子集。它可以把大量的观测值归约为若干个类。
最常用的两种聚类方法是层次聚类(hierarchical agglomerative clustering)和划分聚类(partitioning clustering)。在层次聚类中,每一个观测值自成一类,这些类每次两两合并,直到所有的类被聚成一类为止。在划分聚类中,首先指定类的个数K,然后观测值被随机分成K类,再重新形成聚合的类。对于层次聚类来说,最常用的算法是单联动(single linkage)、全联动(complete linkage )、平均联动(average linkage)、质心(centroid)和Ward方法。对于划分聚类来说,最常用的算法是K均值(K-means)和围绕中心点的划分(PAM)。
在机器学习中,聚类分析是一种无监督学习,分类分析是一种有监督学习有层次聚类和划分聚类,层次聚类适合小样本,比如100到200个,划分聚类是大样本。
1 聚类分析的一般步骤
像因子分析一样,有效的聚类分析是一个多步骤的过程,这其中每一次决策都可能影响聚类结果的质量和有效性。这里聚类分析有11个典型步骤。
(1) 选择合适的变量。第一(并且可能是最重要的)步是选择你感觉可能对识别和理解数据
中不同观测值分组有重要影响的变量。
(2) 缩放数据。如果我们在分析中选择的变量变化范围很大,那么该变量对结果的影响也是
最大的。这往往是不可取的,分析师往往在分析之前缩放数据。最常用的方法是将每个变量标准化为均值为0和标准差为1的变量。其他的替代方法包括每个变量被其最大值相除或该变量减去它的平均值并除以变量的平均绝对偏差。这三种方法能用下面的代码来解释:
df1 <- apply(mydata, 2, function(x){(x-mean(x))/sd(x)})
#也可以使用scale()函数来将变量标准化到均值为0和标准差为1的变量。
df2 <- apply(mydata, 2, function(x){x/max(x)})
df3 <- apply(mydata, 2, function(x){(x – mean(x))/mad(x)})
(3) 寻找异常点。许多聚类方法对于异常值是十分敏感的,它能扭曲我们得到的聚类方案。
你可以通过outliers包中的函数来筛选(和删除)异常单变量离群点。mvoutlier包中包含了
能识别多元变量的离群点的函数。一个替代的方法是使用对异常值稳健的聚类方法,围绕中心点的划分可以很好地解释这种方法。
(4) 计算距离。尽管不同的聚类算法差异很大,但是它们通常需要计算被聚类的实体之间的
距离。两个观测值之间最常用的距离量度是欧几里得距离,其他可选的量度包括曼哈顿距离、兰氏距离、非对称二元距离、最大距离和闵可夫斯基距离等。
(5) 选择聚类算法。接下来选择对数据聚类的方法,层次聚类对于小样本来说很实用(如150
个观测值或更少),而且这种情况下嵌套聚类更实用。划分的方法能处理更大的数据量,但是需要事先确定聚类的个数。一旦选定了层次方法或划分方法,就必须选择一个特定的聚类算法。
(6) 获得一种或多种聚类方法。
(7) 确定类的数目。为了得到最终的聚类方案,你必须确定类的数目。对此研究者们也提出
了很多相应的解决方法。常用方法是尝试不同的类数(比如2~K)并比较解的质量。
(8) 获得最终的聚类解决方案。一旦类的个数确定下来,就可以提取出子群,形成最终的聚
类方案了。
(9) 结果可视化。可视化可以帮助你判定聚类方案的意义和用处。层次聚类的结果通常表示
为一个树状图。划分的结果通常利用可视化双变量聚类图来表示。
(10) 解读类。一旦聚类方案确定,你必须解释(或许命名)这个类。一个类中的观测值有何相似之处?不同的类之间的观测值有何不同?这一步通常通过获得类中每个变量的汇总统计来完成。对于连续数据,每一类中变量的均值和中位数会被计算出来。对于混合数据(数据中包含分类变量),结果中将返回各类的众数或类别分布。
(11) 验证结果。验证聚类方案相当于问:“这种划分并不是因为数据集或聚类方法的某种特
性,而是确实给出了一个某种程度上有实际意义的结果吗?”如果采用不同的聚类方法或不同的样本,是否会产生相同的类?fpc、clv和clValid包包含了评估聚类解的稳定性的函数。
2 计算距离
聚类分析的第一步都是度量样本单元间的距离、相异性或相似性。
查看在flexclust包中的营养数据集,它包括对27种肉、鱼和禽的营养物质的测量。最初的
几个观测值由下面的代码给出:
data(nutrient, package="flexclust") head(nutrient, 4)
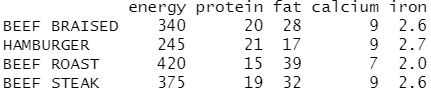
R软件中自带的dist()函数能用来计算矩阵或数据框中所有行(观测值)之间的距离。格式是dist(x, method=),这里的x表示输入数据,并且默认为欧几里得距离。函数默认返回一个
下三角矩阵,但是as.matrix()函数可使用标准括号符号得到距离。对于营养数据集的数据框来说,前四行的距离为:
d <- dist(nutrient) #计算数据框中所有行之间的距离 as.matrix(d)[1:4,1:4] #取前四行展示

结果分析:观测值之间的距离越大,异质性越大。观测值和它自己之间的距离是0。
欧几里得距离通常作为连续型数据的距离度量。但是如果存在其他类型的数据,则需要相异的替代措施,你可以使用cluster包中的daisy()函数来获得包含任意二元(binary)、名义
(nominal)、有序(ordinal)、连续(continuous)属性组合的相异矩阵。cluster包中的其他函数可以使用这些异质性来进行聚类分析。例如agnes()函数提供了层次聚类,pam()函数提供了围绕中心点的划分的方法。
本文来自博客园,作者:zhang-X,转载请注明原文链接:https://www.cnblogs.com/YY-zhang/p/15138080.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号