
OO第一单元总结
第一单元总结
第一单元课下作业总共分为三个大作业,简单的概括一下分别是,多项式的求导、含有三角函数的表达式的求导、加入了嵌套的表达式求导。
一、大体思路
第一次作业
这是第一次接触面向对象,写作业的过程中就想尽可能地去理解面向对象的思想并应用在程序当中。把多项式的每个项作为一个基本单位,即Item,Item类能够组合成Expression类。这里的想法是可以通过创建Expression的对象来调用Item进行求导和toString等操作。这里只是做了简单的分层操作,没有做到对面向对象的理解。
类图

第二次作业
有了上一次作业的经验。对整体的分层比较清晰,同时做到了检查格式于计算相分离。这也是使我在完成代码时比较轻松,以及在在完成之后没有经过任何debug,一次就过了中测,且在互测中没有被狼。但是没有去考虑有关代码的性能优化问题,没有思考到较好的优化方法,考虑到了可以优化的公式很多,但是无法得出优化后就一定会短,可能会出现无效的优化,且考虑到多次优化和比较的话可能会导致TLE,所以在下手优化了一段时间后就放弃了。
类图
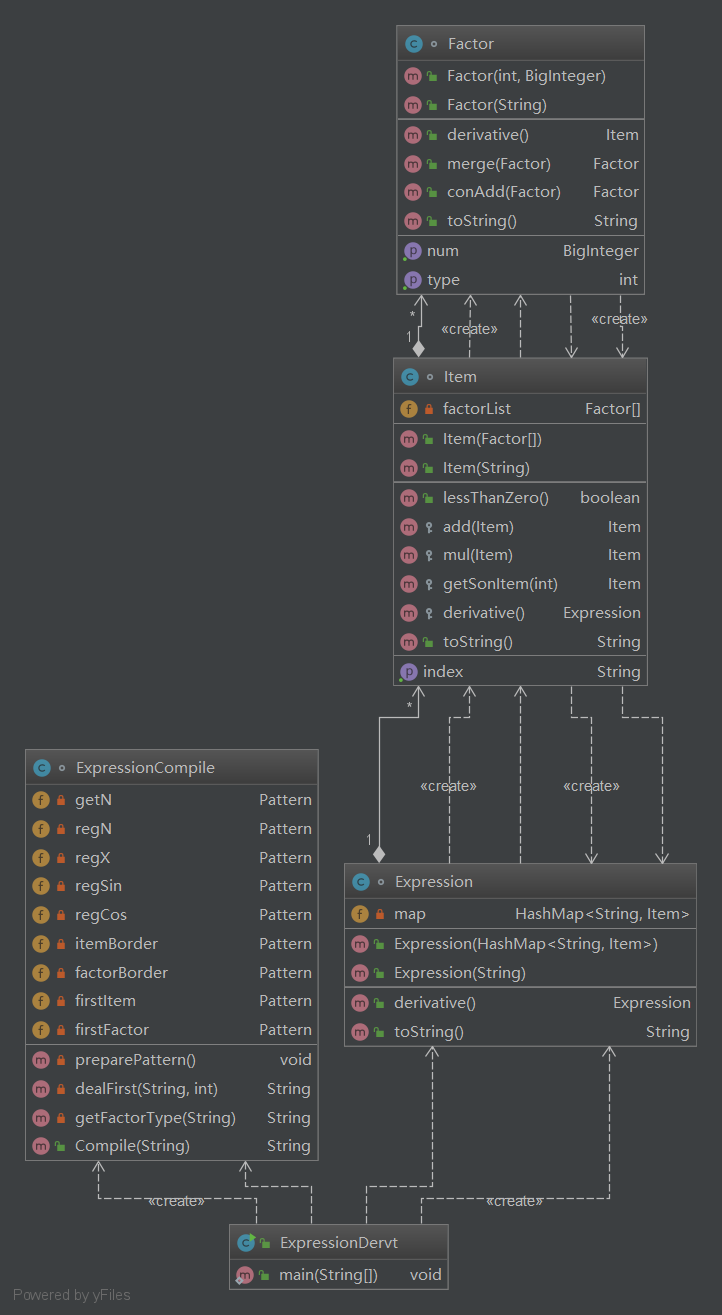
第三次作业
第三次作业由于多了嵌套,这导致之前两次的作业的设计架构都不适合了。不过仍采用了格式检查与计算相分离。主要通过Expression这个超类,创建它的2个组合子类,即加法组合,乘法组合,以及4个因子子类,即常数,幂函数,sin,cos。之后再进行递归求导和toString,一层一层逐渐获得。
类图

二、基于MetricsReloaded的代码分析
由于第三次作业的代码量比较足够,度量问题明显,所以仅分析第三次作业。
类:
参照大佬哪里有只喵对代码度量的度量方法,我也采用的是CK度量元。对于每一项参数的理解可以参照https://blog.csdn.net/m0_37924639/article/details/79784522>
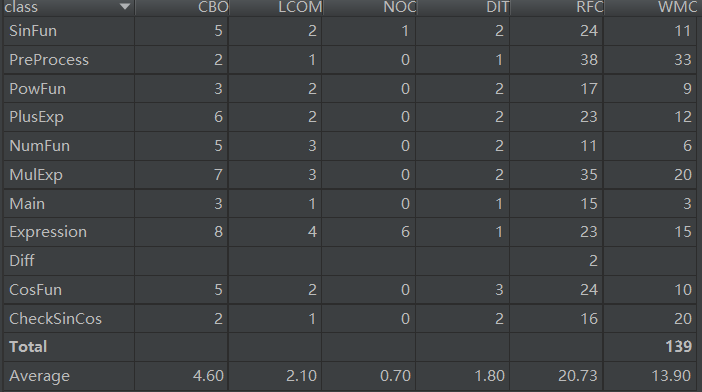
CBO:MulExp的类的耦合性较高是因为在这个类的构造函数中,实现了对因子类的分类。
LCOM:可以看出我的NumFun和MulExp两个类内聚过低。
NOC:可以看出我的类大部分都是Expression类的子类.
DIT:可以看出类继承的深度过低,扩展性不高。
从RFC和WMC中可以看出代码的复杂度在PreProcess和MulExp的复杂度有点高,在这两个类中确实存在一些方法是面向过程的,尤其是PreProcess,这一点需要改进。
方法:
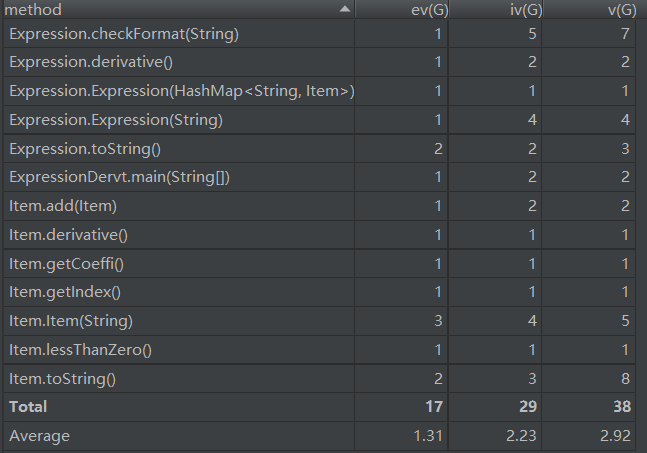
这里可以发现在对字符串的预处理和格式检验的时候写的方法过于复杂且我的这个检查格式的类是采用面向过程的方法,应该采取改进方法。
三、Bug分析:
第一次作业已知的bug总共存在2个,且都是有关于表达式格式的判断的bug。
- 第一个bug是有关空白字符的判断,如\v,\f,原因是对指导书的理解错误。修改方式:判断字符串是否出现不应存在的字符。
- 第二个bug是有关正则匹配的TLE问题,虽然在判断的时候采用了分割项的方法,但是没有考虑到大量空格作为整个项去匹配正则,从而会导致TLE。修改方式:通过将多个空白字符转化为一个空格,这样既能避免正则匹配大量空格,也能够不妨该对其他特殊情况的判断。
第二次作业在公测和互测当中都没有发现bug。
第三次作业总共有一个bug。
- 多重嵌套导致TLE的问题。修改方式:通过在计算的不同阶段插入输出发现超时的部分存在于toString的部分。接着在通过在toString方法加入输出,发现真正的问题存在于创建的表达式树太深,且有许多多余的分支,从而导致toString时间过长。所有通过重构相关类的构造方法,从而达到删除表达树中多余节点的目的。
四、寻找他人bug的策略
我在互测组里寻找他人bug的方式是,首先把在之前自己写作业的时候制造的测试集把所有人的程序都跑一遍,如果跑出bug来,会去关注被hack到的小朋友的代码问题大概出现在哪里,尽量避免对一个人提交多次同质bug。之后,我会快速的浏览关注同组同学的整体架构,由于时间和精力有限,我不可能去仔细思考所有人的代码,所以会选择出架构清晰的,代码漂亮的代码进行阅读,去寻找他们的bug,然后针对bug构造测试数据。
五、心得体会
在这三次的作业中,可以看见自己的进步:在不断地理解面向对象的思想,也养成了在编写代码前进行了清晰的架构设计,同时在讨论区中从大佬哪里学到了好多小技巧。但是需要注意,在设计架构的时候不仅仅只考虑代码的正确性,同时也应着重去考虑代码的效率,课后的测试当中应该针对自己的架构来构造合理的测试集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号