第一次个人项目
| 这个作业属于哪个课程 | 软件工程2024 (广东工业大学) |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 目标 | 学习并使用Git |
GitHub地址:查重
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 10 | 20 |
| 估计这个任务需要多少时间 | 600 | 800 |
| 开发 | 300 | 400 |
| 需求分析 | 30 | 20 |
| 生成设计文档 | 20 | 20 |
| 设计复审 | 30 | 20 |
| 代码规范 | 10 | 10 |
| 具体设计 | 100 | 150 |
| 具体编码 | 200 | 300 |
| 测试 | 200 | 300 |
| 报告 | 20 | 50 |
| 测试报告 | 20 | 40 |
| 计算工作量 | 10 | 10 |
| 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 1550 | 2160 |
计算模块接口的设计与实现过程
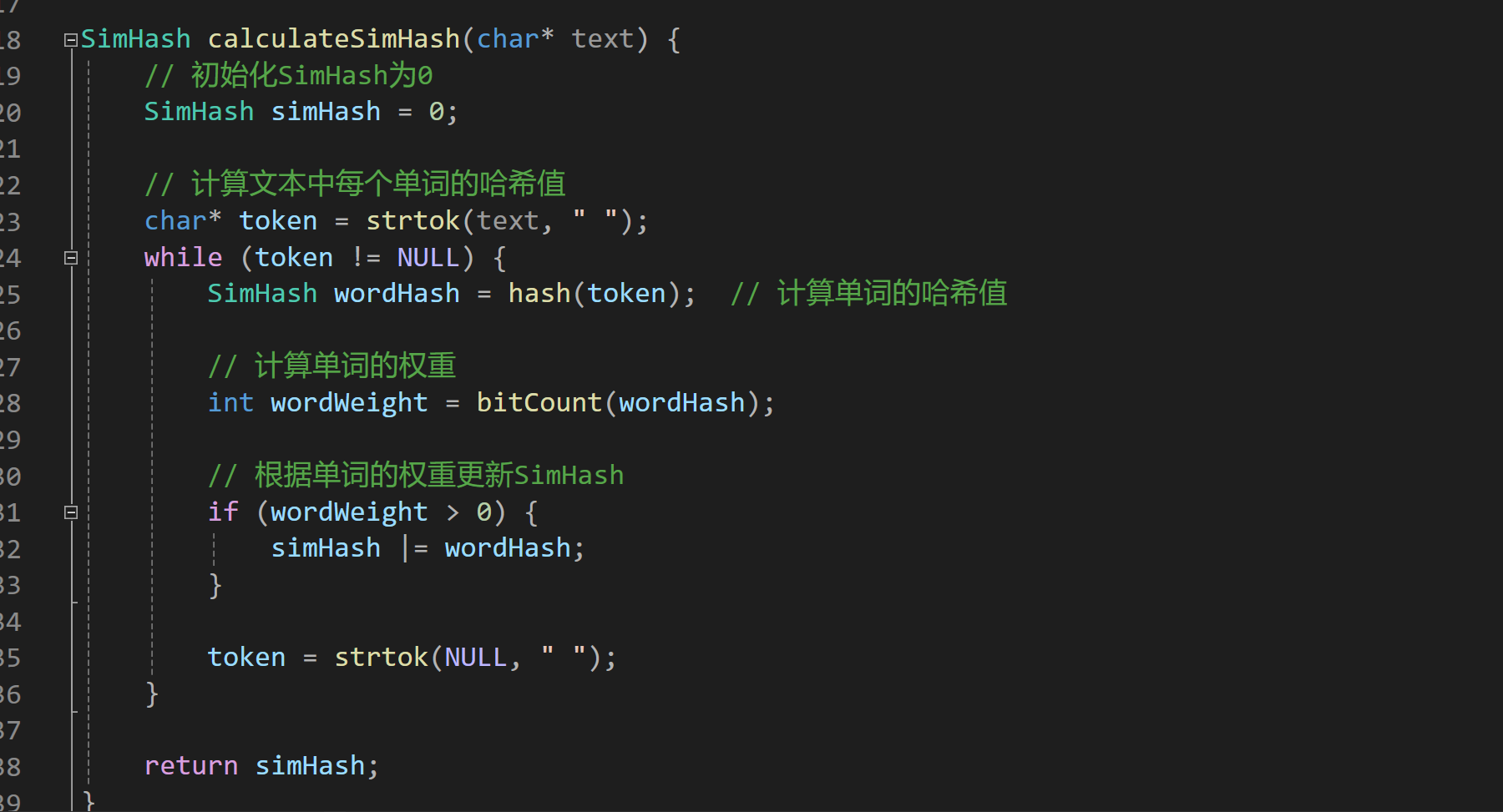
核心:SimHash算法
SimHash是一种用于比较文本相似度的算法。它通过将文本转换为固定长度的二进制码,然后对这些码进行比特运算和计算哈希值,从而判断文本之间的相似程度。
基本步骤:
- 文本预处理:首先,对文本进行预处理操作,例如去除标点符号、停用词、转换为小写等。
- 特征提取:将文本转换为特征向量。常用的特征抽取方法包括词袋模型(Bag of Words)、TF-IDF、Word2Vec等。
- 特征加权:对提取的特征进行加权处理,以便突出关键词的重要性。通常使用词频(TF)或TF-IDF进行权重计算。
- SimHash计算:对于每个特征向量,进行SimHash计算。将特征向量的每个元素进行哈希映射,并将结果进行加权合并,得到一个二进制码表示文本。
- 相似度计算:通过比特运算(如汉明距离)来计算两个SimHash码之间的相似度。汉明距离越小,表示两个文本越相似。
反思与总结
对于算法的选取
一开始在了解了解各类查重算法时,只选取了自己感兴趣的余弦相似度学习。但是并没有发现余弦相似度所涉及的文本向量化与自己当前掌握的c语言并不十分契合(文本处理应使用Python、Java等高级语言),最后导致花了更多的时间却无法解决问题。所以针对需求正确的选择合适自己的算法才是最重要的。
基础缺失
学习过程中对Git、VS使用的不熟练,包括c语言中的对文件的操作浪费了很多时间,这些都是之后的学习中亟待解决的问题。
性能分析图

单元测试
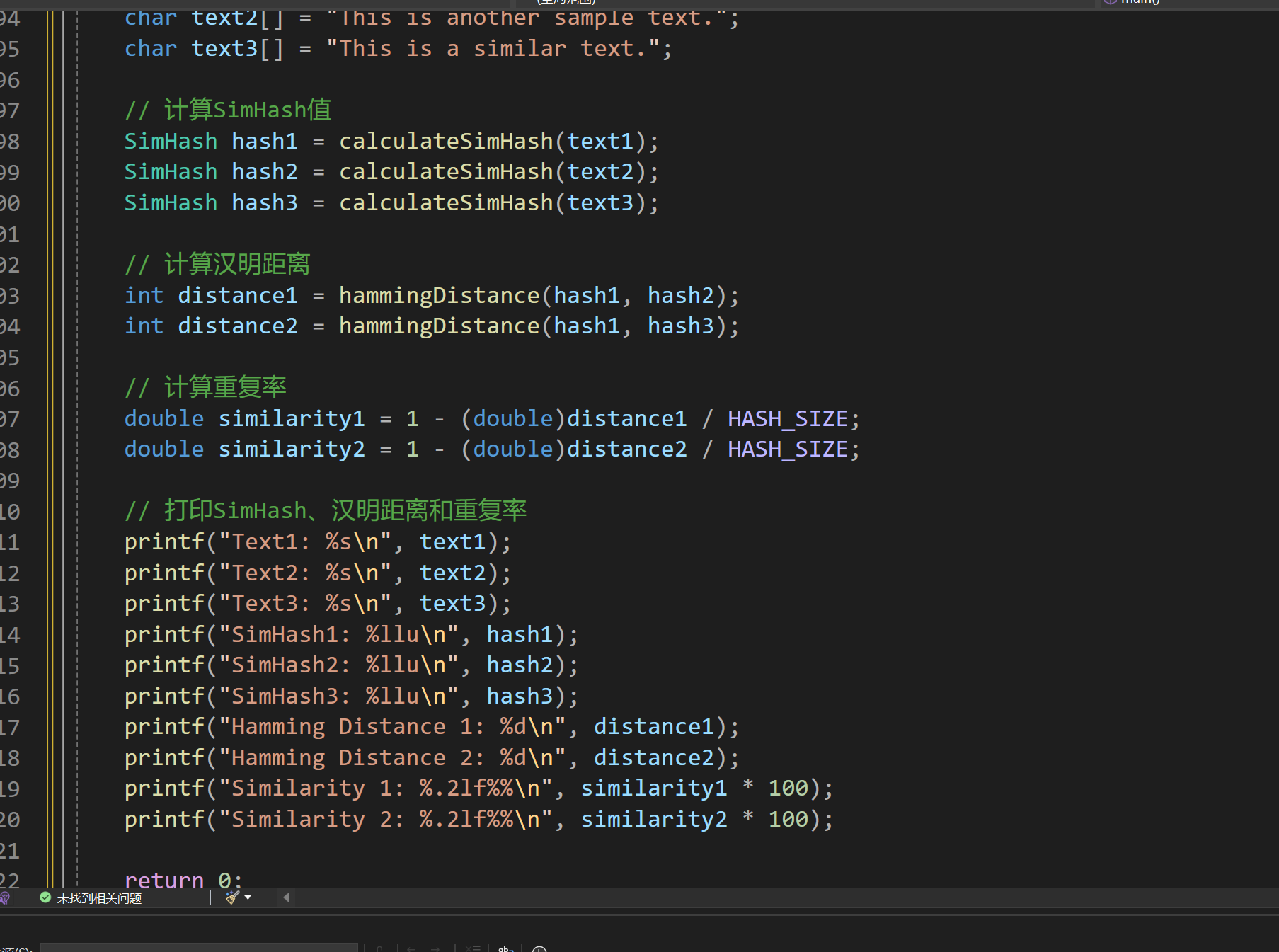

SimHash测试
通过多次更换text中的语句,进行大致的判断

 浙公网安备 33010602011771号
浙公网安备 33010602011771号