逆向基础-基础知识和常用汇编指令
关于计算机的一些基础概念
什么是寄存器
寄存器是计算机中的一种非常小但速度极快的数据存储单元,通常位于中央处理器(CPU)内部。
寄存器用于临时存储数据、地址、状态标志以及其他与指令执行、数据处理和任务管理相关的信息。
需要注意的是,寄存器不是CPU特有的概念,除了CPU,其他一些芯片也有寄存器,比如中断控制芯片等。
计算机的存储体系
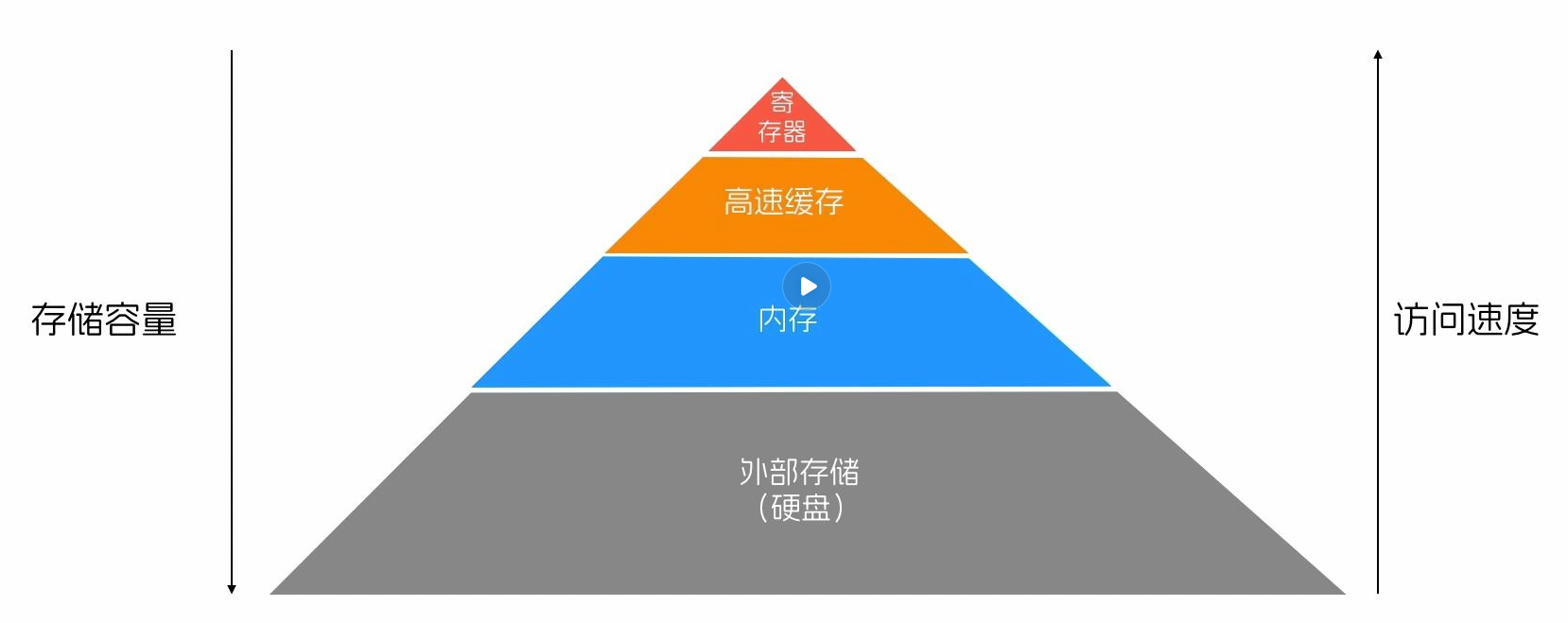
图中整体系,从上到下容量越来越大,但是访问速度越来越慢
寄存器和高速换成存在CPU的内部,CPU的计算部件访问起来速度非常快
内存需要走总线系统传输数据,加上本身还有寻址和读取数据的时间,速度会比寄存器和缓存慢很多
外部存储则是受限于其存储原理、大容量寻址、总线传输的限制,所以访问起来是最慢的
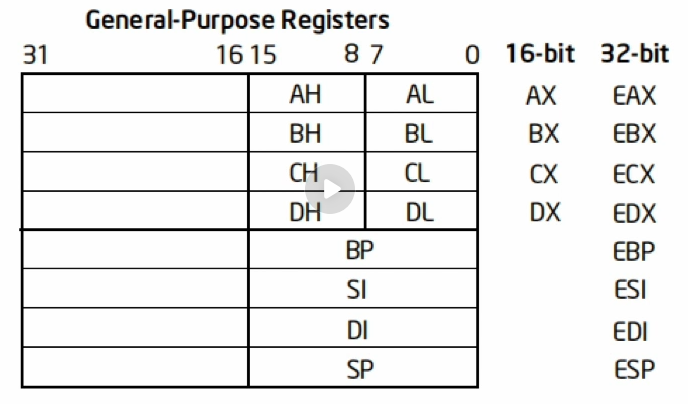
x86架构CPU寄存器(16位)
从最简单的16位的8086CPU分析
这个寄存器拥有八个通用寄存器,四个段寄存器,一个指令寄存器,一个标志寄存器
虽然名称为通用寄存器,但是实际用途中并不是真的通用,八个寄存器各有各自的用处
比较特殊的是段寄存器,因为这四个寄存器涉及到实模式、保护模式下段寄存器两种完全不同的用法
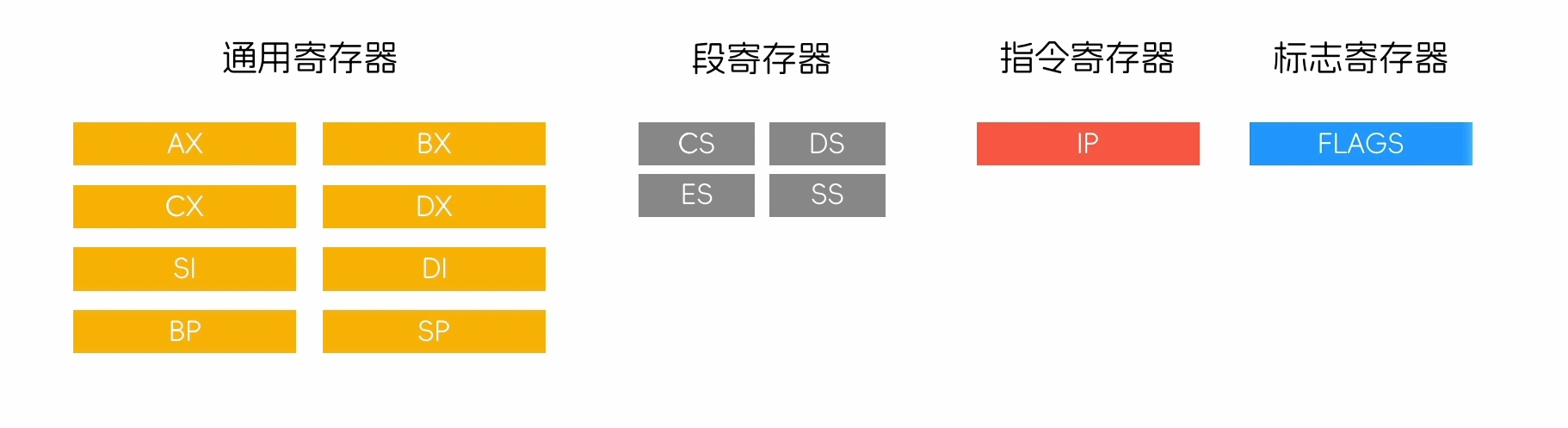
- 通用寄存器
AX:
BX:
CX:
DX:
SI:间接寻址存放源和目的地址
DI:间接寻址存放源和目的地址
BP:
SP:指向堆栈的最顶部
- 段寄存器
CS:指向代码段(Code Segment)
DS:指向数据段(Data Segment)
ES:指向附加段(Extra Segment)
SS:指向堆栈段(Stack Segment)
- 指令寄存器
IP:存放程序下一条将要执行的指令的地址,引导CPU的执行流程
- 标志寄存器
FLAGS:存放程序运行过程中的一些标志和状态信息
关于8086CPU图解

从图中我们可以看出地址线是20位,而数据线是16位
AD 0~A19/S6:这20个针脚代表地址线
AD 0~AD 15:这16个针脚代表数据线
上面所述的AD分别代表address(地址)和data(数据)。其中的前面16个针脚均是数据线和地址线复用的针脚
因为地址线共有20个针脚,而2^10=1024=1KB。
所以地址大小为2^20=1024*1024=1MB,所以8086的寻址空间为1MB。
而8086CPU的寄存器是16位的,寻址空间最大为64KB
(2^16)/1024 = 64KB
为了解决寻址问题,所以启用段寄存器来存储段基地址,而其他寄存器所存储的地址是相对于段的偏移地址,
寻址的时候就是:段寄存器中的地址+其他寄存器中的地址=完整地址
比如CS+IP
关于寄存器寻址方式
实模式(实地址模式)
实模式下的寻址:段基址+段内偏移
取指令:CS:IP
取数据:DS:SI
读取堆栈:SS:SP
缺陷:
1. 寻址空间最大只支持1MB(地址总线是20位)
2. 多进程剑内存无法很好的隔离
3. 缺乏权限控制,应用程序很容易访问操作系统内核地址空间
x86架构CPU寄存器(32位)
保护模式
保护模式下有两种内存管理:分段式内存管理+分页式内存管理
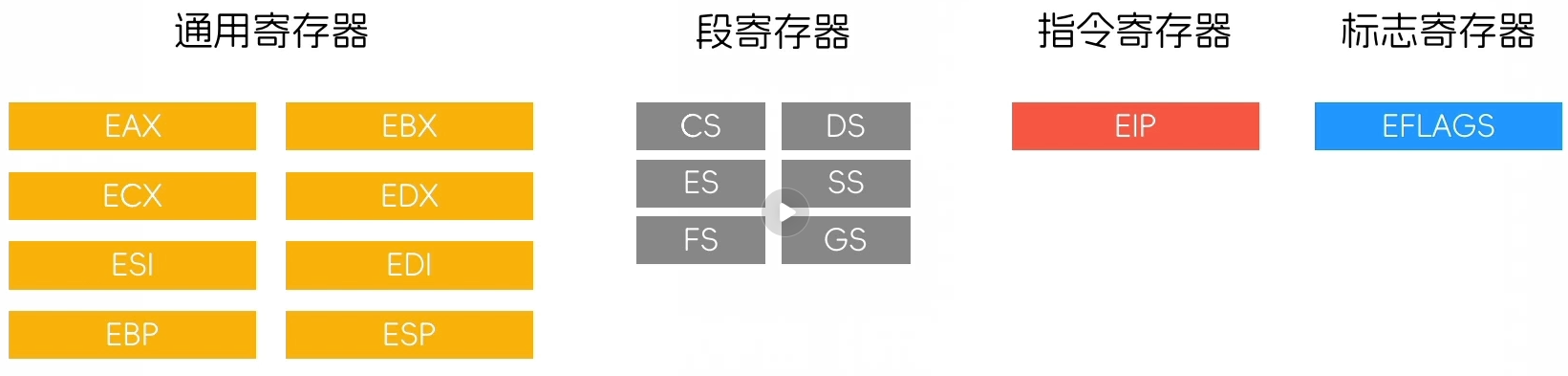
在16位寄存器名字原有基础上的前面加上了一个E,代表扩展Extend
然后段寄存器增加两个:FS和GS
16位只能寻址64KB,而32位则是可以寻址4GB那么大的地址空间
- 分段式内存管理
8086CPU采用的其实就是分段式内存管理模式,把内存分成一段一段的进行控制管理
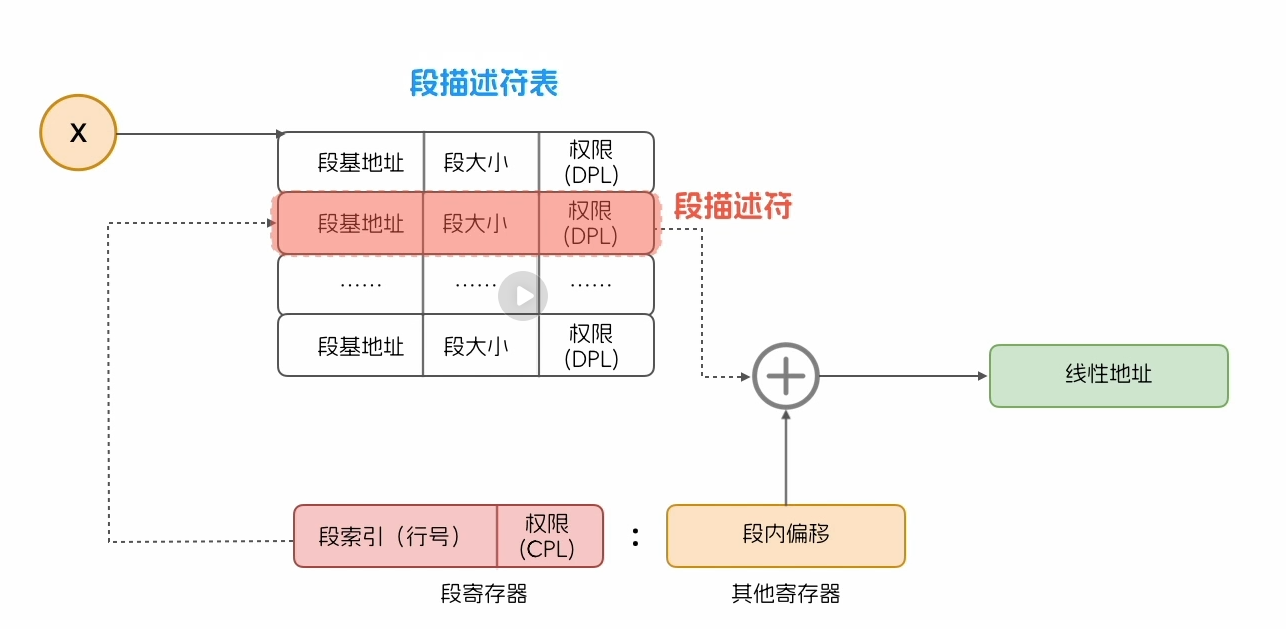
而32位操作系统则在段寄存器这里引入了一个新机制:段描述符
而存储段描述符的表被称为段描述符表
DPL(Descriptor Privilege Level):在段描述符中,有一个是对权限描述的位置,占用两个比特位
CPL(Current Privilege Level):在段寄存器中也有一个地方用来描述权限,也占用两个比特位
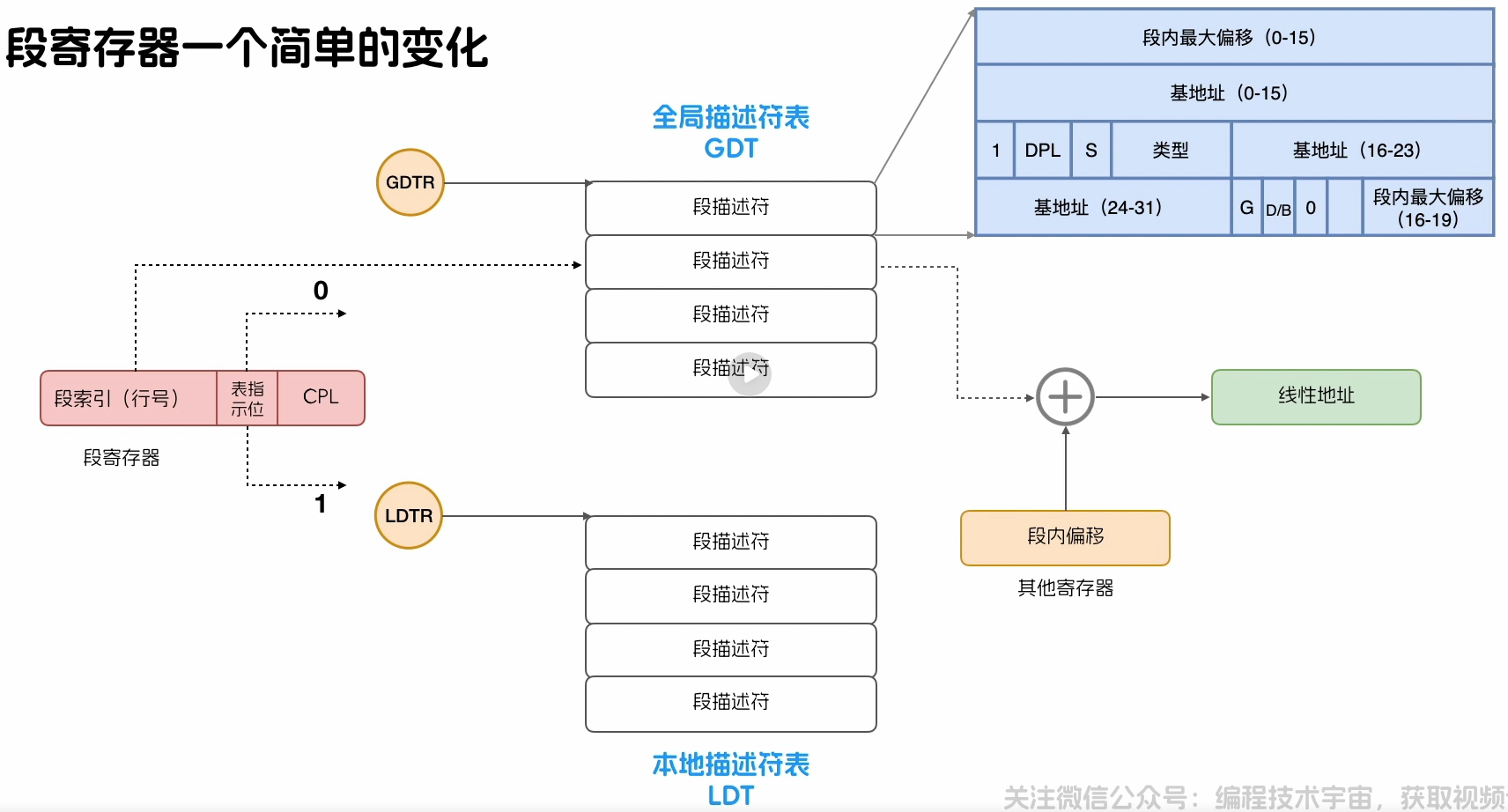
表指示位:占用一个比特位,用来记录使用那一个段描述符表
GDT:全局描述符表
LDT:本地描述符表
专门用来指向描述符表的寄存器
1. GDTR
2. LDTR
权限管理方式就是,程序执行的时候,调取段寄存器中的表指示位获取(确定)对应的段描述符表,
然后根据段索引找到对应的段描述符,再通过CPL与对应段描述符表中
的DPL进行对比确认权限,如果权限准许,则获取段基地址然后与段内
偏移地址进行拼接,最后得到需要的线性地址
分段式内存管理解决了权限的问题,但是依然没有解决多进程之间内存空间如何隔离的问题
- 分页式内存管理
在没有使用分页式内存管理的时候,多程序的情况下,如果读取同一
个物理地址中的数据,都是一样的,如果有程序进行了这个数据的修改,
则其他程序也会受到影响,为了解决这个问题,所以引入分页式内存管理。
操作系统把进程所需要使用的地址空间内存和物理内存都进行分页,
每页大小一般都是4KB,然后再把进程地址空间的内存页面和物理内存
页面进行映射。这样操作系统也就掌管了进程地址空间的内存页面和
物理内存页面的映射关系,并负责为所有进程分配和回收页面。而进
程看到的内存地址空间不再是真实的内存,而是虚拟的内存地址。
但是随着进程的增多,物理内存就算再大,也有被消耗完的那一刻。
这时候操作系统会把长期不怎么被调度的内存页面中的数据写入到硬
盘中的分页文件(临时)里面,然后再给新的进程地址空间页面分配
这个刚刚被腾出来的内存页面。如何后面有程序需要用到被保存到硬
盘上的分页文件中的数据的时候,则会重新去把这个数据加载回来。
这样的操作方式,实际使用的内存是大于真实的内存的,多出的这部
分内存就被成为虚拟内存。
对于一个程序来说,虽然给到的是真实内存那么大的可以正常使用的内存,
但是内存真正被使用的部分是比较少的,其他很多地方属于空白状态,比
如一个4GB的内存,表的行数:4GB / 4KB = 1048576,而存储这张表需要
的内存量:( 4B + 4B ) * 1048576 = 8388608 B = 8MB。
如果是这种情况,这张表里面大片空白的数据,那么会造成内存的浪
费,并且这还只是一个进程的情况下,如果多个进程,每个都有这一张
表,那么资源会被大量浪费了。为了解决这个问题,我们把这张大表分
成多个小表,假设每个小表是1024项,然后再弄个表(根表)对这些小
表进行管理,这个根表的每一项都记录一个小表,所以这个根表总共共
需要1024项映射。等到需要查询数据的时候,从根表查询,如果映射不
存在,则小表则不存在,这时候不仅查询效率上去了,存储的利用率也上去了
根表:页目录
小表:页表
CR3寄存器:指向当前进程的页目录所在的内存地址
x86把虚拟内存地址分成了3段,分别是10位,10位,12位
页目录索引:22~31
页表索引:12~21
页内偏移:0~11

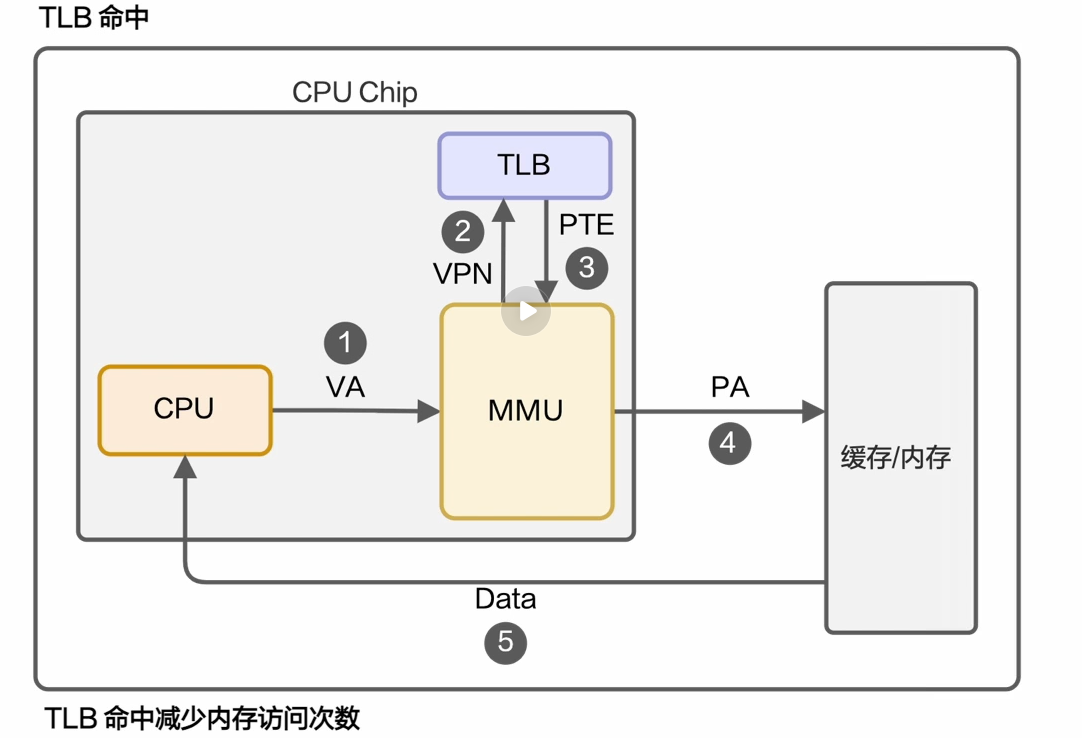
TLB:转换后备缓存区
这是CPU内部提供的缓存空间,用来把翻译过的内存地址存储起来,
如果后面遇到同样的地址的时候,就优先查这里面的。这样可以节省大量的性能开销
x86架构CPU权限级别
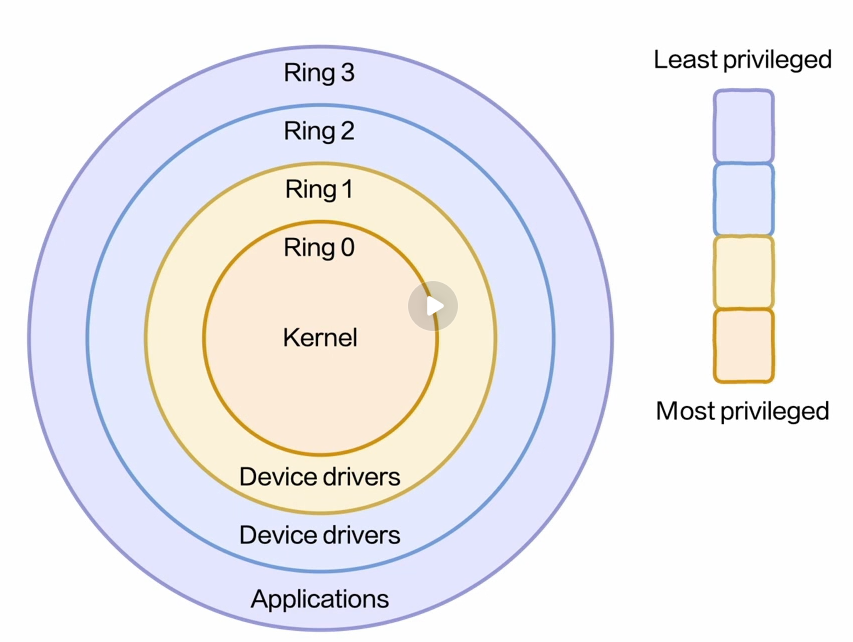
共有四个权限级别,从Ring0-Ring3,一般成为0环到3环。其中0环是权限最高级别,3环是权限最低级别。
在英特尔设想中,操作系统运行在0环,各种驱动程序运行在1环和2环,
应用程序运行在3环,而外环的程序代码无法访问内环的内存空间。
但是Windows和Linux都嫌这种方式过于麻烦,所以只是用来0环和3环。
操作系统内核、驱动程序在0环,应用程序在3环。所以我们很少听见1环和2环
关于在cpu中,汇编使用的指令名和格式的差异
比如都是把5这个值赋值给eax寄存器
- windows
windows的芯片是intel的,指令如下:
mov eax,5
三个位置分别是:
mov:指令助记符
eax:目标操作数
5:源操作数
- linux
linux的芯片是AT&T的,指令如下:
movl $5,%eax
三个位置分别是:
movl:指令助记符
$5:源操作数
%eax:目标操作数
运算符
数学运算
- 加法:add
- 减法:sub
- 乘法:mul/imul
- 除法:div/idiv
逻辑运算
- 与:and
- 或:or
- 非:not
- 异或:xor
比较
- 比较大小:cmp
- 测试:test
函数调用
- 调用:call
- 返回:ret
- 系统调用:sysenter/syscall
- 系统调用返回:sysexit/sysret
- 中断返回:iret
堆栈操作
- 压栈:push
- 出栈:pop
- 寄存器批量入栈:pushad
- 寄存器批量出栈:popad
- eflags寄存器入栈:pushfd
- eflags寄存器出栈:popfd
跳转
- 条件跳转:je/jz/jne/jnz/jb/jnb/jg/jng
- 无条件跳转:jmp
赋值
- 普通:mov
- 单字节:movsb
- 双字节:movsw
- 四字节:movsd
- 取地址:lea
关于字
- 字节:byte
- 字:word
- 双字:dword
- 四字:qword
关于位,字节,字,字长的概念描述和关系
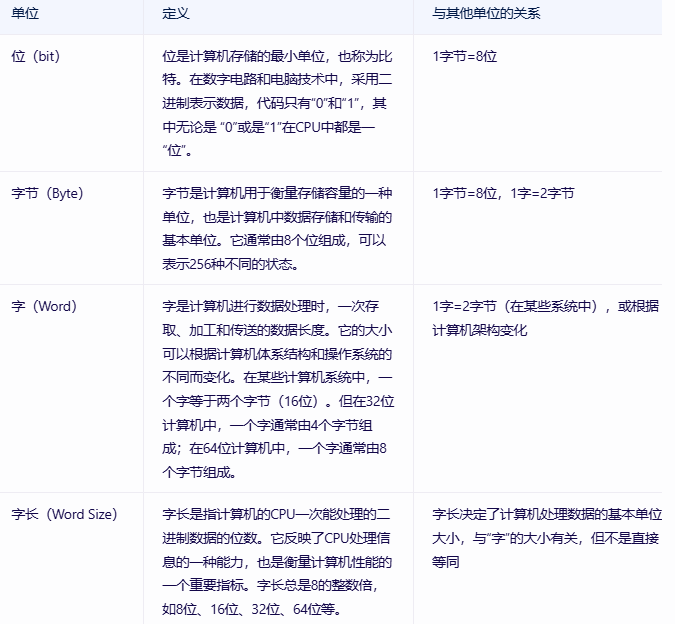
位(bit):位是计算机存储和处理数据的最小单位。在二进制系统中,一个位只能表示0或1两种状态。
字节(Byte):字节是计算机中常用的数据存储单位。它通常由8个位组成,可以表示从00000000到11111111的256种不同的状态。
在计算机中,文本、图像、音频和视频等数据都是以字节的形式存储和传输的。
字(Word):字是计算机进行数据处理时的一个固定长度的位组。它的大小可以根据不同的计算机体系结构和操作系统而变化。
在某些计算机系统中,一个字等于两个字节(即16位)。但在现代计算机中,特别是在32位或64位计算机中,一个字的大小通常更大,以匹配CPU的字长。
字长(Word Size):字长是指计算机的CPU一次能处理的二进制数据的位数。它决定了计算机处理数据的基本单位大小。
字长越大,计算机在单次操作中能处理的信息量就越大,从而可能提高运算精度和处理效率。但字长的增加也会伴随更高的资源消耗和技术实现难度。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号