计算机系统结构 互联网路、并行主存系统、霍纳法则和forkjoin
互联网络的设计目标
- 成本要低:结构不要复杂
- 性能要高:处理单元间信息传送的步数要少
- 灵活性高:满足算法和应用需要
- 可扩充性:能用基本构件组合实现复杂的互连
互联网络要抉择的问题
- 操作方式:同步(阵列处理机(单处理机):SIMD)、异步(多处理机)、同步异步组合
- 控制策略:集中式(SIMD)、分布式
- 交换方式:线路交换、包交换、线路与包交换组合
- 拓扑结构:
- 静态拓扑(线型、环型、树型、网络型等):不灵活
- 动态拓扑(单级、多级)
单级互联网络
- 立方体单级网络(Cube(N))
- PM2I单级网络(PM2(±i))
- 混洗交换单级网络(Shuffle)
- 蝶形单级网络(Butterfly)
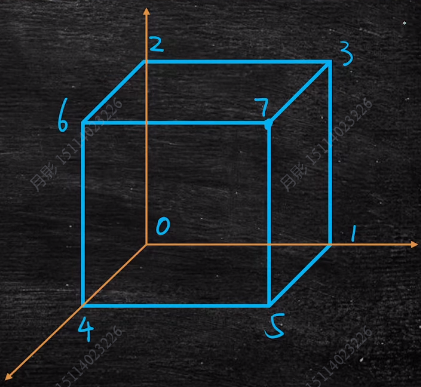
立方体单级网络(Cube(N))
_
Cube₀(b₂b₁b₀)
_
Cube₁(b₂b₁b₀)
_
Cube₂(b₂b₁b₀)
上图中,立方体有8个顶点,编号为0-7,根据log₂8=3,所以每个顶点边线直连为三个顶点。如果把每个顶点编号都换成二进制编号,则可以发现直连顶点与当前顶点关系只会对某一个二进制数位取反。比如顶点7,二进制为111,与之相连的是3(011),5(101),6(110),每次111其中一个数位取反则可以得到其他三个数值
PM2I单级网络(PM2(±i))
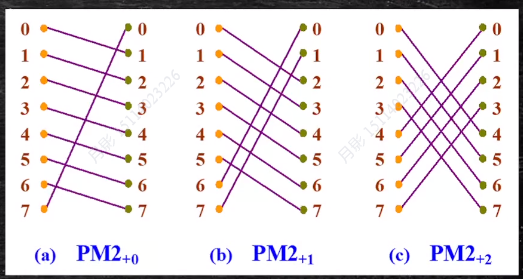
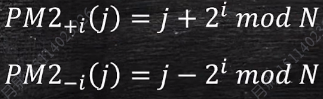
PM2+i(j) = j + 2^i mod N
PM2-i(j) = j - 2^i mod N
其中的j是代表顶点编号,i代表代表log₂N的数值,比如N=8的时候,log₂8=3,i取值为0,1,2这三个数
最大传输距离:N/2
混洗交换单级网络(Shuffle)
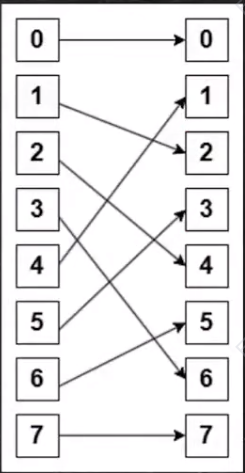
Shuffle(b₂b₁b₀) = b₁b₀b₂
蝶形单级网络(Butterfly)
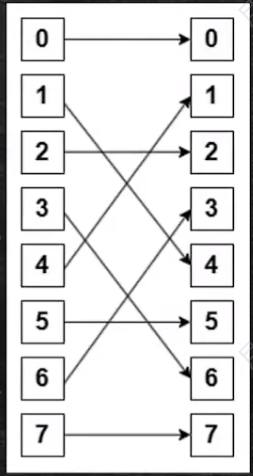
Butterfly(b₂b₁b₀) = b₀b₁b₂
如果是四位,直观点看:Butterfly(ABCD) = DCBA
多级互联网路
- 多级立方体网络
- 多级混洗交换网络
- 多级PM2I网络
- 基准网络
交换开关
四个状态:
直连
交换
上拨
下拨
如果有个开关只有一个状态,被称为单功能开关,两个状态被称为二功能开关,四个状态都有,称为四功能开关
级控制方式
- 级控制
设定某一个级中所有开关所拥有哪些状态,同一级别下,所有开关状态是一致的,比如只设定0级中所有开关为直连,那么此时就只会直连
- 单元控制
不同开关有各自不同的状态,不分级别,只把开关看成一个个体
- 部分级控制
比如设定第0级别开关只有一种状态,那么第1级别就是两种状态,第2级别就是三种状态,第N个就是N+1种状态
多级立方体网络
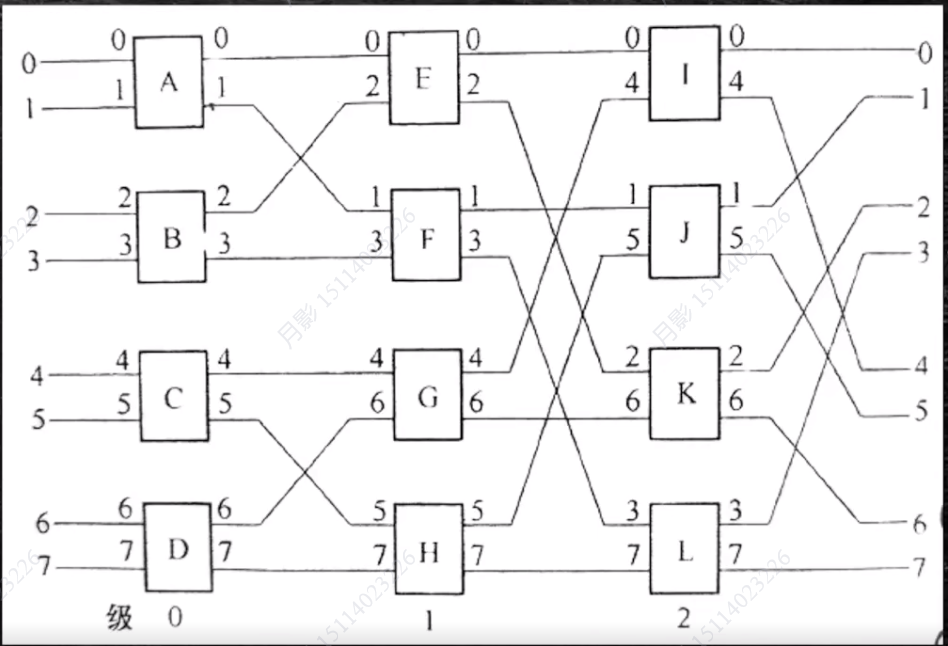
- STARAN网络
- 间接二进制N方体网络
多级混洗交换网络

- 又称Omega网络
- 四功能交换单元
- 单元控制
并行主存系统的无冲突访问
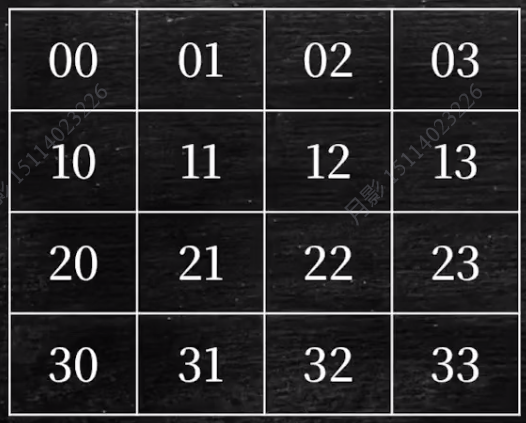
要实现无冲突访问,需要进行存储体拓展,按质数个拓展,比如途中是4列,则拓展为5列,如果是8列,则拓展为11列。然后下一行与上一行第一个相差2个存储体,如下图所示
多处理机(MIMD)
- 概念
- 两台以上
- 共享I/O
- 通过共享主存或通信网络通信
- 协同求解
- 目标
- 提高性能
- 提高系统可靠性、适应性和可用性
硬件结构
- 紧耦合多处理机
- 通过共享主存实现通信
- 有两种构型,区别在于是否自带专用Cache
- 松耦合多处理机
- 较大的局部存储器
- 通信: 通道互连、消息传送系统
- 两种构型:层次型和非层次型
机间互连形式
- 总线
- 环形互连
- 交叉开关
- 多端口存储器
- 蠕虫穿洞寻径网络
- 开关枢纽结构形式(分布结构多处理机)
多Cache的一致性问题解决办法
- 解决进程迁移引起的多Cache不一致性
- 禁止进程迁移
- 让进程中的数据重新写回主存中
- 以硬件为基础实现多Cache的一致性
- 监视Cache协议法:实现简单,只适用于总线互连、机数较少的多处理机
- 写作废法:IBM 370
- 写更新法(又叫播写法)
- 目录表法
- 全映像目录表
- 有限目录表
- 链式目录表
- 监视Cache协议法:实现简单,只适用于总线互连、机数较少的多处理机
- 以软件为基础实现多Cache的一致性(低成本、低可靠性)
并行算法
- 按运算对象来分:数值型和非数值型
- 按并行进程间的操作顺序来分:同步型、异步型、独立型
- 按任务粒度来分:细粒度、中粒度、粗粒度
霍纳法则
- 利用交换律、分配律:把相同的计算集中在一起
- 利用结合律、分配律:把操作数配对,尽可能并行,减少树高
程序段的数据相关
- 无任何相关:可以并行、交换串行、顺序串行
- 数据相关(先写后读):不能并行,特殊情况下可以交换串行
- 数据反相关(先读后写):可以并行,不能交换串行
- 数据输出相关(写-写):可以并行,不能交换串行
- 先写后读+先读后写:必须并行、读写要同步,不能交换串行和顺序串行
FORK JOIN
- 题目
Z = E + A *B * C / D + F
这道题我们先通过霍纳法则进行划分,然后再看其步骤
(E + F) + [(A * B) * (C / D)]
所有可以得到步骤:
X1 = A * B
X2 = C / D
X3 = G * H
X4 = E + F
Z = X3 + X4
根据分析X1和X2并行,X3和X4并行
根据上面步骤,我们可以得到以下FORK JOIN语句:
FORK S20
S10 X1
JOIN 2
GOTO S30
S20 X2
JOIN 2
S30 FORK S50
S40 X3
JOIN 2
GOTO 60
S50 X4
JOIN 2
S60 Z
多处理机操作系统分类
- 主从型操作系统(适用:负荷固定、功能相差大的异构多处理机)
- 简单、经济、方便,是目前主流
- 对主处理机可靠性要求高(单点故障率高)
- 各自独立型操作系统(适用:松耦合多处理机)
- 可靠性高、效率高
- 实现复杂、各处理机负荷平衡困难、存储器利用率低
- 浮动型操作系统(适用:紧耦合多处理机)
- 各类资源负荷平衡、灵活性高
- 设计最困难
数据流计算机和归约机
工作方式
- 控制驱动:冯诺依曼型计算机
- 数据驱动:数据流计算机
- 需求驱动:归约机(函数式语言)
数据流计算机模型(基于异步性、函数性)
- 数据驱动
- 需求驱动
数据驱动
- 按数据可用性次序进行
- 数据就绪即可执行,是提前求值的策略
需求驱动
- 按数据需求所决定的次序
- 某函数需要用到数据时才驱动求值操作,是滞后求值的策略
数据流计算机的结构(根据对数据令牌处理方式不同)
- 静态数据流计算机
- 数据令牌没加标号
- 不支持递归的并发激活,只支持一般的循环
- 动态数据流计算机
- 令牌带标记
数据流计算机存在的问题
- 不适用于数据相关性强的场景
- 给数据建立、识别、处理标记需要额外开销和存储空间
- 不保存数组
- 变量表示数值,而不是存储单元位置
- 互联网络设计困难,I/O系统不完善
- 没有程序计数器,诊断和维护困难
数据流计算机的进展
- 采用提高并行性等级的数据流计算机
- 采用同步、异步结合的数据流计算机
- 采用控制流、数据流相结合的数据流计算机
归约机
- 基于数据流计算机模型
- 采用需求驱动(对数据的需求来源于函数式语言对表达式的归约)
归约机的特点
- 面向函数式语言、或以函数式语言为机器语言的非冯诺依曼机器
- 具有大容量物理存储器和虚拟存储器
- 处理部分是多个处理机并行的结构
- 采用适合于函数式程序运行的多处理机互连结构(如树形互连、多层次复合的互连)
- 进程、数据、结点机、处理机尽量靠近

 浙公网安备 33010602011771号
浙公网安备 33010602011771号