redis key的基础命令
官方文档
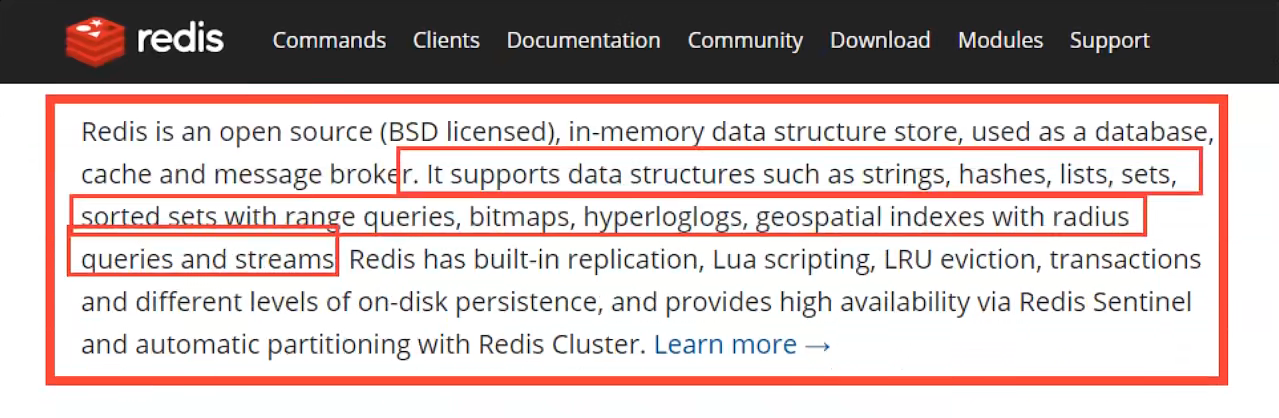
redis中文网站解释如下:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
五大数据类型
Redis-Key
# 设置key-value
set <key> <value>
# 通过key得到value
get <key>
# 查看当前全部key
keys *
# 判断当前数据库中是否存在某一个key值
exists <key>
# 移除某一个值(注意,db起始值在这里为1)
move <key> <db>
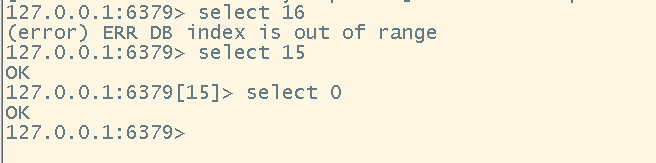
# 切换数据库(注意,切换数据库的时候,默认共计16个数据库,但是起始值为0,所以最大值为15)
select <db>
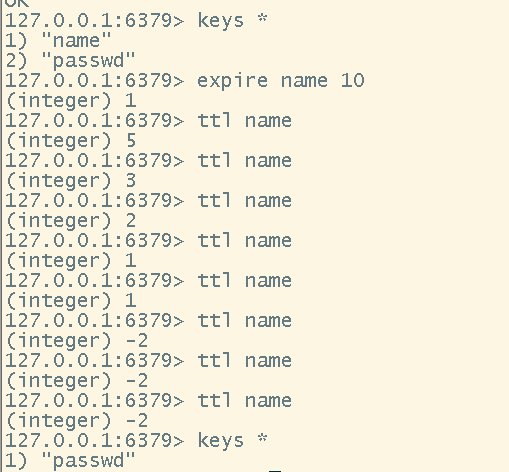
# 设置某个值过期时间
expire <key> <seconds>
# 查看某个值距离过期时间还剩多久,如果为-2则代表已经过期
ttl <key>
# 查看当前key的类型
type <key>
- 切换到最后一个数据库和第一个数据库
- 设置过期时间和查看还有多久过期
String(字符串)
# 给某一个值后面追加内容
append <key> <new value>
# 查看某个值的长度
strlen <key>
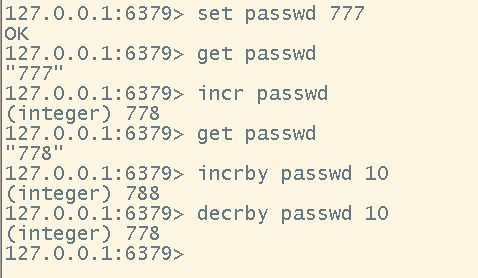
# 自增+1
incr <key>
# 自减-1
decr <key>
# 自定义自增量
incrby <key> <num>
# 自定义自减量
decrby <key> <num>
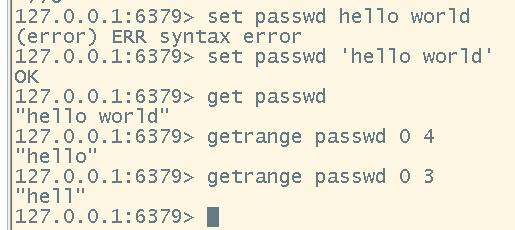
# 截取字符串(注意,start为0,end为-1的时候是获取当前key下的全部value。并且取值的时候,是闭区间[start,end])
getrange <key> <start> <end>
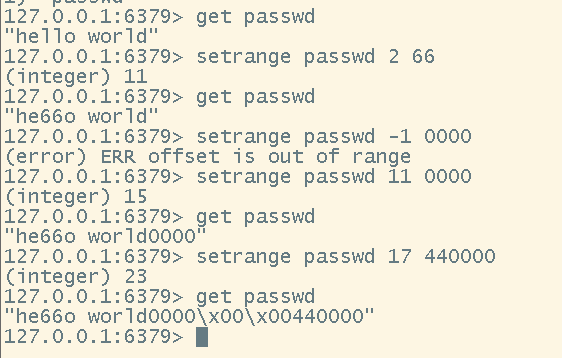
# 在指定位置替换或插入指定字符串
setrange <key> <start> <value>
# 设置某个值过期时间
expire <key> <seconds>
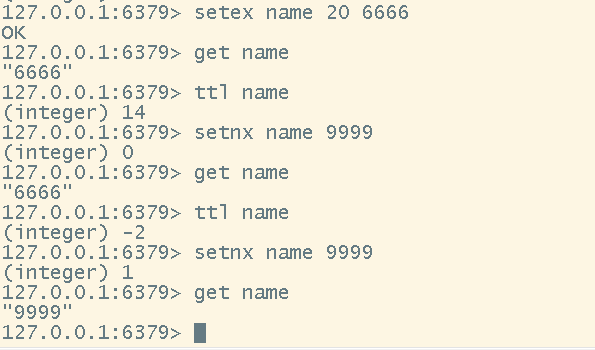
# 创建一个key-value,并且设置过期时间(set with expire)
setex <key> <seconds> <value>
# 创建key-value的时候,如果key已经存在了,则不会创建,如果不存在则创建
setnx <key> <value>
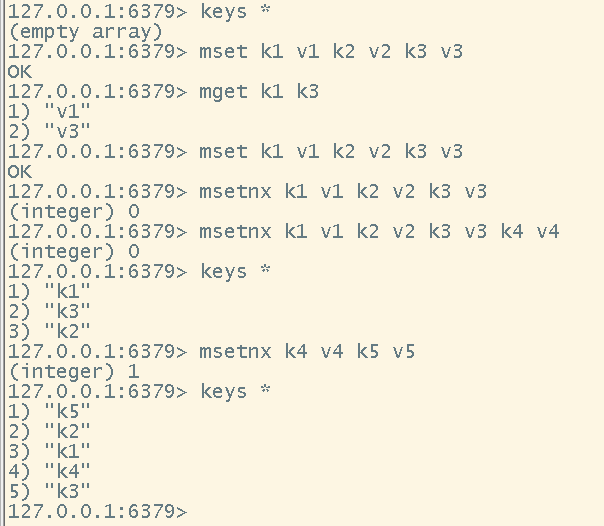
# 批量设置值
mset <key> <value> [<key> <value> .......]
# 批量获取值
mget <key> [<key> ......]
# 批量创建,并且在创建之前做批量判断即将创建的值是否存在(该操作是原子性的操作,要么都创建成功,要么都创建失败)
msetnx <key> <value> [<key> <value> ......]
# 先获取值,再设置值(打印出来的是上一个value,当前存储的是当前输入的value)
getset <key> <value>
- 设置自增和自减
- 截取字符串
- 在指定位置替换或插入指定字符串
- 设置过期时间和判断key-value是否创建
- 批量创建和批量获取
- 先获取值,再设置值
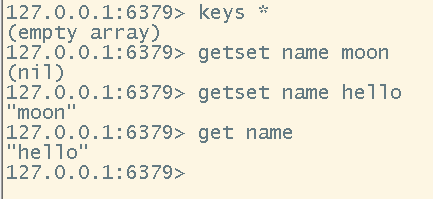
# 实战中的一些思路和用法
# 如果我们需要存储对象格式,比如这样的:{name:moon,age:19},且需要按照表,id,字段的方式存储的话,可以这样构建数据
mset <table>:<id>:<field>
# 举例
mset user:1:name moon user:1:age 19
# 注意:这里把user:1:name看出普通key即可,在redis中允许冒号(:)这个特殊字符
List
# 创建一个list,并且从左边开始向list里面存储一个或多个元素(或者直接在已有的list中存储一个或多个元素)
lpush <key> <element> [<element> ......]
# 创建一个list,并且从右边开始向list里面存储一个或多个元素(或者直接在已有的list中存储一个或多个元素)
rpush <key> <element> [<element> ......]
# 查看list中存储的元素内容(start为0,end为-1的时候是查询该list全部内容),此方法可以用作截取list
# 需要注意的是,get <key>命令无法直接查询list内容,会报错:(error) WRONGTYPE Operation against a key holding the wrong kind of value
lrange <key> <start> <end>
# 查询list长度
llen <key>
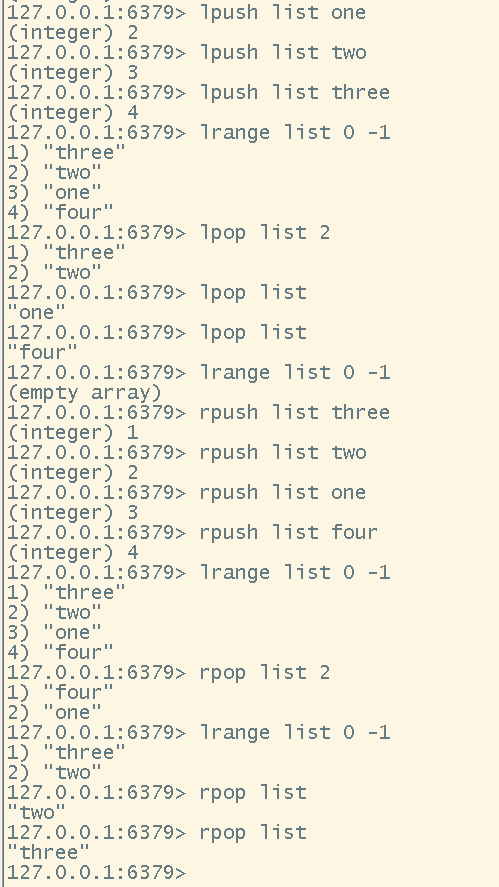
# 移除list中最左边的元素
lpop <key>
# 移除list中最右边的元素
rpop <key>
# 移除list从左开始的前num个元素
lpop <key> <num>
# 移除list从右开始的前num个元素
rpop <key> <num>
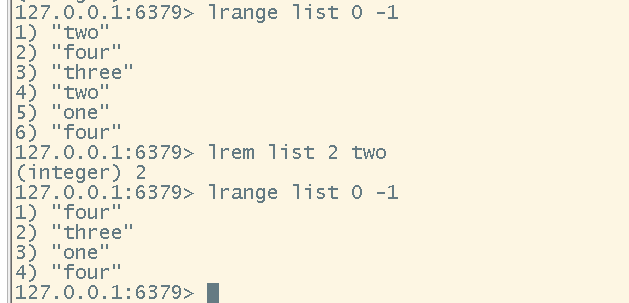
# 移除list中指定的元素(如果list中有多个重复值,可以通过count选择需要移除的重复值的个数)
lrem <key> <count> <element>
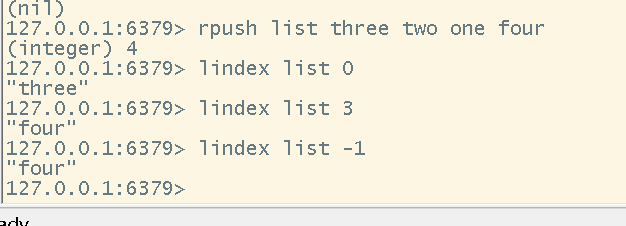
# 获取指定下标的值
lindex <key> <index>
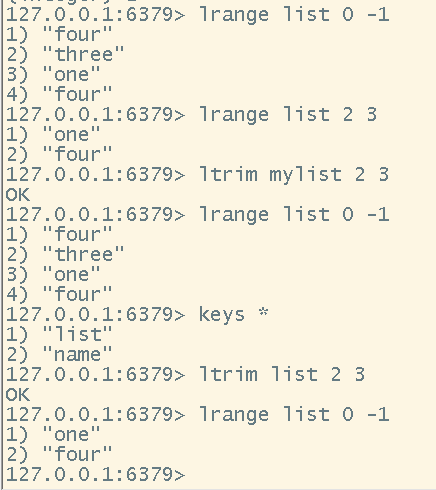
# 截取指定位置为一个新的list,并存储到redis中
# 注意:ltrim与lrange的区别在于,前一个截取后,会把原来的list替换为截取后的list,lrange则是理解为查看当前list的某一段元素,原本的list并没有受到影响
ltrim <key> <start> <end>
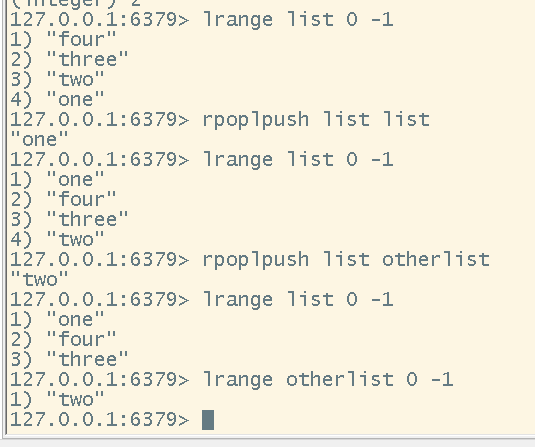
# 移除当前list最右边的元素,并且把该元素存放到指定列表的最左边
# 注意:list1和list2可以是同一个list,这个方法是把某一个列表最右边的元素取出来后移动到指定的列表的最左侧
rpoplpush <list1> <list2>
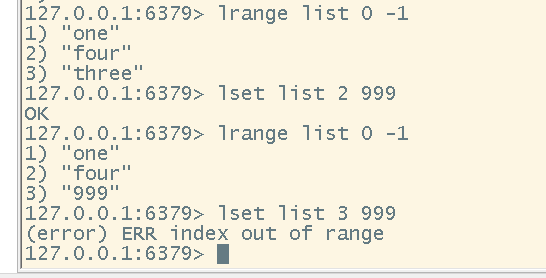
# 将指定下标的值替换为指定的值,更新列表某个值
# 注意:该方法只能更新已存在的元素,如果超过list长度,则返回报错:(error) ERR index out of range
lset <list> <index> <element>
# 向list中,在指定位置插入一个元素
linsert <key> <before|after> <element> <new element>
-
list添加元素,查看元素,获取list长度

-
移除list元素
-
移除指定元素
-
通过下标获取指定元素的值
-
把list截取为一个新的list
-
移除当前list最右边的元素,并且把该元素存放到指定列表的最左边
-
更新列表某一个值
-
在list中的指定位置插入一个值
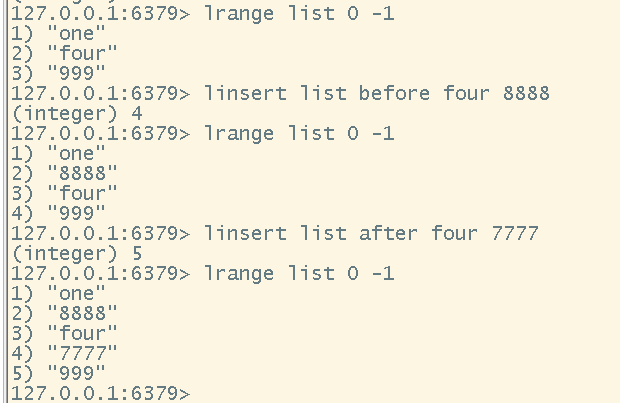
-
总结
1. 在redis中的list实际是一个链表,before node after。left,right都可以插入值
2. 如果key不存在,则创建一个新的链表,如果存在key,则新增内容
3. 如果移除所有值,空链表,也是代表不存在的
4. 在两边插入或者改动值,效率最高。对于更改中间元素,效率会低一些
Set(无序集合)
- set中的值是不能重复的
# 创建set或者添加元素
sadd <key> <value>
# 查询set中的内容
smembers <key>
# 判断set中是否存在某个元素
sismember <key> <element>
# 获取set长度
scard <key>
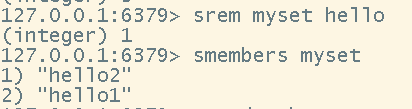
# 移除set中的指定元素
srem <key> <element>
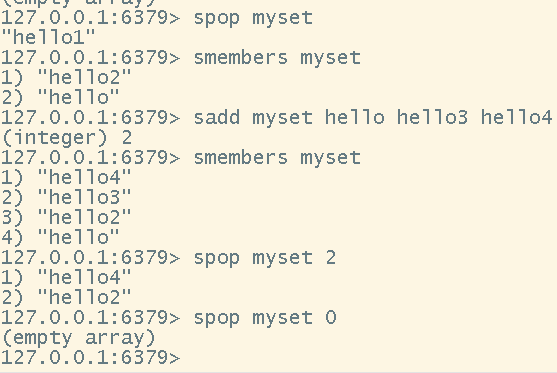
# 随机移除num个元素(num默认为1)
spop <key> <[num]>
# 随机从set中抽选出num个元素(num默认为1)
srandmember <key> <[num]>
# 将一个指定的值移动到另一个指定的set中
# 注意:如果key2原本不存在,则新创建一个并且把被移动的值存入其中
smove <key1> <key2> <element>
# 比较多个set之间的元素差异(差集)
# key1和后面的keyN进行比较,返回结果为key1中有的元素,而keyN中没有的元素
sdiff <key1> <key2> [...<keyN>]
# 获得差集,并且把差集结果存放在一个新的set中
sdiffstore <new key> <key1> <key2> [...<keyN>]
# 获取多个set之间的共同元素(交集)
sinter <key1> <key2> [...<keyN>]
# 获得差集,并且把交集结果存放在一个新的set中
sinterstore <new key> <key1> <key2> [...<keyN>]
# 获取多个set之间的全部元素(并集)
sunion <key1> <key2> [...<keyN>]
# 获得差集,并且把并集结果存放在一个新的set中
sunionstore <new key> <key1> <key2> [...<keyN>]
- 给set添加元素和查询set中的元素
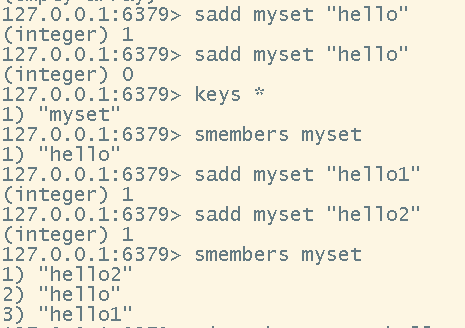
- 判断set中是否存在某个元素

- 查看set长度

- 删除set中指定的元素
- 随机移除num个元素
- 随机抽查set中的num哥元素
- 将set中的指定元素移动到另一个set中
- 比较多个集合之间的差异
- 将比较的差集存放在一个新set中

- 获取多个集合的相同元素
- 将比较的交集存放在一个新的set中

- 获取多个集合的全部元素

- 将比较的并集存放在一个新的set中

Hash
# 创建hash并存储元素
hset <key> <field> <value>[<field> <value>...]
# 批量存储元素
# 按照redis的提示,赶紧hmset和hset没区别,都可以一次性添加多个
hmset <key> <field> <value>[<field> <value>...]
# 取出hash中的value
hget <key> <field>
# 批量取出hash中的value
hmget <key> <field>
# 获取hash中的全部内容
hgetall <key>
# 删除hash中指定的值
hdel <key> <field>
# 查看hash中键值对数量
hlen <key>
# 判断hash中指定字段是否存在
hexists <key> <field>
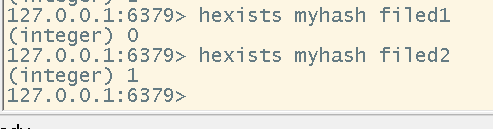
# 判断hash中是否存在某一个键,如果不存在则创建一个键值对
hsetnx <key> <field> <value>
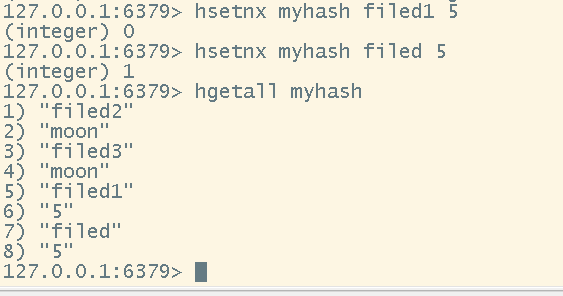
# 获取hash中全部的键
hkeys <key>
# 获取hash中全部的值
hvals <key>
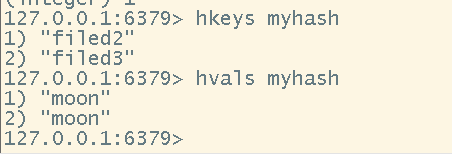
# 对某一个value进行自增或自减
# 注意:hash中没有decr,只有用incr负数操作达到自减的目的
hincrby <key> <field> <num>
- 创建hash,存储元素,查询元素
- 获取hash中的全部内容
- 删除hash中指定的值
- 获取hash中的键值对数量
- 判断hash中是否存在某一个键
- 判断hash中是否存在某一个键,如果不存在则创建一个键值对
- 获取全部的键或者值
- 对hash中的某一个值进行自增或自减
Zset(有序集合)
# 添加一个或多个值
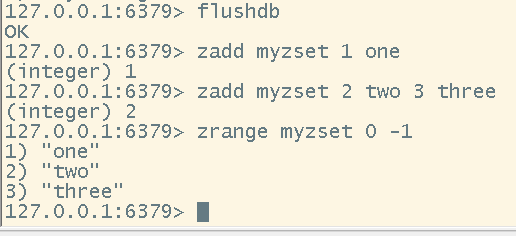
zadd <key> <index> <value> [<index> <value>...]
# 查看zset中的内容
zrange <key> <start> <end>
# 排序(升序)
# inf代表无穷的意思,在代码中不用更改
# zset默认情况下,只会打印value,withscores参数代表打印出index和value
zrangebyscore <key> <-inf> <inf> [withscores]
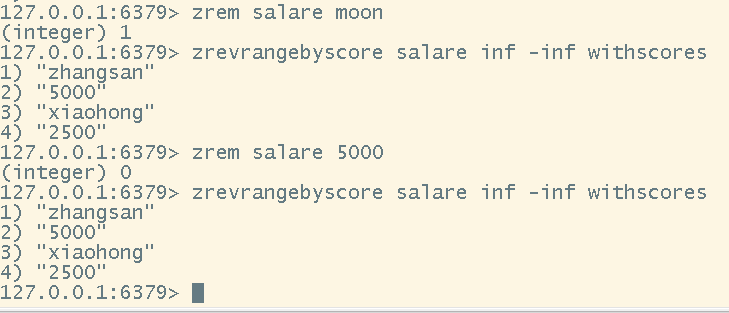
# 倒序排序(降序)
zrevrangebyscore <key> <inf> <-inf> [withscores]
# 移除一个元素
zrem <key> <value>
# 获取zset中的元素个数
zcard <key>
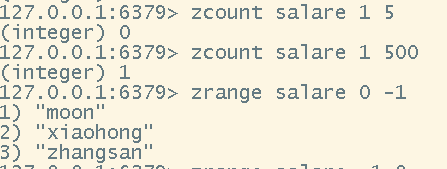
# 获取指定范围类的元素数量
zcount <key> <min> <max>
- 添加值和查看数据
- 排序

- 移除一个元素
- 查询元素个数

- 获取指定范围内的全部元素数量
三种特殊数据类型
geospatial(地理位置)
在3.2.0版本之前只有六个命令,在3.2.10 版本后,共有十个命令。
中文版本的redis官网,也只有这六个命令
中文版官网:http://www.redis.cn/commands/geoadd.html
官网:https://redis.io/commands/geoadd/
- 通用的六个命令:
GEOADD
GEODIST
GEOHASH
GEOPOS
GEORADIUS
GEORADIUSBYMEMBER
- 后面新增的四个命令
GEORADIUSBYMEMBER_RO
GEORADIUS_RO
GEOSEARCH
GEOSEARCHSTORE
- 命令使用
# 添加经纬度坐标和地理名称
# cityName是可以写成中文的,代表地点名称
# 经度(longitude)范围:[0,180]
# 维度(latitude)范围:[0,90]
geoadd <key> <longitude> <latitude> <cityName> [<longitude> <latitude> <cityName>...]
# 查询某一个城市的地理位置
geopos <key> <cityName>
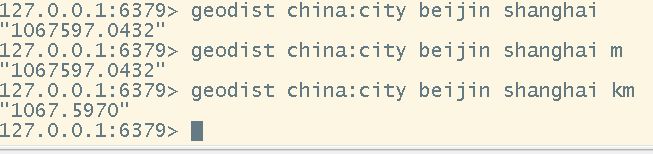
# 查询两个点之间的距离
geodist <key> <地点名称1> <地点名称2> [m|km|ft|mi]
# 以给定的经纬度为中心,搜索指定半径内的所有地理位置
# withcoord:展示出结果的坐标
# withdist:展示出结果距离当前指定经纬度的直线距离
georadius <key> <longitude> <latitude> <radius> [m|km|ft|mi] [withcoord] [withdist]
# 通过当前已存入的地点找出该地点周围指定范围内的其他地点
# withcoord:展示出结果的坐标
# withdist:展示出结果距离当前指定经纬度的直线距离
georadius <key> <value> <radius> [m|km|ft|mi] [withcoord] [withdist]
# 获取一个或多个位置元素的11个字符的geohash字符串
# 返回的字符串如何越像,则经纬度越接近
geohash <key> <cityName> [<cityName>...]
# geo的底层实现:zset。所以我们可以通过zset命令操作geo,具体命令可以查看zset
zrange <key> <start> <end>
- 添加经纬度坐标和地理名称

- 查询某一个城市的地理位置以及插入中文城市名

- 查询两点之间的直线距离
- 以给定的经纬度为中心,搜索指定半径内的所有地理位置
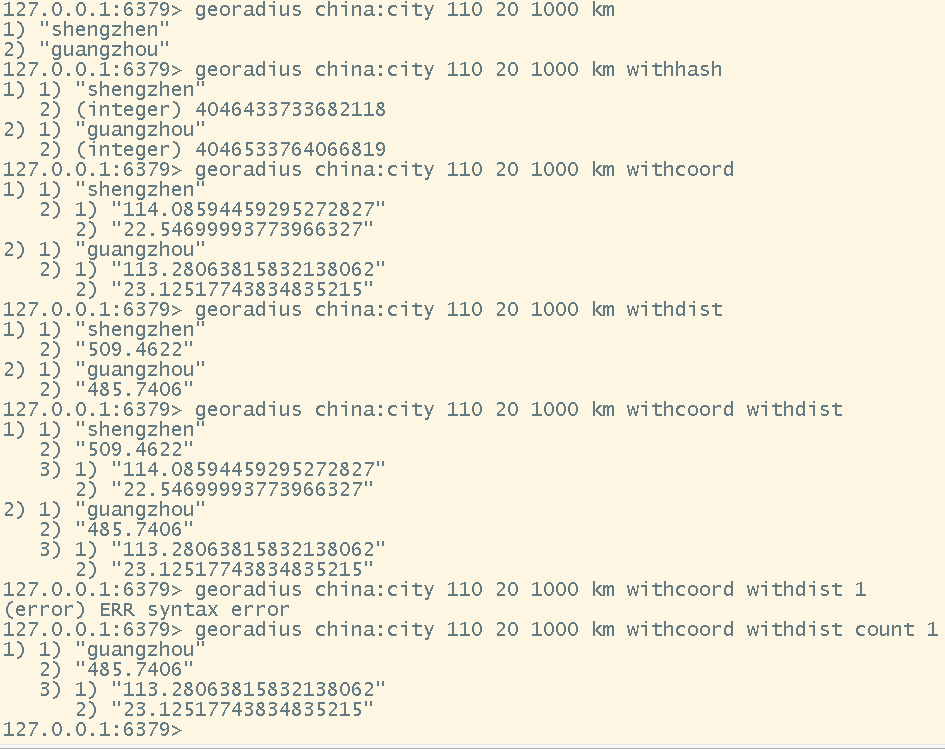
- 通过当前已存入的地点找出该地点周围指定范围内的其他地点

- 获取一个或多个位置元素的11个字符的geohash字符串

- geo原理
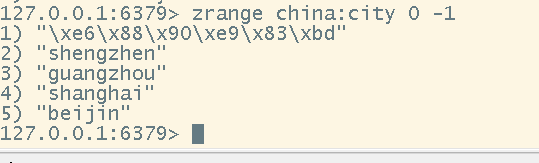
hyperloglogs(基数)
redis hyperloglogs是基数统计算法
网页的uv(一个人访问一个网站多次,都是算作一个人)
传统的方法:set保存用户的id,然后就可以统计set中的元素数量作为标准判断!这个方法如果保存大量的用户id,就会比较麻烦,我们的目的是计数,而不是保存用户id
hyperloglogs有点,占用内存是固定的,2^64的存储数据(不同元素的基数),只需要使用12kb内存。但是统计的数据大概有0.81%的错误率,对于正常统计来说,可以忽略不计。
# 添加基数元素
pfadd <key> <element> [<element>......]
# 统计基数元素数量
pfcount <key>
# 合并多个基数集合
pfmerge <new key> <key1> <key2> [<keyN>......]

如果运行容错,那么就可以选择使用hyperloglogs。如果不允许容错,就是用set或者其他不会出现错误率的方法
bitmaps(位图)
这个存储的是两个状态的值,只有0和1这种区别的状态值
bitmap,位图,即是使用bit。 redis字符串是一个字节序列。
1 Byte = 8 bit

# 插入数据,设置值
setbit <key> <offset> <value>
# 获取某一个offset的值
getbit <key> <offset>
# 统计选择的那一部分offset的和
bitcount <key> [start end]
注意:redis的setbit设置或清除的是bit位置,而bitcount计算的是byte位置。

上图之所以会出现不管end是多少,返回的结果都是3的原因就是当前的数据均存放在一个byte中,所以当前统计的也只有这一个byte的所有为1的数量
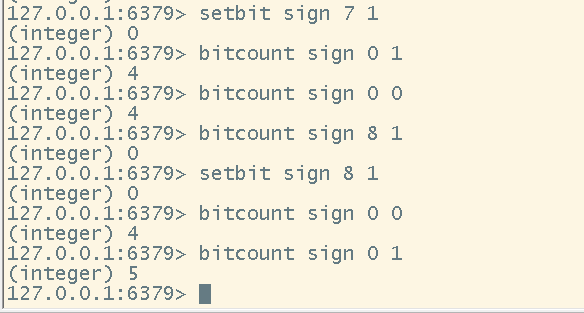
在后面的下标为7和8的地方加上一个1之后,我们可以看见查询变化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号