几何建模与处理之二 数据拟合(2)
几何建模与处理之二 数据拟合(2)
回顾:学习了函数、映射、变换等数学上的基础概念和知识,数据拟合的三步曲方法论,四种拟合方法,继续学习函数拟合问题。
函数拟合
输入:一些观察(采用)点\(\lbrace x_i,y_i\rbrace_{i=0}^n\)
输出:拟合数据点的函数\(y=f(x)\),并用于预测
拟合函数的“好坏”
分段线性插值函数\(y=f_1(x)\)
- 数据误差为0
- 函数性质不好:只有C0连续,不光滑(数值计算)
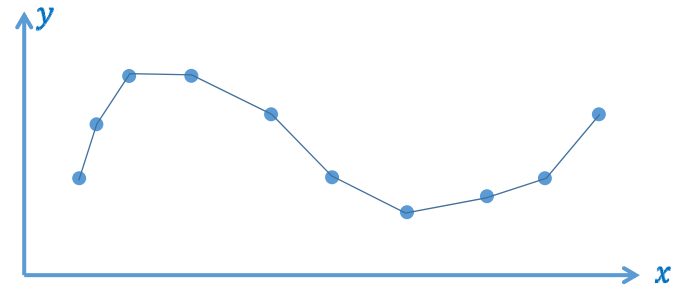
光滑插值函数\(y=f_2(x)\)
- 数据误差为0
- 可能被“差数据”(噪声、outliers)带歪,导致函数性质不好、预测不可靠
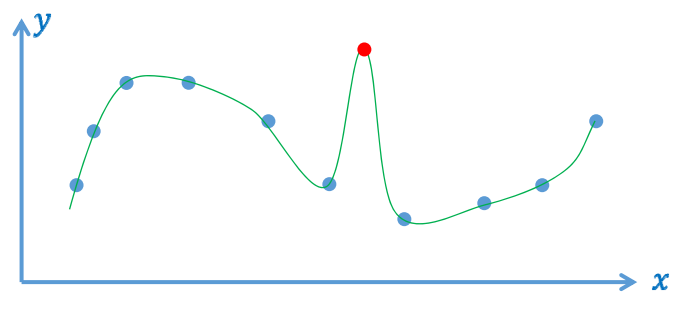
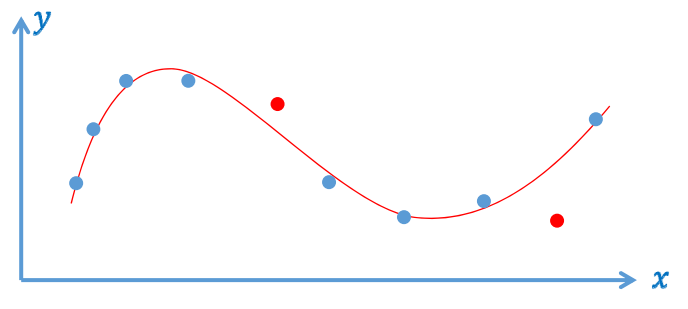
逼近拟合函数\(y=f_3(x)\)
- 数据误差不为0,但足够小
多项式插值
多项式插值定理:若\(x_i\)两两不同,则对于任意给定的\(y_i\),存在唯一的次数至多是
n次的多项式\(p_n\),使得\(P_n(x_i)=y_i,i=0,\dots,n\)。
技巧1:构造插值问题的通用解
寻找一组次数为n的多项式基函数\(l_i\)使得
插值问题的解为:
计算多项式\(l_i(x)\):
最终多项式基函数(拉格朗日多项式)为
技巧2:更方便的求解表达
Newton插值:具有相同“导数”(差商)的多项式 构造(n阶Taylor展开)
定义:
一阶差商:
k阶差商:
Newton 插值多项式:
多项式插值存在的问题
-
系统矩阵稠密
-
依赖于基函数选取,矩阵可能病态,导致难以求解(求逆)
病态问题:
-
输入数据的细微变化导致输出(解)的剧烈变化

-
将线性方程看成直线(超平面)当系统病态时,直线变为近似平行,求解(即直线求交)变得困难、不精确
矩阵条件数:
- 等于最大特征值和最小特征值之间比例
- 条件数大意味着基元之间有太多相关性
对于等距分布的数据点\(x_i\),范德蒙矩阵的条件数随着数据点数n呈指数级增长(多项式的最高次数为n -1)

原因:
幂(单项式)函数基:幂函数之间差别随着次数增加而减小;不同幂函数之间唯一差别为增长速度(\(x^i\)比\(x^{x-i}\)增长块)

趋势:
好的基函数一般需要系数交替;互相抵消问题
解决方法:
使用正交多项式基( Gram‐Schmidt正交化 )
多项式插值的结果:
- 振荡(龙格Runge)现象;
- 对插值点数高度敏感性
多项式逼近
使用逼近型的好处:
- 数据点含噪声、outliers等
- 更紧凑的表达
- 计算简单、更稳定
最小二乘逼近
法方程 最小解满足
(最小化二次目标函数:\(x^TAx+b^T+c\),充分必要条件:\(2Ax=-b\))
函数空间及基函数
Bernstein多项式做逼近
伯尔斯坦Bernstein给出了构造性证明。
对[0,1]区间上任意连续函数\(f(x)\)和任意正整数\(n\),以下不等式对所有\(x\in [0,1]\)成立
\(b_{n,j}\)为Bernstein多项式。

Bernstein基函数的良好性质:非常好的几何意义!
-
正性、权性(和为1)
-
凸包性
-
变差缩减性
-
递归线性求解方法
-
细分性
-
...
(在Bezier曲线和B样条篇更详细地学习)
RBF函数插值/逼近
Gauss函数
-
两个参数:均值\(\mu\),方差\(\sigma\)
\(g_{\mu, \sigma}(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\)
-
几何意义:
- 均值\(\mu\):位置
- 方差\(\sigma\):支集宽度
-
不同均值和方差的Gauss函数都线性无关

RBF函数拟合
RBF函数:
均值\(\mu\),方差\(\sigma\)对函数的形状影响较大,考虑同时对均值\(\mu\),方差\(\sigma\)优化。
一般Gauss函数表达为标准Gauss函数的形式:
则RBF函数表达为:
用标准表达后,基函数是由一个基本函数通过平移和伸缩变换而来的。n足够大,a和b足够多(随机),所产生的函数空间可以逼近所有函数。
将Gauss函数看成网络:
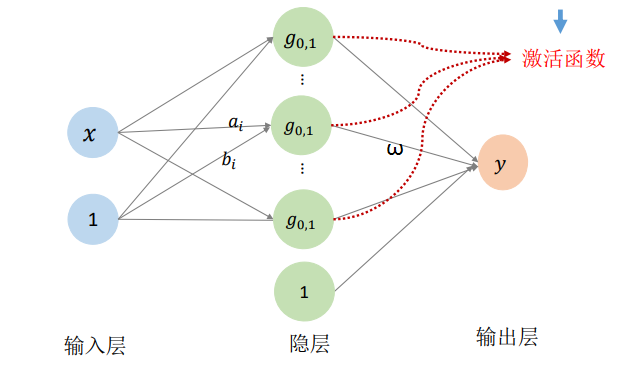
神经元:
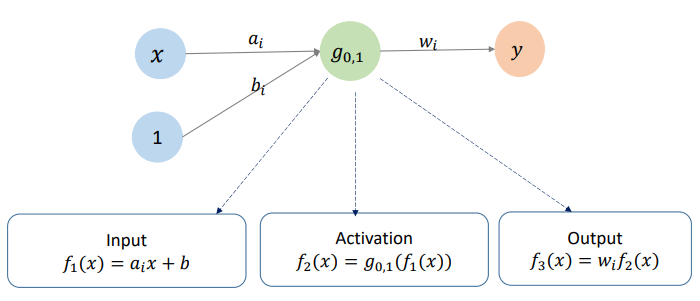
RBF神经网络
- 高维情形:RBF(Radial Basis Function),径向基函数
- 一种特殊的BP网络,优化:BP算法
- 核函数思想
- Gauss函数的特性:拟局部性
启发:由一个简单的函数通过(仿射)变换构造出一组基函数,张成一个函数空间
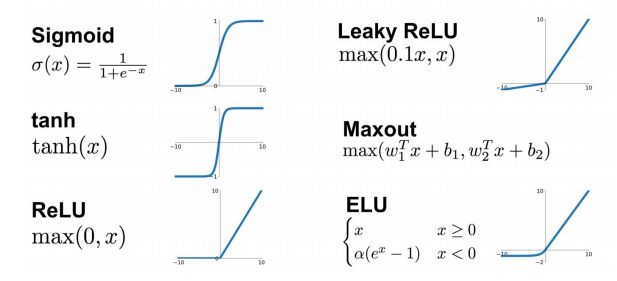
几种常用的激活函数:
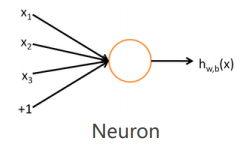
高维情形:多元函数
变量的多个分量的线性组合:
单隐层神经网络函数:
多层神经网络:多重复合的函数
线性函数和非线性函数的多重复合:
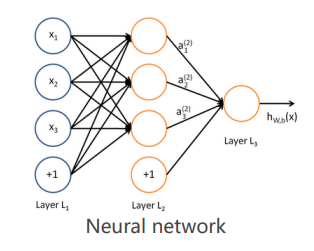
用神经网络函数来拟合数据
理论支撑:万能逼近定理:自由度足够多
问题建模
- 理解问题、问题分解(多个映射级联) …
找哪个?
- 损失函数、各种Penalty、正则项 …
到哪找?
- 神经网络函数、网络简化 …
怎么找?
-
优化方法(BP方法)
-
初始值、参数 …
调参:有耐心、有直觉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号