渗透测试思路 - 工具篇
渗透测试思路
Another:影子
(主要记录一下平时渗透的一些小流程和一些小经验)
工具篇
前言
工欲善其事,必先利其器
一个好的工具能够省下很多时间,所以一个工具集合,可以快速的完成渗透测试
真实IP
Nslookup
自带工具
nslookup 获取到的ip有多条时,就可以判断是否为CDN,多半为假IP
解析记录
历史解析记录中可能会存在网站真实IP
在线工具
http://toolbar.netcraft.com/
http://viewdns.info/
邮箱
通过订阅网站订阅邮件功能,让网站给自己发送邮件,通过查看邮件源代码来获取网站真实IP
信息泄露
有些网站都会有网站信息测试页面没有删除
例如:PHPinfo.php
不要觉得不会存在phpinfo这种文件,某某po主站上似乎就存在phpinfo文件,在某天大佬群中看到的,还吃了一次瓜,真香!
来获取网站真实IP地址
Github上面的信息泄露等
网络空间
在线工具:
https://www.shodan.io/
https://fofa.so/
Ping
多地Ping,企业使用CDN的时候可能只对国内的进行CDN,可以尝试全球Ping
在线工具推荐:站长工具
子域名爆破
Layer子域名挖掘机4.2纪念版
使用过的人应该都知道这个工具的强大,爆破速度快,准确率高,内置字典丰富

subDomainsBrute
Github: https://github.com/lijiejie/subDomainsBrute/
扫描速度快,多线程高并发,
笔者在使用的时候有个小bug,域名在使用泛解析的时候,爆破就会出现问题,可能是本地环境的问题,最后需要将爆破的结构手动进行title获取然后手动筛选
当时写的一个title的小脚本
有个BUG,没有自动识别https还是http的功能,大佬可以加一下这个功能,然后让小影子看看,嘿嘿嘿
#coding:utf-8
import requests
import os
import sys
import getopt
import re
reload(sys)
sys.setdefaultencoding('GBK')
def title(url):
file = open(url)
headers = {
'Host': 'www.starsnowsec.com',
'Connection': 'close',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': '',
}
try:
for line in file:
line = line.strip('\n')
url = 'https://' + line
r = requests.get(url,headers=headers)
if r.status_code == 200:
title = re.findall('<title>(.+)</title>',r.text)
result = '[*]URL:' + str(url) + ' +title:' + str(title[0])
f = open('result.txt','a+')
f.write(result+'\n')
f.close()
print result
pass # do something
# with open(url, "r") as f: #打开文件
# data = f.read() #读取文件
# print data
# print "1"
else:
print "-" * 40
print r.text
pass
except:
print "error!"
pass
def main():
# 读取命令行选项,若没有该选项则显示用法
try:
# opts:一个列表,列表的每个元素为键值对
# args:其实就是sys.argv[1:]
# sys.argv[1:]:只处理第二个及以后的参数
# "ts:h":选项的简写,有冒号的表示后面必须接这个选项的值(如 -s hello)
# ["help", "test1", "say"] :当然也可以详细地写出来,不过要两条横杠(--)
opts, args = getopt.getopt(sys.argv[1:], "u:h",["url", "help"])
# print opts
# 具体处理命令行参数
for o,v in opts:
if o in ("-h","--help"):
usage()
elif o in ("-u", "--url"):
title(v)
# 经测试--是不能带后继值的
#
except getopt.GetoptError as err:
# print str(err)
print 'Error!'
main()
R3con1z3r
# 安装
pip install r3con1z3r
# 使用
r3con1z3r -d domain.com
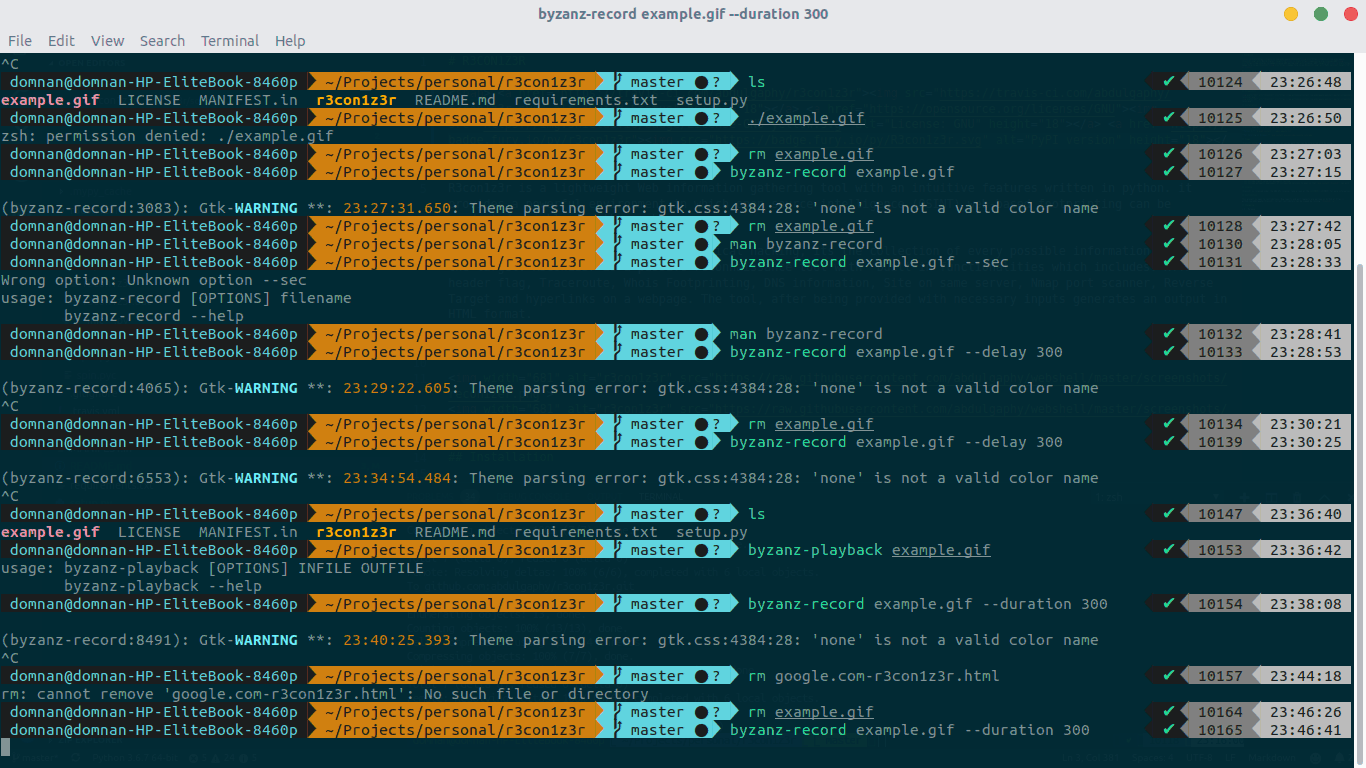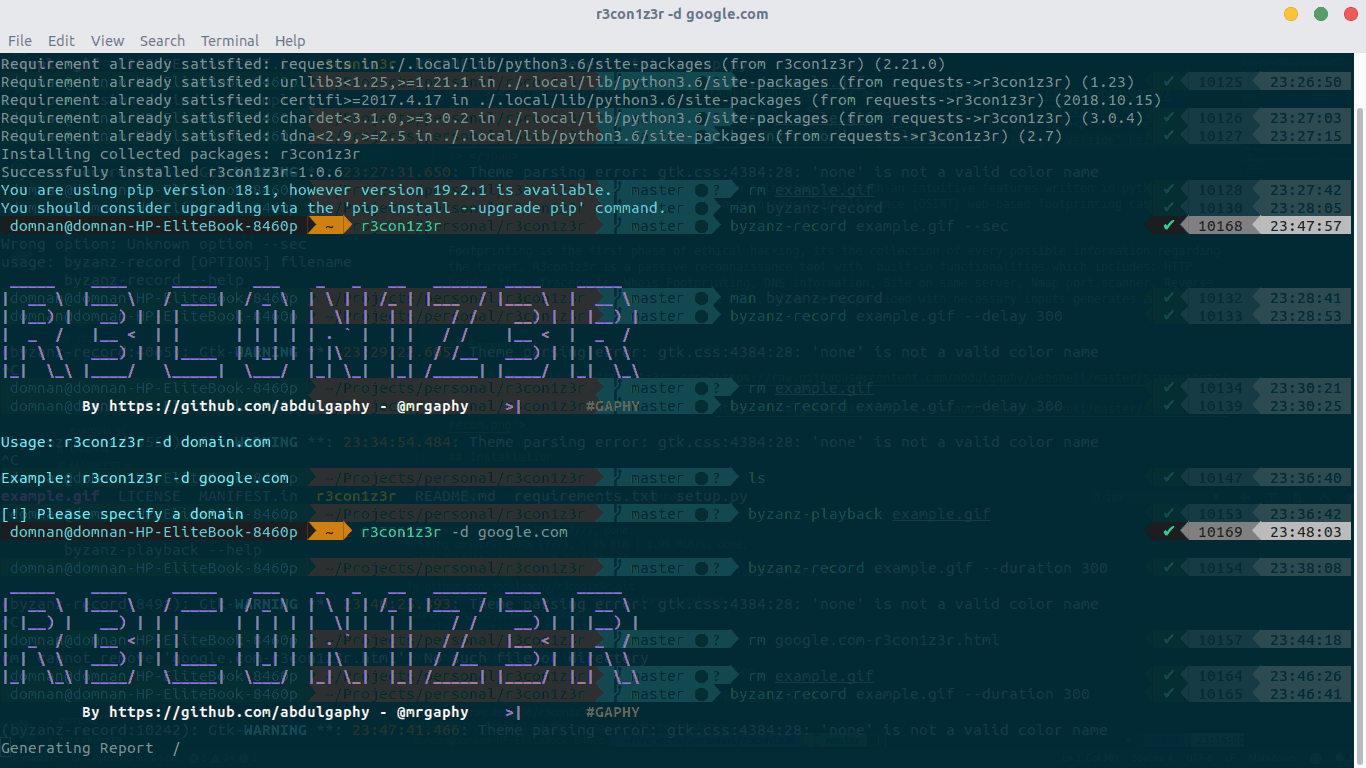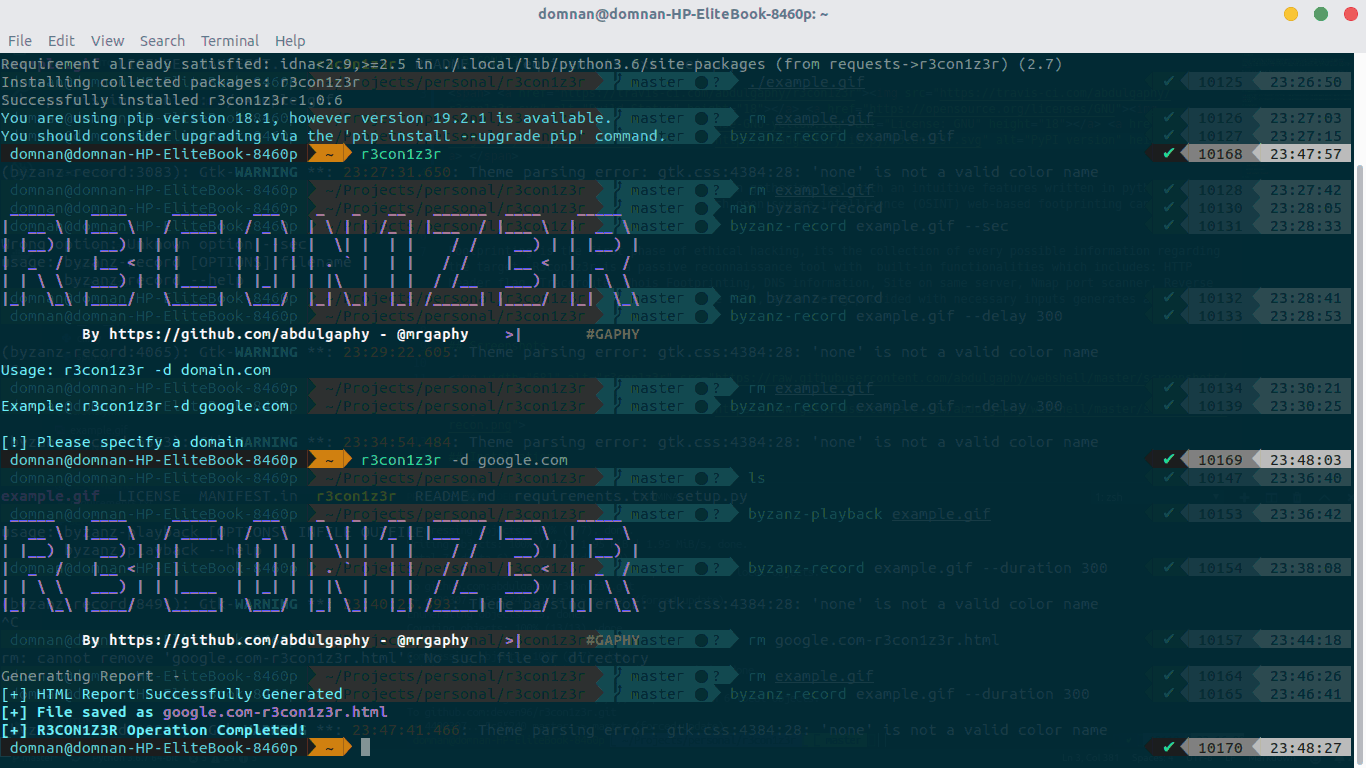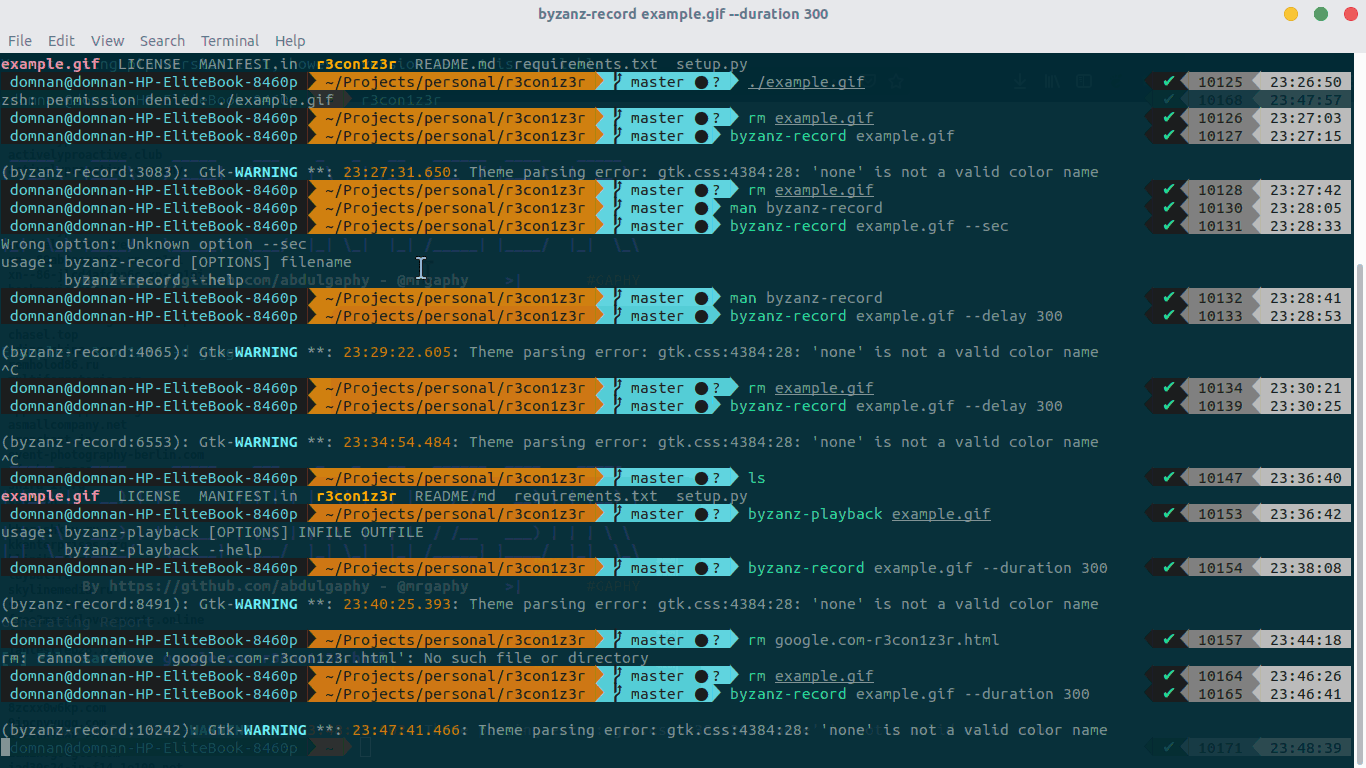 使用结果
使用结果



r3con1z3r 会对HTTP Header,Route,Whois,DNS,IP,端口,内链爬取进行收集
优点:使用简单,界面简洁,准确率高
缺点:笔者在使用的时候,速度过慢,还要挂代理
OneForAll
Github
git clone https://github.com/shmilylty/OneForAll.git
Gitee
git clone https://gitee.com/shmilylty/OneForAll.git
👍功能特性
- 收集能力强大,详细模块请阅读收集模块说明。
- 利用证书透明度收集子域(目前有6个模块:
censys_api,certspotter,crtsh,entrust,google,spyse_api) - 常规检查收集子域(目前有4个模块:域传送漏洞利用
axfr,检查跨域策略文件cdx,检查HTTPS证书cert,检查内容安全策略csp,检查robots文件robots,检查sitemap文件sitemap,利用NSEC记录遍历DNS域dnssec,后续会添加NSEC3记录等模块) - 利用网上爬虫档案收集子域(目前有2个模块:
archivecrawl,commoncrawl,此模块还在调试,该模块还有待添加和完善) - 利用DNS数据集收集子域(目前有24个模块:
binaryedge_api,bufferover,cebaidu,chinaz,chinaz_api,circl_api,cloudflare,dnsdb_api,dnsdumpster,hackertarget,ip138,ipv4info_api,netcraft,passivedns_api,ptrarchive,qianxun,rapiddns,riddler,robtex,securitytrails_api,sitedossier,threatcrowd,wzpc,ximcx) - 利用DNS查询收集子域(目前有5个模块:通过枚举常见的SRV记录并做查询来收集子域
srv,以及通过查询域名的DNS记录中的MX,NS,SOA,TXT记录来收集子域) - 利用威胁情报平台数据收集子域(目前有6个模块:
alienvault,riskiq_api,threatbook_api,threatminer,virustotal,virustotal_api该模块还有待添加和完善) - 利用搜索引擎发现子域(目前有18个模块:
ask,baidu,bing,bing_api,duckduckgo,exalead,fofa_api,gitee,github,github_api,google,google_api,shodan_api,so,sogou,yahoo,yandex,zoomeye_api),在搜索模块中除特殊搜索引擎,通用的搜索引擎都支持自动排除搜索,全量搜索,递归搜索。
- 利用证书透明度收集子域(目前有6个模块:
- 支持子域爆破,该模块有常规的字典爆破,也有自定义的fuzz模式,支持批量爆破和递归爆破,自动判断泛解析并处理。
- 支持子域验证,默认开启子域验证,自动解析子域DNS,自动请求子域获取title和banner,并综合判断子域存活情况。
- 支持子域接管,默认开启子域接管风险检查,支持子域自动接管(目前只有Github,有待完善),支持批量检查。
- 处理功能强大,发现的子域结果支持自动去除,自动DNS解析,HTTP请求探测,自动筛选出有效子域,拓展子域的Banner信息,最终支持的导出格式有
rst,csv,tsv,json,yaml,html,xls,xlsx,dbf,latex,ods。 - 速度极快,收集模块使用多线程调用,爆破模块使用massdns,DNS解析速度每秒可解析350000以上个域名,子域验证中DNS解析和HTTP请求使用异步多协程,多线程检查子域接管风险。
- 体验良好,各模块都有进度条,异步保存各模块结果。
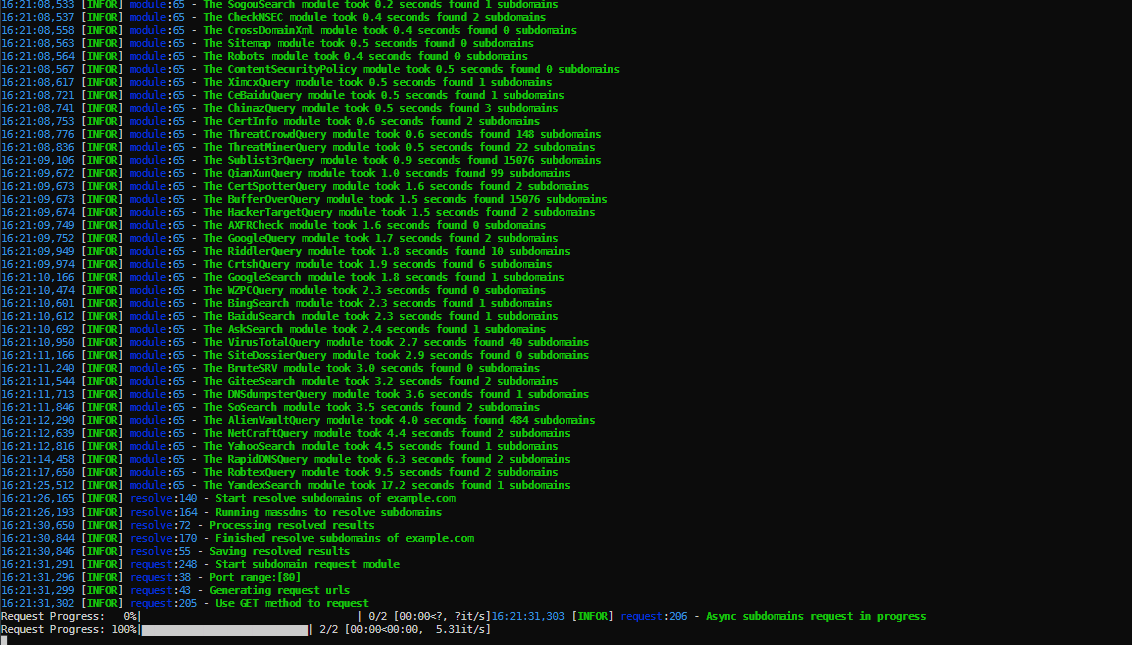
在线工具
https://phpinfo.me/domain/ 子域名爆破
目录扫描
御剑
说起来目录扫描,绝大部分人都是知道御剑的,并且也是使用过的,不多说什么,推荐
Tips: 可以尝试多收集几款不一样的御剑,不同的御剑的结果也是不一样的(相同情况下)
笔者这里是有四种

WebPathBrute
https://github.com/7kbstorm/7kbscan-WebPathBrute
7kb大佬的WebPathBrute
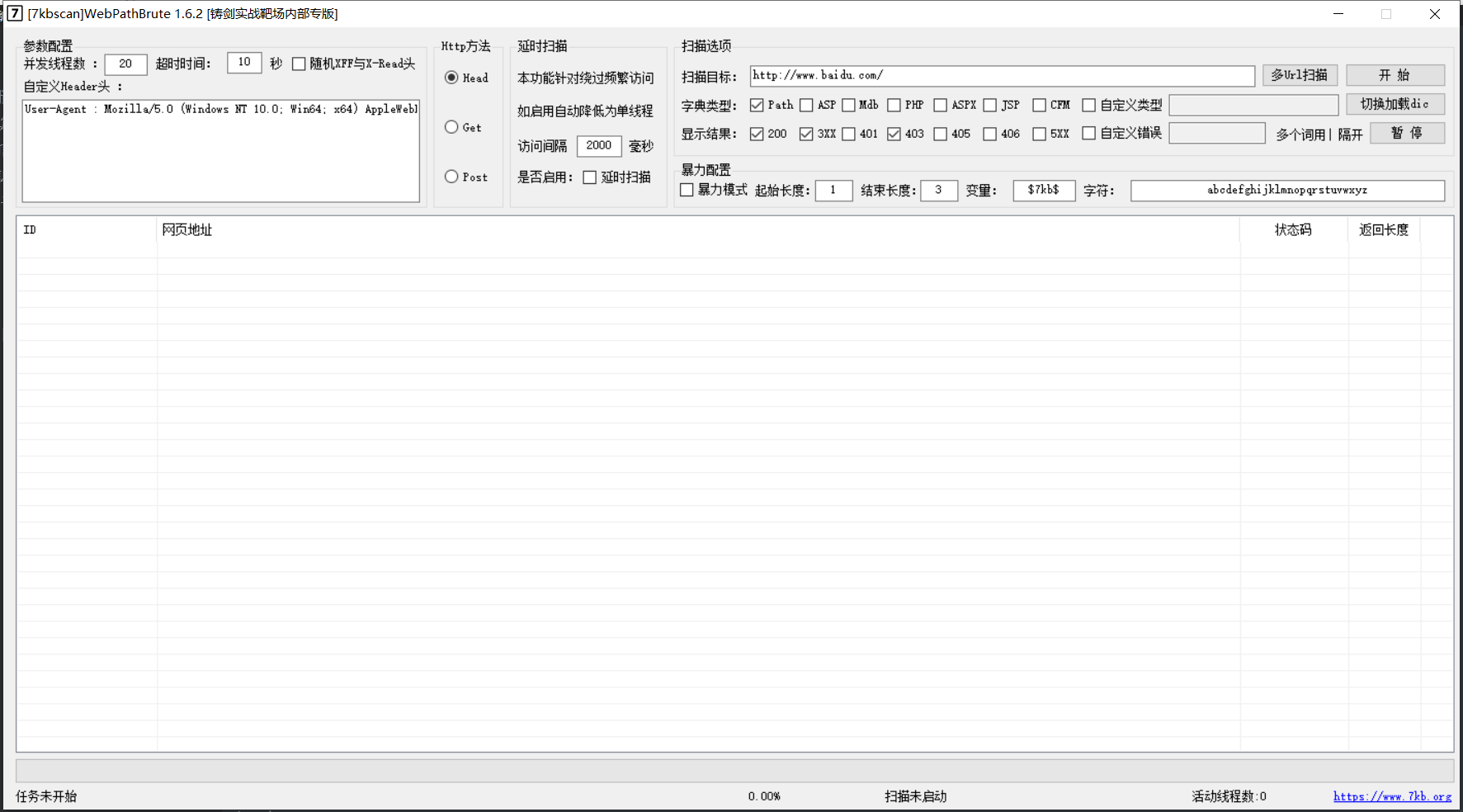
界面简洁,功能强大,
以下是悬剑中WebPathBrute的工具介绍原话:
一、先说说并发线程数吧,虽然默认是20 但是加大也无妨看你自己的各个参数设置和机器网络等配置了。
二、超时时间自己视情况而定 也不必多介绍了。
三、这个随机xff头和xr头 套用百度上一段话 能懂得自然懂得 不懂得也无所谓 很少能碰见需要用到的这种情况 勾选后每次访问都会随机生成这两个IP值 如果线程开的大 可能比较耗cpu。
1、X-Forwarded-For是用于记录代理信息的,每经过一级代理X-Forwarded-For是用于记录代理信息的,每经过一级代理(匿名代理除外),代理服务器都会把这次请求的来源IP追加在X-Forwarded-For中,来自4.4.4.4的一个请求,header包含这样一行 X-Forwarded-For: 1.1.1.1, 2.2.2.2, 3.3.3.3 代表 请求由1.1.1.1发出,经过三层代理,第一层是2.2.2.2,第二层是3.3.3.3,而本次请求的来源IP4.4.4.4是第三层代理
2、X-Real-IP,一般只记录真实发出请求的客户端IP,上面的例子,如果配置了X-Read-IP,将会是X-Real-IP: 1.1.1.1
四、自定义User Agent头这个不必解释了吧。
五、自定义错误页面关键字 这个针对修改了错误页面的网站的功能 大家常用 所以我也不在这里多啰嗦了。
六、http访问方法 HEAD GET POST 三种方式,head请求扫描速度最快 但是准确率不如以下两种,post请求是为某些情况绕过waf使用的。
七、延时扫描功能 勾选效果是: 单线程扫描、默认每隔2秒访问一次。适用于某些存在CCwaf的网站 免于频繁访问被认为是CC攻击。(默认两秒已经能过云锁以及安全狗的默认CC设置)
八、扫描类型 分别对应同目录下多个txt文件 自定义对应的文件是custom.txt,后缀格式为".xxx",如不需要后缀可以不填 直接将字典内容修改为"111.svn"此类即可。
九、状态码我也不多解释了
十、双击表格内某行即调用系统默认浏览器打开当前行Url 右键可复制Url内容。
十一 批量导入的Url与填写的Url都需要以 http:// https://开头的格式。
Dirsearch
轻量级,功能强大,速度快
使用 python3.x 运行
Install
git clone https://github.com/maurosoria/dirsearch.git
cd dirsearch
python3 dirsearch.py -u <URL> -e <EXTENSION>
Usage: dirsearch.py [-u|--url] target [-e|--extensions] extensions [options]
更多使用方法
dirsearch.py -h, --help
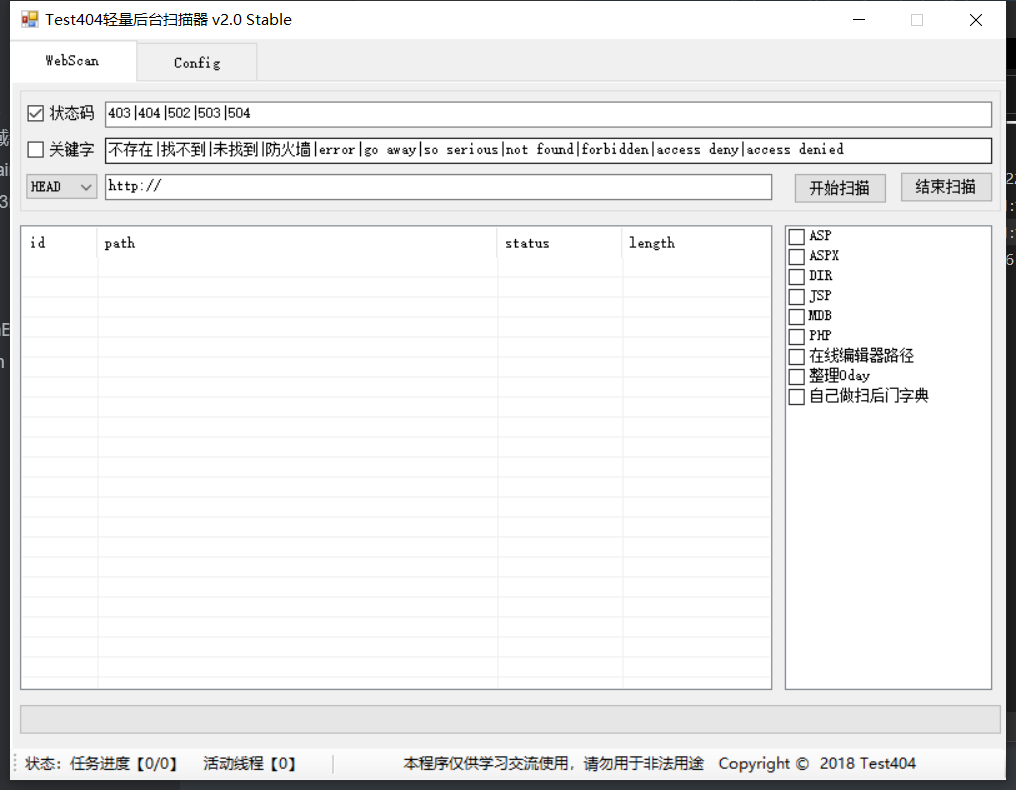
Test404
轻量级,使用方便
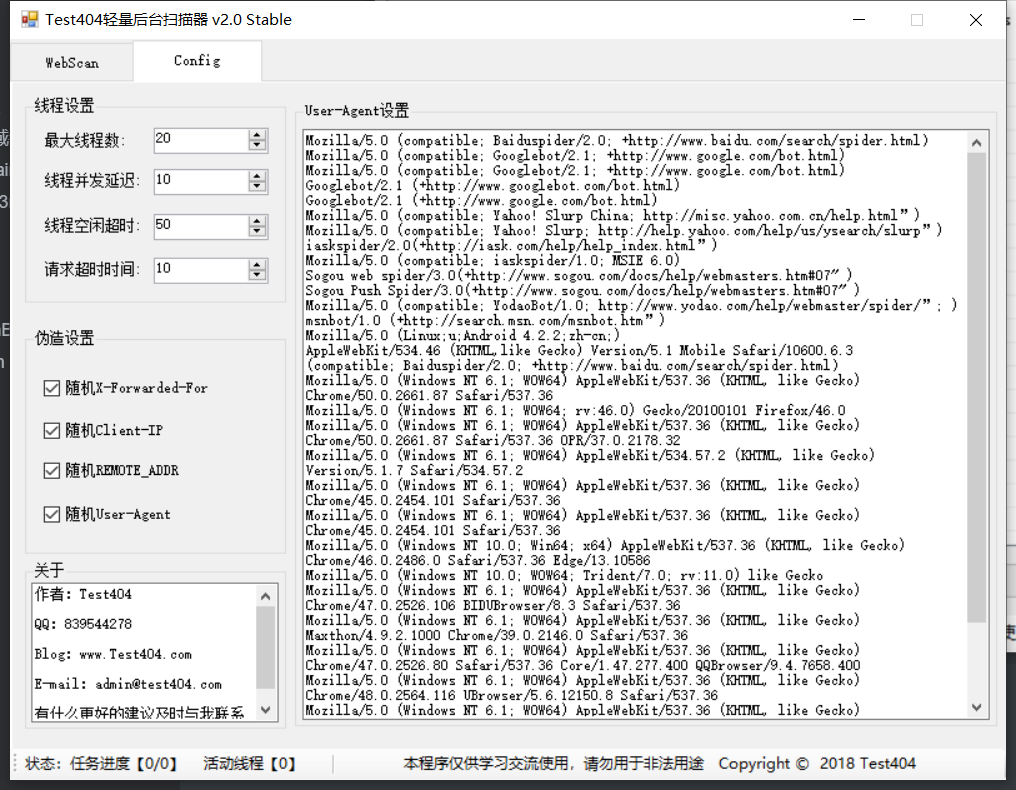
端口扫描
Nmap
不多说
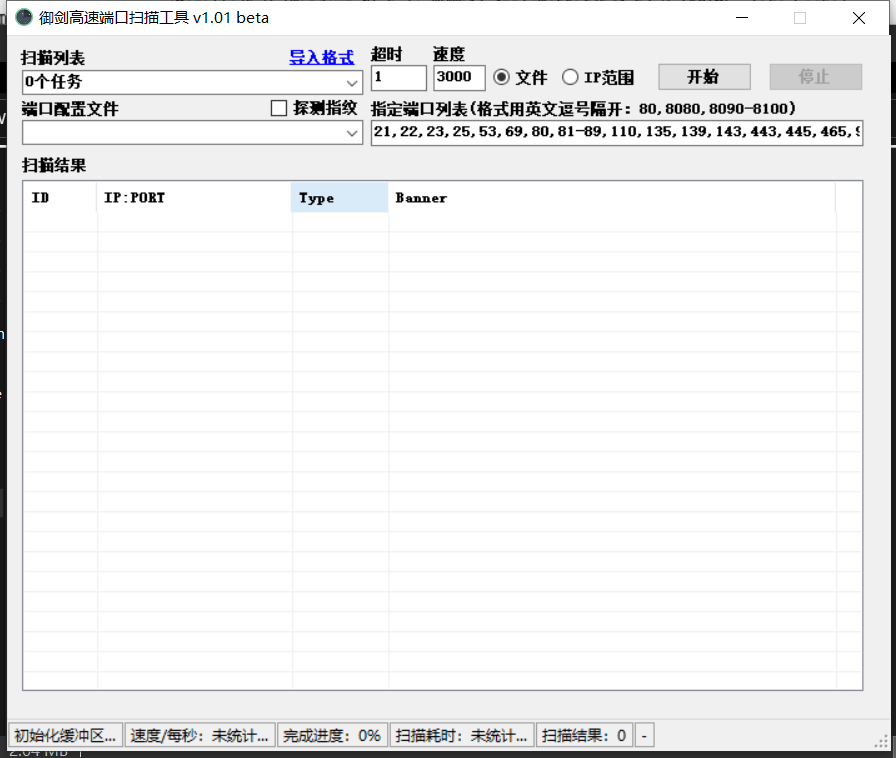
御剑高速端口扫描工具
配置简单,扫描快速,界面简洁
Masscan
速度非常快(取决于网络还有电脑性能)
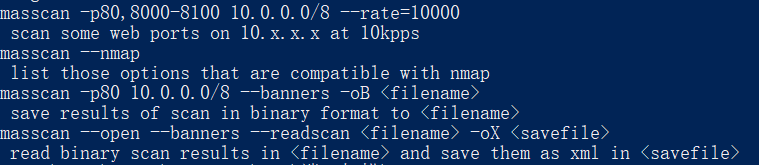
应该都听说过Masscan,笔者就不多说了
综合扫描
Goby
界面是我用过中UI最好看的一个
这界面,爱了爱了~~
Xray
这个也不用我多说,挂上代理,点到哪里,挖到那里
用了都说真香
WVS
报告简洁,功能强大
生成的报告如下
Nessus
目前全世界最多人使用的系统漏洞扫描与分析软件
也不用多说
AWVS
这个也不用多说
权限管理
AntSword
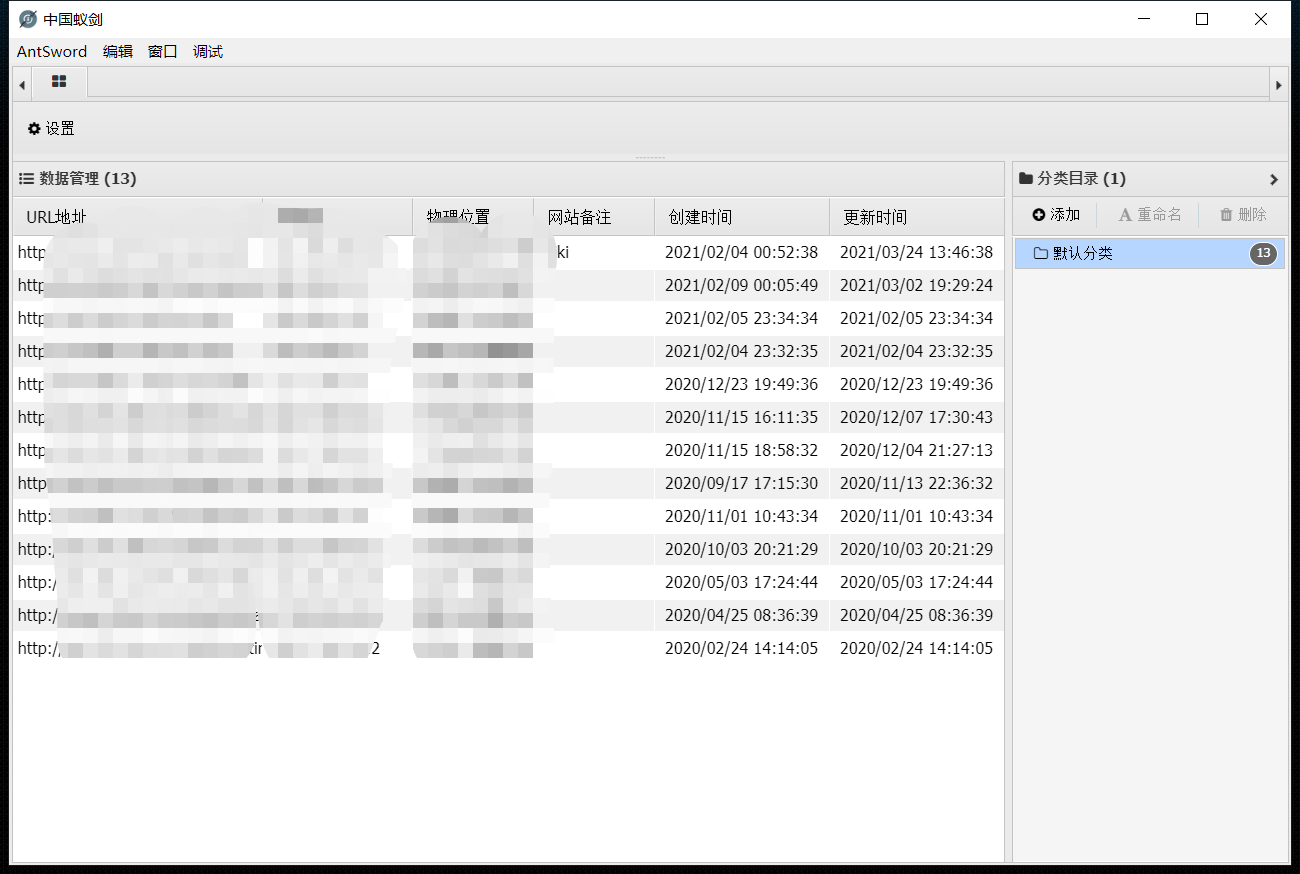
还有可下载的插件市场
冰蝎
天蝎
笔者还没有用过,不过是悬剑里推荐的,应该不错!
SQL注入
笔者第一开始时候用的工具都是流光,明小子啊D一类的(脚本小子),然后那个时候都是带后门的,把电脑搞得一团糟,想想就想笑,哈哈哈哈
小的时候我垃圾(脚本小子),本来觉得长大了就厉害了,没想到越长大越废物(还是脚本小子),呜呜呜呜呜~~~
Sqlmap
不必多说,功能强大,笔者最喜欢一把梭
远控
NC
nc被称为瑞士军刀,强大之处不用多说
CobaltStrike
这种东西也不用多说,就说一个CS后渗透插件
Github: https://github.com/DeEpinGh0st/Erebus
抓包改包
BurpSuite
学安全没有个bp感觉都说不出去 基本都是破解版 哈哈哈哈
Fiddler
和burpsuite一样,抓取数据包
笔者更喜欢使用BurpSuite一点,Fiddler没有过多地使用过
Wireshark
不用笔者多说,Wireshark,我愿称你为数据分析第一
RawCap
非常轻巧的一款工具

不过笔者并没有用过几次
追求轻便的大佬可以尝试一下
批量测试
百度URL关键字网址提取
# -*- coding: UTF-8 -*-
import requests
import re
from bs4 import BeautifulSoup as bs
def main():
for i in range(0,100,10):
expp=("/")
# print(i)
url='https://www.baidu.com/s?wd=inurl admin.php&pn=%s'%(str(i))
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
r=requests.get(url=url,headers=headers)
soup=bs(r.content,'lxml')
urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})
for url in urls:
r_get_url=requests.get(url=url['href'],headers=headers,timeout=4)
if r_get_url.status_code==200:
url_para= r_get_url.url
url_index_tmp=url_para.split('/')
url_index=url_index_tmp[0]+'//'+url_index_tmp[2]
with open('cs.txt') as f:
if url_index not in f.read():#这里是一个去重的判断,判断网址是否已经在文本中,如果不存在则打开txt并写入我们拼接的exp链接。
print(url_index)
f2=open("cs.txt",'a+')
f2.write(url_index+expp+'\n')
f2.close()
if __name__ == '__main__':
f2=open('cs.txt','w')
f2.close()
main()
有需要可以自行在Github'上面搜索,或者自己写个小脚本
(Tips:别忘了结果去重!)
采集收集
Fofa采集
ZoomEye采集
工具在github上面都是有的,笔者也不多bb
浏览器插件
Hackbar
好用程度不用多说
个人比较喜欢这个版本的火狐+这个hackbar
Wappalyzer
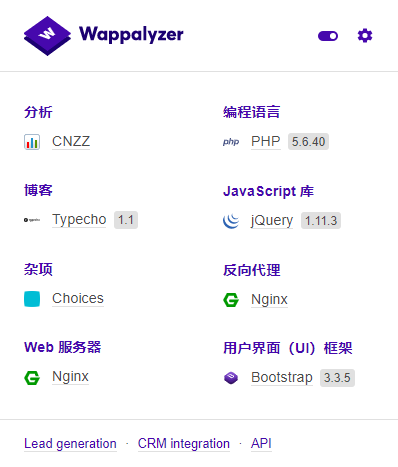
很清楚,显示了前端的那些库,语言,框架,版本等
FoxyProxy
代理工具
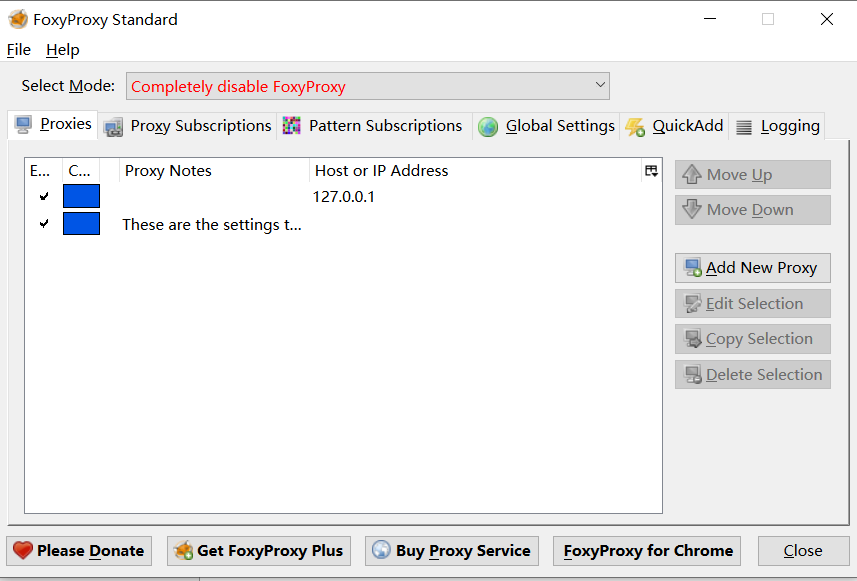
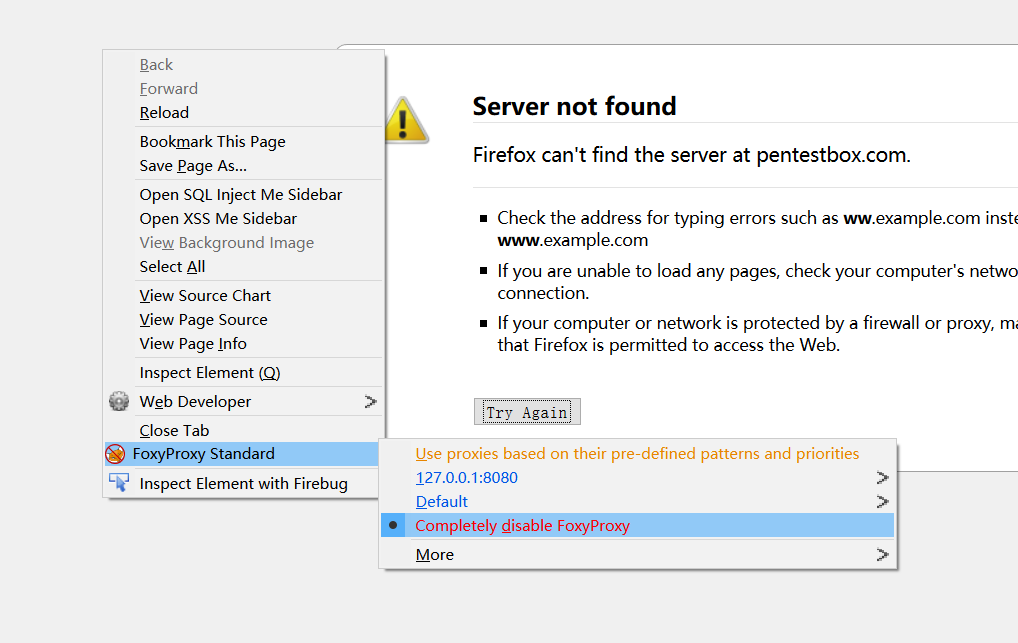
右键直接换代理,方便Burpsuite来回切换
Site Spider
前端小爬虫,用来爬取内链和外链链接
FireBug
不用多说
后言
我用的火狐是 Pentest Box 里面的
www.pentestbox.com
里面携带的插件挺齐全
有兴趣的可以尝试下载玩玩,有两个版本,一个是带metasploit,一个不带,可以随意选择
里面的环境还有工具基本常用的都已经下载好了,也有更新功能等
下载功能等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号