论文阅读-Talking Face Generation by Adversarially Disentangled Audio-Visual Representation
论文阅读-Talking Face Generation by Adversarially Disentangled Audio-Visual Representation

论文链接: https://www.aaai.org/ojs/index.php/AAAI/article/view/4967
概述
作者提出, 现有的talking face generation要么针对特定的主题构建人脸模型, 要么建模嘴唇变化和演讲之间的关系. 而本文综合了这两个方面.
(实际上看introduction怎么看怎么有种作者原来是做自动唇读联想的, 把论文改了改再发的感觉)
总之作者提出, 'One important reasonis that the subject-related and speech-related information arecoupled together such that the talking faces are difficult tolearn in a purely data-driven manner.' 意思是与主题(也就是人脸)相关的信息和预语音相关的信息是被耦合的, 这样导致模型很难从数据里面学到人脸的生成. 这导致了目前的人脸生成工作往往缺乏泛化(特定的3D人脸模型), 或者出现模糊和序列无关(深度学习模型).
既然有这个耦合的靶子, 作者的目的也就明显了, 解耦. 类似下图的形式:
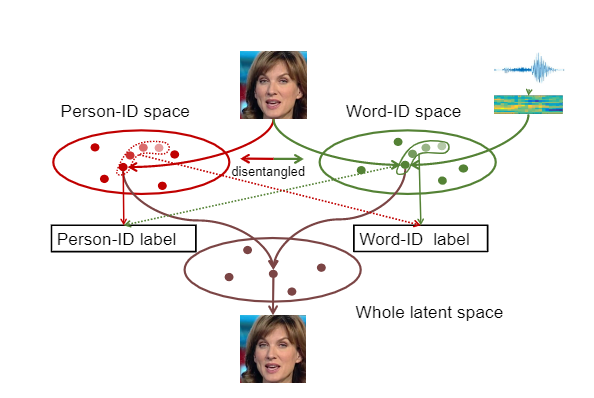
说话的人脸被分解为person和word两个特征, 作者认为这样解耦了之后模型就能以数据驱动的方法学到怎么生成人脸了. 当然如何解耦是个大问题. 作者做法的框架是利用唇读模型, 从原始的talking face视频中获取一个联合embedding空间, 这个空间里面人脸和其对应的语音特征是嵌入到一起的. 接着使用对抗学习解耦其中的人脸特征和语音特征.
作者的贡献体现在三个方面:
1)通过唇读模型学习联合嵌入空间, 实验证明这种空间提升了唇读的baseline结果*(所以这工作本来就是干的这个吧, talking face generation还做了唇读实验顺便还提升了baseline???)
2)使用对抗学习解耦人脸和语音信息
3)一个能生成高质量的, 任意身份talking face的端到端模型.
方法
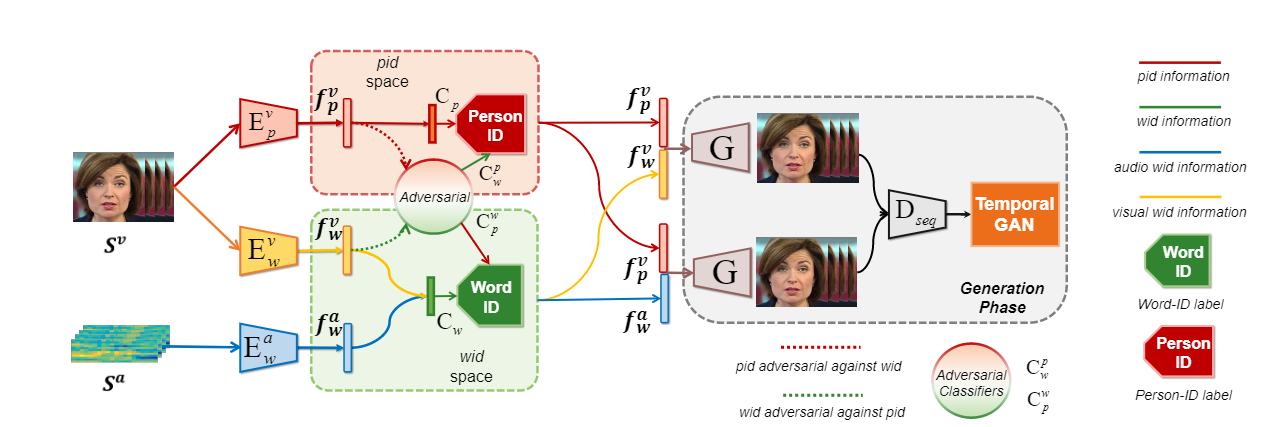
模型架构如图. 输入包含了源视频和源音频.
一个的encoder-decoder + adversarial的模型. 三个encoder完成了所谓的解耦操作.
特征表示学习
具体来讲, 三个encoder分别为 Video to Word-ID, Audio to Word-ID, Vider to Person-ID. 分别从视频中抽取人脸特征\(f_p^v\)和语音特征\(f_w^v\), 音频中抽取音频特征\(f_w^a\). 其中, 限制\(f_w^v\)和\(f_w^a\)两个音频特征分布相似(也就是在同一隐空间). 这样就能保证 \(G\left(f_{p}^{v}, f_{w}^{v}\right) \simeq\) \(G\left(f_{p}^{v}, f_{w}^{a}\right)\) --- 保证生成的图像更加逼真, DeepFakes的思路. 限制特征相似的方法如图:
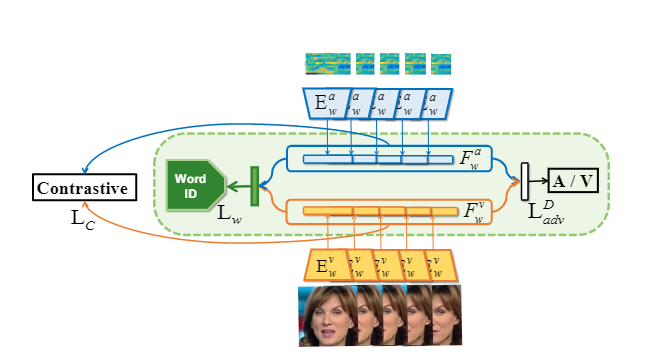
作者使用了一个共享分类器, 一般来说应该用不同的分类器识别源音频和源视频的特征. 但作者使用共享分类器, 使它们更加接近. 这在相关研究中是可行的, 这个过程称为\(L_w\). 其次作者计算了一个限制loss\(L_C\), 使接近的sample更接近, 如果两个sample的label相同, 则设\(l_{m=n} = 1\), 否则设为0.
loss函数:
其中\(d_{m n}=\left\|F_{w(m)}^{v}-F_{w(n)}^{a}\right\|_{2}\).
最后, 为了让视频和音频特征更相似, 作者还是用了domain adversarial training. 以增强共享分类器的分类能力.这个过程为\(L_{adv}^D\).
隐空间解耦对抗训练
Person-ID和Word-ID是从统一视频源获得的, 作者希望让两种特征互相解耦. 解耦方法使用对抗学习, 作者训练了一个分类器\(C_p^w\), 将\(f_p^v\)转化到Word-ID空间
对于\(f_p^v\)的对应特征处理方法相似.
(这块属实看的一头雾水, 以后补吧, 大概意思明白就完了)
任意talking face生成
\(G\left(f_{p}^{v}, f_{w}^{v}\right)\)和\(G\left(f_{p}^{v}, f_{w}^{a}\right)\) 是视频特征\(f_p^v\)和其他两个音频特征组合后生成的图像. 其中\(f_w^v\)来自源视频, 另一个来自源音频. 训练是比较标准的对抗学习, 两个loss:
上面是源视频和生成视频的距离, 下面是GAN的loss.两个loss相加就是总loss.
总结
实验就直接不看了, 这篇论文是我读起来比较难受的一篇了, 总感觉说的不是很清楚.
我个人理解是, 为了实现talking face generation, 作者搞出来三个特征, 源视频的人脸特征, 源视频的音频特征, 源音频的音频特征. 人脸特征是必须的, 它提供的是期望生成视频的表情和pose等信息, 而两个音频特征被映射到同一隐空间, 并可以分别生成video.
我们直觉上的talking face generation应该是匹配源音频的生成视频(以音频为主), 但作者的理解好像跟faceswap比较类似, 更倾向于生成换脸后的视频(以视频为主), 最后结果倒是挺相似的, 但总感觉哪里不对.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号