python机器学习——感知器
最近在看机器学习相关的书籍,顺便把每天阅读的部分写出来和大家分享,共同学习探讨一起进步!作为机器学习的第一篇博客,我准备从感知器开始,之后会慢慢更新其他内容。
在实现感知器算法前,我们需要先了解一下神经元(neuron)的工作原理,神经元有很多树突和一个轴突,树突(Dendrites)可以从其他神经元接收信息并将其带到细胞体(Cell nucleus),轴突(Axon)可以从细胞体发送信息到其他神经元。树突传递过来的信息在细胞体中进行计算处理后,如果结果超过某个阈值,轴突会传递信号到其他的神经元。人们通过认识神经元的工作过程,创造出了感知器学习算法。

感知器是Frank Rosenblatt在1975年就职于康奈尔实验室时所发明的一种人工神经网络,它被视为一种最简单形式的前馈神经网络,是一种二元线性分类器,不足在于不能处理线性不可分问题。
下图为三种不同情况,左图中的两类可以使用一条直线(即线性函数)分开,即线性可分;中间和右边由于不能使用线性函数分开,则为线性不可分。

我们直接来看一个实例,假设我们现在需要对花进行分类,数据集中有两种花朵,分别将其记为1和-1,我们需要根据数据集含有的花的一些特征来进行分类,这里仅使用两种花的特征,即萼片长度和花瓣长度,将这两个特征用向量表示为:
x也叫做输入向量,我们再定义一个相应的权重向量w:
将x和w线性组合后得到z:
我们假设,如果样本的激活值z大于等于事先设置好的阈值b,我们就说此样本属于类别1,否则属于类别-1,公式表示如下:
可以看出这个想法和神经元的工作原理很相似。为了方便,我们将阈值b移到等式的左边并额外定义一个权重参数来代替-b,更新z为以下等式:
那么上式中的z大于等于0的情况也就等价于之前当z大于等于阈值b的情况,可以得到:
上面的函数也叫做激活函数,我们通过激活函数将z压缩到了一个二元输出(1,-1),也就是:

我们总结一下我们学到的,感知器的总体结构如下:
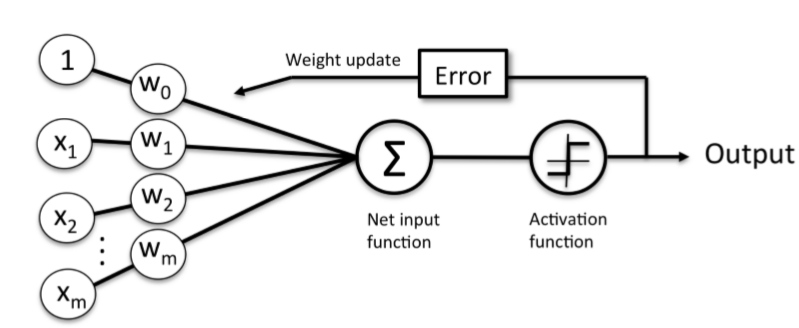
感知器将输入变量x与权重向量w结合得到z,z经过激活函数后被压缩到一为二元输出。
我们可以看出权重向量w决定着分类是否准确,那么我们如何选择合适的权重向量w呢?我们不能一个一个给w赋值,这样工作量太大且没有效率,其实感知器可以通过数据集中的样本自动调整w,随着训练的进行,w的变化趋于平稳,分类的准确率也会大大提高。
我们更新权重向量w的公式为:
其中学习率介于0.0和1.0之间,用于控制w更新的程度,权重向量w中的每一个参数都是同步更新的,即只有在w的每个参数的更新大小都计算出来后才会改变w的值,我们使用数据集中的大量训练样本x来更新w,来逐渐提高分类准确率。
感知器算法只有类别线性可分且学习率较小的情况下才能保证收敛,感知器接收训练样本x,将x与w线性结合得到z,再将z传递给激活函数,产生一个分类结果作为对样本x的预测类别,之后按照更新规则来更新w,等收敛后感知器也就训练完成了。
接下来我们开始实现感知器算法并使用Iris数据集训练:
import pandas as pd
读取数据集
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.tail()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
由上表可以看到每个输入向量x都包含4个特征(0、1、2、3)和1个正确的类别(4)
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
取出前100个训练样本的类别向量,若其类别输入‘Iris-setosa’,则将其设置为-1,否则设置为1
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
取出前100个训练样本的前两个特征向量
X = df.iloc[0:100, [0, 2]].values
画出这100个训练样本的类别分布图
plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.legend(loc='upper left')
plt.show()

实现感知器
import numpy as np
class Perceptron(object):
"""Perceptron classifier.
Parameters
----------
eta:float
Learning rate(between 0.0 and 1.0
n_iter:int
Passes over the training dataset.
Attributes
----------
w_:1d-array
weights after fitting.
errors_:list
Number of miscalssifications in every epoch.
"""
def __init__(self, eta=0.01, n_iter=10):
self.eta = eta
self.n_iter = n_iter
def fit(self, X, y):
"""Fit training data.
:param X:{array-like}, shape=[n_samples, n_features]
Training vectors, where n_samples is the number of samples and
n_features is the number of features.
:param y: array-like, shape=[n_samples]
Target values.
:return:
self:object
"""
self.w_ = np.zeros(1 + X.shape[1]) # Add w_0
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, self.w_[1:]) + self.w_[0]
def predict(self, X):
"""Return class label after unit step"""
return np.where(self.net_input(X) >= 0.0, 1, -1) #analoge ? :n in C++
ppn = Perceptron(eta = 0.1, n_iter = 10)
ppn.fit(X, y)
<__main__.Perceptron at 0x16680906978>
画出训练曲线
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker = 'o')
plt.xlabel('Epoches')
plt.ylabel('Number of misclassifications')
plt.show()

画出分界线
from matplotlib.colors import ListedColormap
def plot_decision_region(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 0].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
#plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx), marker = markers[idx],
label=cl)
plot_decision_region(X, y, classifier=ppn)
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()

参考:
https://www.toutiao.com/a6669391886744027662/
https://zh.wikipedia.org/wiki/%E6%84%9F%E7%9F%A5%E5%99%A8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号