WEB03_Day01(上)-关联查询、权限管理、MySQL体系架构、MySQL运行机制
一、关联查询
-
1对1关系:
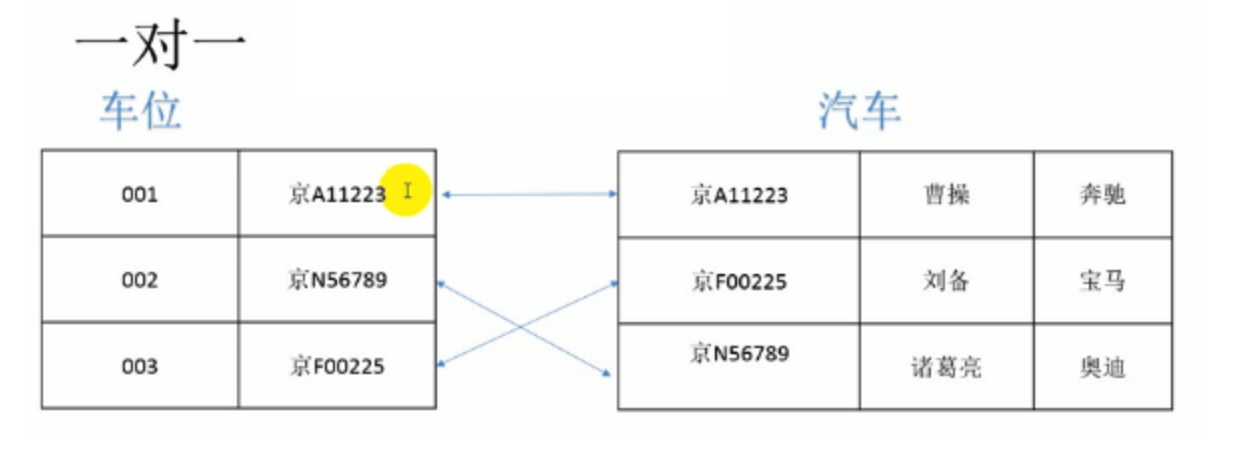
-
1对多关系:

-
多对多关系:
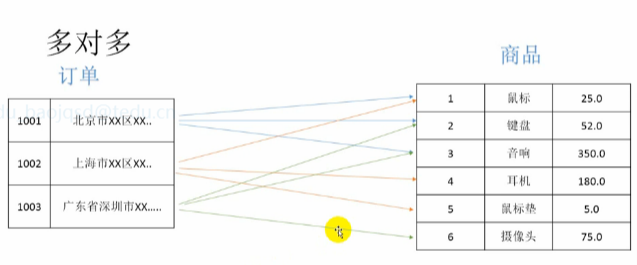
1.2 关联查询
定义:同时查询多张表数据的查询方式称为关联查询
1.2.1 等值连接(笛卡尔积)
格式: select 字段信息 from A,B where 关联关系 and 其它条件
注意:关联查询必须写关联关系,如果不写会得到两张表结果的乘积,这个乘积称为笛卡尔积,这是一个错误的查询结果,工作中切记不要出现。
-
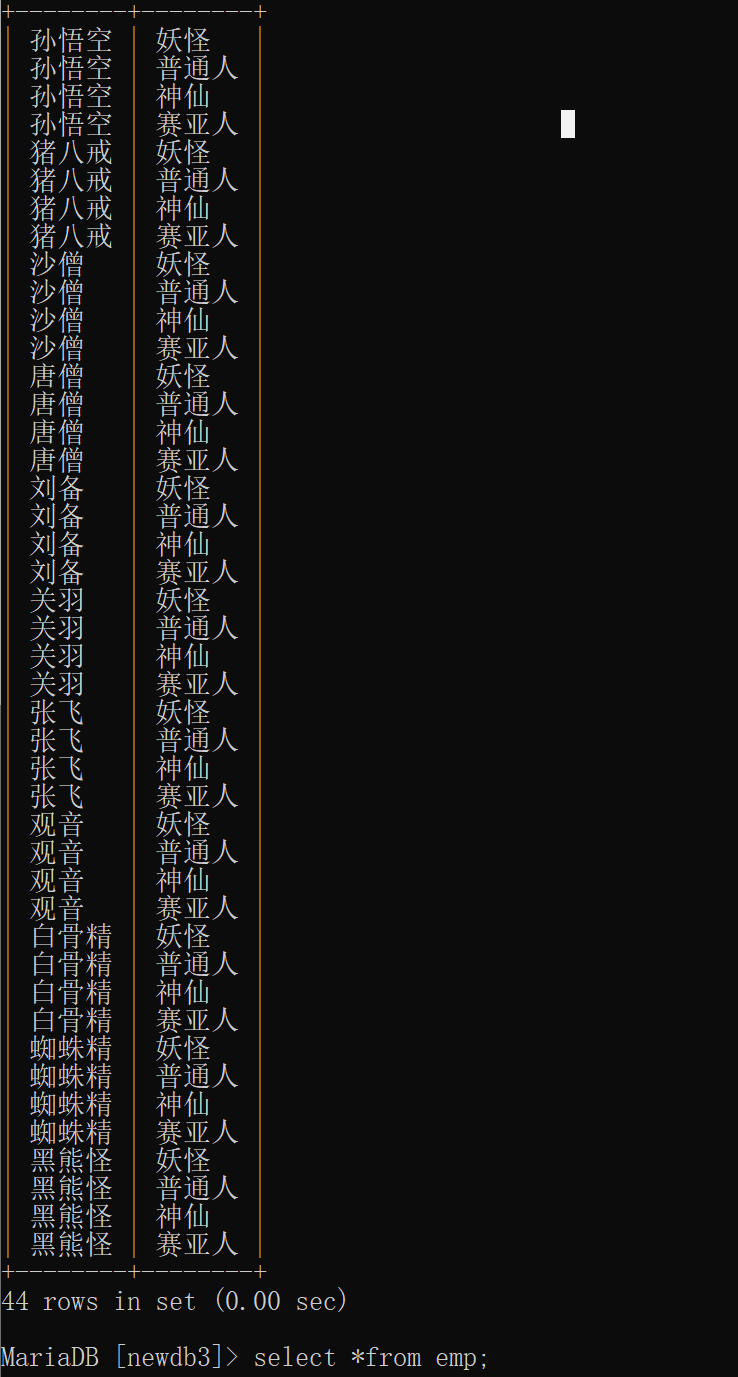
查询每个员工的姓名和对应的部门名
-- 错误的查询方式,两张表中的字段查询并未给定关联条件
select ename,dname from emp,dept;
-- 错误方式,虽然给定数据表之间的关联条件,但是两张数据表中的关联条件的字段名称一致
select ename,dname from dept,emp where deptno=deptno;
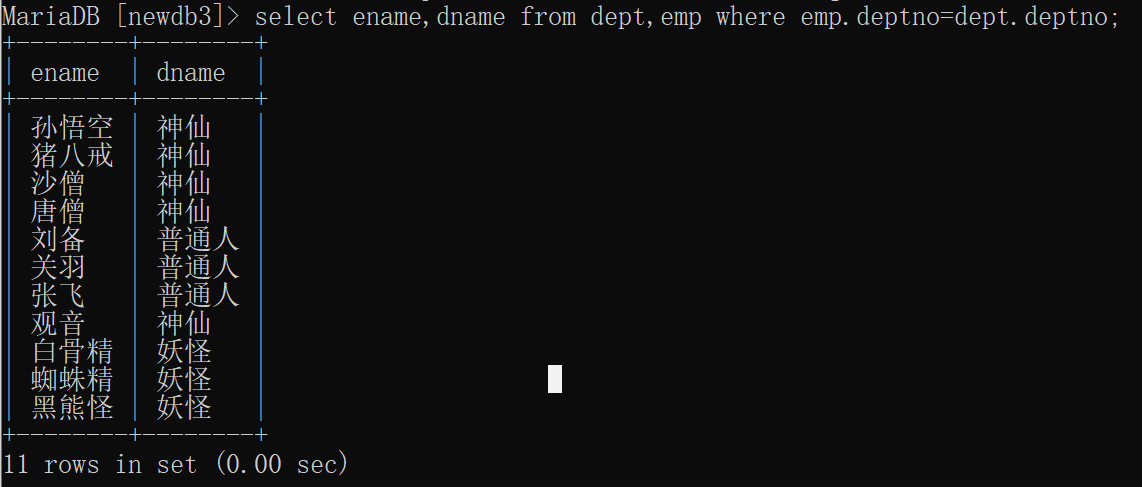
-- 正确方式,两张表中字段查询给定员工表中的deptno和部门表中的deptno进行添加关联条件
select ename,dname from dept,emp where emp.deptno=dept.deptno;
错误查询:
正确查询:
-
查询工资高于2000的员工姓名工资和部门所在地
select e.ename,e.sal,d.loc from emp as e,dept as d where e.deptno=d.deptno and e.sal>2000;

等值连接问题点:
-
数据表与数据表之间在from关键字之后用逗号进行分隔,意图并不清晰
-
关联条件和查询条件都写到where关键字的后面,sql语句书写并不规范
1.2.2 内连接
定义:内连接是一种一一映射关系,就是两张表都有的才能显示出来,用韦恩图表示是两个集合的交集
格式: select 字段信息 from A inner join B on 关联关系 where 其它条件(inner可以省略)

-
查询每个员工的姓名和对应的部门名
select e.ename,d.dname from emp e inner join dept d on e.deptno=d.deptno;

-
查询1号部门的员工的姓名,工作,部门名和部门所在地
select e.ename,e.job,d.dname,d.loc from dept d inner join emp e on d.deptno=e.deptno where e.deptno=1;
select e.ename,e.job,d.dname,d.loc from dept d inner join emp e on d.deptno=e.deptno where d.deptno=1;

1.2.3 外连接
左连接和右连接
查询一张表的全部数据以及另外一张表的交集数据,也就是在连接开始前指定左侧或者右侧表为主表
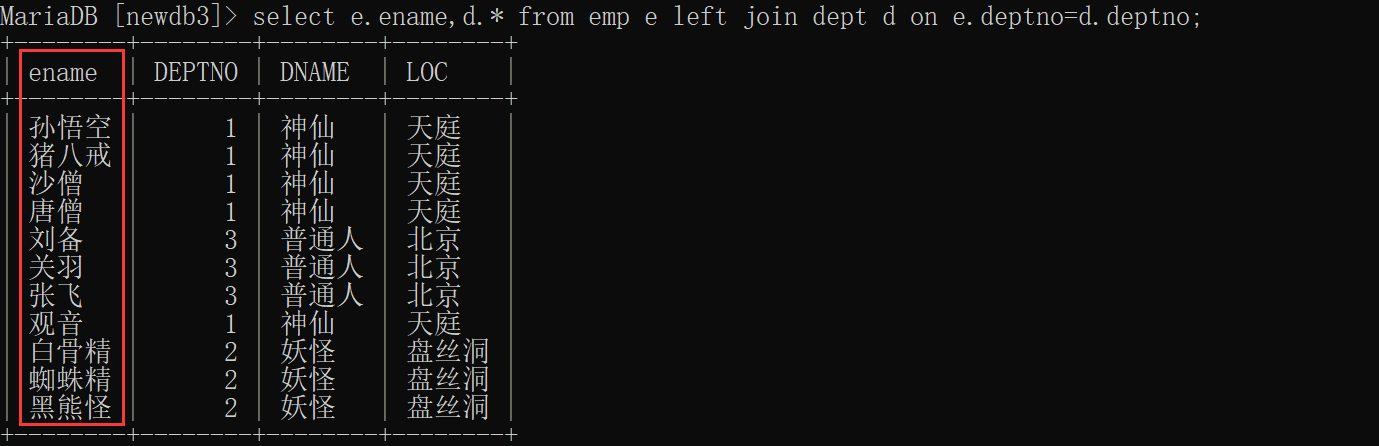
左连接定义:左连接是左边表的所有数据都有显示出来,右边的表数据只显示共同有的那部分,没有对应的部分只能补空显示,所谓的左边表其实就是指放在left join的左边的表。
左连接格式:select 字段信息 from A left join B on 关联关系 where 其它条件
-
查询所有员工姓名和对应的部门信息
select e.ename,d.* from emp e left join dept d on e.deptno=d.deptno;
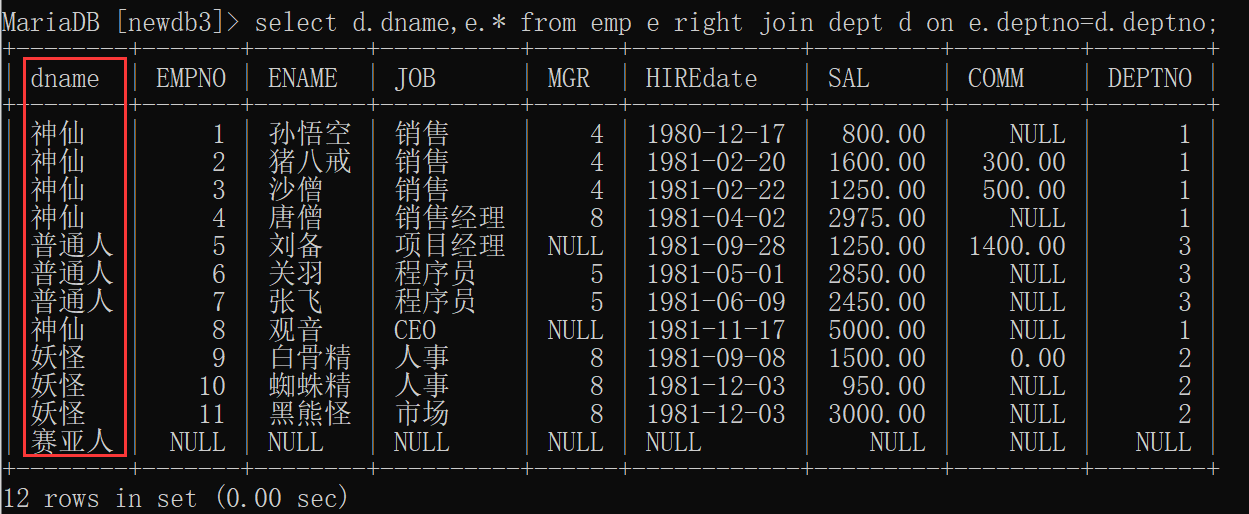
右连接定义:右连接正好是和左连接相反的,这里的右边也是相对right join来说的,在这个右边的表就是右表。
右连接格式:select 字段信息 from A right join B on 关联关系 where 其它条件

-
查询所有部门名以及部门对应的员工信息
select d.dname,e.* from emp e right join dept d on e.deptno=d.deptno;
1.3 关联查询和子查询之间的区别
-
适用场景:
-
子查询适合将一个查询结果作为另一个查询语句的条件
-
关联查询适合查询的结果是多张数据表中的数据内容
-
子查询可以用于单表查询,也可以用于多表,但是关联查询必须要多表之间存在关联关系
-
-
效率对比:
-
关联查询的效率要高于子查询,子查询走的是笛卡尔积(对进行多次遍历所有的数据内容)
-
关联查询会将当前需要进行从多表中间查询的数据根据关联条件进行查询。
-
二、权限管理(扩展)
2.1 定义
网站中的资源内容常常会根据登录的不同的用户,进而显示不同的资源(功能),比如下面学生和老师访问某个学习平台系统,老师登录以后可以进行设计试卷和试卷评分,当前这些功能是学生所不能访问。
2.2 关联理解图解
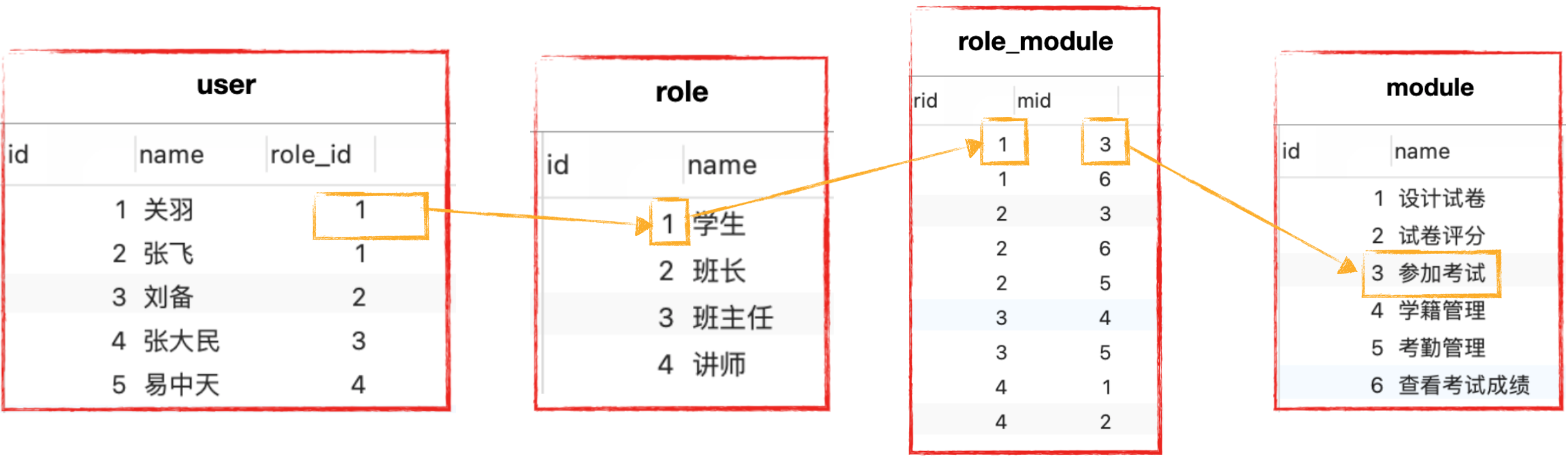 2.3 ER图表
2.3 ER图表

-
sql语句
-- 创建数据库
CREATE DATABASE `tedu_role` CHARACTER SET utf8;
USE `tedu_role`;
-- 创建用户表
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id主键',
`name` varchar(10) DEFAULT NULL COMMENT '姓名',
`role_id` int(11) DEFAULT NULL COMMENT '角色id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `user`(`id`,`name`,`role_id`) values (1,'关羽',1),(2,'张飞',1), (3,'刘备',2),(4,'张大民',3),(5,'易中天',4);
-- 创建角色表
DROP TABLE IF EXISTS `role`;
CREATE TABLE `role` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '角色id主键',
`name` varchar(10) DEFAULT NULL COMMENT '角色名字',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `role`(`id`,`name`) values (1,'学生'),(2,'班长'),(3,'班主任'), (4,'讲师');
-- 创建权限表
DROP TABLE IF EXISTS `module`;
CREATE TABLE `module` (
`id` int(11)