
数据采集第三次作业
第三次作业

作业1
代码
展开
import os
import random
import threading
import time
from queue import Queue
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
#爬虫基类
class BaseCrawler:
def __init__(self,save_dir='./images'):
self.save_dir = save_dir
if not os.path.exists(self.save_dir):
os.makedirs(self.save_dir)
def get(self,url):
try:
response=requests.get(url,timeout=10)
response.raise_for_status()
html = response.text
return html
except Exception as e:
print(e)
#解析img
def to_links(self,html):
links=[]
soup = BeautifulSoup(html, 'lxml')
imgs = soup.find_all('img')
for img in imgs:
src = img.get('src')
if src.startswith('//'):
src='https:'+src
if not src.startswith('http'):
continue
links.append(src)
return links
#爬虫
def crawl(self,url):
for link in self.to_links(self.get(url)):
self.download(link)
#下载链接
def download(self,url):
try:
img_path=url.split('/')[-1]
with open(os.path.join(self.save_dir,img_path),'wb') as f:
f.write(requests.get(url).content)
print('downloaded',url)
return True
except Exception as e:
print('下载失败',e)
return False
#多线程爬虫
class MultiCrawler(BaseCrawler):
def __init__(self, urls=None, save_dir='./images', max_page=51, max_num=151):
super().__init__(save_dir)
if urls is None:
urls = []
self.max_page = max_page
self.max_num = max_num
self.downloaded_count = 0
self.downloaded_count_lock = threading.Lock()
#线程任务
def worker(self,page_num):
time.sleep(random.uniform(1,3))
url=f"https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684&page_index={page_num}#J_tab"
links=self.to_links(self.get(url))
with self.downloaded_count_lock:
if self.downloaded_count >= self.max_num:
return
# print(page_num,len(links))
#重写一下下载程序,保证线程安全
for link in links:
with self.downloaded_count_lock:
if self.downloaded_count >= self.max_num:
break
with self.downloaded_count_lock:
img_path = link.split('/')[-1]
if os.path.exists(os.path.join(self.save_dir,img_path)):
continue
if self.download(link):
with self.downloaded_count_lock:
self.downloaded_count += 1
def crawl(self):
threads = []
for page_num in range(1,self.max_page+1):
t=threading.Thread(target=self.worker,args=(page_num,))
threads.append(t)
t.start()
for t in threads:
t.join()
# print('单线程')
# BaseCrawler().crawl("https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684&page_index=1#J_tab")
print('多线程')
MultiCrawler().crawl()
结果:
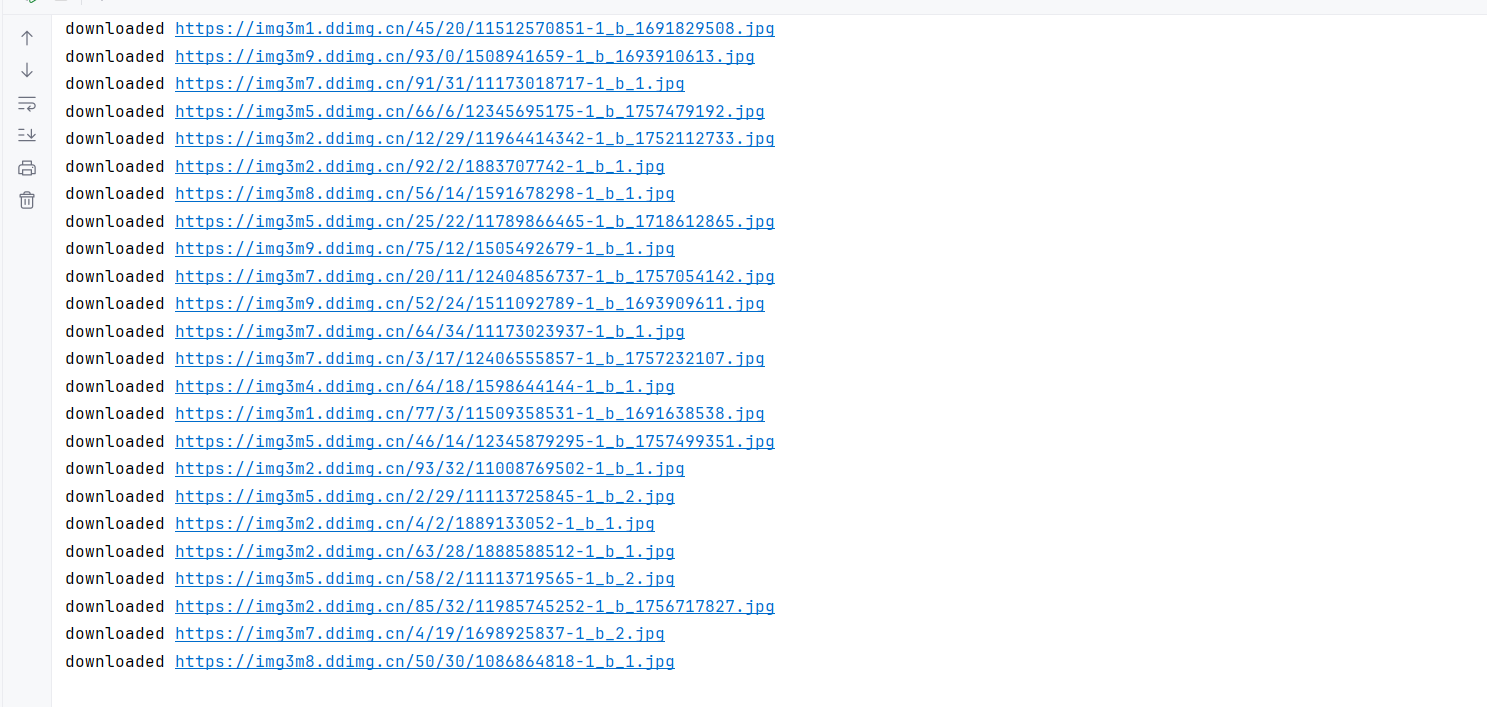
选择当当网作为目标网站,实现了单线程和多线程两种下载方式。为了提升下载效率,没有对下载过程加锁,但当线程数过多时可能会超过预设的下载数量限制。
心得
通过本次实践,我深入掌握了多线程爬虫的开发技巧:
线程安全控制:使用线程锁(threading.Lock)确保共享资源(如下载计数器)的线程安全访问
URL规范化处理:对图片链接进行标准化处理,确保能够正确下载不同格式的URL
异常处理机制:完善的异常捕获和处理,提高爬虫的健壮性
进度控制:通过计数器机制精确控制下载数量,避免无限爬取
多线程技术显著提升了爬虫效率,但也带来了更复杂的并发控制问题,需要在性能和代码复杂度之间找到平衡。
链接:https://gitee.com/wsxxs233/data-collection/tree/master/task3/blog/q1
作业2
代码
spider
import json
import time
from scrapy_selenium import SeleniumRequest
import scrapy
from stocks.items import StocksItem
#spider类
class StocksSpider(scrapy.Spider):
name = "stocks"
def start_requests(self):
url = 'https://quote.eastmoney.com/center/hszs.html'
#启用selenium中间件,替换request
yield SeleniumRequest(url=url, callback=self.parse,wait_time=30 )
def parse(self, response):
#xpath解析定位表格
table=response.xpath('//table[@class="quotetable_m"]/tbody')
tr=table[0].xpath('.//tr')
for t in tr:
item= StocksItem()
for i,name in enumerate(['id','code','stock_name','last_price','change_percent','change','volume','amplitude','high','low','open','close']):
item[name]=t.xpath('.//text()').extract()[i]
yield item
用于访问网页并用xpath解析内容
middleware
#selenium中间件
class SeleniumMiddleware:
"""Scrapy middleware handling the requests using selenium"""
def __init__(self, driver_name, driver_executable_path, driver_arguments,
browser_executable_path):
"""Initialize the selenium webdriver
Parameters
----------
driver_name: str
The selenium ``WebDriver`` to use
driver_executable_path: str
The path of the executable binary of the driver
driver_arguments: list
A list of arguments to initialize the driver
browser_executable_path: str
The path of the executable binary of the browser
"""
webdriver_base_path = f'selenium.webdriver.{driver_name}'
driver_klass_module = import_module(f'{webdriver_base_path}.webdriver')
driver_klass = getattr(driver_klass_module, 'WebDriver')
driver_options_module = import_module(f'{webdriver_base_path}.options')
driver_options_klass = getattr(driver_options_module, 'Options')
driver_service_module= import_module(f'{webdriver_base_path}.service')
driver_service_klass = getattr(driver_service_module, 'Service')
driver_options = driver_options_klass()
if browser_executable_path:
driver_options.binary_location = browser_executable_path
for argument in driver_arguments:
driver_options.add_argument(argument)
driver_service = driver_service_klass()
if driver_executable_path:
driver_service.executable_path=driver_executable_path
driver_kwargs = {
'options': driver_options,
'service': driver_service
}
# options = options, service = service
self.driver = driver_klass(**driver_kwargs)
@classmethod
def from_crawler(cls, crawler):
"""Initialize the middleware with the crawler settings"""
driver_name = crawler.settings.get('SELENIUM_DRIVER_NAME')
driver_executable_path = crawler.settings.get('SELENIUM_DRIVER_EXECUTABLE_PATH')
browser_executable_path = crawler.settings.get('SELENIUM_BROWSER_EXECUTABLE_PATH')
driver_arguments = crawler.settings.get('SELENIUM_DRIVER_ARGUMENTS')
if not driver_name or not driver_executable_path:
raise NotConfigured(
'SELENIUM_DRIVER_NAME and SELENIUM_DRIVER_EXECUTABLE_PATH must be set'
)
middleware = cls(
driver_name=driver_name,
driver_executable_path=driver_executable_path,
driver_arguments=driver_arguments,
browser_executable_path=browser_executable_path
)
crawler.signals.connect(middleware.spider_closed, signals.spider_closed)
return middleware
def process_request(self, request, spider):
"""Process a request using the selenium driver if applicable"""
if not isinstance(request, SeleniumRequest):
return None
self.driver.get(request.url)
try:
print('等待页面加载')
# 等待特定元素加载完成
WebDriverWait(self.driver, 15).until(
EC.presence_of_element_located((By.TAG_NAME, "body"))
)
# 等待AJAX加载完成
WebDriverWait(self.driver, 15).until(
lambda driver: driver.execute_script("return document.readyState") == "complete"
)
# 等待关键内容加载
WebDriverWait(self.driver, 20).until(
EC.presence_of_element_located((By.CLASS_NAME, "main-content"))
)
print('加载完成')
except Exception as e:
spider.logger.warning(f"等待超时: {request.url}, 错误: {str(e)}")
for cookie_name, cookie_value in request.cookies.items():
self.driver.add_cookie(
{
'name': cookie_name,
'value': cookie_value
}
)
if request.wait_until:
WebDriverWait(self.driver, request.wait_time).until(
request.wait_until
)
if request.screenshot:
request.meta['screenshot'] = self.driver.get_screenshot_as_png()
if request.script:
self.driver.execute_script(request.script)
body = str.encode(self.driver.page_source)
# Expose the driver via the "meta" attribute
request.meta.update({'driver': self.driver})
return HtmlResponse(
self.driver.current_url,
body=body,
encoding='utf-8',
request=request
)
def spider_closed(self):
"""Shutdown the driver when spider is closed"""
self.driver.quit()
从scrapy_selenium里搬运的中间件(scrapy_selenium.middlewares.SeleniumMiddleware)。因为版本的原因scrapy_selenium库不是很适配新版的selenium,主要体现在webdriver的调用,新版webdriver移除了executable_path,使用option作为参数,这里做了适当修改。
结果:
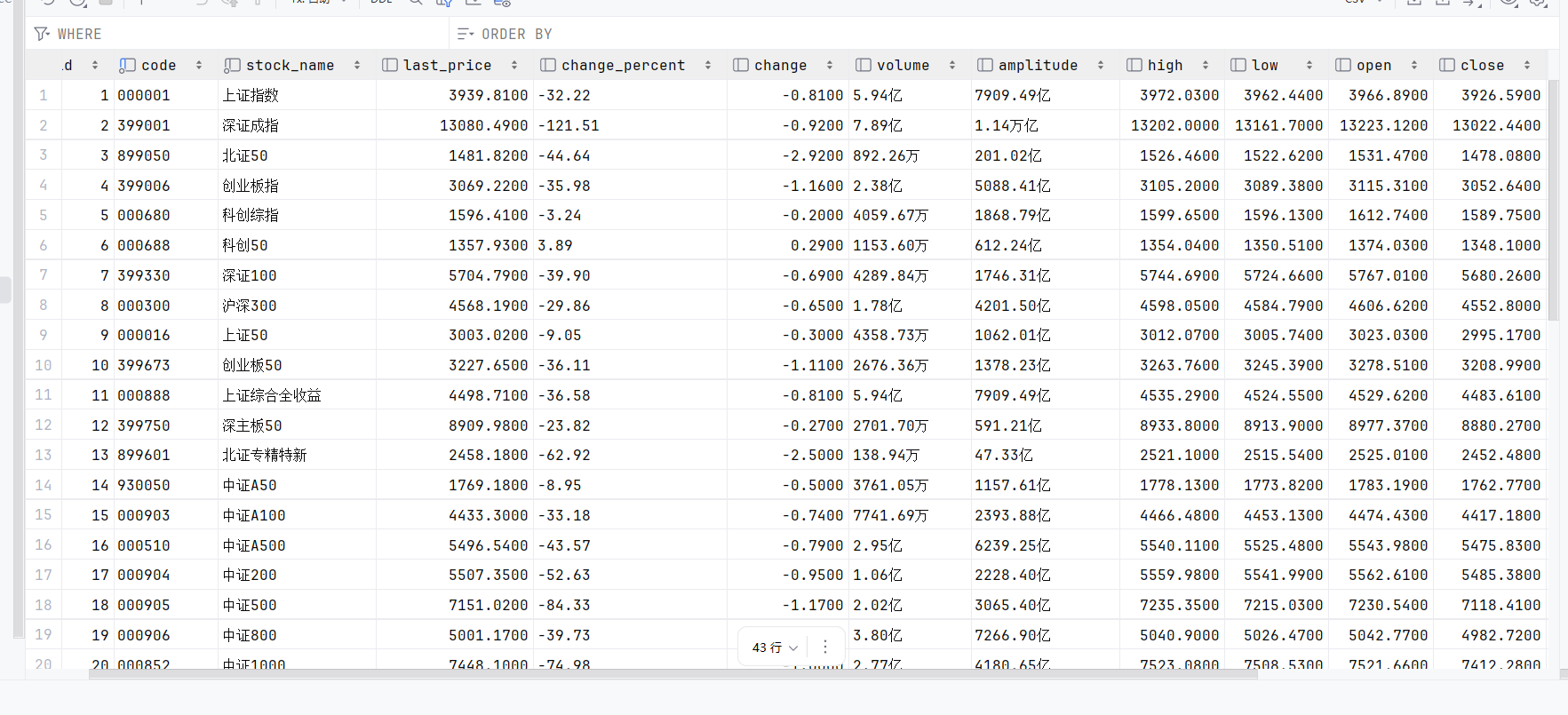
心得
本次实践让我深入理解了Scrapy框架与Selenium的集成应用:
中间件深度定制:通过自定义Selenium中间件,解决了新版Selenium与scrapy_selenium库的兼容性问题,掌握了动态导入和反射的应用
Scrapy架构理解:深入理解了Scrapy的请求-响应流程、中间件机制和信号系统
XPath精准解析:通过精确的XPath选择器,从复杂的HTML结构中提取结构化数据
这种组合技术特别适用于处理JavaScript动态渲染的网页,为爬取现代Web应用提供了有效解决方案。
链接:https://gitee.com/wsxxs233/data-collection/tree/master/task3/blog/q2
作业3
代码
展开
import json
import time
import scrapy
from exchange.items import ExchangeItem
class ExchangeSpider(scrapy.Spider):
name = "exchange"
def start_requests(self):
url = 'https://www.boc.cn/sourcedb/whpj/'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
#xpath定位解析
table=response.xpath('//table[@cellpadding="0" and @align="left"]')[0]
tr=table.xpath('.//tr[position()>1]')
for t in tr:
if len(t.xpath('.//td')) == 8:
item = ExchangeItem()
item['Currency']=t.xpath('.//td')[0].xpath('./text()').extract_first()
item['TBP']=t.xpath('.//td')[1].xpath('./text()').extract_first()
item['CBP']=t.xpath('.//td')[2].xpath('./text()').extract_first()
item['TSP']=t.xpath('.//td')[3].xpath('./text()').extract_first()
item['CSP']=t.xpath('.//td')[4].xpath('./text()').extract_first()
item['Time']=t.xpath('.//td')[7].xpath('./text()').extract_first()
yield item
结果
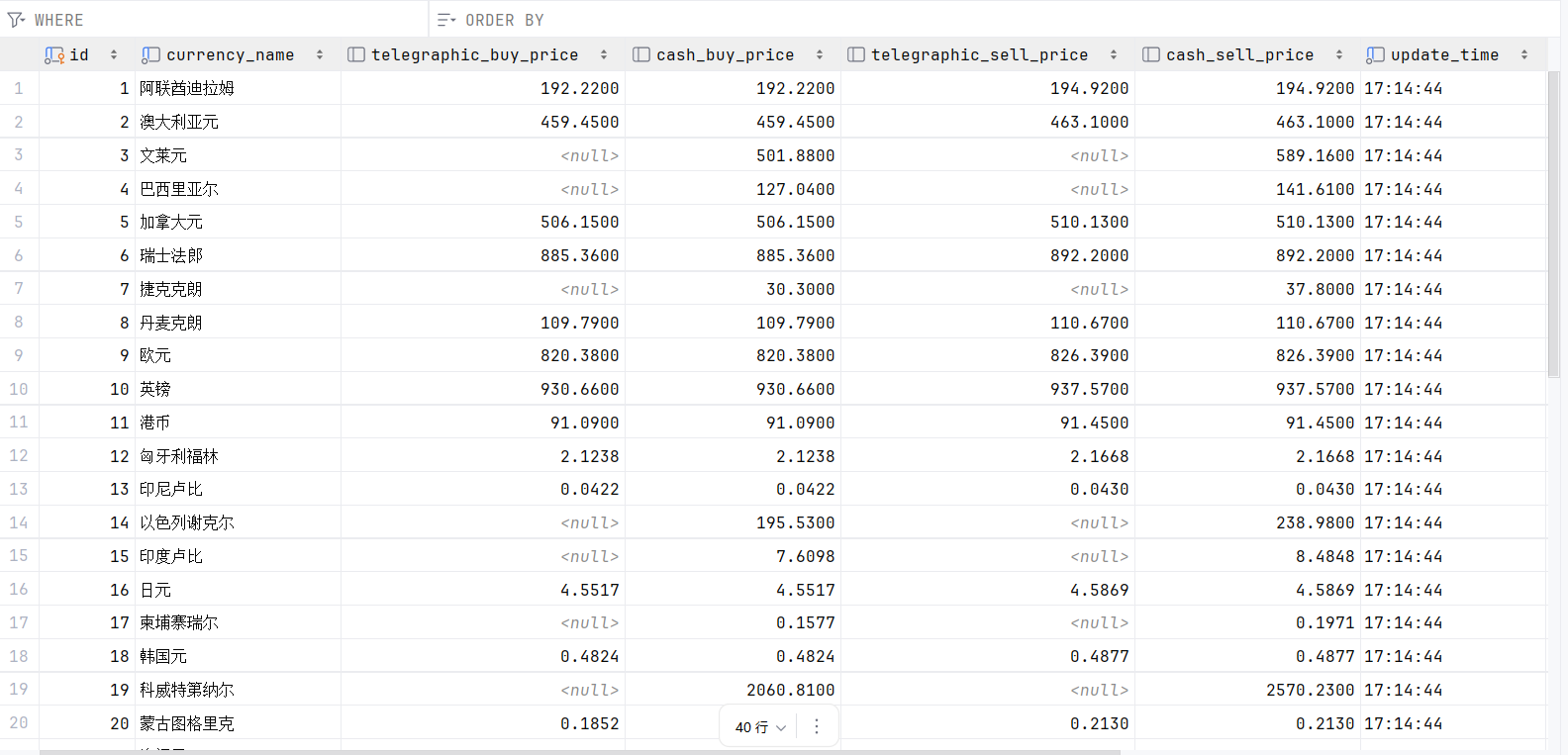
心得
通过本次汇率数据爬取项目,我获得了以下宝贵经验:
精准的XPath定位:掌握了使用复杂XPath表达式定位表格数据的方法,特别是通过属性组合和位置选择器精确定位目标元素
结构化数据提取:将网页中的非结构化数据转换为结构化的Item对象,为后续存储和分析奠定基础
MySQL数据库集成:学习了Scrapy与MySQL的集成,包括数据库连接池管理、表结构设计和数据批量插入
管道编程模式:深入理解了Scrapy的管道机制,掌握了数据验证、清洗和存储的完整流程
链接:https://gitee.com/wsxxs233/data-collection/tree/master/task3/blog/q3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号