数据采集第二次作业
第二次作业
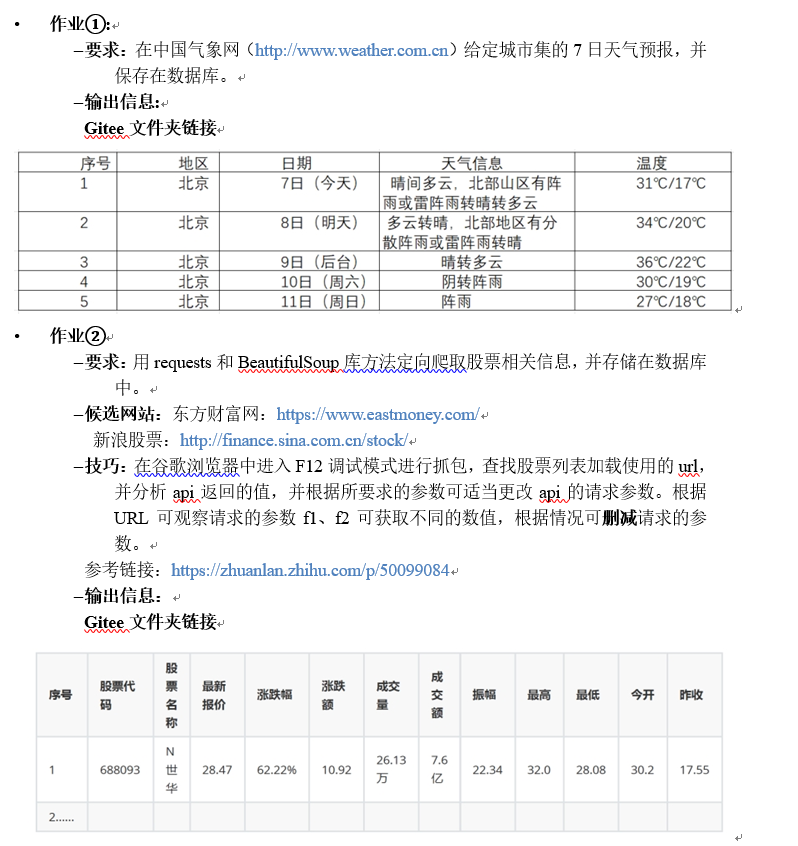

作业1
相关代码和结果
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.db = None
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101",
"深圳": "101280601"} # 城市的编码本
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
# self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
注意到跳转的链接那指定城市有一个编码,如北京为:101010100。只要把链接改成对应城市即可查看相关城市的天气

结果:

心得
这里学会了通过观察url中的差异来访问不同的网站,来自动化获取想要的信息。此外学习了sqlite3的一些用法。
链接:https://gitee.com/wsxxs233/data-collection/tree/master/task2/blog/q1
作业2
代码和结果
import json
import sqlite3
import time
import pandas as pd
import requests
def format_number_to_units(number, precision=2):
"""
将浮点数转换为以万或亿为单位的字符串
参数:
number: 要转换的浮点数
precision: 保留的小数位数,默认为2位
返回:
转换后的字符串,如"1.00万"、"100.00万"、"1.00亿"
"""
abs_num = abs(number)
# 判断条件决定使用哪个单位
if abs_num >= 1e8: # 大于等于1亿
result = number / 1e8
unit = '亿'
elif abs_num >= 1e4: # 大于等于1万但小于1亿
result = number / 1e4
unit = '万'
else: # 小于1万
result = number
unit = ''
# 格式化数字,保留指定小数位数
if unit: # 如果转换了单位
formatted_num = f"{result:.{precision}f}"
return f"{formatted_num}{unit}"
else: # 如果没有转换单位,直接返回原数字的格式化
return f"{result:.{precision}f}"
import beautifultable
headers = {
'accept-language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'connection':'keep-alive',
'cookie':'fullscreengg=1; fullscreengg2=1; qgqp_b_id=110282da83710be39d3f04bc22ad49b4; st_si=47037965562448; st_asi=delete; st_nvi=ze_XYSElrfUrGQxs2o7x999b8; nid=0ee489b5a0c26ceb35970162b7983121; nid_create_time=1761721084597; gvi=IVLmXbTDpuiq7cx02UETE789b; gvi_create_time=1761721084597; st_pvi=74642916940458; st_sp=2025-10-29%2014%3A58%3A03; st_inirUrl=; st_sn=26; st_psi=20251029161701538-113200301321-3924716102',
'host':'push2.eastmoney.com',
'referer':'https://quote.eastmoney.com/center/gridlist.html',
'sec-ch-ua':'"Microsoft Edge";v="141", "Not?A_Brand";v="8", "Chromium";v="141"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'sec-fetch-dest':'script',
"user-agent":
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0'
}
table = beautifultable.BeautifulTable()
table.columns.header = ["序号", "代码", "名称", "最新价", "涨跌幅", "跌涨额", "成交量", "成交额", "涨幅"]
table.columns.width = [15, 15, 15, 15, 15, 15, 15, 15, 15]
table.columns.alignment = beautifultable.enums.ALIGN_LEFT
for i in range(5):
url = f'https://push2.eastmoney.com/api/qt/clist/get?np=1&fltt=1&invt=2&cb=jQuery3710277153053545653_1761725821366&fs=m%3A0%2Bt%3A6%2Bf%3A!2%2Cm%3A0%2Bt%3A80%2Bf%3A!2%2Cm%3A1%2Bt%3A2%2Bf%3A!2%2Cm%3A1%2Bt%3A23%2Bf%3A!2%2Cm%3A0%2Bt%3A81%2Bs%3A262144%2Bf%3A!2&fields=f12%2Cf13%2Cf14%2Cf1%2Cf2%2Cf4%2Cf3%2Cf152%2Cf5%2Cf6%2Cf7%2Cf15%2Cf18%2Cf16%2Cf17%2Cf10%2Cf8%2Cf9%2Cf23&fid=f3&pn={i+1}&pz=20&po=1&dect=1&ut=fa5fd1943c7b386f172d6893dbfba10b&wbp2u=%7C0%7C0%7C0%7Cweb&_=1761725821372'
time.sleep(5)
response=requests.get(url,headers=headers)
response.encoding=response.apparent_encoding
response_text=response.text
start_index = response_text.find('(') + 1
end_index = response_text.rfind(')')
json_data_str = response_text[start_index:end_index]
js=json.loads(json_data_str)
for id,item in enumerate(js['data']['diff']):
f2='{}.{}'.format(str(item['f2'])[:-2],str(item['f2'])[-2:])
f3='{}.{}%'.format(str(item['f3'])[:-2],str(item['f3'])[-2:])
f4='{}.{}'.format(str(item['f4'])[:-2],str(item['f4'])[-2:])
f7='{}.{}%'.format(str(item['f7'])[:-2],str(item['f3'])[-2:])
table.rows.append([id+20*i+1,item["f12"],item["f14"],f2,f3,f4,format_number_to_units(float(item["f5"])),format_number_to_units(float(item["f6"])),f7])
print(f'page{i+1}')
df=table.to_df()
conn=sqlite3.connect('stocks.db')
df.to_sql(
name='A',
con=conn,
if_exists='replace',
index=False
)
conn.close()
# 从数据库读取数据验证
conn = sqlite3.connect('stocks.db')
# 读取整个表
result_df = pd.read_sql('SELECT * FROM A', conn)
print("从数据库读取的数据:")
print(result_df)
conn.close()
结果:

这里通过F12调试发现股票信息是存在这个js文件的,用request下载再用json解析即可得到想要的信息。
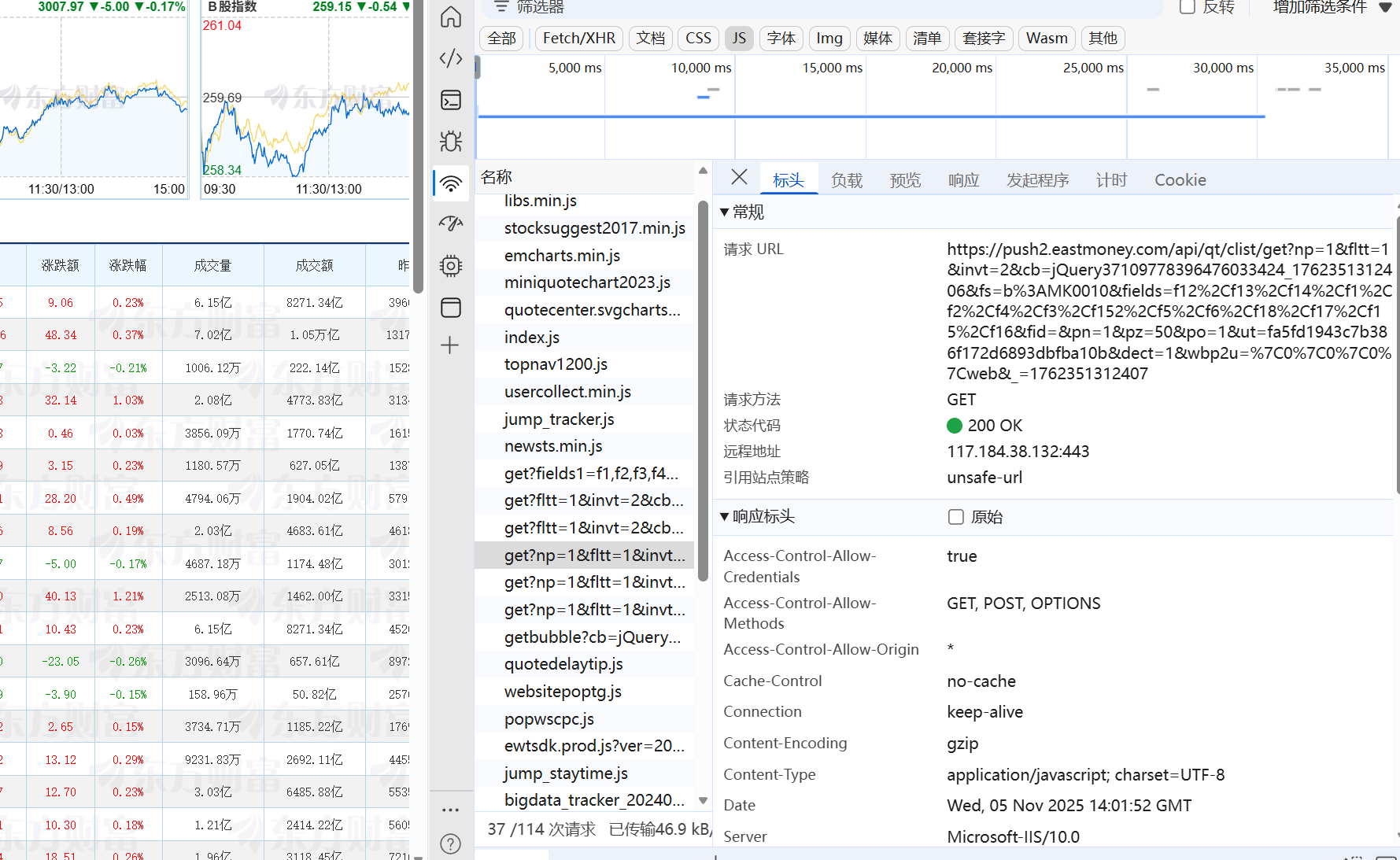
心得
这里学会了怎么通过接口获取信息和使用json解析。同时发现请求的时候带上请求标头不容易被服务器拦截。
链接:
https://gitee.com/wsxxs233/data-collection/tree/master/task2/blog/q2
作业3
代码与结果
import sqlite3
import beautifultable
import js2py
import pandas as pd
import requests
import json
import re
url='https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/2021/payload.js'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0',
'cookie':'_clck=1vlmizh%5E2%5Eg0r%5E0%5E2112;'
' Hm_lvt_af1fda4748dacbd3ee2e3a69c3496570=1760366429,1760516847,1760627317,1762352079; '
'Hm_lpvt_af1fda4748dacbd3ee2e3a69c3496570=1762352079; HMACCOUNT=3C6775A98EF952A2; '
'_clsk=xrufho%5E1762352080299%5E1%5E1%5Ev.clarity.ms%2Fcollect'
}
# js=requests.get(url,headers=headers)
# with open("cache.js",'w',encoding='utf-8') as f:
# f.write(js.text)
with open('cache.js', 'r', encoding='utf-8') as f:
s = f.read()
pattern = r'__NUXT_JSONP__\("/rankings/bcur/\d+",\s*\(function\(([^)]*)\)\s*{([\s\S]*)}\s*\(([^)]*)\)\)\);'
match = re.search(pattern, s)
func_params = match.group(1) # 函数参数: a, b, c, d, e, f, ...
function_body = match.group(2) # 函数体
actual_params = match.group(3) # 实际参数值
def extract_with_js_engine(func_params: str, function_body: str, actual_params: str) :
"""
使用JavaScript引擎执行函数并提取数据
"""
try:
# 创建JavaScript执行环境
context = js2py.EvalJs()
# 构建完整的JavaScript代码
js_code = f"""
// 定义函数
function getData({func_params}) {{
{function_body}
}}
// 调用函数并返回结果
var result = getData({actual_params});
// 返回univData数组
result.data[0].univData;
"""
# 执行JavaScript代码
univ_data = context.eval(js_code)
# 转换为Python列表
universities = []
for univ in univ_data:
university_info = {
'排名': univ.get('ranking', ''),
'学校名称': univ.get('univNameCn', ''),
'英文名称': univ.get('univNameEn', ''),
'学校类型': univ.get('univCategory', ''),
'所在省份': univ.get('province', ''),
'总分': univ.get('score', '')
}
universities.append(university_info)
return universities
except Exception as e:
print(f"JavaScript执行失败: {e}")
return []
import beautifultable
table = beautifultable.BeautifulTable()
table.columns.header = ["排名", "学校名称", "英文名称", "学校类型", "所在省份", "总分"]
table.columns.width = [15, 15, 60, 15, 15, 15]
for data in extract_with_js_engine(func_params, function_body, actual_params):
table.append_row(data.values())
df=table.to_df()
conn=sqlite3.connect('ranking.db')
df.to_sql(
name='A',
con=conn,
if_exists='replace',
index=False
)
conn.close()
# 从数据库读取数据验证
conn = sqlite3.connect('ranking.db')
# 读取整个表
result_df = pd.read_sql('SELECT * FROM A', conn)
print("从数据库读取的数据:")
print(result_df)
conn.close()
这里下载下来是js里的函数,一些参数设置成形参了直接json提取不方便,用jspy运行这个函数得到好看的结果。


心得
学会了怎么运行js代码并获取有用的信息。
链接:
https://gitee.com/wsxxs233/data-collection/tree/master/task2/blog/q3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号