1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
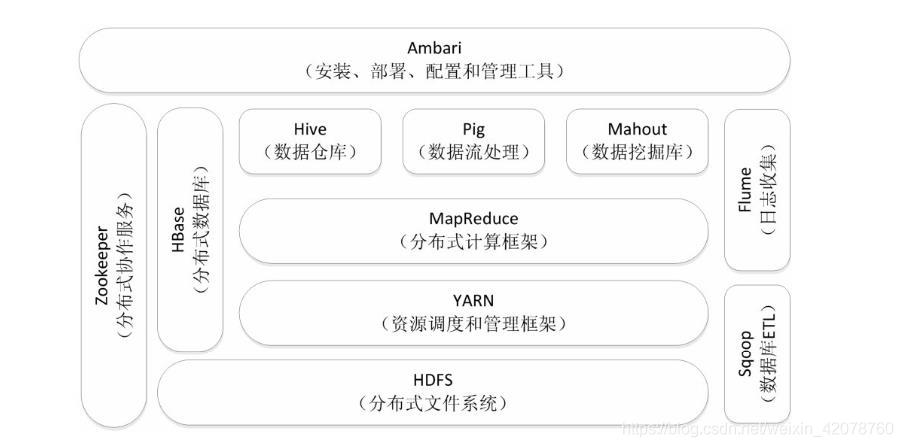
(1).HDFS 分布式文件系统
Hadoop分布式文件系统HDFS是针对谷歌分布式文件系统(Google File System,GFS)的开源实现,它是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
HDFS具有很好的容错能力,并且兼容廉价的硬件设备,因此,可以以较低的成本利用现有机器实现大流量和大数据量的读写。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
客户端访问文件机制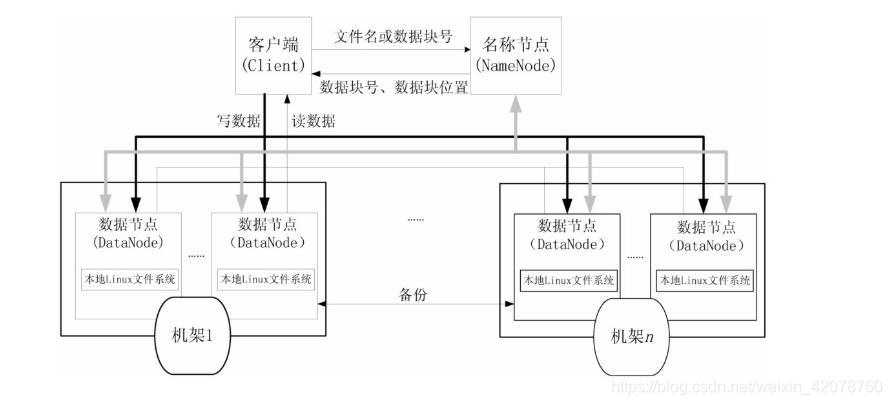
用户在使用 HDFS 时,仍然可以像在普通文件系统中那样,使用文件名去存储和访问文件。
实际上,在系统内部,一个文件会被切分成若干个数据块,这些数据块被分布存储到若干个数据节点上。
当客户端需要访问一个文件时,首先把文件名发送给名称节点,名称节点根据文件名找到对应的数据块(一个文件可能包括多个数据块),再根据每个数据块信息找到实际存储各个数据块的数据节点的位置,并把数据节点位置发送给客户端,最后,客户端直接访问这些数据节点获取数据。在整个访问过程中,名称节点并不参与数据的传输。
这种设计方式,使得一个文件的数据能够在不同的数据节点上实现并发访问,大大提高了数据的访问速度。
(2).MapReduce
MapReduce 是一种分布式并行编程模型,用于大规模数据集(大于1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。MapReduce极大方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算。
并行计算流程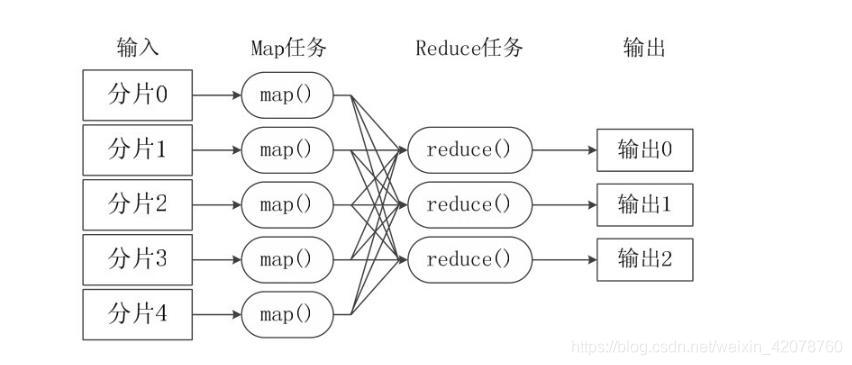
在MapReduce中,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的小数据块,这些小数据块可以被多个Map任务并行处理。MapReduce框架会为每个Map任务输入一个数据子集,Map任务生成的结果会继续作为Reduce任务的输入,最终由Reduce任务输出最后结果,并写入分布式文件系统。
涉及理念:计算向数据靠拢
MapReduce 设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为移动数据需要大量的网络传输开销,尤其是在大规模数据环境下,这种开销尤为惊人,所以,移动计算要比移动数据更加经济。本着这个理念,在一个集群中,只要有可能,MapReduce框架就会将Map程序就近地在 HDFS 数据所在的节点运行,即将计算节点和存储节点放在一起运行,从而减少了节点间的数据移动开销。
(3).YARN
YARN 是负责集群资源调度管理的组件。YARN 的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架,比如MapReduce、Tez、Storm、Giraph、Spark、OpenMPI等,由YARN为这些计算框架提供统一的资源调度管理服务(包括 CPU、内存等资源),并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩。
通过这种方式,可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率,同时,不同计算框架可以共享底层存储,在一个集群上集成多个数据集,使用多个计算框架来访问这些数据集,从而避免了数据集跨集群移动,最后,这种部署方式也大大降低了企业运维成本。
YARN支持的计算框架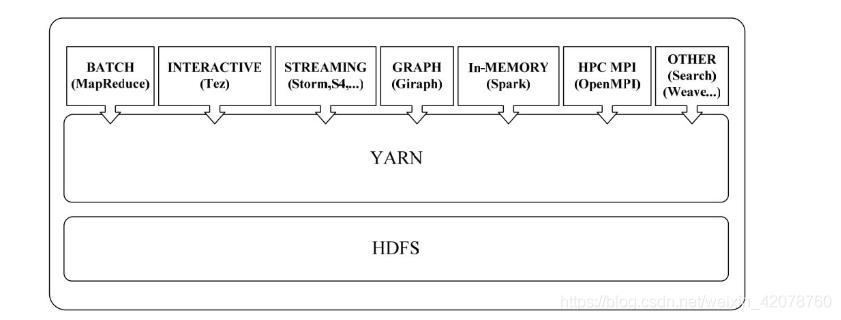
目前,可以运行在YARN之上的计算框架包括离线批处理框架MapReduce、内存计算框架Spark、流计算框架Storm和DAG计算框架Tez等。和YARN一样提供类似功能的其他资源管理调度框架还包括Mesos、Torca、Corona、Borg等。
(4).HBase
HBase 是针对谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行元素和数百万列元素组成的数据表
HBase利用MapReduce来处理HBase中的海量数据,实现高性能计算;利用 Zookeeper 作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力,当然,HBase也可以在单机模式下使用,直接使用本地文件系统而不用 HDFS 作为底层数据存储方式,不过,为了提高数据可靠性和系统的健壮性,发挥HBase处理大量数据等功能,一般都使用HDFS作为HBase的底层数据存储方式。此外,为了方便在HBase上进行数据处理,Sqoop为HBase提供了高效、便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
(5).Hive
Hive是一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
Hive的学习门槛比较低,因为它提供了类似于关系数据库SQL语言的查询语言——HiveQL,可以通过HiveQL语句快速实现简单的MapReduce统计,Hive自身可以自动将HiveQL语句快速转换成MapReduce任务进行运行,而不必开发专门的MapReduce应用程序,因而十分适合数据仓库的统计分析。
(6).Flume
Flume 是 Cloudera 公司开发的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统。
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
(7).Sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
通过Sqoop,可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(比如导入到HDFS、HBase或Hive中),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
2.对比Hadoop与Spark的优缺点。
(1)Spark对标于Hadoop中的计算模块MR,但是速度和效率比MR要快得多;
(2)Spark没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作,它只是一个计算分析框架,专门用来对分布式存储的数据进行计算处理,它本身并不能存储数据;
(3)Spark可以使用Hadoop的HDFS或者其他云数据平台进行数据存储,但是一般使用HDFS;
(4)Spark可以使用基于HDFS的HBase数据库,也可以使用HDFS的数据文件,还可以通过jdbc连接使用Mysql数据库数据;Spark可以对数据库数据进行修改删除,而HDFS只能对数据进行追加和全表删除;
(5)Spark数据处理速度秒杀Hadoop中MR;
(6)Spark处理数据的设计模式与MR不一样,Hadoop是从HDFS读取数据,通过MR将中间结果写入HDFS;然后再重新从HDFS读取数据进行MR,再刷写到HDFS,这个过程涉及多次落盘操作,多次磁盘IO,效率并不高;而Spark的设计模式是读取集群中的数据后,在内存中存储和运算,直到全部运算完毕后,再存储到集群中;
(7)Spark是由于Hadoop中MR效率低下而产生的高效率快速计算引擎,批处理速度比MR快近10倍,内存中的数据分析速度比Hadoop快近100倍(源自官网描述);
(8)Spark中RDD一般存放在内存中,如果内存不够存放数据,会同时使用磁盘存储数据;通过RDD之间的血缘连接、数据存入内存中切断血缘关系等机制,可以实现灾难恢复,当数据丢失时可以恢复数据;这一点与Hadoop类似,Hadoop基于磁盘读写,天生数据具备可恢复性;
(9)Spark引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟,对7的补充;
(10)Spark中通过DAG图可以实现良好的容错。
3.如何实现Hadoop与Spark的统一部署?
一方面,由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。
由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署(如图9-16所示)。这些不同的计算框架统一运行在YARN中,可以带来如下好处:
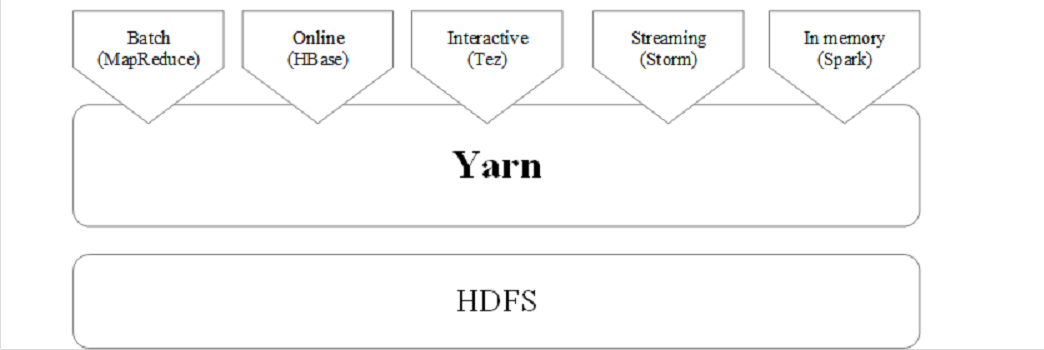
计算资源按需伸缩;
不用负载应用混搭,集群利用率高;
共享底层存储,避免数据跨集群迁移。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号