Python-爬虫基础八-urllib的一个类型和六个方法
urllib的详解使用
Urllib 库是 Python 内置的 HTTP 请求库,urllib 模块提供的上层接口,使访问 www 和 ftp 上的数据就像访问本地文件一样,并且它也是requests的底层库。它包含四个模块:
- urllib.request:请求模块。
- urllib.error:异常处理模块。
- urllib.parse:URL解析模块。
- urllib.robotparser:robots.txt解析模块。
实例1:使用urllib来获取百度首页的源码
# 使用urllib来获取百度首页的源码 import urllib.request # (1)定义一个url 就是你要访问的地址 url = 'http://www.baidu.com' # (2)模拟浏览器向服务器发送请求 response响应 response = urllib.request.urlopen(url) # (3)获取响应中的页面的源码 content 内容的意思 # read方法 返回的是字节形式的二进制数据 # 我们要将二进制的数据转换为字符串 # 二进制--》字符串 解码 decode('编码的格式') content = response.read().decode('utf-8') # (4)打印数据 print(content)
运行结果:

1个类型和6个方法
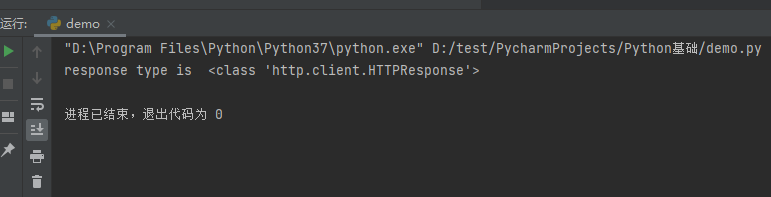
一个类型:HTTPResponse
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 一个类型 # response是HTTPResponse的类型 print('response type is ', type(response))
运行结果:
六个方法
- read(); 按照一个字节一个字节去读
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 按照一个字节一个字节的去读 content = response.read() print('response.read() is: ', content)
运行结果:

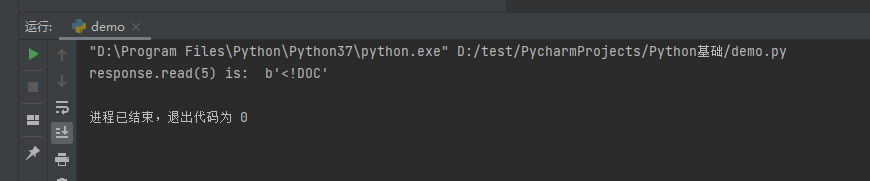
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 返回参数个字节 ##这里5表示返回5个字节 content = response.read(5) print('response.read(5) is: ', content)
运行结果:
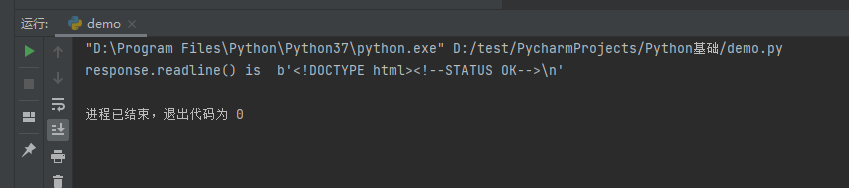
- readline():读取一行
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 读取一行 content = response.readline() print('response.readline() is ', content)
运行结果:
- readlines():读取所有行
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 读取所有行 content = response.readlines() print(type(content)) print(content)
运行结果:

- getcode(): 返回状态码
网页返回状态码的含义详细介绍 1、 1xx(临时响应)用于表示临时响应并需要请求者执行操作才能继续的状态代码。 (1)100(继续) 请求者应当继续提出请求。服务器返回此代码则意味着,服务器已收到了请求的第一部分,现正在等待接收其余部分。 (2)101(切换协议) 请求者已要求服务器切换协议,服务器已确认并准备进行切换。 2、 2xx(成功)用于表示服务器已成功处理了请求的状态代码。 (1)200(成功) 服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。如果您的 robots.txt 文件显示为此状态,那么,这表示 Googlebot 已成功检索到该文件。 (2)201(已创建) 请求成功且服务器已创建了新的资源。 (3)202(已接受) 服务器已接受了请求,但尚未对其进行处理。 (4)203(非授权信息) 服务器已成功处理了请求,但返回了可能来自另一来源的信息。 (5)204(无内容) 服务器成功处理了请求,但未返回任何内容。 (6)205(重置内容) 服务器成功处理了请求,但未返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如清除表单内容以输入新内容)。 (7)206(部分内容) 服务器成功处理了部分 GET 请求。 3、 3xx(已重定向)要完成请求,您需要进一步进行操作。通常,这些状态代码是永远重定向的。Google 建议您在每次请求时使用的重定向要少于 5 个。您可以使用网站管理员工具来查看 Googlebot 在抓取您已重定向的网页时是否会遇到问题。诊断下的抓取错误页中列出了 Googlebot 由于重定向错误而无法抓取的网址。 (1)300(多种选择) 服务器根据请求可执行多种操作。服务器可根据请求者 (User agent) 来选择一项操作,或提供操作列表供请求者选择。 (2)301(永久移动) 请求的网页已被永久移动到新位置。服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。您应使用此代码通知 Googlebot 某个网页或网站已被永久移动到新位置。 (3)302(临时移动) 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。但由于 Googlebot 会继续抓取原有位置并将其编入索引,因此您不应使用此代码来通知 Googlebot 某个页面或网站已被移动。 (4)303(查看其他位置) 当请求者应对不同的位置进行单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。 (5)304(未修改) 自从上次请求后,请求的网页未被修改过。服务器返回此响应时,不会返回网页内容。 (6)305(使用代理) 请求者只能使用代理访问请求的网页。如果服务器返回此响应,那么,服务器还会指明请求者应当使用的代理。 (7)307(临时重定向) 服务器目前正从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置。但由于 Googlebot 会继续抓取原有位置并将其编入索引,因此您不应使用此代码来通知 Googlebot 某个页面或网站已被移动。
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 返回状态码 如果是200了 那么就证明我们的逻辑没有错 print(response.getcode())
运行结果:

- geturl(): 返回的是url地址
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 返回的是url地址 print(response.geturl())
运行结果:

- getheaders(): 获取请求头信息
import urllib.request url = 'http://www.baidu.com' # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # 获取是一个状态信息 print(response.getheaders())
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号