实验4
Task1
源代码
GradeCalc.h
#pragma once
#include <vector>
#include <array>
#include <string>
class GradeCalc
{
public:
GradeCalc(const std::string& cname);
void input(int n); // 录入n个成绩
void output() const; // 输出成绩
void sort(bool ascending = false); // 排序 (默认降序)
int min() const; // 返回最低分(如成绩未录入,返回-1)
int max() const; // 返回最高分 (如成绩未录入,返回-1)
double average() const; // 返回平均分 (如成绩未录入,返回0.0)
void info(); // 输出课程成绩信息
private:
void compute(); // 成绩统计
private:
std::string course_name; // 课程名
std::vector<int> grades; // 课程成绩
std::array<int, 5> counts; // 保存各分数段人数([0, 60), [60, 70), [70, 80), [80,90), [90, 100]
std::array<double, 5> rates; // 保存各分数段人数占比
bool is_dirty; // 脏标记,记录是否成绩信息有变更
};
GradeCalc.cpp
#include "GradeCalc.h"
#include <algorithm>
#include <array>
#include <cstdlib>
#include <iomanip>
#include <iostream>
#include <numeric>
#include <string>
#include <vector>
GradeCalc::GradeCalc(const std::string& cname)
:course_name{ cname }, is_dirty{ true }
{
counts.fill(0);
rates.fill(0);
}
void GradeCalc::input(int n) {
if (n < 0) {
std::cerr << "无效输入! 人数不能为负数\n";
std::exit(1);
}
grades.reserve(n);
int grade;
for (int i = 0; i < n;) {
std::cin >> grade;
if (grade < 0 || grade > 100) {
std::cerr << "无效输入! 分数须在[0,100]\n";
continue;
}
grades.push_back(grade);
++i;
}
is_dirty = true; // 设置脏标记:成绩信息有变更
}
void GradeCalc::output() const {
for (auto grade : grades)
std::cout << grade << ' ';
std::cout << std::endl;
}
void GradeCalc::sort(bool ascending) {
if (ascending)
std::sort(grades.begin(), grades.end());
else
std::sort(grades.begin(), grades.end(), std::greater<int>());
}
int GradeCalc::min() const {
if (grades.empty())
return -1;
auto it = std::min_element(grades.begin(), grades.end());
return *it;
}
int GradeCalc::max() const {
if (grades.empty())
return -1;
auto it = std::max_element(grades.begin(), grades.end());
return *it;
}
double GradeCalc::average() const {
if (grades.empty())
return 0.0;
double avg = std::accumulate(grades.begin(), grades.end(), 0.0) / grades.size();
return avg;
}
void GradeCalc::info() {
if (is_dirty)
compute();
std::cout << "课程名称:\t" << course_name << std::endl;
std::cout << "平均分:\t" << std::fixed << std::setprecision(2) << average() << std::endl;
std::cout << "最高分:\t" << max() << std::endl;
std::cout << "最低分:\t" << min() << std::endl;
const std::array<std::string, 5> grade_range{ "[0, 60) ","[60, 70)","[70, 80)","[80, 90)","[90, 100]" };
for (int i = grade_range.size() - 1; i >= 0; --i)
std::cout << grade_range[i] << "\t: " << counts[i] << "人\t"
<< std::fixed << std::setprecision(2) << rates[i] * 100 << "%\n";
}
void GradeCalc::compute() {
if (grades.empty())
return;
counts.fill(0);
rates.fill(0.0);
// 统计各分数段人数
for (auto grade : grades) {
if (grade < 60)
++counts[0]; // [0, 60)
else if (grade < 70)
++counts[1]; // [60, 70)
else if (grade < 80)
++counts[2]; // [70, 80)
else if (grade < 90)
++counts[3]; // [80, 90)
else
++counts[4]; // [90, 100]
}
// 统计各分数段比例
for (int i = 0; i < rates.size(); ++i)
rates[i] = counts[i] * 1.0 / grades.size();
is_dirty = false; // 更新脏标记
}
demo1.cpp
#include <iostream>
#include <string>
#include "GradeCalc.h"
void test() {
GradeCalc c1("OOP");
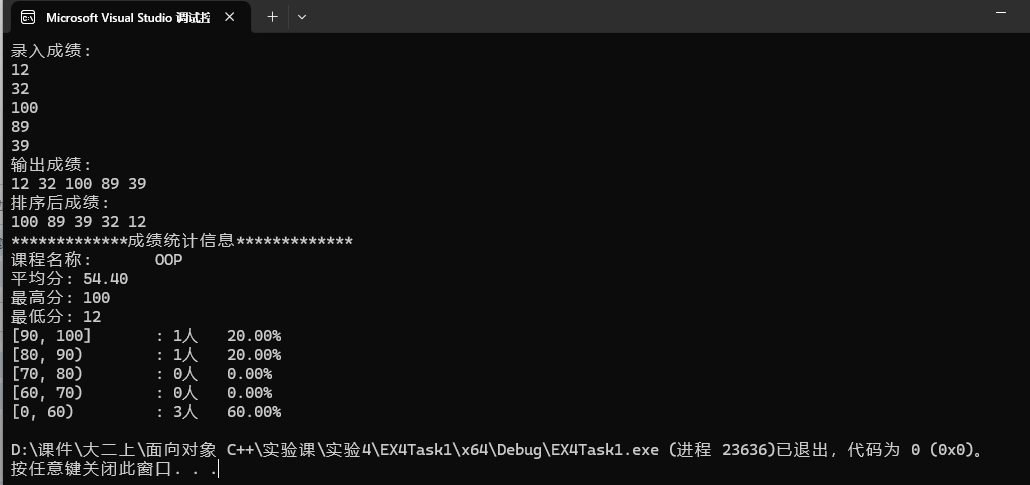
std::cout << "录入成绩:\n";
c1.input(5);
std::cout << "输出成绩:\n";
c1.output();
std::cout << "排序后成绩:\n";
c1.sort(); c1.output();
std::cout << "*************成绩统计信息*************\n";
c1.info();
//GradeCalc c("OOP");
//c.input(5);
//c.push_back(97);
}
int main() {
test();
}
测试截图
问题
问题1:组合关系识别
GradeCalc 类声明中,逐行写出所有体现"组合"关系的成员声明,并用一句话说明每个被组合对象的功能。
std::string course_name; 存储课程名称,用于标识课程
std::vector<int> grades; 动态存储多个课程成绩,支持成绩的增删改查等操作
std::array<int, 5> counts; 固定大小存储5个分数段的人数统计结果
std::array<double, 5> rates; 固定大小存储5个分数段的人数占比
bool is_dirty; 标记成绩数据是否变更,用于控制是否重新计算统计信息
问题2:接口暴露理解
如在 test 模块中这样使用,是否合法?如不合法,解释原因。
不合法
原因:push_back()函数不是c的成员函数,无法进行正常调用
问题3:架构设计分析
当前设计方案中, compute 在 info 模块中调用:
(1)连续打印3次统计信息, compute 会被调用几次?标记 is_dirty 起到什么作用?
(2)如新增 update_grade(index, new_grade) ,这种设计需要更改 compute 调用位置吗?简洁说明理由。
(1)1次 ; 当且仅当数据被修改时,is_dirty值为true,此时会调用compute()函数进行数据更新
(2)不需要 ; 只需要在update_grade(index, new_grade)函数中修改完成数据后,将is_dirty设置为true。后续在调用info()函数时会再次调用compute()函数进行重新统计
问题4:功能扩展设计
要增加"中位数"统计,不新增数据成员怎么做?在哪个函数里加?写出伪代码。
(1)不新增数据成员的要求下,可以在排序后根据索引直接进行中位数获取的操作
(2)可以在info()函数中添加
(3)在info()函数的最后添加:
if (!grades.empty()) {
std::vector<int> temp = grades; // 复制一个成绩容器
std::sort(temp.begin(), temp.end());
double a;
int size = temp.size();
if (size % 2 == 1) {
a = temp[size / 2]; // 奇数个取中间值
} else {
a = (temp[size/2 - 1] + temp[size/2]) / 2.0; // 偶数个取平均
}
std::cout << "中位数:\t" << a << std::endl;
}
问题5:数据状态管理
GradeCalc 和 compute 中都包含代码: counts.fill(0); rates.fill(0); 。
compute 中能否去掉这两行?如去掉,在哪种使用场景下会引发统计错误?
不能去掉。
当多次调用compute()函数时,counts和rates会保留上一次统计的旧数据,导致新统计结果与旧数据叠加,造成统计错误
问题6:内存管理理解
input 模块中代码 grades.reserve(n); 如果去掉:
(1)对程序功能有影响吗?(去掉重新编译、运行,观察功能是否受影响)
(2)对性能有影响吗?如有影响,用一句话陈述具体影响。
(1)无影响
(2)有。当n较大时,grades会多次进行扩容操作,这导致内存重新分配和数据拷贝的额外开销
Task2
源代码
GradeCalc.h
#pragma once
#include <array>
#include <string>
#include <vector>
class GradeCalc : private std::vector<int> {
public:
GradeCalc(const std::string& cname);
void input(int n); // 录入n个成绩
void output() const; // 输出成绩
void sort(bool ascending = false); // 排序 (默认降序)
int min() const; // 返回最低分
int max() const; // 返回最高分
double average() const; // 返回平均分
void info(); // 输出成绩统计信息
private:
void compute(); // 计算成绩统计信息
private:
std::string course_name; // 课程名
std::array<int, 5> counts; // 保存各分数段人数([0, 60), [60, 70), [70, 80), [80,90), [90, 100]
std::array<double, 5> rates; // 保存各分数段占比
bool is_dirty; // 脏标记,记录是否成绩信息有变更
};
GradeClac.cpp
#include <algorithm>
#include <array>
#include <cstdlib>
#include <iomanip>
#include <iostream>
#include <numeric>
#include <string>
#include <vector>
#include "GradeCalc.h"
GradeCalc::GradeCalc(const std::string& cname) : course_name{ cname }, is_dirty{ true } {
counts.fill(0);
rates.fill(0);
}
void GradeCalc::input(int n) {
if (n < 0) {
std::cerr << "无效输入! 人数不能为负数\n";
return;
}
this->reserve(n);
int grade;
for (int i = 0; i < n;) {
std::cin >> grade;
if (grade < 0 || grade > 100) {
std::cerr << "无效输入! 分数须在[0,100]\n";
continue;
}
this->push_back(grade);
++i;
}
is_dirty = true;
}
void GradeCalc::output() const {
for (auto grade : *this)
std::cout << grade << ' ';
std::cout << std::endl;
}
void GradeCalc::sort(bool ascending) {
if (ascending)
std::sort(this->begin(), this->end());
else
std::sort(this->begin(), this->end(), std::greater<int>());
}
int GradeCalc::min() const {
if (this->empty())
return -1;
return *std::min_element(this->begin(), this->end());
}
int GradeCalc::max() const {
if (this->empty())
return -1;
return *std::max_element(this->begin(), this->end());
}
double GradeCalc::average() const {
if (this->empty())
return 0.0;
double avg = std::accumulate(this->begin(), this->end(), 0.0) / this->size();
return avg;
}
void GradeCalc::info() {
if (is_dirty)
compute();
std::cout << "课程名称:\t" << course_name << std::endl;
std::cout << "平均分:\t" << std::fixed << std::setprecision(2) << average() <<
std::endl;
std::cout << "最高分:\t" << max() << std::endl;
std::cout << "最低分:\t" << min() << std::endl;
const std::array<std::string, 5> grade_range{ "[0, 60) ",
"[60, 70)",
"[70, 80)",
"[80, 90)",
"[90, 100]" };
for (int i = grade_range.size() - 1; i >= 0; --i)
std::cout << grade_range[i] << "\t: " << counts[i] << "人\t"
<< std::fixed << std::setprecision(2) << rates[i] * 100 << "%\n";
}
void GradeCalc::compute() {
if (this->empty())
return;
counts.fill(0);
rates.fill(0);
// 统计各分数段人数
for (int grade : *this) {
if (grade < 60)
++counts[0]; // [0, 60)
else if (grade < 70)
++counts[1]; // [60, 70)
else if (grade < 80)
++counts[2]; // [70, 80)
else if (grade < 90)
++counts[3]; // [80, 90)
else
++counts[4]; // [90, 100]
}
// 统计各分数段比例
for (int i = 0; i < rates.size(); ++i)
rates[i] = counts[i] * 1.0 / this->size();
is_dirty = false;
}
demo2
#include <iostream>
#include <string>
#include "GradeCalc.h"
void test() {
GradeCalc c1("OOP");
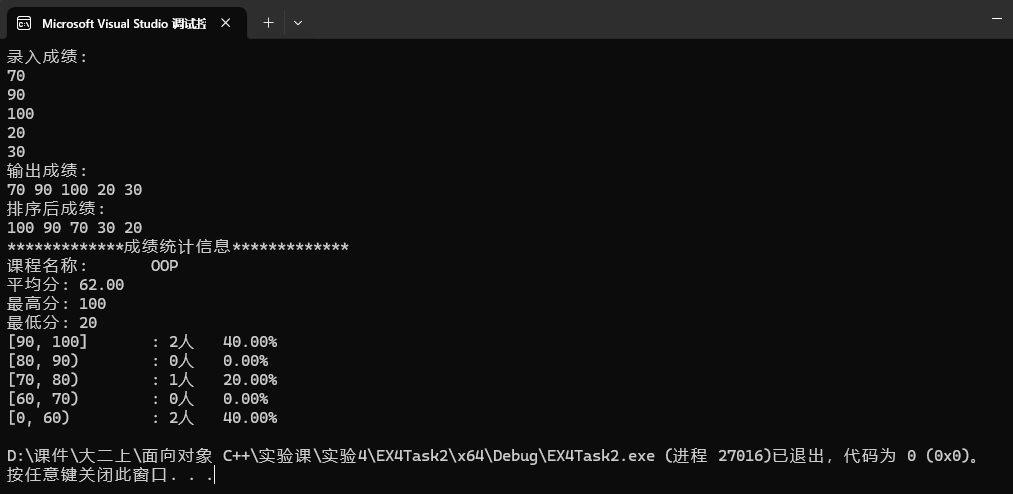
std::cout << "录入成绩:\n";
c1.input(5);
std::cout << "输出成绩:\n";
c1.output();
std::cout << "排序后成绩:\n";
c1.sort(); c1.output();
std::cout << "*************成绩统计信息*************\n";
c1.info();
}
int main() {
test();
}
测试截图
问题
问题1:继承关系识别
写出 GradeCalc 类声明体现"继承"关系的完整代码行。
class GradeCalc : private std::vector<int>
问题2:接口暴露理解
当前继承方式下,基类 vector
如在 test 模块中这样用,能否编译通过?用一句话解释原因。
(1)不会
(2)不能。GradeCalc采用private继承
问题3:数据访问差异
对比继承方式与组合方式内部实现数据访问的一行典型代码。说明两种方式下的封装差异带来的数据访问接口差异。
继承:直接复用基类的接口
组合:通过成员变量调用其接口
问题4:组合 vs. 继承方案选择
你认为组合方案和继承方案,哪个更适合成绩计算这个问题场景?简洁陈述你的结论和理由。
组合
GradeCalc类与vector是“has-a”的关系,而不是一个“is-a”的关系
Task3
源代码
Graph.h
#pragma once
#include <string>
#include <vector>
enum class GraphType { circle, triangle, rectangle };
class Graph
{
public:
virtual void draw() {}
virtual ~Graph() = default;
};
// Circle类声明
class Circle : public Graph {
public:
void draw();
};
// Triangle类声明
class Triangle : public Graph {
public:
void draw();
};
// Rectangle类声明
class Rectangle : public Graph {
public:
void draw();
};
// Canvas类声明
class Canvas {
public:
void add(const std::string& type); // 根据字符串添加图形
void paint() const; // 使用统一接口绘制所有图形
~Canvas(); // 手动释放资源
private:
std::vector<Graph*> graphs;
};
// 4. 工具函数
GraphType str_to_GraphType(const std::string& s); // 字符串转枚举类型
Graph* make_graph(const std::string& type); // 创建图形,返回堆对象指针
Graph.cpp
#include <algorithm>
#include <cctype>
#include <iostream>
#include <string>
#include "Graph.h"
// Circle类实现
void Circle::draw() { std::cout << "draw a circle...\n"; }
// Triangle类实现
void Triangle::draw() { std::cout << "draw a triangle...\n"; }
// Rectangle类实现
void Rectangle::draw() { std::cout << "draw a rectangle...\n"; }
// Canvas类实现
void Canvas::add(const std::string& type) {
Graph* g = make_graph(type);
if (g)
graphs.push_back(g);
}
void Canvas::paint() const {
for (Graph* g : graphs)
g->draw();
}
Canvas::~Canvas() {
for (Graph* g : graphs)
delete g;
}
// 工具函数实现
// 字符串 → 枚举转换
GraphType str_to_GraphType(const std::string& s) {
std::string t = s;
std::transform(s.begin(), s.end(), t.begin(),
[](unsigned char c) { return std::tolower(c); });
if (t == "circle")
return GraphType::circle;
if (t == "triangle")
return GraphType::triangle;
if (t == "rectangle")
return GraphType::rectangle;
return GraphType::circle; // 缺省返回
}
// 创建图形,返回堆对象指针
Graph* make_graph(const std::string& type) {
switch (str_to_GraphType(type)) {
case GraphType::circle: return new Circle;
case GraphType::triangle: return new Triangle;
case GraphType::rectangle: return new Rectangle;
default: return nullptr;
}
}
demo3.cpp
#include <string>
#include "Graph.h"
void test() {
Canvas canvas;
canvas.add("circle");
canvas.add("triangle");
canvas.add("rectangle");
canvas.paint();
}
int main() {
test();
}
测试截图

问题
问题1:对象关系识别
(1)写出Graph.hpp中体现"组合"关系的成员声明代码行,并用一句话说明被组合对象的功能。
(2)写出Graph.hpp中体现"继承"关系的类声明代码行。
(1)组合:std::vector<Graph*> graphs;
(2)继承:
class Circle : public Graph
class Triangle : public Graph
class Rectangle : public Graph
问题2:多态机制观察
(1) Graph 中的 draw 若未声明成虚函数, Canvas::paint() 中 g->draw() 运行结果会有何不同?
(2)若 Canvas 类 std::vector<Graph*> 改成 std::vector
(3)若 ~Graph() 未声明成虚函数,会带来什么问题?
(1)无论g指向哪个派生类对象,都会调用基类Graph中的draw()
(2)始终调用Graph::draw(),无法调用派生类中的draw()函数
(3)只会调用基类的析构函数,而不会去调用派生类的析构函数。在通过基类指针删除派生类对象时,因此会导致内存泄露或者资源未释放
问题3:扩展性思考
若要新增星形 Star ,需在哪些文件做哪些改动?逐一列出。
(1)Graph.h文件:
修改GraphType枚举:
enum class GraphType { circle, triangle, rectangle, star };
新增Star类声明:
class Star : public Graph {
public:
void draw();
};
(2)Graph.cpp文件:
实现Star::draw():
void Star::draw() {
std::cout << "draw a circle...\n" << std::endl;
}
扩展str_to_GraphType()函数:
GraphType str_to_GraphType(const std::string& s) {
if (s == "circle") return GraphType::circle;
else if (s == "triangle") return GraphType::triangle;
else if (s == "rectangle") return GraphType::rectangle;
else if (s == "star") return GraphType::star; // 新增
else throw std::invalid_argument("Unknown graph type");
}
扩展make_graph()函数:
Graph* make_graph(const std::string& type) {
GraphType gt = str_to_GraphType(type);
switch (gt) {
case GraphType::circle: return new Circle();
case GraphType::triangle: return new Triangle();
case GraphType::rectangle: return new Rectangle();
case GraphType::star: return new Star(); // 新增
default: throw std::invalid_argument("Unsupported graph type");
}
}
问题4:资源管理
观察 make_graph 函数和 Canvas 析构函数:
(1) make_graph 返回的对象在什么地方被释放?
(2)使用原始指针管理内存有何利弊?
(1)在Canvas的析构函数中,遍历graphs向量,通过delete g释放每个Graph*指向的对象(delete g会调用正确的派生类的析构函数)
(2)优点:灵活性更高;无需额外的内存
缺点:必须手动释放内存,否则会导致内存泄露
Task4
源代码
Toy.h
#pragma once
#include <string>
#include <iostream>
#include <vector>
#include <memory>
class SpecialAbility {
public:
virtual ~SpecialAbility() = default;
virtual std::string performAbility() const = 0;
};
class Toy : public SpecialAbility {
protected:
std::string name;
std::string type;
double money;
public:
Toy(const std::string& name, const std::string& type, double money);
virtual ~Toy() = default;
std::string getName() const;
std::string getType() const;
double getMoney() const;
virtual std::string performAbility() const = 0; // 纯虚函数
};
//类Plush的实现
class Plush : public Toy {
public:
Plush(const std::string& name, double money);
std::string performAbility() const override;
};
//类Robot的实现
class Robot : public Toy {
public:
Robot(const std::string& name, double money);
std::string performAbility() const override;
};
class ToyFactory {
private:
std::vector<std::unique_ptr<Toy>> toys;
public:
void addToy(std::unique_ptr<Toy> toy);
void displayToys() const;
};
Toy.cpp
#include "Toy.h"
//Toy
Toy::Toy(const std::string& name, const std::string& type, double money)
: name(name), type(type), money(money) {
}
std::string Toy::getName() const {
return name;
}
std::string Toy::getType() const {
return type;
}
double Toy::getMoney() const {
return money;
}
std::string Toy::performAbility() const {
return "This toy has a special ability!";
}
//Plush
Plush::Plush(const std::string& name, double money)
: Toy(name, "Plush", money) {
}
std::string Plush::performAbility() const {
return getName() + " is a soft plush toy! ";
}
//Robot
Robot::Robot(const std::string& name, double money)
: Toy(name, "Robot", money) {
}
std::string Robot::performAbility() const {
return "The robot is moving!";
}
//ToyFactory
void ToyFactory::addToy(std::unique_ptr<Toy> toy) {
toys.push_back(std::move(toy));
}
void ToyFactory::displayToys() const {
for (const auto& toy : toys) {
std::cout << "Name: " << toy->getName()
<< ", Type: " << toy->getType()
<< ", Price: $" << toy->getMoney()
<< ", Ability: " << toy->performAbility()
<< std::endl;
}
}
demo4.cpp
#include "Toy.h"
#include <memory>
int main() {
ToyFactory factory;
// 使用 std::make_unique 创建 Plush 和 Robot 对象
factory.addToy(std::make_unique<Plush>("Cat", 19.99));
factory.addToy(std::make_unique<Robot>("Dog", 49.99));
factory.displayToys();
return 0;
}
测试截图

场景描述
根据玩具的名称和金额,输出玩具的类别和特异功能
各类的关系
Toy继承SpecialAbility,Plush和Robot继承Toy
SpecialAbility和Toy都是抽象类。纯虚函数在Plush和Robot类中实现
ToyFactory与Toy是组合关系,是has-a的关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号