OpenCL [00] 起步
OpenCL [00] 起步
本系列博客为作者本人在学习 OpenCL 过程中的笔记与思考,并希望在这个过程中能够帮助更多对高性能计算(HPC)与异构计算感兴趣的同仁了解、学习、掌握 OpenCL,或者起到抛砖引玉的作用,引发读者思考。因为本人能力、精力有限,在编写本博文的过程中势必会有错谬之处,诚恳地希望各位读者能不吝赐教、指点斧正,感激不尽。
OpenCL(Open Computing Language,开放计算语言)是一个为异构平台编写程序的框架,此异构平台可由CPU、GPU、DSP、FPGA或其他类型的处理器与硬体加速器所组成。[1]
OpenCL 由非盈利组织 Khronos 维护。本篇博客「从 OpenCL 官方教程开始」基于 github 上的 Khronos 官方教程 OpenCL-Guide 编写。
什么是 OpenCL
在「End of Moore's Law」时代,如何更加充分地利用被物理定律限制住了的硬件资源、“榨取” 更多性能以满足日益增长的工业需求,变成一个越来越重要的问题。Khronos 维护了一系列与并行计算有关的标准,在这个领域做出了很多努力:
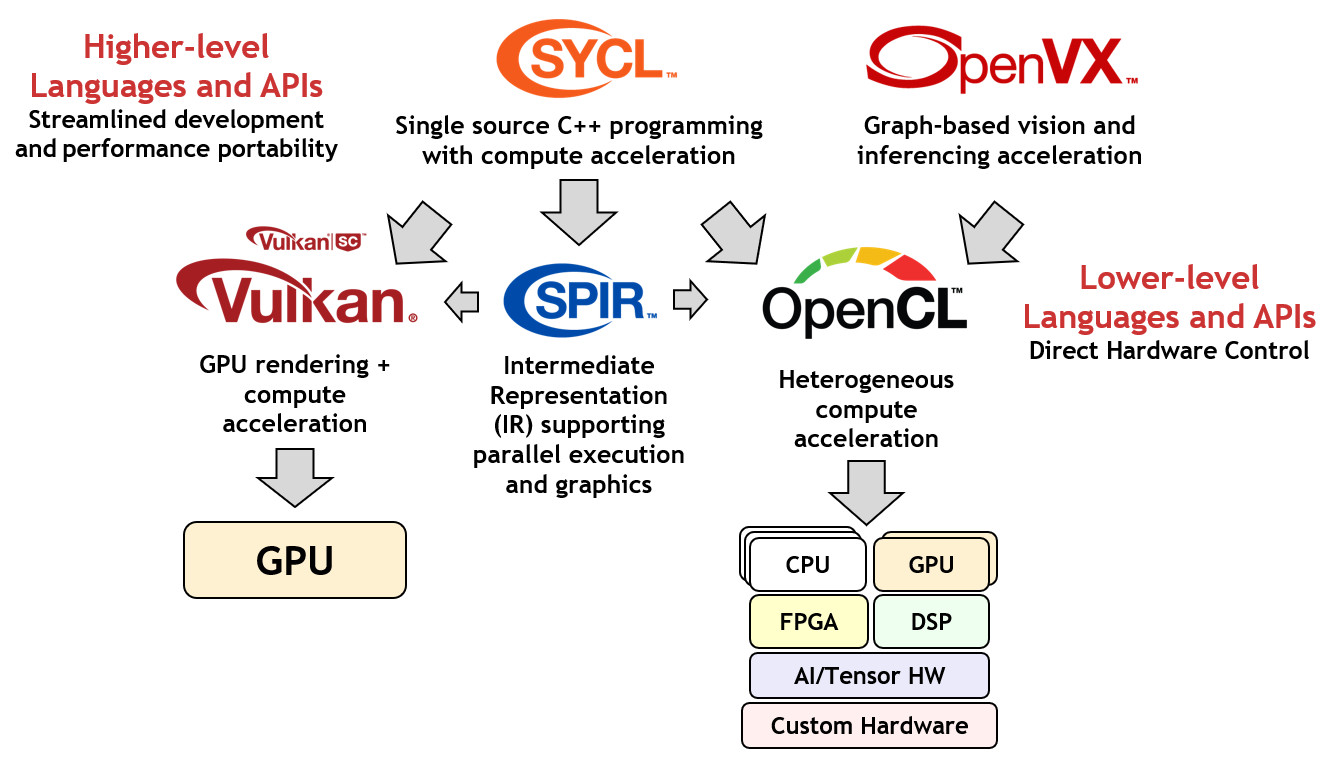
OpenCL(Open Computing Language,开放计算语言)是一个为异构平台编写程序的框架,此异构平台可由CPU、GPU、DSP、FPGA或其他类型的处理器与硬体加速器所组成。[1:1]
-
OpenCL 是一个标准,而非具体实现。例如,C语言有C89、C99等标准,而GNU/GCC、VS、Clang等提供了标准的实现,并提供了各自的扩展。
-
OpenCL是一个异构的平台。「异构」意味相同的代码可以在多种设备上运行(但是并 没有保证可以有相同的性能)。和 OpenCL 类似的一个并行计算框架 CUDA 就非异构,而只服务于 Nvidia 一家的显卡。
-
OpenCL 是一个并行计算语言,是在 GNU C/C++ 的子集上上添加最小化语义扩展的一个语言。使用 OpenCL 的程序能利用其并行计算能力提高性能。
工业上广泛使用 OpenCL,并有许多硬件产商支持 OpenCL。[2] 近些年来,随着深度学习的发展,由于 OpenCL 出色的加速能力与可移植性,它逐渐在被用在各种机器学习栈上,在缺乏 GPU 的场景(无法使用或者处于成本考量不使用GPU的地方)上大放异彩。
OpenCL运行原理
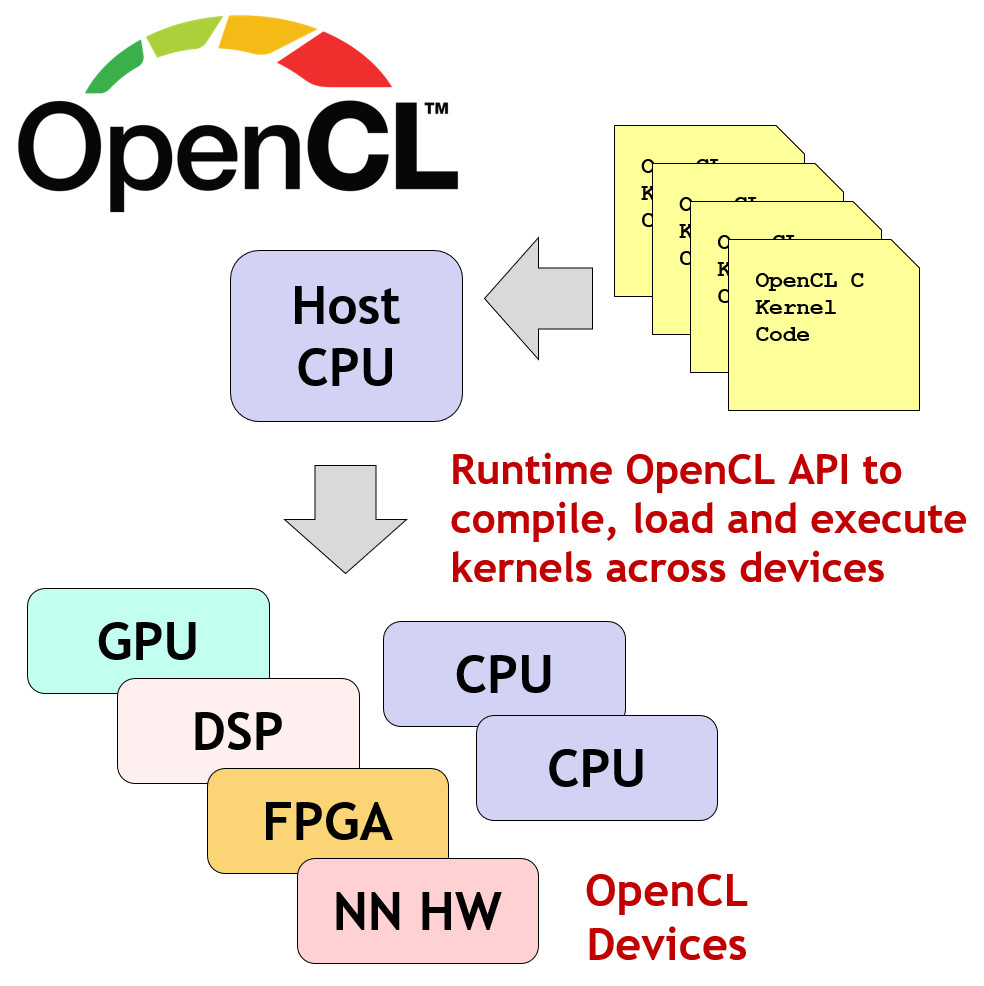
OpenCL 提供了一个编程框架(即上述的「C/C++子集上的最小语义扩展」)与运行时,由此支撑了一个概念:kernel。
kernel是一个 小型 的程序,能在 各种并行加速设备 上运行。
一个程序中有大量的可并行的部分,如果将它们抽离出来、并行执行,那么就可以最大限度利用设备的资源、实现加速程序运行的目的——当然这个加速也不是无止境的,遵循 Amdahl's Law,并与问题规模、并行实现代价有关。举个最浅显的例子,一个人抄写一百页书的速度一定不如一百个人同时抄写各自的那一页来得快。
OpenCL 之所以被称之为 「异构」计算语言,是由于它的 kernel 能在各种硬件设备上运行。而 CUDA 的 kernel 就只能在 Nvidia 的设备上运行。
OpenCL 提供两套 API,分别是 「Platform Layer API」与 「Runtime API」:
-
Platform Layer API:这套 API 运行所谓的
host CPU上,它用于:- 探测可用的并行处理器或加速计算设备
- 选择、初始化之后运行
kernel的计算设备
-
Runtime API:这套 API 用于支持
kernel运行,它用于:- 编译
kernel程序 - 将编译好的程序载入到设备并运行
- 收集运行结果
- 编译
同样的,一个 OpenCL 程序分为 host code 与 device kernel。host code 和普通的 C/C++ 程序一样(也可以使用 python binding 等),而 device code 就是 kernel 部分,可以在 OpenCL 程序运行时再使用 Runtime API 编译、链接。
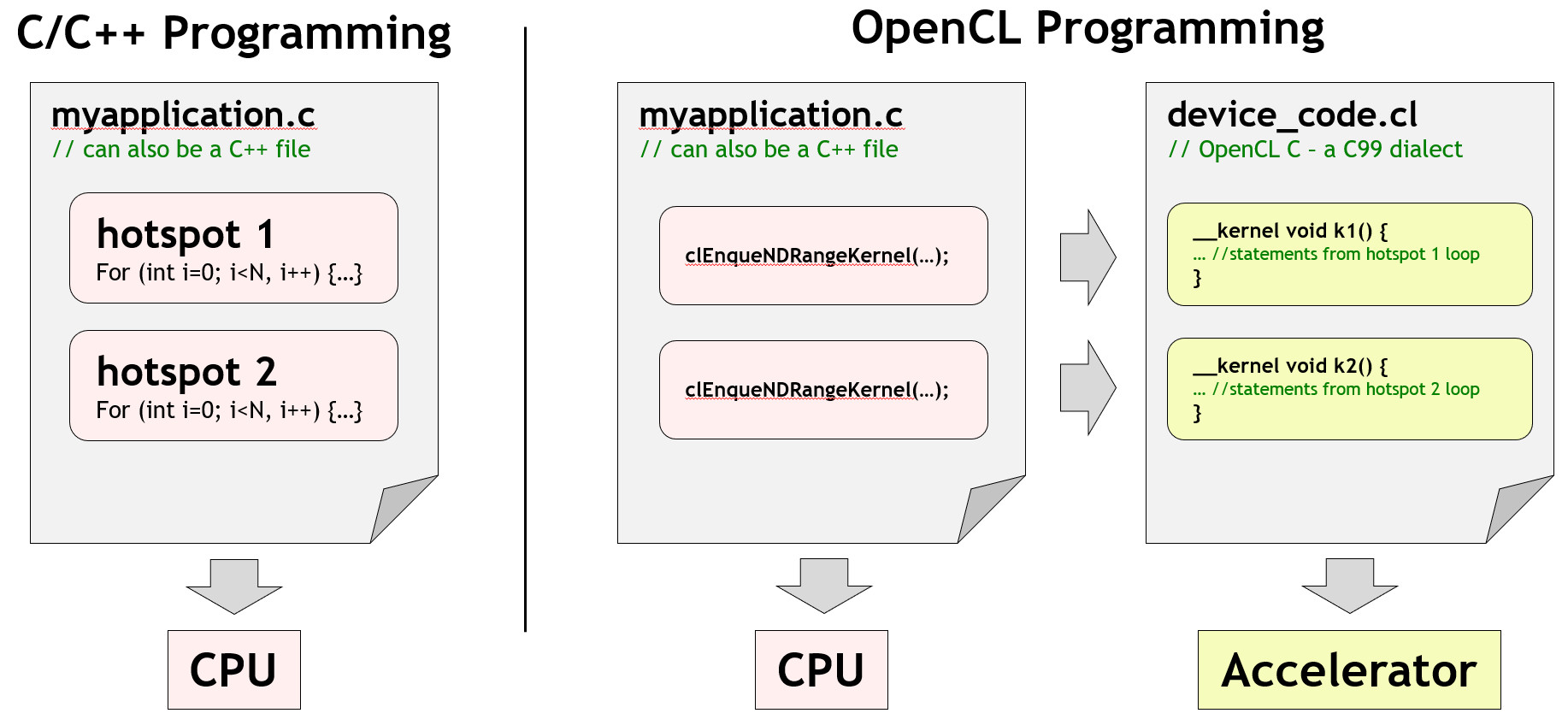
OpenCL3.0 引入了很多 C++17 的特性。通常可以使用 C/C++ 编写 kernel。当其他语言需要使用 OpenCL 时,可以先将其他语言的并行部分编译为 SPIR-V 作为中间表示,再传入 OpenCL,进行加速。
作为底层编程框架,OpenCL 需要工程师显式控制 kernel 运行、内存分配、CPU 同步等低级内容。
编程模型
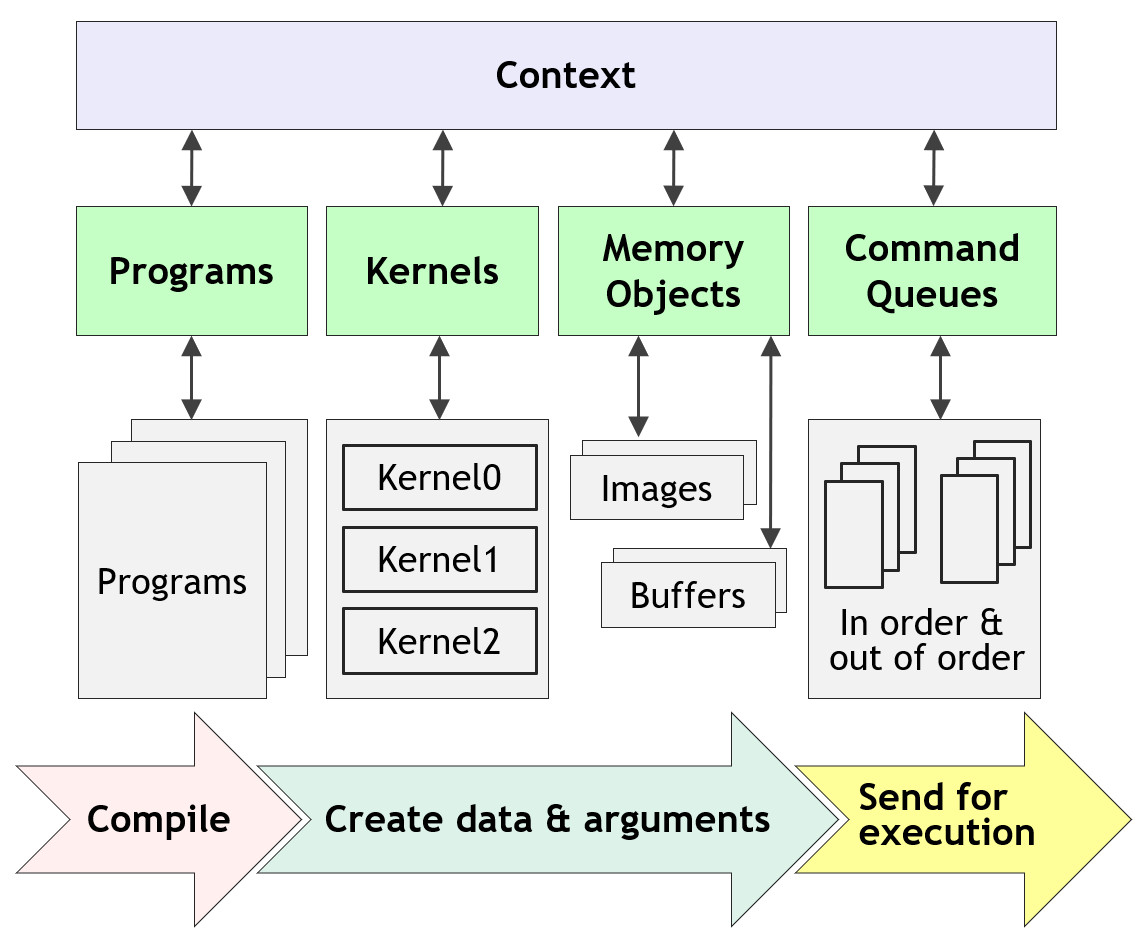
kernel:OpenCL 程序的基本执行单元,类似于C语言中函数的的概念(事实上编写kernel程序就是编写完成各种小任务的函数),使用 SIMD(Single Instruction Multiple Data)或 SPMD(Single Program Multiple Data)的方式并行;program:是kernel和一系列函数的集合。为了满足异构要求,kernel可以在运行时编译、链接;image:OpenCL特有的数据组织方式,对程序员不透明,对矩阵运算和图像操作做了硬件特定的优化。内存可能不连续;buffer:与C语言中使用malloc申请的数组类似,存储对象为连续数组。内存连续,主要用于一维数组;memory object:由image和buffer组成;command queue:是Platform Layer API的一部分,用于将kernel发送到设备上、在设备和CPU间传输数据。对一个command queue使用enqueueing命令后,该队列上的kernel将开始异步地在并行加速设备上运行。这些kernel可以以in-order和out-of-order的方式执行;context:记录、管理上述内容;platform:意味 OpenCL 的各种不同实现;device:各种可以用于加速的设备,比如GPU、FPGA等,甚至CPU本身;
执行模型
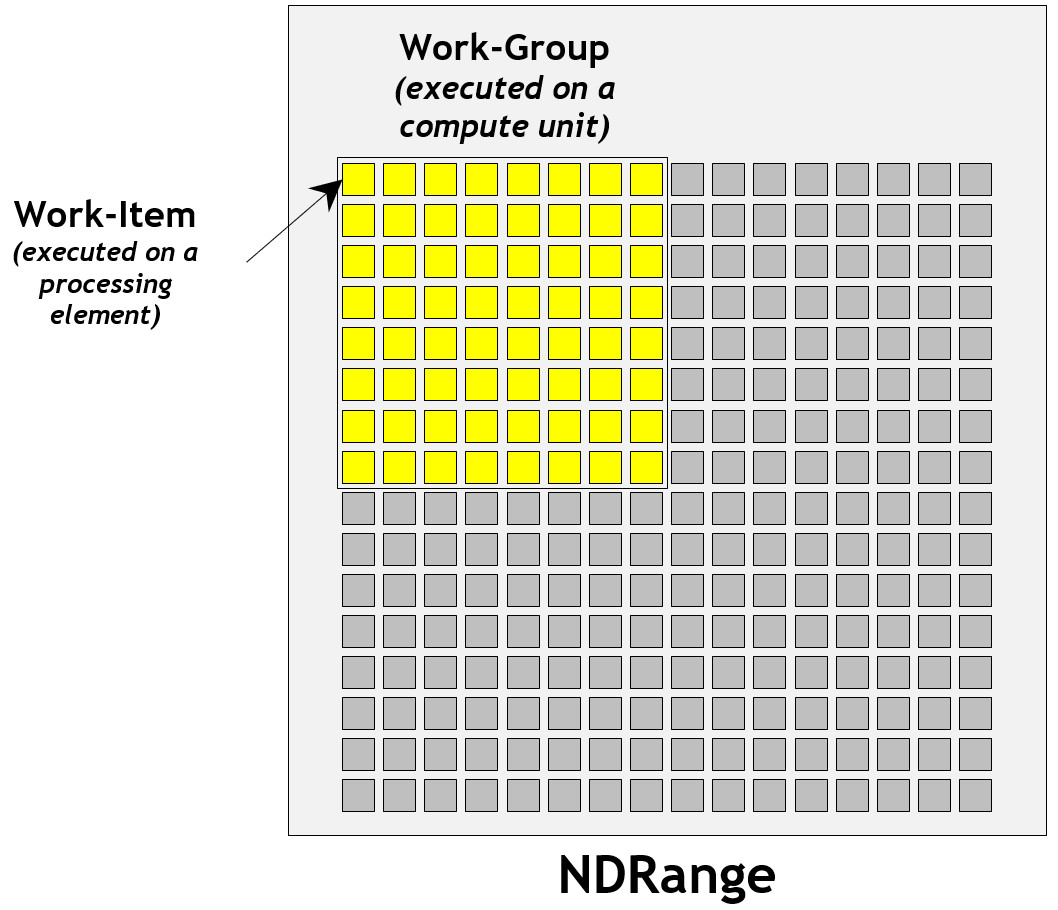
使用 clEnqueueNDRangeKernel 命令来运行一个有着 N 维数据结构的 kernel 程序。而 work-item 则是一个 kernel 运行的数据大小。例如,N=1时,work-item就是一维数组上的一个元素;N=2时,work-item就是二维图像上的一个像素点。
处理器通常是一次性执行一批 work-item 的。因此,另一个术语 work-group 用来描述一组 work-items。这些 wrok-items 共享 local memory,使用 work-group barriers 进行同步也更加容易。在使用 clEnqueueNDRangfeKernel 时,需要指定单个 work-group 的大小。
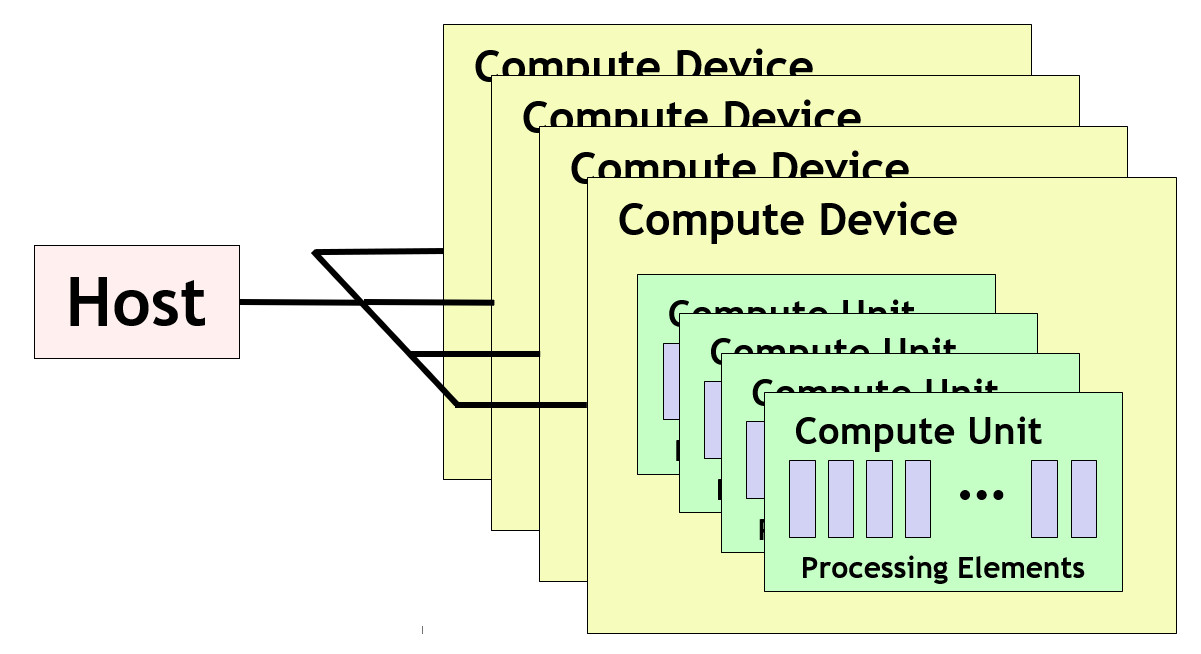
一个设备上有一个或者多个 compute unite,而一个 compute unite 上有一个或者多个 processing element。一个典型的例子是,设备 GPU 上有多个 compute unit: SM(streaming multiprocessors),一个 SM 上有多个 SP (streaming processors)。多个独立的小型 processing elements 聚合为一个 compute unit,目的就是为了更好地进行同步、内存共享等。
一个 work-item 运行在一个 processing element 上,一个 work-group 运行在一个 compute unit 上。
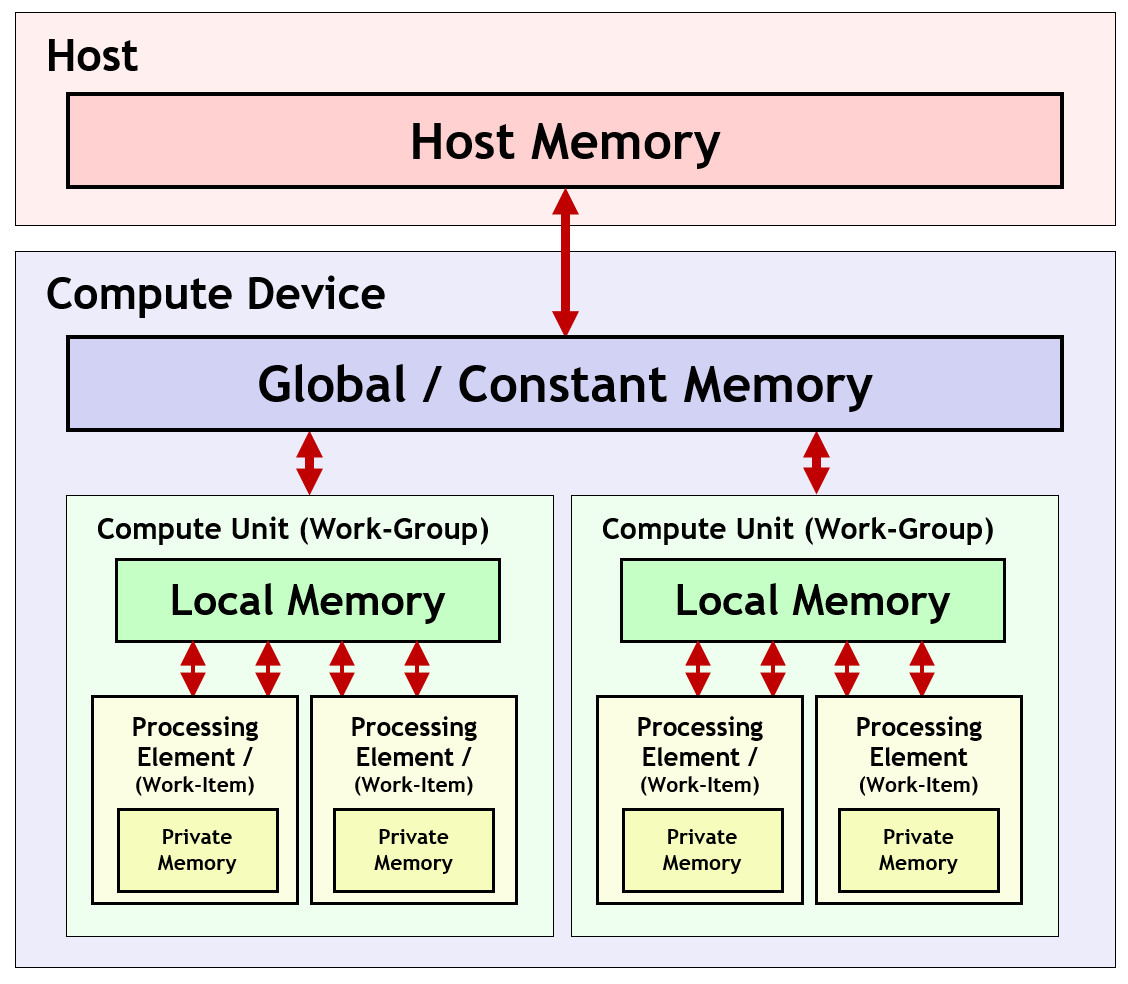
内存模型
OpenCL 的内存层级:
- host:CPU使用的内存
- global/constant:一个设备上的所有 computing unit 可见
- local:一个 computing unit 运行的所有 processing element 可见
- private:单个处理单元可见
运行步骤
一个完成的 OpenCL 程序运行步骤为:
- 探测可用的
platforms和devices - 为一个
platforms上的device(s)创建context - 创建、编译一个
program(即编译、链接kernel) - 选择需要执行的
kernel - 创建
memory objects - 创建
command queue(s) - 开始传输数据、运行
kernel(即Enqueue) - 收集、同步运行结果
Offline Compilation
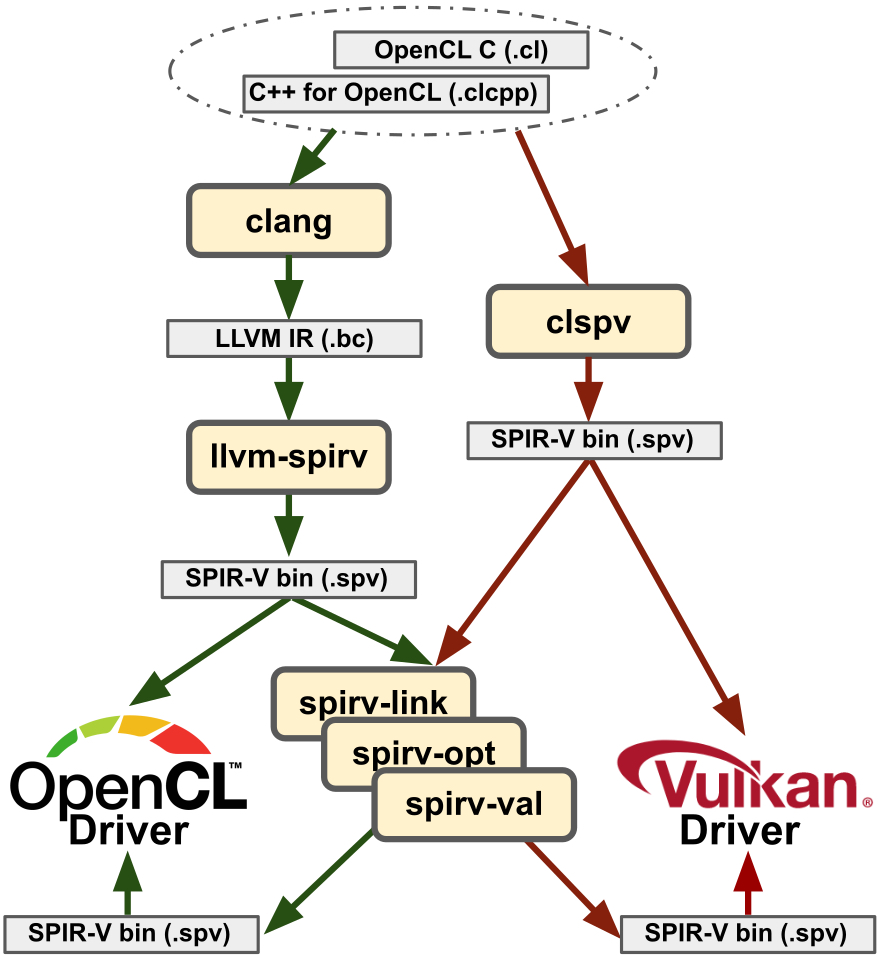
OpenCL 支持 Offline Compilation,即在事先编译好 kernel,到程序运行时不需要再次编译、直接载入即可。这样子,程序运行时就省下了编译kernel的时间。
有两种方法能实现 Offlien Compilation:
- 曾经 Online 编译过的
kernel将被缓存,第二次运行程序时将不再再次编译、而是直接调用缓存的kernel二进制。使用clGetProgramInfo接口也可以获取二进制文件 - 在执行程序前使用离线编译器编译
kernel,程序运行时载入即可
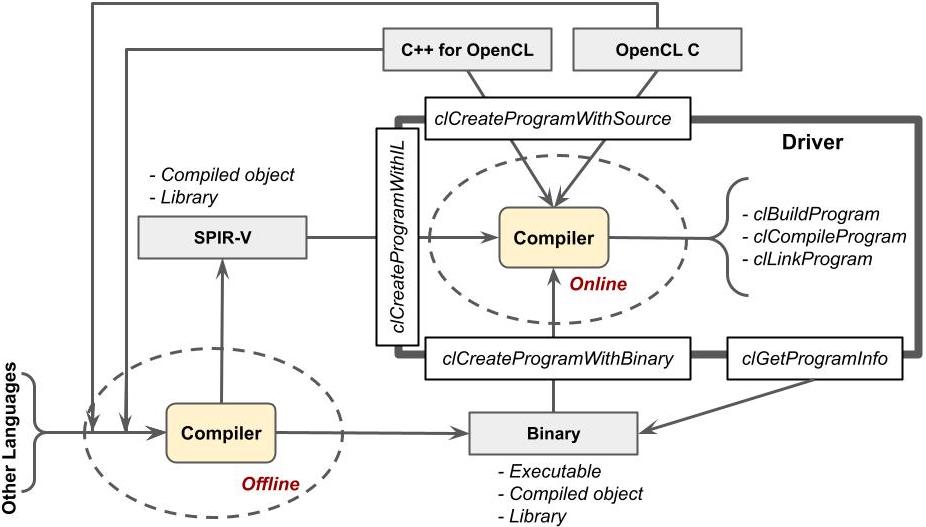
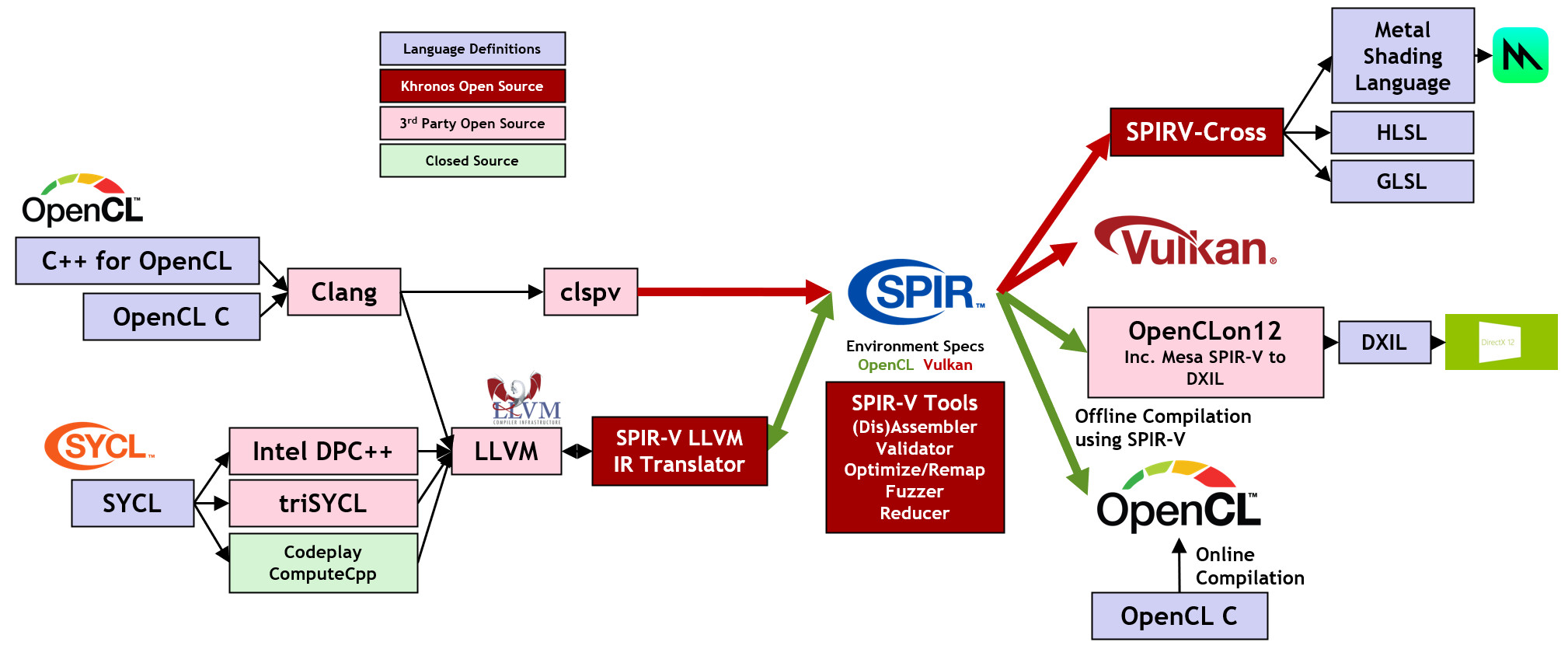
SPIR-V 是 Khronos 定义的一种和并行计算有关的中间表示。曾经的 OpenCL 都是直接使用缓存的 kernel 二进制实现 Offline Compilation 的,但是这种做法产生的二进制文件设备强关联,移植性很差。添加了 SPIR-V 后,其他语言也可以通过产生 SPIR-V 来编写 kernel。到目前为止,SPIR-V 的生态已经很完善了:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号