
wcPro--WordCount扩展
Github:https://github.com/whoNamedCody/wcPro
PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
10 | 10 |
|
· Estimate |
· 估计这个任务需要多少时间 |
40 | 50 |
|
Development |
开发 |
30 | 35 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
20 | 25 |
|
· Design Spec |
· 生成设计文档 |
20 | 20 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
10 | 10 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
40 | 45 |
|
· Design |
· 具体设计 |
20 | 25 |
|
· Coding |
· 具体编码 |
30 | 50 |
|
· Code Review |
· 代码复审 |
20 | 30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
10 | 15 |
|
Reporting |
报告 |
40 | 50 |
|
· Test Report |
· 测试报告 |
40 | 45 |
|
· Size Measurement |
· 计算工作量 |
10 | 15 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
10 | 20 |
|
合计 |
350 | 445 |
基本任务:
1、接口说明:
获取输入模块分析得到的字符文本:public void setFileContext(String fileContext);
供输出模块获取分析并排序好的单词list: public ArrayList<String> getWords();
供输出模块获取排序好的单词个数list:public ArrayList<Integer> getWordsNum();
2、核心模块设计思路:
首先规定了如上接口,根据上面方法可知我的核心类是标准的java类,对外只提供get()和set()方法作为接口,我觉得java作为面对对象的典型语言,这样封装是一个很好的编程习惯。其次谈一谈算法思路,一开始想用正则表达式判定的,后来一想不如自己写判断,算是对自己的一个锻炼。
审题可知数字和除‘-’外的字符都不能算在单词里,所以分割文本内容时就数字和这些字符,当然这样分割出来就有一些包括‘-’字符,其中很大一部分是对‘-’的判定。对‘-’处理时我取名为“头尾截除”,每当‘-’出现在分割后字符串的首尾时就去除,这样就使‘-word-’和‘word’是同一个单词了。这样分割出来得到原始的单词list,统计单词词频只需要统计在这个list里出现的次数。单词一个list,词频一个list,再对词频进行排序,具体的实现就不说了。
当然,这个思路也很简单,期待有更优的思路。
3、设计测试用例的思路:
覆盖所有能考虑到的可能出错的情况,模块内测试采用白盒测试,包括对判定的测试、等价类测试和边界测试,模块间测试因为不易观察内部细节,可以采用黑盒测试,及测试模块间接口包括输入和输出。就我负责的核心模块而言,我设计测试用例的思路是,对判定的测试,测试哪些是单词,哪些不是单词,等价类测试,划分等价类,如’software‘和’cotnent’是一类测试,边界测试,这里不得不提的是‘-’字符,这个字符在单词间时表示的连接起来的是一个单词,在首尾时不记入单词,这里就需要对这种情况进行边界测试,另外如‘ “I’和‘ Let's’也需要进行这种边界测试。
测试基本单词:software
测试‘-’字符:content-based、-、-content-
测试特殊情况:Let's、“I
测试数字情况:TABLE1-2、12TABLE1-2
测试特殊字符:;'"~!(){}\1233",\";
其他测试为基本测试的混合测试,不在一一列举,下面为测试用例表
右击在新标签页打开查看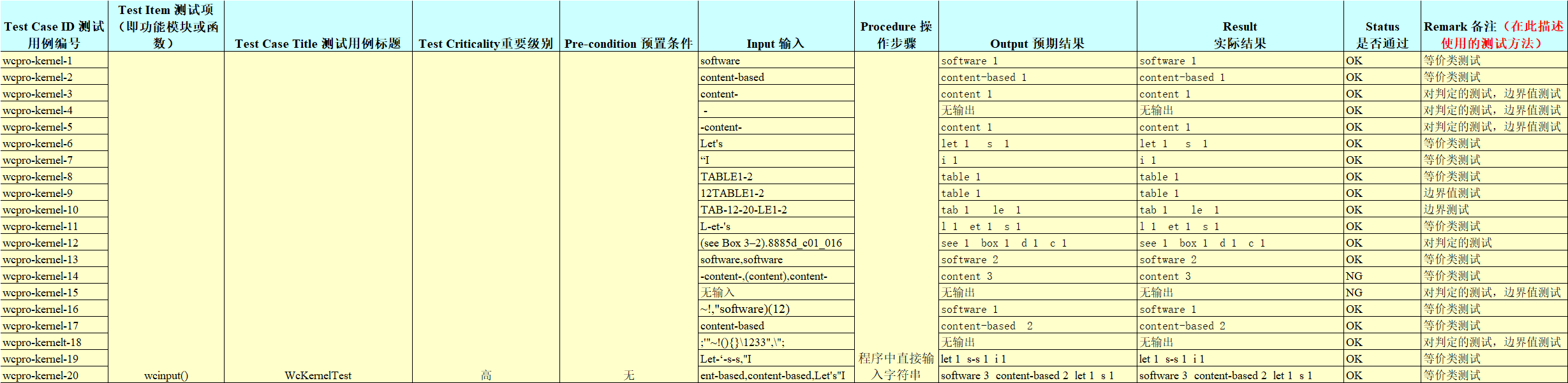
4、评价测试质量和被测模块的质量
单元测试:
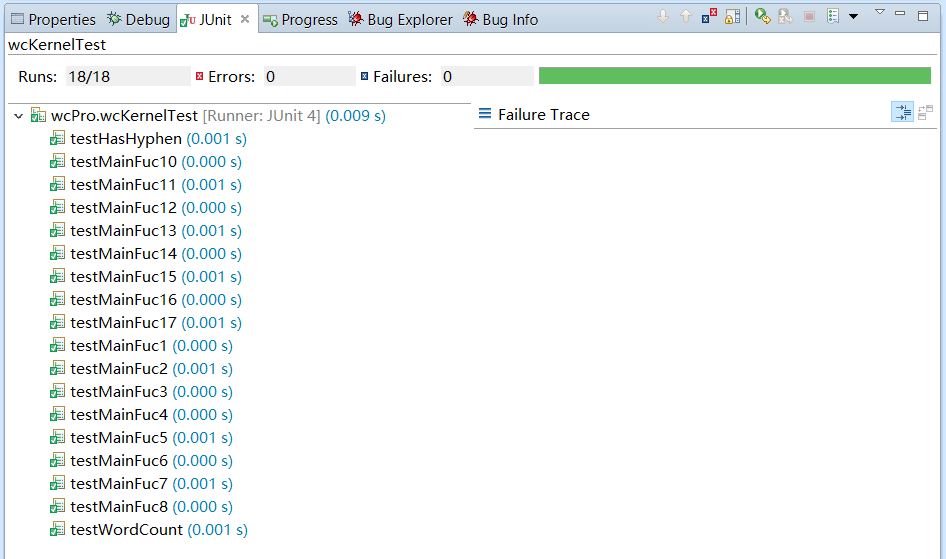
这是我写的核心模块,根据上面单元测试结果看,效率还不错,感觉核心模块最耗时的是单词排序和词频排序,这里用了几个循环,有关I/O的在输入和输出模块,故只需考虑内部编码,平均测试时间为9ms,这个结果应该不错,当然可能是测试文本文件不够大,也期待能继续改进。实现更优的结果。
5、小组贡献度:
17039 25% 17040 25% 17048 25% 17050 25%
扩展任务:
1、开发规范文档:
2、分析的是17050的输出模块:
问题:
1)封装:函数使用静态函数,完全丢弃了面向对象的编程风格。按照标准,标准的java类应该包括私有变量,构造方法,get()和set()方法作为接口。
2)变量:部分变量没有实际意义,使得读代码的人不能很清楚地明白代码的含义。
3)冗长:代码太过冗长,例如连续大量使用if...else...,使得程序结构变得复杂,降低了代码的可读性。
4)缩进:在上述开发规范文档中,缩进是4个空格,但是输出模块的代码缩进比较混乱。
5)注释:规范的注释是英文注释,但是在输出模块中使用的是中文,这是不合规范的。
6)效率:代码中for循环用的过多了,肯定会增加时间复杂度。
输出模块代码:
1 package wcPro; 2 import java.io.*; 3 import java.util.ArrayList; 4 5 6 public class wcOutput 7 { 8 public static void output(ArrayList<String> word,ArrayList<Integer> wordFreq) 9 { 10 int out; 11 int length;int serial=0; 12 PrintWriter writer=null; 13 try { 14 //输出数组元素个数大于100时只输出前100个 15 if(wordFreq.size()>100) out=100; 16 //否则按实际个数输出 17 else out = wordFreq.size(); 18 19 //词频相等时排序处理 20 String temp = ""; 21 for(int i=0;i<wordFreq.size();i++) 22 for(int j=i+1;j<wordFreq.size();j++) 23 { 24 //在比较的两个单词中取最短的长度 25 if(word.get(i).length()<word.get(j).length()) length = word.get(i).length(); 26 else length = word.get(j).length(); 27 //词频相等时进行排序 28 if(wordFreq.get(i)==wordFreq.get(j)) 29 { 30 for(;serial<length;serial++)//单词一位一位比较 31 { 32 //当前一个单词的某位字母小于后一个单词的对应位字母时,不改变原顺序 33 if(word.get(i).charAt(serial)<word.get(j).charAt(serial)) 34 break; 35 //当前一个单词的某位字母等于后一个单词的对应位字母时,继续比较下一位字母 36 else if(word.get(i).charAt(serial)==word.get(j).charAt(serial)) 37 continue; 38 //当前一个单词的某位字母大于后一个单词的对应位字母时,交换两个单词的顺序 39 else if(word.get(i).charAt(serial)>word.get(j).charAt(serial)) 40 { 41 temp = word.get(i); 42 word.set(i,word.get(j)); 43 word.set(j, temp); 44 break; 45 } 46 } 47 //当某一个单词里的字母已经比较完了仍没有结果 48 if(serial==length) 49 { 50 if(word.get(i).length()<word.get(j).length()) ; 51 //单词长的放后面 52 else 53 { 54 temp = word.get(i); 55 word.set(i,word.get(j)); 56 word.set(j, temp); 57 } 58 } 59 serial=0; 60 } 61 //词频不等时打破内层循环(该单词不会再与后面单词相等),从外层循环继续 62 else 63 break; 64 } 65 66 writer=new PrintWriter(new BufferedOutputStream(new FileOutputStream("result.txt"))); 67 if(word.size()!=wordFreq.size()) 68 System.out.println("Error handle!"); 69 else {//程序的输出口 70 for(int i=0;i<out;i++){ 71 writer.write(word.get(i)+"\t"+wordFreq.get(i)+"\r\n"); 72 System.out.println(word.get(i)+"\t"+wordFreq.get(i)); 73 } 74 } 75 writer.flush(); 76 } catch (Exception e) { 77 System.out.println("Error in output"); 78 }finally{ 79 if(writer!=null) 80 writer.close(); 81 } 82 } 83 }
3、选择工具:FindBugs
下载地址:http://findbugs.sourceforge.net/
4、运行截图及分析:
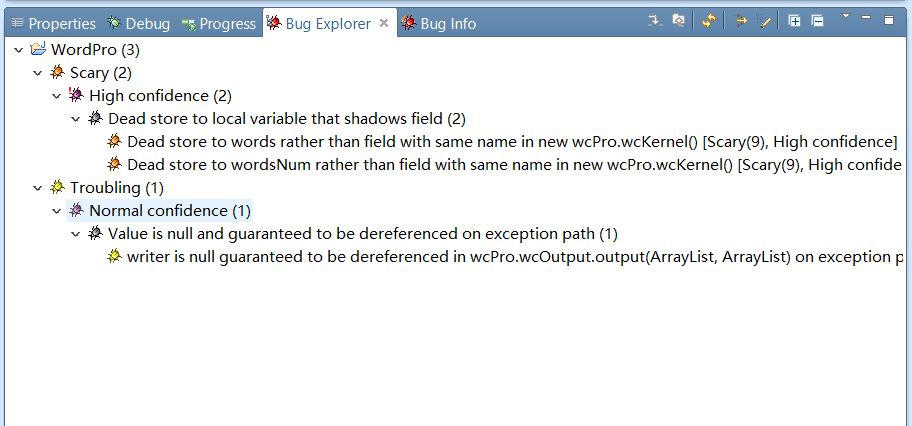
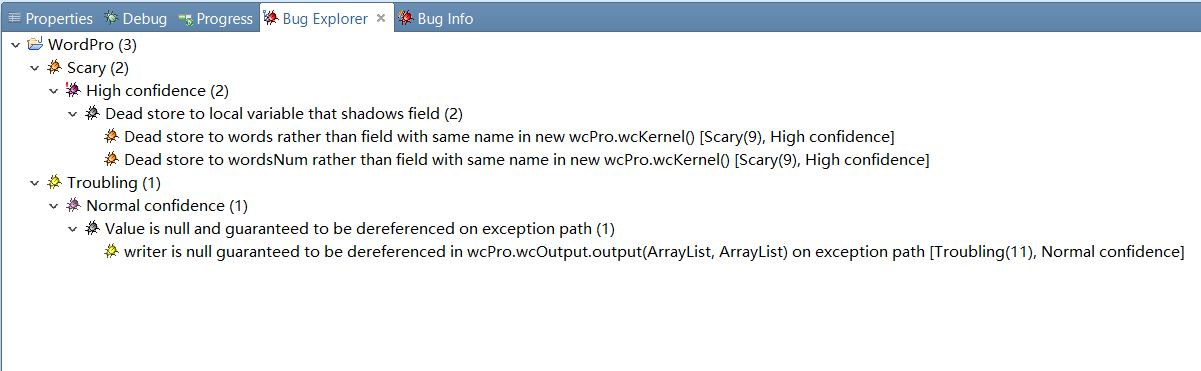
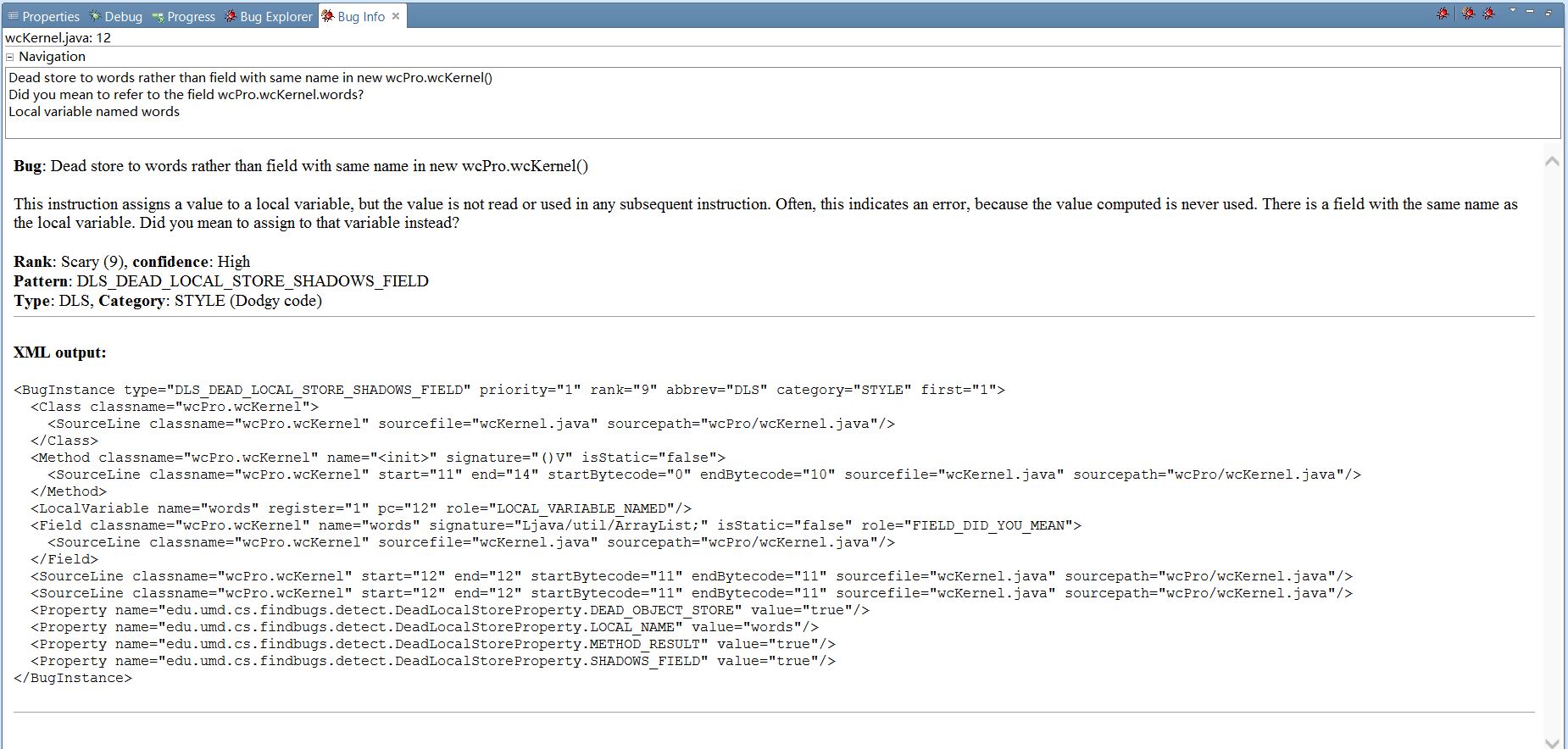
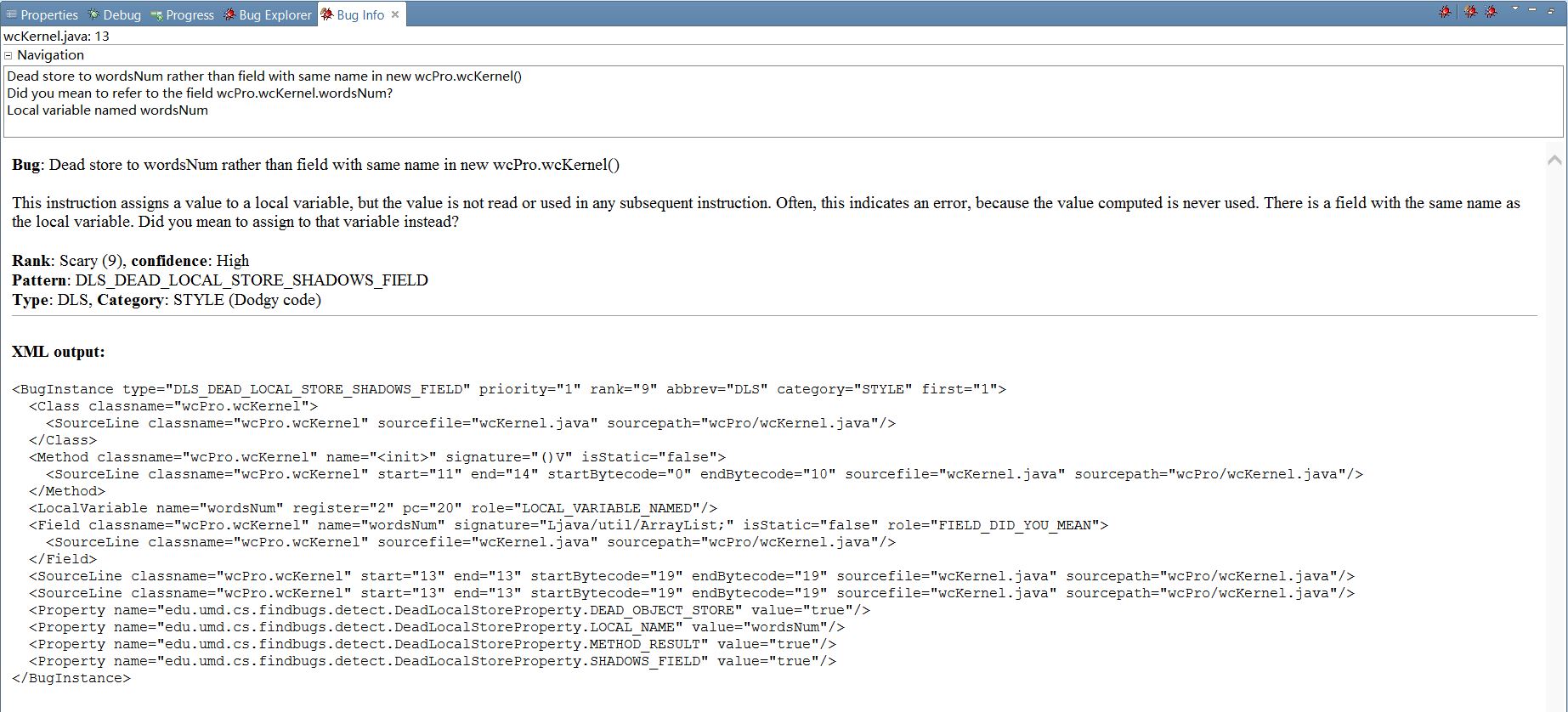
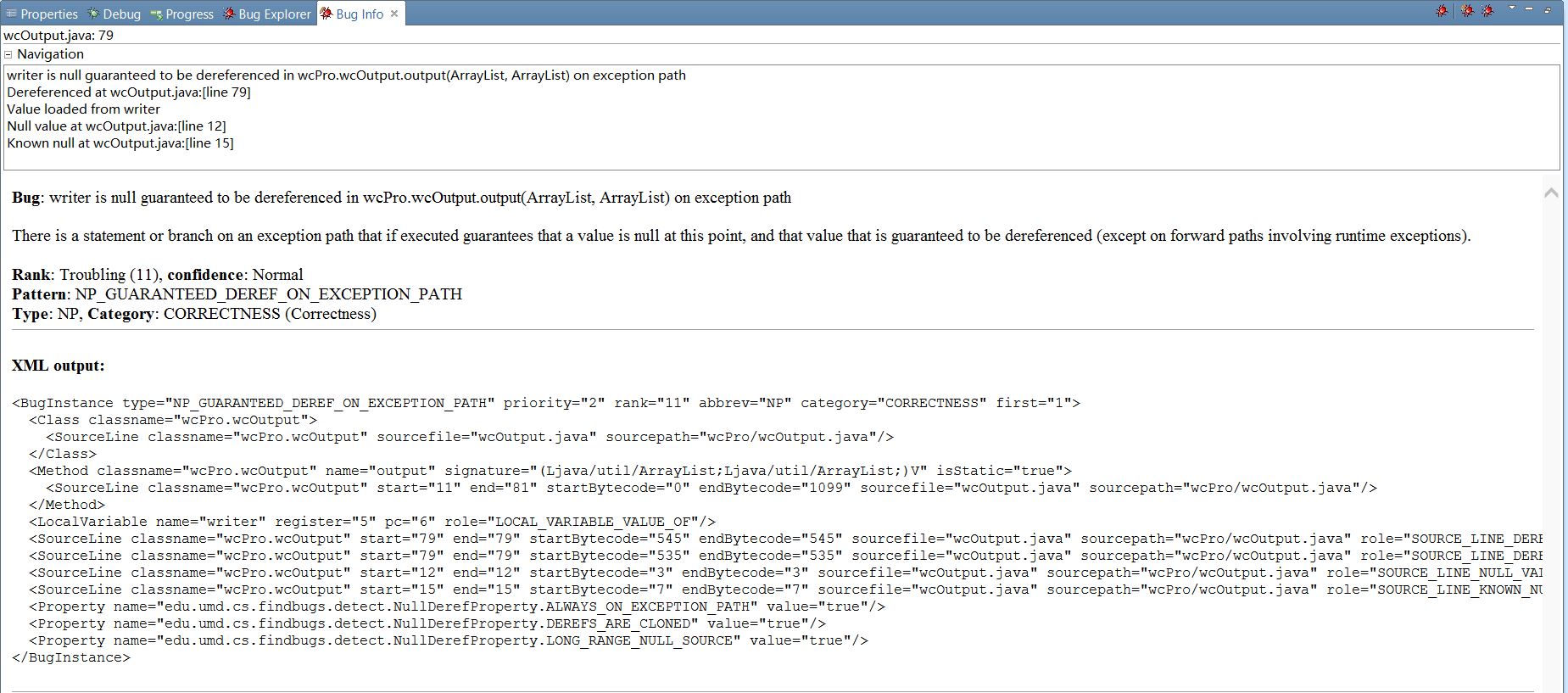
分析:
1)核心模块中两个多余无效赋值,
words=new ArrayList<String>();
wordsNum=new ArrayList<Integer>();
改进方法:删除这两句即可。
2)输出模块没有判断writer是否为空。
改进方法:增加 if(writer!=null) 语句。
5、4中分析的是整个程序的,总共三个不规范的bugs,其中核心模块是笔者负责的。
高级任务:
1、测试数据集的设计思路:
保证数据集足够大,尽可能增大程序分析的压力,比如我测试的是2M的txt文件。
2、优化前的性能指标:

3、评审过程:
1)、作者、 讲解员:冷福星 U201517048
记录员、评审员:康之是 U201517040
评审员、讲解员:李慎纲 U201517050
主持人、评审员:付佳韵 U201517039
2)、目的:通过对代码的评审,规范代码,检查出代码不合乎规范的地方,便于复杂模块间的接口联调,提高开发的效率和正确率。
3)、讲解:
main函数里输入命令并解析,command函数执行命令输出,wc函数完成核心功能。
评审:
(1)、每个“{“ 和”}”没有独占一行
(2)、注释不清晰,没有解释为什么这么做,没有使用全英文注释
(3)、多行语句写在同一行
(4)、不是所有地方提供报错功能
(5)、循环太多,增加时间复杂度
(6)、if的缩进不合理
(7)、有些地方命名不规范
(8)、循环变量命名没有意义
(9)、接口定义不清晰,没有指明变量意义
4、影响性能指标的主要因素:
1) 读和写文件即I/O操作是十分耗时的
2)核心功能的单词和词频分析
5、优化的设计思路:
尽可能优化单词分析和单词排序算法
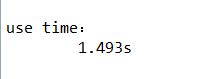
优化后性能指标:
6、软件开发、软件测试、软件质量
基本任务对应软件开发,扩展任务对应软件测试,高级任务对应提高软件质量。
1)没有软件开发就没有测试,软件开发提供软件测试的对象。
2)软件开发和软件测试都是软件开发周期的重要组成部分。
3)软件开发和软件测试都是软件过程中的重要活动。
4)软件测试是保证软件质量的重要手段。
附加题:
因为附加题很简单,就是设计一个图形界面,没有什么特殊的地方,说具体怎么编码反而显得繁琐,索性这里只给出程序界面,具体代码和exe参见笔者的github地址。
参考链接:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号