


软工第二次作业
github仓库地址:https://github.com/DanielWen2005/3123004671
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 锻炼实践个人项目能力,需求分析、规划,以及测试能力 |
一、PSP
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 10 | 10 |
| - 估计这个任务需要多少时间 | 10 | 10 |
| 开发 | 185 | 250 |
| - 需求分析 (包括学习新技术) | 45 | 60 |
| - 生成设计文档 | 20 | 20 |
| - 设计复审 | 20 | 30 |
| - 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| - 具体设计 | 30 | 30 |
| - 具体编码 | 30 | 45 |
| - 代码复审 | 10 | 20 |
| - 测试(自我测试,修改代码,提交修改) | 30 | 35 |
| 报告 | 20 | 25 |
| - 测试报告 | 5 | 10 |
| - 计算工作量 | 5 | 5 |
| - 事后总结, 并提出过程改进计划 | 10 | 10 |
| - 合计 | 215 | 285 |
二、计算模块接口的设计和实现过程
代码中主要函数功能包括读入文件,数据预处理,计算重复率,结果输出。
- 读入文件模块:从命令行参数获取论文原文文件绝对路径,抄袭版论文的文件的绝对路径和输出的答案文件的绝对路径,并尝试打开文件将内容存储为字符串。
- 数据预处理模块:对获取到的内容进行预处理,删除空格、标点符号等无意义内容,减少计算量。
- 计算模块:采用计算莱文斯坦距离的方式计算处理后的论文原文和抄袭版论文的重复率。
- 输出模块:将计算得到的重复率输出到获取到的输出答案文件的绝对路径文件中。
算法关键在于计算两个字串之间,由一个转换成另一个所需的最少编辑操作次数来计算两篇论文的相似度。与分词后计算差异对比,本算法优势在于有效的避免了通过插入单个字符或混淆项影响分词,从而使计算出的重复率偏低。本算法对微小干扰项的抗干扰能力较强,在频繁插入单个字符、打乱文本顺序等操作后仍能识别出较高的抄袭重复率。
三、计算模块接口部分的性能改进
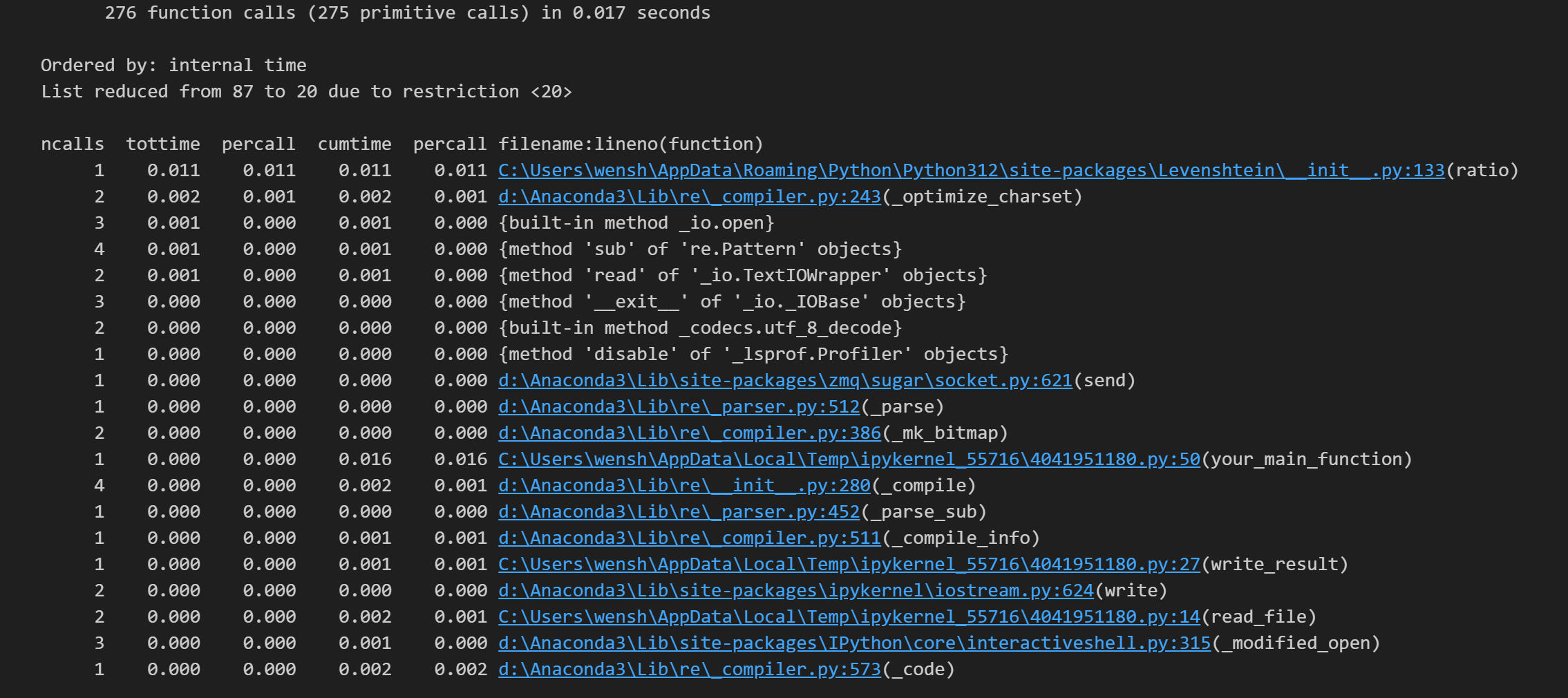
使用cProfile分析这段代码性能得出,计算模块中计算莱文斯坦距离的函数在整段程序中占用了绝大部分时间(计算函数占用总运行时长70%左右)。
在思考与查阅资料后尝试使用截断取样的方法减少计算莱文斯坦距离函数的数据量以改进计算模块接口部分的性能。限制该函数的处理数据量,对过长的文段进行取样处理,以样本的重复率作为整体的重复率。
测试后发现有效提升了计算模块的性能,且计算得出的重复率与优化前计算得出的重复率在可接受误差区间内。
四、计算模块单元测试展示
采用unittest和coverage测试代码以及代码覆盖率。通过构造内容完全相同的文件,内容部分不同的文件以及内容完全不同的文件测试该程序。尝试构造不存在的文件路径,无法打开的文件类型,不合理的数据测试测试程序。
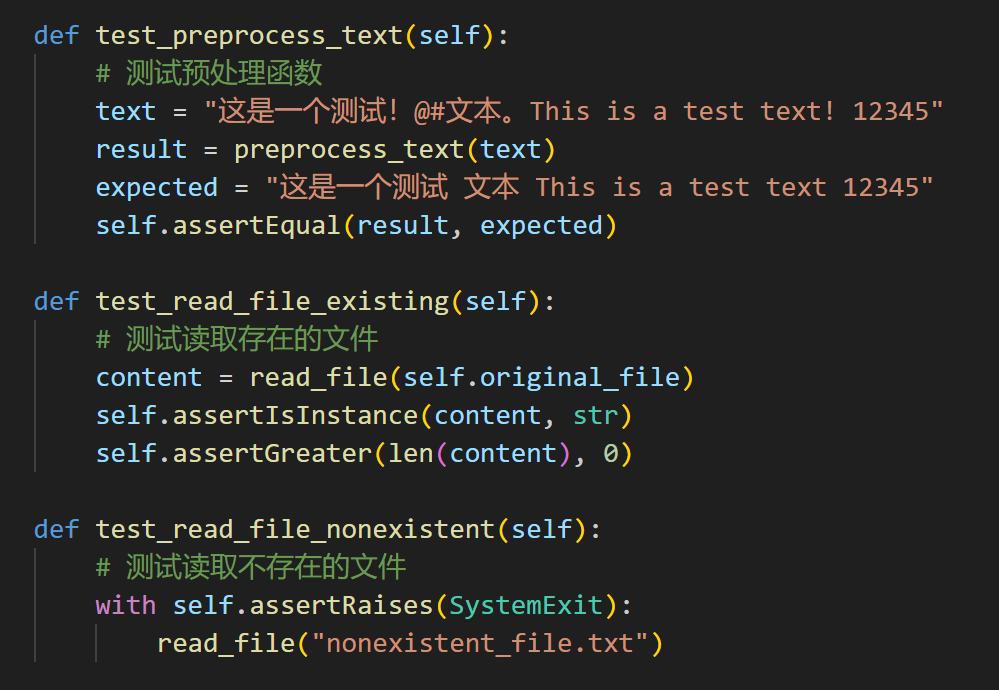
测试得出代码覆盖率100%

五、计算模块部分异常处理说明
1、命令行运行格式错误

2、文件不存在
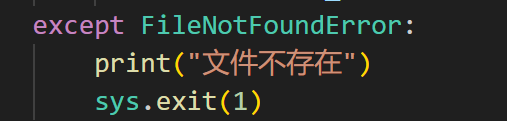
3、文件无法读取
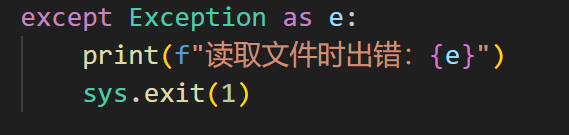
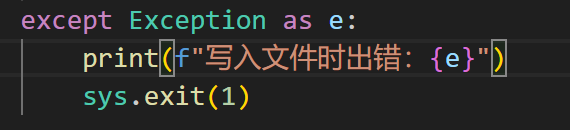
4、答案文件写入错误

 浙公网安备 33010602011771号
浙公网安备 33010602011771号