分布式系统中的主从复制基本原理
分布式系统中的主从复制基本原理
复制指在多台机器上保存相同数据的副本,通过数据的复制,人们希望达到以下目的:
- 使用户使用物理上离他们更近的的数据,降低访问延迟。
- 部分组件出现故障,系统仍然可以继续工作,提高可用性。
- 扩展至多台机器以令他们同时提供数据访问服务,提高读吞吐量。
本文只讨论一些简单情况:数据规模比较小,每台机器都可以存储数据集的完整副本;只考虑简单的故障问题;不考虑多主节点和无主节点架构。
1. 主从复制的基本工作原理
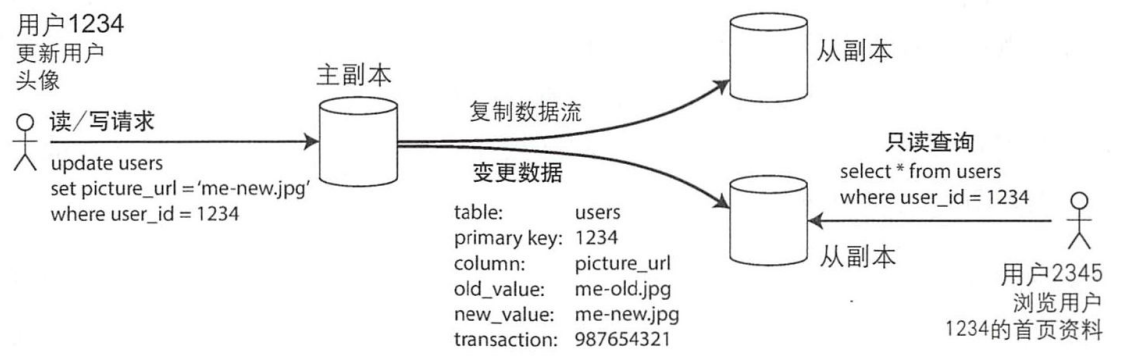
- 指定一个节点为主节点,客户写数据库时首先写到主节点。
- 其他节点为从节点,主节点将数据写到本地后将数据更改以日志的形式发送给所有从节点。每个从节点获得日志后将其应用到本地的,且严格保持与主节点相同的写入顺序。
- 客户端从数据库读数据时,可以在主节点或从节点上执行查询。只有主节点可以接受写请求,所有节点都可以接受读请求。
复制技术广泛应用于各种关系型数据库、非关系型数据库、分布式消息队列、网络文件系统等等。
2. 同步复制与异步复制
对于关系型数据库,复制通常是同步或异步可选的的。对于其它系统通常是只能选择其中一个。
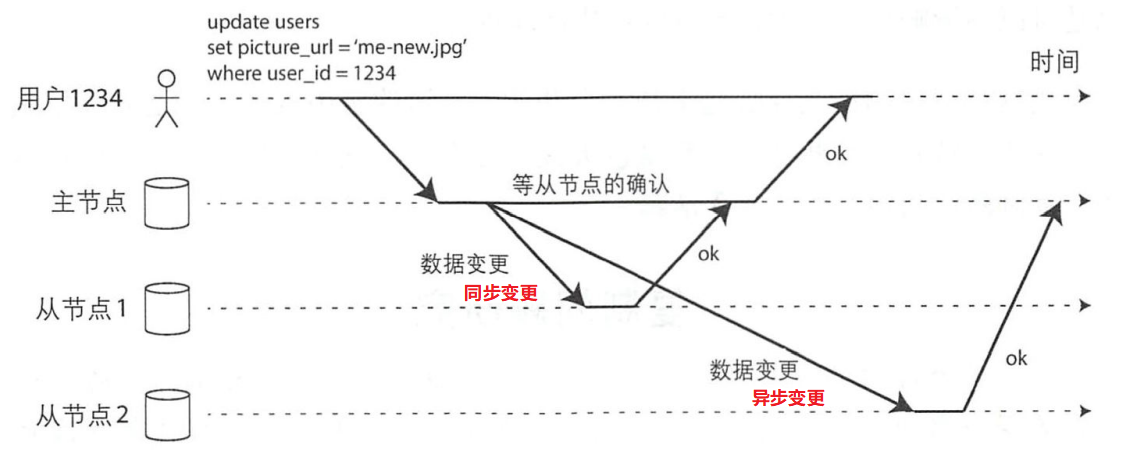
上图中表达了向从节点1同步变更,向从节点2异步变更。
2.1 从节点失效:追赶式恢复
从节点的失效恢复比较简单,只需要通过中断前记录的最后一个执行事务的事务号,向主节点请求从这个事务到当前中间执行的所有操作,然后追赶上主节点的进度即可。
2.2 主节点失效:节点切换
当主节点失效,我们要做的是将其中一个从节点提升为主节点,令他行使主节点的职责。这个过程可以手动切换,也可以自动进行,自动进行的步骤如下:
- 确认主节点失效。一般使用心跳+超时的机制。节点之间互相发送心跳消息来确认对方是否存活,超过一段时间未收到心跳消息回复则认为该节点已下线。
- 选举新的主节点。可以通过共识选举的方式确定新的主节点,也可以由之前选定的某控制节点来指定新的主节点。主要原则在于让新的主节点和原主节点最为相似。
- 重新配置系统使主节点生效。我们需要做一些配置让新的主节点切实生效,例如让所有客户端将请求路由到新的主节点上;在原主节点再次上线之后令他降级为从节点。
上述过程中存在许多变数:
-
如果使用的是异步复制,且失效之前新主节点没收到原主节点的所有数据,且选举之后原主节点很快重新上线。接下来新的主节点很可能收到来自原主节点的冲突的写请求,因为原主节点尚未搞明白身份的变化。
常见的解决方案是,原主节点上未完成复制的写请求就此丢弃。
-
在故障情况下,可能出现两个节点都认为自己是主节点,这种情况非常危险并且难以处理。
-
难以设置恰好的超时时间来判定主节点失效,过长可能导致恢复时间太长,过短可能导致很多不必要的主节点切换。
3. 复制日志的实现
3.1 基于语句的复制
最简单的方法,主节点将每个写请求转发给从节点。这样做很合理也不复杂,但有一些不适用的场景:
- 任何调用非确定函数的语句,比如
NOW()获取当前时间,RAND()获取一个随机数。 - 语句中使用了自增列,或依赖于数据库的现有数据。那么副本必须按完全相同的顺序执行。
- 有副作用的语句,如触发器,存储过程,用户自定义函数等。
3.2 基于预写日志WAL传输
主节点可以将它的 WAL 日志传输给从节点,从节点依次构造数据副本。
这样做缺点在于复制方案强依赖于存储引擎的实现方式(实质上是 WAL 的实现方式)。
3.3 基于行的逻辑日志复制
我们也可以令复制和存储引擎采用不同的日志格式,让复制和存储逻辑剥离。
关系型数据库的逻辑日志往往是以下这样的实现:
- 对于行插入,日志包含新值。
- 对于行删除,日志唯一标识已删除的行,通常是依赖主键。
- 对于行更新,日志唯一标识需要更新的行和他们的新值。
如果事务涉及多行的修改,则会产生多个这样的日志记录,并在后面跟着一条记录来指出事务已经提交。例如 MySQL 的 binlog 是这样实现的。
3.4 基于触发器的复制
前面的复制方法都是数据库提供的,我们也可以自己实现一个触发器,来自己实现复制的逻辑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号