结对作业二
| 这个作业属于哪个课程 | 2021春软工实践|W班 (福州大学) |
|---|---|
| 这个作业的要求在哪里 | 结对作业二 |
| 结对学号 | 221801326、221801124 |
| 这个作业的目标 | 采用web技术实现原型功能 |
| 其他参考文献 | 无 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 25 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 25 |
| Development | 开发 | 1620 | 2350 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 25 |
| • Design Spec | • 生成设计文档 | 20 | 20 |
| • Design Review | • 设计复审 | 10 | 12 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| • Design | • 具体设计 | 20 | 20 |
| • Coding | • 具体编码 | 1400 | 2100 |
| • Code Review | • 代码复审 | 30 | 28 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | 70 | 90 |
| • Test Repor | • 测试报告 | 45 | 60 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 1710 | 2465 |
Github仓库地址及代码规范
云服务器访问链接
成品展示
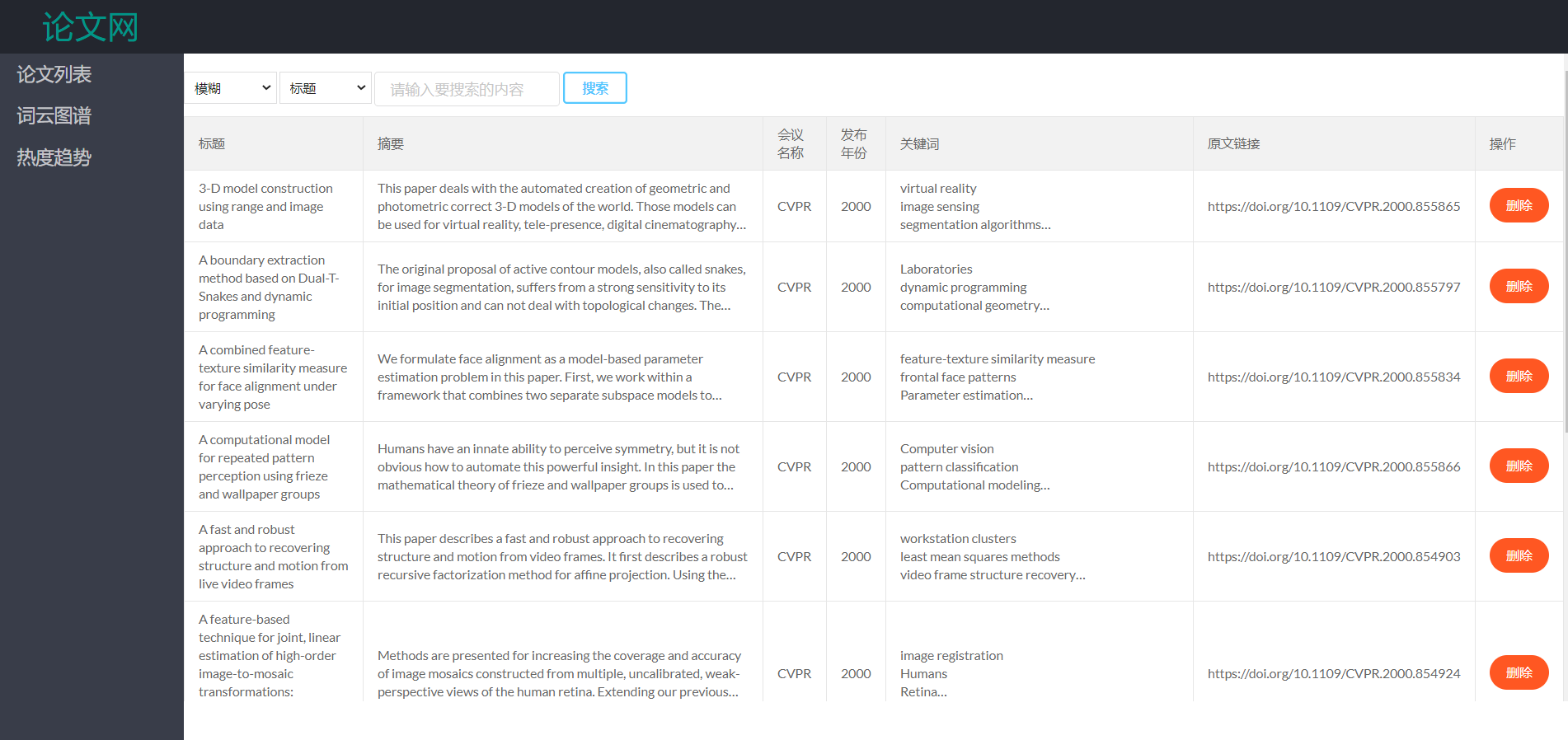
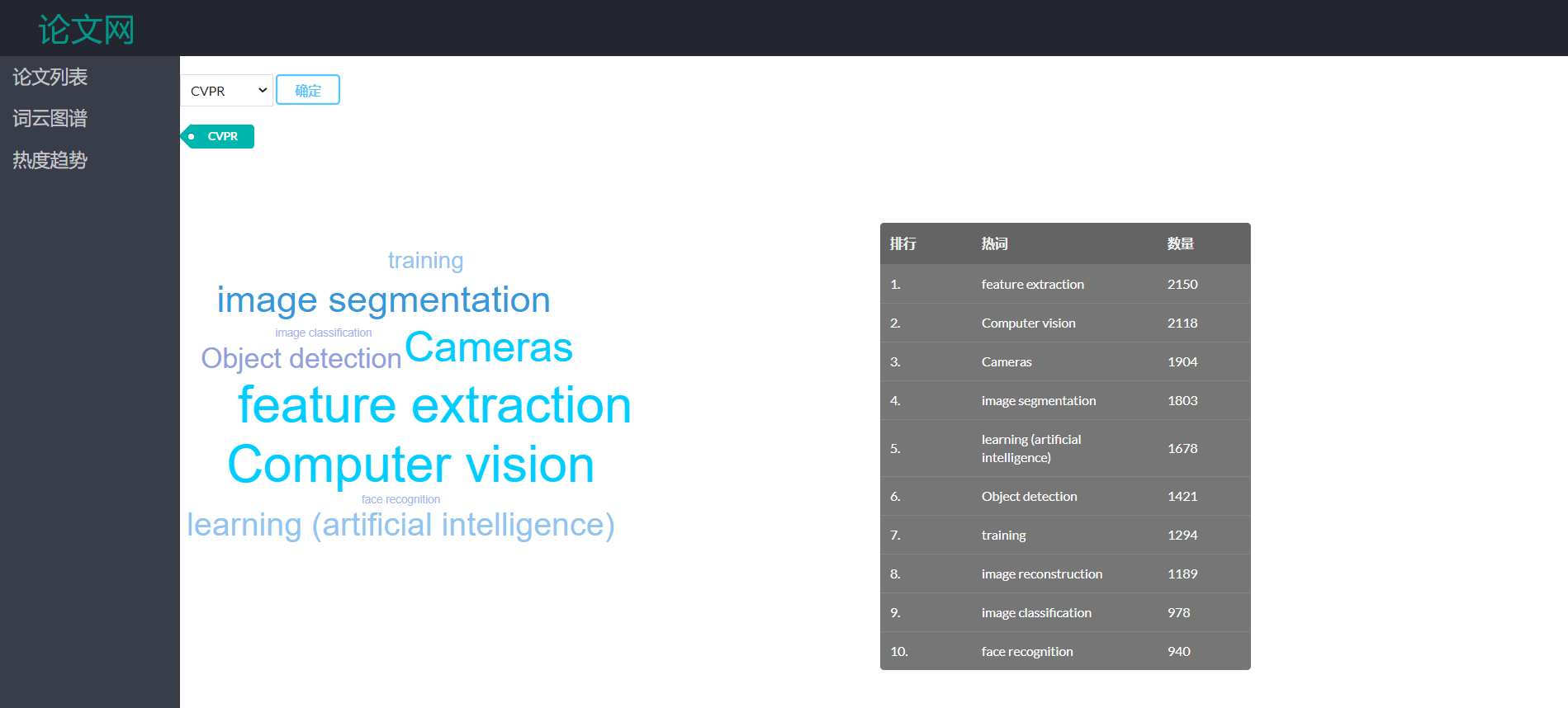
- 侧边栏有论文列表、词云图谱、热度趋势等功能供用户选择
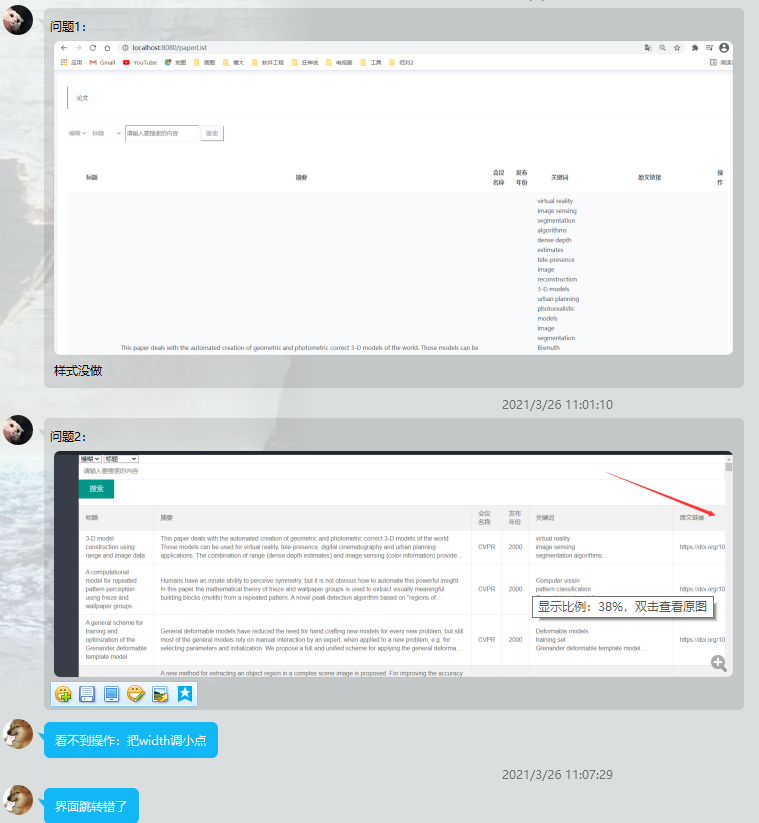
- 在论文列表中展示所有论文,用户可以通过下拉框选择是模糊查询还是精确查询,并选择通过标题、摘要、会议名称、发布年份、关键词来对文章进行搜索。同时在文章列表中增加了删除操作,用户点击删除后,重新返回文章列表。

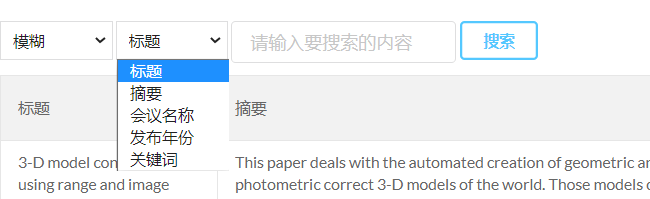
- 因为有些文章摘要过长或者关键词过多,展示全部的摘要内容或关键词会导致页面展示不够整齐和美观,所以我们在这设置了鼠标事件,默认展示三行摘要内容或者三个关键词,当用户鼠标移至摘要时,会将摘要内容全部展示;鼠标移至关键词内容时,会有滚动条,可以滚动查看所有的关键词。

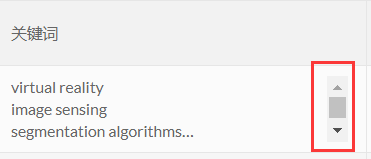
- 由于文章篇幅过多,对文章进行了分页操作。
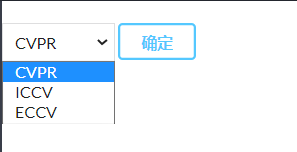
- 词云图谱展示部分,设置了下拉框,默认展示CVPR的top10的热词。用户可以通过选择不同的顶会查看对应的热门关键词,并在右侧辅以表格直观显示对应的热词的数量。用户可以通过点击对应词云跳转展示热词相关的文章。
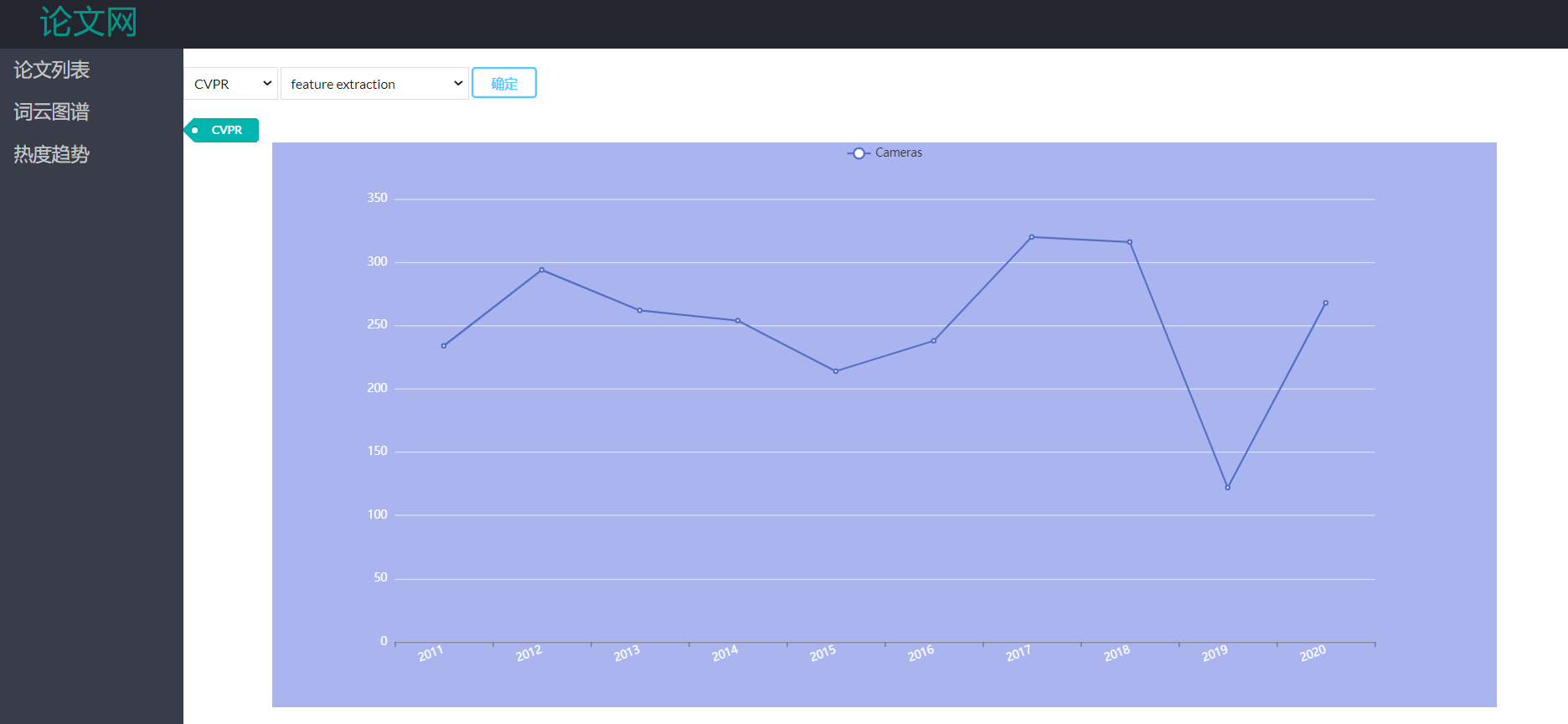
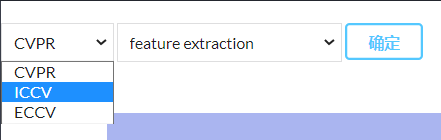
- 热度趋势展示部分,提供了两个下拉框,第一个用来选择顶会;第二个下拉框级联第一个下拉框,当第一个下拉框内容改变时,第二个下拉框根据第一个下拉框内容展示对应顶会的top10关键词。选择完毕后,点击确定,在折线图中展示该关键词近10年的频数变化趋势。
结对讨论过程描述
- 我们刚拿到题目的时候,首先先对项目进行了需求分析和数据库设计(这部分我们约出来在工作室里面讨论,因为觉得当面讨论的效果会比在网上讨论好),而且一起制定了共同的代码规范(如果存在差异的话,在讨论后选择使用更好的)。
- 在炜嘉将json文件全部解析之后,我们一起进行了页面设计(参考了我们之前做的原型)并且分配了任务,炜嘉负责功能一,思萍负责功能二,如果剩余时间较多就一起实现功能三。
- 在代码实现的时候,如果遇到问题,就会跟对方讨论,我们在线下的下课时间会讨论功能的具体实现,也会在课余时间约出来一起写代码。

- 在线上一般会用qq讨论,偶尔还会使用qq电话和屏幕共享。
- 在遇到问题时,我们会通过屏幕共享一起分析问题所在,同时,我们会对彼此的代码和所实现的功能进行复审,确保如果遇到问题可以及时解决。
- 最后我们各自进行了一次测试,测试了所有功能,确保没有bug后,完成了这次的结对编程任务~
设计实现过程
- 架构
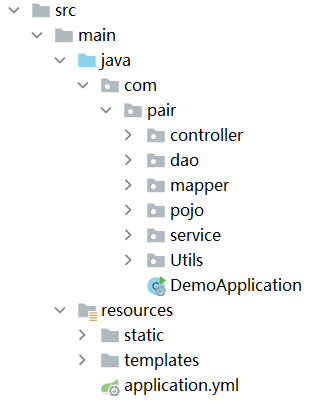
-
设计
-
后端
- 我们前端使用了thymeleaf,后端使用spring boot,使前后端不分离。
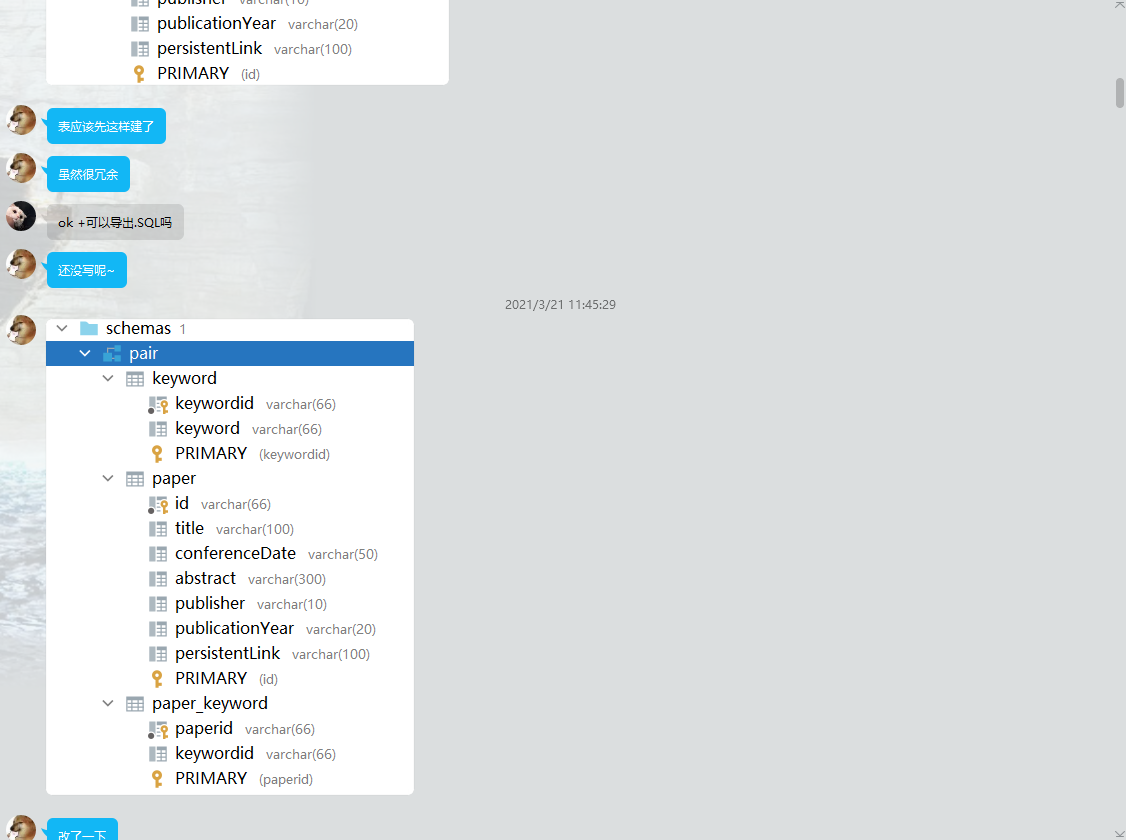
- 在pojo中,封装了实体类Paper,PaperKeyword(paper和keyword的对应关系),和Keyword来对数据进行传递。
- 在dao层中,设计了各种Mapper接口,定义了访问数据库的方法,主要用于实现数据持久化。
- 在mapper中,通过各种Mapper.xml对Mapper接口进行了实现。
- 在service层中,通过调用dao层的方法,定义了各种服务,主要实现了业务模块的应用逻辑。
- 在controller中,通过调用service层来负责具体业务模块流程的控制
- 在utils中对工具类进行封装,封装了把解析JSON文件到数据库的类。
-
前端
- 在static中放了一些静态文件,比如用到的css,js等
- 在templates里放了要实现的html界面(用thymeleaf进行数据绑定)
-
实现过程:我们先设计了dao层(将需求分析得到的需求细化到要用到的数据库操作)、mapper(操作的具体实现)和utils(将要用到的工具类先写好),进行测试,确保dao层的方法能正确的进行数据库操作。然后进行service层设计,将业务封装到service层中,最后在controller层中实现页面的跳转。
-
功能结构图
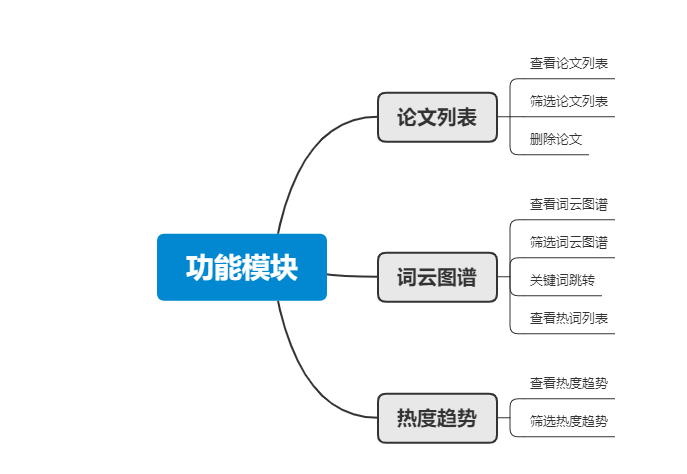
关键代码说明
-
数据库设计
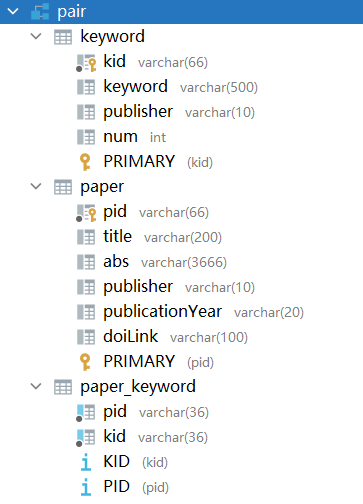
-
词云展示部分:通过HttpServletRequest获取前端下拉框组件里的顶会名,根据顶会名到数据库中搜索该顶会的关键词top10,返回top10关键词(包含关键词名,关键词数量)。并将top10关键词的词名和关键词数量用model返回给前端。
@RequestMapping("/clouds")
public String getKeyWords(Model model, HttpServletRequest request) {
String publisher = request.getParameter("meeting");
keywordService.getTop10Cloud(model, publisher);
return "cloud";
}
public List<Keyword> getKeyWords(String publisher) {
return keywordMapper.getKeyWords(publisher);
}
public void getTop10Cloud(Model model, String publisher) {
if (publisher == null) {
publisher = "CVPR";
}
List<Keyword> keyWords = getKeyWords(publisher);
String kws[] = new String[10];
int nums[] = new int[10];
for (int i = 0; i < keyWords.size(); i++) {
kws[i] = keyWords.get(i).getKeyword();
nums[i] = keyWords.get(i).getNum();
}
model.addAttribute("meeting", publisher);
model.addAttribute("kw0", kws[0]);
model.addAttribute("num0", nums[0]);
……
}
<select id="getKeyWords" resultType="keyword" parameterType="String">
select * from pair.keyword where publisher=#{publisher} order by num
desc limit 10;
</select>
- 词云展示页面使用了JQCloud,通过设置其link属性来完成点击跳转,使用RestFul风格携带关键词返回,并通过该关键词查询并返回相关数据,同时为了实现分页,用了HttpServletRequest保存了"selectTerm"搜索项目,"selectItem"搜索内容,"selectMode"搜索方式,并用转发来保证跳转后依旧可以使用分页功能。
var
word_array = [
{text: "[[${kw0}]]", weight: parseInt("[[${num0}]]"), link: "./getPapers/[[${kw0}]]"},
{text: "[[${kw1}]]", weight: parseInt("[[${num1}]]"), link: "./getPapers/[[${kw1}]]"},
{text: "[[${kw2}]]", weight: parseInt("[[${num2}]]"), link: "./getPapers/[[${kw2}]]"},
{text: "[[${kw3}]]", weight: parseInt("[[${num3}]]"), link: "./getPapers/[[${kw3}]]"},
………
];
@RequestMapping("/getPapers/{keyword}")
public void getPapers(@PathVariable("keyword") String keyword, Model model, HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
paperService.getPapersByKeyword(model, keyword);
request.setAttribute("selectTerm", "keyword");
request.setAttribute("selectItem", keyword);
request.setAttribute("selectMode", "precise");
request.getRequestDispatcher("/paperSelect").forward(request, response);
}
- 热度趋势部分的下拉框级联展示使用了ajax技术,第一个下拉框设置onchange属性,当其改变时,获取其选择值,通过url携带参数进行查询并返回对应顶会的top10关键词进行展示。
<form th:action="@{/top10}" method="post" style="margin-top: auto;margin-bottom: auto">
<select name="meeting" id="meeting" onchange="getwords()" class="ui fluid dropdown"
style="width: 100px;height: 35px;display: inline">
<option value="CVPR">CVPR</option>
<option value="ICCV">ICCV</option>
<option value="ECCV">ECCV</option>
</select>
<select name="words" id="words" class="ui fluid dropdown" style="width: 200px;height: 35px;display: inline">
</select>
<input type="submit" value="确定" class="ui inverted blue button" style="height: 33px;"/>
</form>
<script>
function getwords() {
var meeting = $("#meeting").val();
$.ajax({
type: "GET",
url: "/top10words/" + meeting,
async: true,
success: function (data) {
var rList = data;
var rSelect = "";
for (var i = 0; i < rList.length; i++) {
rSelect += ("<option value = '" + rList[i].keyword + "'>" + rList[i].keyword + "</option>");
}
$("#words").empty();
$("#words").append(rSelect);
}
})
}
</script>
@RequestMapping("/top10words/{meeting}")
@ResponseBody
public List<Keyword> getTop10ByMeeting(@PathVariable("meeting") String meeting) {
List<Keyword> top10Keyword = keywordService.getTop10Keyword(meeting);
return top10Keyword;
}
<select id="getTop10Keyword" resultType="keyword" parameterType="String">
select * from pair.keyword where publisher=#{publisher} order by num desc limit 10
</select>
- 文章的搜索功能因为可以使用模糊查询或精确查询,同时可以选择查询项目,所以我在paperService中写了两个查询方法,以下展示模糊查询的mapper.xml
@RequestMapping("/paperSelect")
public String paperSelect(HttpServletRequest request, Model model) {
String selectTerm, selectItem, selectMode;
if (request.getAttribute("selectItem") == null) {
selectTerm = request.getParameter("selectTerm");
selectItem = request.getParameter("selectItem");
selectMode = request.getParameter("selectMode");
} else {
selectTerm = (String) request.getAttribute("selectTerm");
selectItem = (String) request.getAttribute("selectItem");
selectMode = (String) request.getAttribute("selectMode");
}
//查询的内容
Map<String, Object> map = new HashMap<>();
map.put(selectTerm, selectItem);
if (selectMode.equals("fuzzy")) {//模糊查询
paperIds = paperService.getPaperIdByFuzzyMode(map);
} else {//精确查询
paperIds = paperService.getPaperIdByPreciseMode(map);
}
begin = 0;//进行分页
if (paperIds.size() - 1 < 8) {
end = paperIds.size() - 1;
} else {
end = 8;
}
List<Paper> papers = new ArrayList<>();
for (int i = begin; i <= end; i++) {
papers.add(paperService.getPaperById(paperIds.get(i)));
}
model.addAttribute("papers", papers);
model.addAttribute("pages", paperIds.size() / 9 + 1);
model.addAttribute("currentPages", begin / 9 + 1);
return "paperList";
}
<select id="getPaperIdByFuzzyMode" resultType="String" parameterType="map">
select distinct p.pid
from paper p
left join paper_keyword pk on p.pid=pk.pid
left join keyword k on pk.kid=k.kid
<where>
<if test="title!=NULL">AND title LIKE "%"#{title}"%"</if>
<if test="abs!=NULL">AND abs LIKE "%"#{abs}"%"</if>
<if test="publisher!=NULL">AND p.publisher LIKE "%"#{publisher}"%"</if>
<if test="publicationYear!=NULL">AND publicationYear LIKE "%"#{publicationYear}"%"</if>
<if test="keyword!=NULL">AND keyword LIKE "%"#{keyword}"%"</if>
</where>
</select>
- 在获得文章列表的时候,因为我封装paper类的时候,通过包含实现文章跟关键词的一对多,所以在进行查询时,使用了外连接,来防止文章关键词为空导致无法连接。
public class Paper {
...
private List<Keyword> keywords;
}
<resultMap id="PaperKeyword" type="Paper">
<result property="pid" column="pid"/>
<result property="title" column="ptitle"/>
<result property="abs" column="pabs"/>
<result property="publisher" column="ppublisher"/>
<result property="publicationYear" column="pyear"/>
<result property="doiLink" column="plink"/>
<collection property="keywords" ofType="Keyword">
<result property="kid" column="kid"/>
<result property="keyword" column="kkey"/>
<result property="publisher" column="ppub"/>
<result property="num" column="pnum"/>
</collection>
</resultMap>
<select id="selectAllPapers" resultMap="PaperKeyword">
select p.pid pid,p.title ptitle,p.abs pabs,p.publisher ppublisher,
p.publicationYear pyear,p.doiLink plink,
k.kid kid,k.keyword kkey,k.publisher ppub,k.num pnum
from paper p
left join paper_keyword pk on p.pid=pk.pid
left join keyword k on pk.kid=k.kid
</select>
心路历程和收获
-
炜嘉:在这次的结对编程中,当看到作业要求的时候,我觉得有点迷茫,因为虽然学过了spring boot,但是使用起来还不太熟练,而且对于词云,热词趋势等完全没有了解,有些许的不自信,不太确定能不能按时完成任务。好在有思萍陪我一起开发,使任务化繁为简,最终只用了不到5天就完成了任务。在结对编程的过程中,我们互相学习,一起进步,我对spring boot的使用也更加熟练,也学会了echart,jqcloud的使用,还学会了如何在服务器上部署项目和数据库设计与调优。两个人结对合作,可以及时的发现自己的问题,也可以锻炼沟通能力和表达能力,与此同时,明确的分工使得两个人各施其职,有着极高的开发效率。
在这次的编码中,遇到的主要问题是把json文件中的数据读进数据库,会遇到以下这些问题
- 字段的设计不合理:比如关键词过长,摘要过长,这些在设计时没考虑到,导致在导入的时候会报错然后停止。
- 数据的导出过慢:我导了第一遍数据用了3h43m,经过分析和调优,主要时间花费在插入数据库的keyword表时,每次都会查询整个keyword表来判断有没有重复,导致时间过长,而且没有设置索引,在设置索引和改进sql语句之后,优化了时间。
- 同时,电脑的性能也有较大的影响(该换电脑了)
-
思萍:在此次的结对编程中,一开始看着作业要求对自己的所能做到的完成程度有着些许的不确定,但是后面投入实践中,使我对springboot的使用熟练度大大提升,提高了自身能力。因为是两个人结对合作,所以两个人的必须更加规范代码的书写,在这次合作中,是一次磨合也是一次成长。同时两个人分工明确,并且互相帮助,期间也多次进行交流沟通,做到了1+1>2。
队友评价:
- 炜嘉:这是和思萍的第二次合作,思萍是我见过最温柔、最认真的女孩子,她对工作十分认真负责。同时也乐于助人,帮我解决了许多小问题,而且思萍总是能有独到的眼光,提出问题的改进方法。在有了第一次合作的配合之后,我们也更加默契,结对开发效率极高。希望以后能多与思萍进行合作。
- 思萍:这是和炜嘉同学的第二次合作,一开始,炜嘉同学便明确了我们的分工,做到了井井有条。在实践过程中,炜嘉同学也热心的帮我解决一些bug问题。炜嘉同学是一个富有责任心并且十分认真的人,无论是分工问题还是平时的交流讨论氛围都很好。和优秀的炜嘉同学合作也提升了我自身。
前端代码规范(来源:阿里巴巴编码规范)
命名规范
- 项目命名
- 全部采用小写的方式
- 以中划线分割
- 目录命名
- 全部采用小写的方式
- 以中划线命名
- 复数时,要采用复数结构
- JS、CSS、SCSS、HTML、PNG等文件命名
- 全部采用小写的方式
- 以中划线命名
- 命名严谨性
- 严禁使用 拼音和中文混合的方式
- 严禁使用中文、中文拼音
- 正确使用 英文拼写和语法
- 一些特殊的词语可以采用国际通用的名称
HTML规范(Template通用)
-
(一) HTML类型
-
推荐使用 HTML5 的文档类型申明
<!DOCTYPE html> -
规定的字符编码
<meta charset="UTF-8"> -
IE兼容模式
<meta http-equiv="X-UA-Compatible" content="IE-Edge"> -
doctypa 大写
-
-
(二) 缩进
- 一个tab 使用两个空格
- 嵌套的节点应该缩进
-
(三) 分块注释
-
在每一个块级元素,列表元素 和 表格元素中,加上一对HTML注释,注释格式
<!-- header 头部 start --> <header> <div> <a href=""></a> </div> </header> <!-- header 头部 end -->
-
-
(四) 语义化标签
- HTML5 有很多语义化标签,优先使用这些语义化标签,避免每一个页面都是
div或者p
- HTML5 有很多语义化标签,优先使用这些语义化标签,避免每一个页面都是
-
(五) 引号
- **使用双引号
" "**而不是单引号''
- **使用双引号
CSS 规范
-
命名
- 类名使用小写字母,以中划线分割
- id 使用 驼峰式命名
- class 的命名不要使用 标签名
-
选择器
-
尽量使用直接子选择器,否则,有时会造成性能损耗
.content > .title { ... }
-
-
尽量使用缩写的属性
border: 1px solid red; -
每个选择器及属性独占一行
img { width: 100%; box-shadow: 3px 3px 3px 3px rgba(0, 0, 0, .1); } -
省略 0 后面的单位
-
避免使用 ID 选择器及 全局标签污染全局样式
Javascript规范
-
命名
-
采用小写驼峰命名
lowerCameCase,代码命名均不能以下划线开头,也不能以下划线或美元符号结尾 -
方法名、参数名、成员变量、局部变量统一采用驼峰命名风格
-
方法名 必须是 动词 或者 动词+名词 形式
-
增删查改,统一使用如下 5 个单词
add / update / delete / get / detail -
常量全部大写,单词之间用下划线隔开,力求语义表达完整清楚,不要嫌名字长
-
-
代码格式
-
使用两个空格进行缩进
if (x < y) { x += 10; } else { x += 1; } -
不同逻辑,不同语义,不同业务之间插入一个空行分隔
-
-
字符串
-
统一使用单引号
'',不使用双引号"",这对创建HTML字符串非常有好处let str = 'foo'; let testDiv = '<div id="test"></div>'
-
-
对象声明
-
使用字面量创建对象
let user = []; -
使用字面量来代替对象构建器
let user = { age: 0 }
-
-
优先使用ES6、ES7、ES8的语法
- 简化程序,使代码更加灵活和可复用
-
括号
-
下列关键词必须有大括号(即使代码只有一行):
if / else / for / while / try / catch / finally / withif (isTrue) { doSomeThing(); }
-
-
undefined判断
-
永远不要直接使用
undefined进行变量判断;使用typeof和字符串'undefined'对变量进行判断if (typeof person === 'undefined') { ... }
-
-
条件判断和循环最多三层
-
条件判断能使用 三目运算符 和 逻辑运算符的,就不要使用条件判断。
如果超过三层的 ,抽成函数,并写清楚注释
-
