

DS博客作业05--查找
| 这个作业属于哪个班级 | 数据结构--网络2011/2012 |
|---|---|
| 这个作业的地址 | DS博客作业05--查找 |
| 这个作业的目标 | 学习查找的相关结构 |
| 姓名 | 王博 |
0.PTA得分截图
查找题目集总得分,请截图,截图中必须有自己名字。题目至少完成总题数的2/3,否则本次作业最高分5分。没有全部做完扣1分。

1.本周学习总结(0-5分)
1.1 查找的性能指标
ASL成功、不成功,比较次数,移动次数、时间复杂度
ASL,即平均查找长度,在查找运算中,由于所费时间在关键字的比较上,所以把平均需要和待查找值比较的关键字次数称为平均查找长度。
计算公式: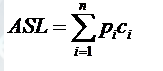
其中n为查找表中元素个数,pi为查找第i个元素的概率,通常假设每个元素查找概率相同,pi=1/n,Ci是找到第i个元素的比较次数。
ASL的计算与移动次数和比较次数有关,决定了该查找算法的时间复杂度,算法的ASL越大,说明时间性能差,反之,时间性能好。
1.2 静态查找
分析静态查找几种算法包括:顺序查找、二分查找的成功ASL和不成功ASL。
顺序查找
按照序列原有顺序对数组进行遍历比较查询的基本查找算法,从表中的最后一个数据元素开始,逐个同记录的关键字做比较,如果匹配成功,则查找成功;反之,如果直到表中第一个关键字查找完也没有成功匹配,则查找失败。
ASL成功: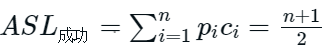
ASL不成功:
int sq_search(keytype keyp[],int n,keytype key)
{
int i;
for(i=0; i<n; i++)
if(key[i] == key)
return i;//查找成功
return -1;//查找失败
}
二分查找
二分查找,也称折半查找,在某些情况下相比于顺序查找,使用折半查找算法的效率更高。但是该算法的使用的前提是静态查找表中的数据必须是有序的。非有序表的查找表使用折半查找算法查找数据之前,需要首先对该表中的数据按照所查的关键字进行排序。
查找方式为(找k),先与树根结点进行比较,若k小于根,则转向左子树继续比较,若k大于根,则转向右子树,递归进行上述过程,直到查找成功或查找失败
ASL成功=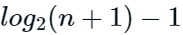
ASL不成功=
//递归法
int BinarySearch(SeqList R,int low,int hight,KeyType k)
{
int mid;
if(low<=high)
{
mid=(low+high)/2;
if(R[mid].key==k)return mid+1;
if(R[mid].key>k)
BinarySearch(R,low,miid-1,k);
else
BinarySearch(R,mid+1,high,k);
}
else return 0;
}
int binarySearch(SeqList R,int n,KeyType k){
int low = 0, high = n-1, mid;
while(low <= high)
{
mid = (low + high) / 2;
if(R[mid.key] == k)
return mid;//找到就返回下标
else if(R[mid].key > k)
high = mid - 1;
else
low = mid + 1;
}
return 0;//找不到返回0
}
1.3 二叉搜索树
1.3.1 如何构建二叉搜索树(操作)
-
结合一组数据介绍构建过程,及二叉搜索树的ASL成功和不成功的计算方法。
构建二叉树要求:
1、若任意结点的左子树不空,则左子树上所有结点的值均不大于它的根结点的值;
2、若任意结点的右子树不空,则右子树上所有结点的值均不小于它的根结点的值;
3、任意结点的左、右子树也分别为二叉搜索树。
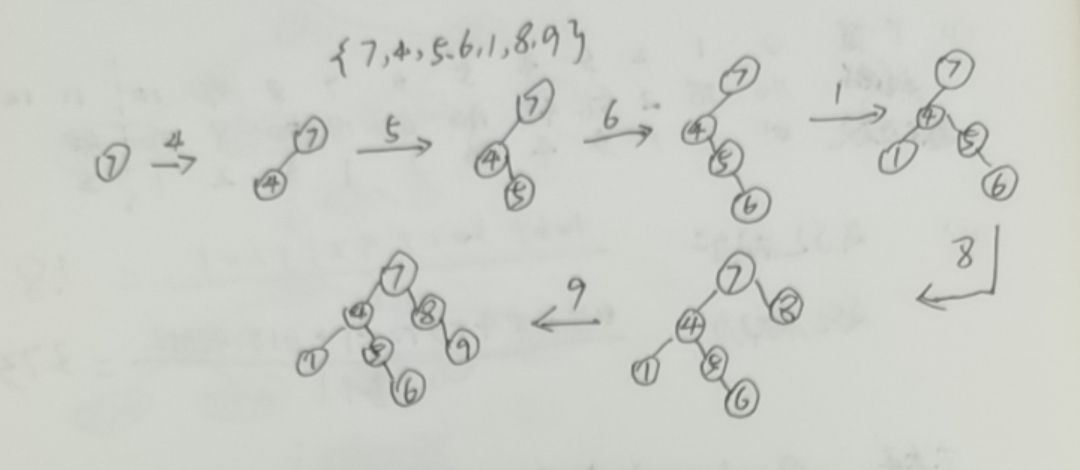
ASL计算
每层的节点数××查找次数(即高度)进行求和即可得到成功的ASL;
每层中空节点数××查找父亲节点的次数(高度-1)进行求和即可得不成功的ASL。
例如图中的ASL计算
-
如何在二叉搜索树做插入、删除。
插入节点:
实现插入时,一般是在底层空结点的为止插入,通过比较找到符合条件的结点,插入要符合小在左,大在右的规律。
删除结点:
没有左右子节点,可以直接删除
存在左节点或者右节点,删除后需要对子节点移动
同时存在左右子节点,不能简单的删除,但是可以通过和后继节点交换后转换为前两种情况
1.3.2 如何构建二叉搜索树(代码)
-
1.如何构建、插入、删除及代码。
-
构建
STNode* CreateBST(KeyType A[], int n) { BSTNode* bt = NULL;//初始时bt为空树 int i = 0; while (i < n) { InsertBST(bt, a[i]);//插入构建二叉树 i++; } return bt;//返回建立的二叉排序树的根指针 } bool InsertBST(BSTNode*& bt, KeyType k) { if (bt == NULL)//原树为空,新插人的结点为根结点 { bt = (BSTNode*)malloc(sizeof(BSTNode)); bt->key = k; bt->lchild - bt->rchild - NULL; return true; } else if (k == bt->key) return false; else if (k < bt->key) return InsertBST(bt → > lchild, k);//插入到左子树中 else return InsertBST(bt->rchild, k);//插入到右子树中 }二叉排序树插入时间复杂度最大为O(n)。若是二叉排序树比较平衡,其时间复杂度下降,最小的时间复杂度为O(logn)。
删除bool DeleteBST(BSTNode& bt, KeyType k) { if (bt == NULL) return false else { if (k < bt->key) return DeleteBST(bt->lchild, k); else if (k > bt->key) return DeleteBST(bt->rchild, k); else { Delete(bt); return true; } } } void Delete(BSTNode*& p) { BSTNode* q; if (p->rchild == NULL) { q = p; p = p->lchild; free(q); } else if (p->lchild = NULL) { q = р; p = p->rchild; free(q); } else Delete(p, p->lchild); } void Deletel(BSTNode* p, BSTNode*& r) { BSTNode* q; if (r->rchild != NULL) Deletel(p, r->rchild); else { p->key = r->key; P->data = r->data; q = r; r = r->lchild; free(q); } } -
3.为什么要用递归实现插入、删除?递归优势体现在代码哪里?
递归操作可以减低算法的复杂度,且较为清晰明了。
1.4 AVL树
-
AVL树解决什么问题,其特点是什么?
AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。
所以AVL树可以提高查找的效率。 -
结合一组数组,介绍AVL树的4种调整做法。
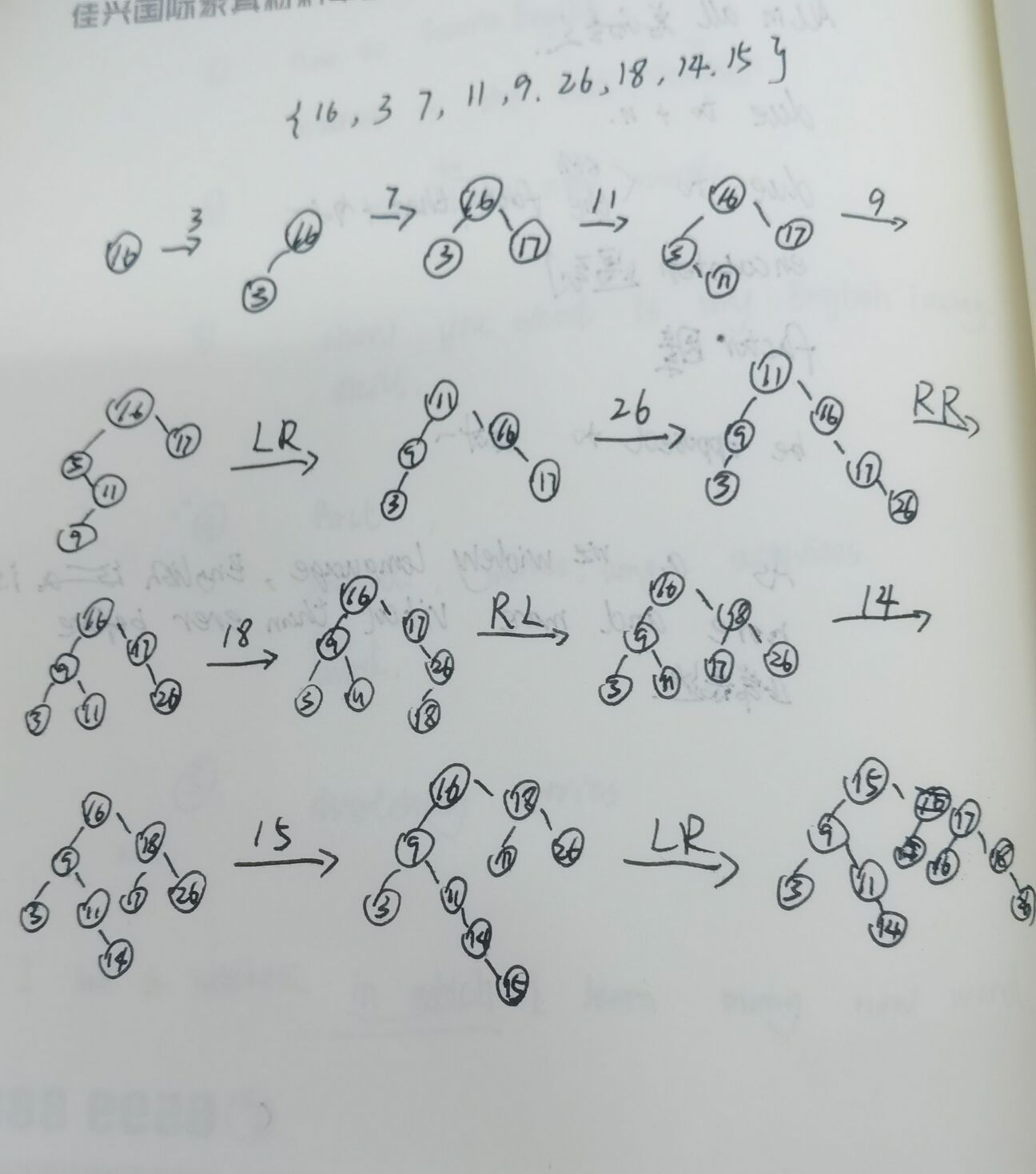
-
AVL树的高度和树的总节点数n的关系?
h = log2(n)+1 (向上取整)
-
介绍基于AVL树结构实现的STL容器map的特点、用法。
map可以将任何基本类型(包括STL容器)映射到任何基本类型(包括STL容器)。
特点:map提供关键字到值的映射 ,其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个称为该关键字的值。
用法:#include <map> end() //返回指向map末尾的迭代器 rbegin() //返回一个指向map尾部的逆向迭代器 rend() //返回一个指向map头部的逆向迭代器 lower_bound() //返回键值>=给定元素的第一个位置 upper_bound() //返回键值>给定元素的第一个位置 empty() //如果map为空则返回true max_size() //返回可以容纳的最大元素个数 size() //返回map中元素的个数 clear() //删除所有元素 count() //返回指定元素出现的次数 equal_range() //返回特殊条目的迭代器对 erase() //删除一个元素 swap() //交换两个map find() //查找一个元素 get_allocator() //返回map的配置器 insert() //插入元素 key_comp() //返回比较元素key的函数 value_comp() //返回比较元素value的函数
1.5 B-树和B+树
-
B-树和AVL树区别,其要解决什么问题?
AVL由于一个结点只能存放一个关键字,若数据量太多会导致树的高度过高,B树的一个结点则可存放多个关键字,降低树的高度,减少查找时间。
一个m阶的B-树每个结点最多m个孩子结点,最多m-1个关键字。除了根节点外,其他结点至少m/2个孩子结点,至少m/2-1个关键字。根节点至少2个孩子。
B-树的查找是通过定义结点的孩子指针个数,通过比较该节点中的关键字,找到对应的孩子指针所指的元素,继续进行比较。 -
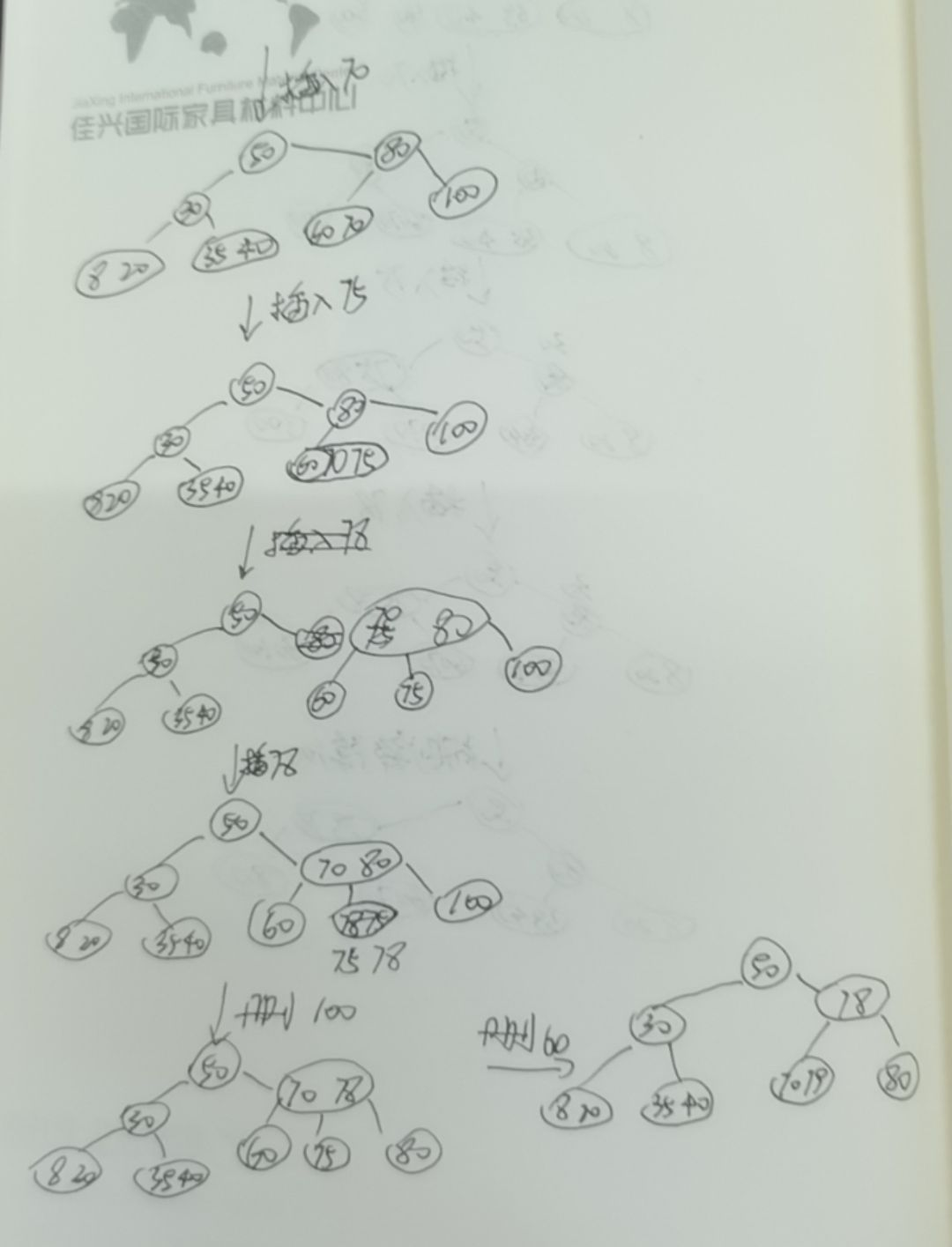
B-树定义。结合数据介绍B-树的插入、删除的操作,尤其是节点的合并、分裂的情况
B-树定义:一棵m阶B-树或者是一棵空树,或者满足一下要求的树就是B-树
- 每个结点之多m个孩子节点(至多有m-1个关键字);
- 除根节点外,其他结点至少有⌈m/2⌉个孩子节点(至少有⌈m/2⌉-1个关键字);
- 若根节点不是叶子结点,根节点至少两个孩子.
![]()
-
B+树定义,其要解决问题
B+树定义:常被用来对检索时间要求苛刻的场景,适用于大型文件索引
满足条件:
- 除根节点,其他每个分支节点至少有m/2棵子树
- 有n棵子树的节点有n个关键字。
- 所有叶子节点包含全部关键字及指向相应记录的指针(关键字按顺序)
- 所有分支节点包含子节点最大关键字及指向子节点的指针
- 每个分支节点至少有m棵子树
- 根节点或没有子树,或者至少有两棵子树
1.6 散列查找。
-
哈希表的设计主要涉及哪几个内容?
-
哈希表的设计主要涉及哪几个内容?
哈希表(hash map)是一种实现关联数组抽象数据类型的数据结构,这种结构可以将关键码映射到给定值。哈希表使用哈希函数计算桶单元或槽位数组中的索引,从中可以找到所需的给定值。
构造的方法有直接定址法,除留余数法。
理想情况下,哈希函数会将每个关键码分配给一个唯一的存储桶单元,但是大多数哈希表设计都使用不完美的哈希函数,这可能会导致哈希冲突,也就是哈希函数会为多个关键码生成相同的索引。这种冲突必须以某种方式解决。
使用除留余数法。开放地址法:
p=num%mod
然后如果该位置是空的,直接插入,如果不是,则产生了哈希冲突,使用用线性探查法,往后找到空位置进行插入

链地址法:

2.PTA题目介绍(0--5分)
介绍3题PTA题目
2.1 是否完全二叉搜索树(2分)
本题务必结合完全二叉搜索树经过层次遍历后在队列的特点去设计实现。结合图形介绍。
2.1.1 伪代码(贴代码,本题0分)
伪代码为思路总结,不是简单翻译代码。
void Insert(BinTree &T, int a)
{
if (结点为空)
{
新建结并且初始化;
}
else
{
if (a < T值)进入右循环;
if (a > T值)进入做循环;
}
}
//层次遍历
q.push(T);
while (!q.empty())
{
if (遇到空结点)
{
flag = 1;
}
else
{
if (flag = 0)计数;
左孩子入队;
右孩子入队;
}
}
2.1.2 提交列表

2.1.3 本题知识点
建树,树的插入,树的层次遍历,队列的使用
2.2 航空公司VIP客户查询(2分)
本题结合哈希链结构设计实现。请务必自己写代码,学习如何建多条链写法。
2.2.1 伪代码(贴代码,本题0分)
伪代码为思路总结,不是简单翻译代码。
//取余求地址
int adr = 0;
for (int i = 12; i <= 16; i++)
{
换成数据;
}
//查找用户是否已存在
node = h[adr]->next;
while (遍历哈希链)
{
比较用户名;
}
//存放数据
if (用户存在)
{
比较路程;
存放数据;
}
else
{
新建结点;
比较路程存放数据;
}
2.2.2 提交列表
2.2.3 本题知识点
哈希链的构造创建和寻找,建链前需要对哈希链进行初始化和申请空间,链拉链法的使用,map库的使用.
2.3 基于词频的文件相似度(1分)
本题设计一个倒排索引表结构实现(参考课件)。单词作为关键字。本题可结合多个stl容器编程实现,如map容器做关键字保存。每个单词对应的文档列表可以结合vector容器、list容器实现。
2.3.1 伪代码(贴代码,本题0分)
伪代码为思路总结,不是简单翻译代码。
map<string, bool>m[101];//如果第i个文件存在单词word,则m[i][word] = true;
static int same[101][101];//定义二维数组存放是否有相似
static int num[101];
for i=0 to 文件组数
{
输入文件编号
for iterator=map.begin() to !map.end()遍历单词
if 单词在两个文件都出现过
修正重复单词数,合计单词数
else if 单词在其中一个文件中出现过
修正合计单词数
end if
end for
end for
}
计算输出文件相似度
2.3.2 提交列表
2.3.3 本题知识点
map相关知识和运用.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号