Hadoop综合大作业
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
我所用到短篇小说是傲慢与偏见,为了方便后续处理,对小说的特殊符号进行了处理,结果如图。

载入数据

创建查表
最终结果:
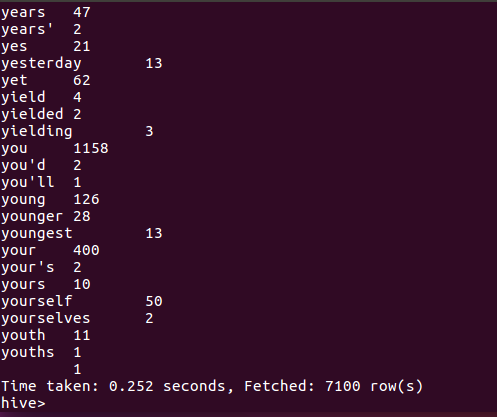
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
因为我爬取的大作业中的内容全都是封装在一个json中的,无法单独取出来,所以我选择用之前校园网爬取的数据导出成csv格式,代码如下
# -*- coding: UTF-8 -*-
# -*- coder: mzp -*-
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime
import pandas
def gzcc_content_info(content_url):
content_info = {}
resp = requests.get(content_url)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text, 'html.parser')
match_str = {'author': '作者:(.*)\s+[审核]?', 'examine': '审核:(.*)\s+[来源]?', 'source': '来源:(.*)\s+[摄影]?', \
'photography': '摄影:(.*)\s+[点击]'}
remarks = soup.select('.show-info')[0].text
for i in match_str:
if re.match('.*' + match_str[i], remarks):
content_info[i] = re.search(match_str[i], remarks).group(1).split("\xa0")[0]
else:
content_info[i] = " "
time = re.search('\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}', remarks).group()
content_info['time'] = datetime.strptime(time, '%Y-%m-%d %H:%M:%S')
#content_info['title'] = soup.select('.show-title')[0].text
#content_info['url'] = content_url
#content_info['content'] = soup.select('#content')[0].text
# with open('test.txt', 'a', encoding='UTF-8') as story:
# story.write(content_info['content'])
return content_info
def gzcc_list_page(page_url):
page_news = []
res = requests.get(page_url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
news_list = soup.select('.news-list')[0]
news_point = news_list.select('li')
for i in news_point:
a = i.select('a')[0]['href']
page_news.append(gzcc_content_info(a))
return page_news
all_news = []
url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
n = int(soup.select('#pages')[0].select("a")[-2].text)
all_news.extend(gzcc_list_page(url))
for i in range(2, 5): # 这里改页数
all_news.extend(gzcc_list_page('http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)))
pan = pandas.DataFrame(all_news)
pan.to_csv('result9.csv', index=False)
然后将这个csv复制黏贴到当地的local/bigdatacase/dataset下,然后新建一个pre_deal.sh然后再让它俩生成一个txt
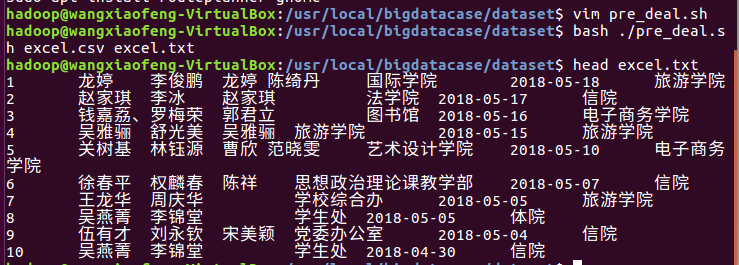
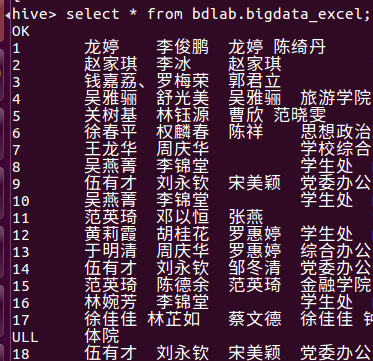
接着就是就是将它上传到hdfs 的hadoop/biddata/dataset中。然后在创建一个database,外键表将这个txt的数据填到表里面。
因为时间处理得不好,类型不是date,所以标示的是null。
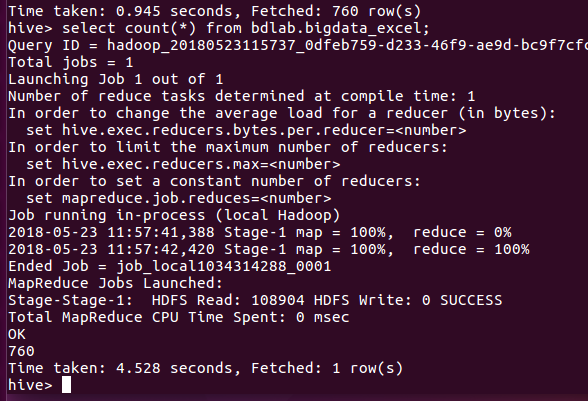
没有时间不能做出其他更好的数据分析,于是我分析了多少条数据。
结果是760条。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号