002-集合框架p2
集合框架p2
Set集合
-
Set集合是Collection中的另一个分支

-
Set系列集合的特点:无序:添加数据的顺序和获取出的数据顺序不一致;不重复;无索引
-
Set系列集合分支
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:排序(默认一定要大小升序排序)、不重复、无索引
-
不支持索引,所以没有get系列的方法
-
注意:Set要用到的常用方法,基本上就是Collection提供的,自己集合没有 额外新增的一些常用功能
HashSet集合的底层原理
-
哈希值
-
就是一个int类型的随机值,Java中的每个对象都有一个哈希值
-
Java中的所有对象,都可以调用Object类提供的hashCode方法,返回该对象自己的哈希值
public int hashCode(); // 返回对象的哈希码值
-
-
对象哈希值的特点
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的。
- 不同对象,他们的哈希值大概率不相等,但也有可能会相等(哈希碰撞)
- int的取值范围是-21亿多到+21亿多,但假如有45亿个对象就无法避免有些对象的哈希值重复
-
HashSet集合是基于哈希表存储数据的
-
哈希表
-
JDK8之前,哈希表 = 数组+链表
-
HashSet在创建对象后,第一次添加数据时,会创建一个默认为16的数组,默认加载因子为0.75,数组名为table。(ArrayList默认创建的长度是10)
-
添加数据时:
-
使用元素的哈希值对数组的长度做运算(与运算,可以理解成求余)计算出应存入的位置。
-
判断当前位置是否为null,如果是null直接存入
-
如果不为null,表示该位置有元素,调用equals方法比较。
-
相等,则说明重复,不存;
-
不相等,则存入数组
-
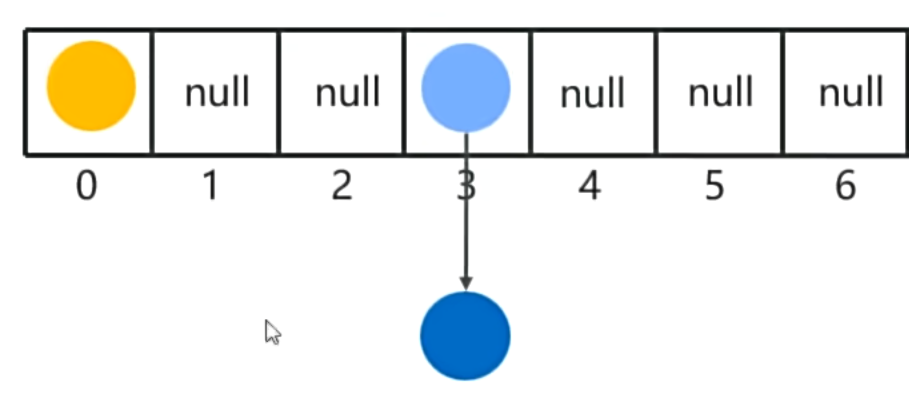
JDK8之前,新元素占老元素位置,老元素挂新元素下面
-
JDK8开始,新元素直接挂在老元素下面
-
这里的挂下面是在这个数组的该位置形成链,指向下一个元素,而不是存入数组下一个位置
-
-
-
-
-
JDK8开始,哈希表 = 数组+链表+红黑树(小数据往左,大数据往右,一样的不存,每条路线上黑节点数量一样)
-
哈希表是一种增删改查数据,性能都较好的数据结构
-
扩容
- JDK8之前:当存数据达到[长度 \(\times\) 加载因子](第一次为16 \(\times\) 0.75 = 12)时,数组长度扩容为原来的两倍,然后重新分配数据存储位置,防止链过长
- JDK8开始:当链表长度超过8,且数组长度>=64时,自动将链表转成红黑树
-
-
HashSet集合元素的去重操作
- 内容相同的不同对象的哈希值是不同的,此时无法自动去重
- 如果希望Set集合认为两个内容一样的对象时重复的,就必须重写对象的
hashCode()和equals()方法- 直接在IDEA里右键就能直接重写
LinkedHashSet的底层原理
- 依然是基于哈希表(数组、链表、红黑树)实现的
- 但是,它的每个元素都额外多了一个双链表的机制记录它前后有元素的位置
- 首尾指针指向第一个元素和最后一个加入的元素
- 每添加一个元素,加双链表指向其前后元素
TreeSet集合
- 底层是基于红黑树实现的排序
- 注意:
- 对于数值类型:Integer、Double,默认按照数值本身的大小进行生必须排序
- 对于字符串类型:默认按照首字母的编号升序排序
- 对于自定义类型如Student对象,TreeSet默认是无法直接排序的
TreeSet自定义排序规则
-
TreeSet默认不能给自定义对象排序,因为不知道大小规则
-
一定要解决,两种方案:
-
一、对象类实现一个Comparable比较接口,重写compare方法,指定大小比较规则
- 升序
- 如果左边大于右边,返回正整数;反之返回负整数;相等返回0
- 降序
- 反过来即可
- 如果不希望TreeSet去重,就用大于等于或者小于等于代替相等时返回0的逻辑

- 升序
-
二、public TreeSet (comparator c)集合自带比较器Comparator对象,指定比较规则
-
TreeSet 可以接一个比较器,可以new的时候直接传入比较器

-
-
比较时要注意,如果比较两个浮点数时,差值小于1,强转为int时会直接变成0,所以此时要不用if比较判断是返回1、0、-1,要不就调用Double自带的比较方法

-
-
总结

- 这是理论上的使用场景,实际上一般都用ArrayList和HashSet。
Map集合
-
认识map集合
-
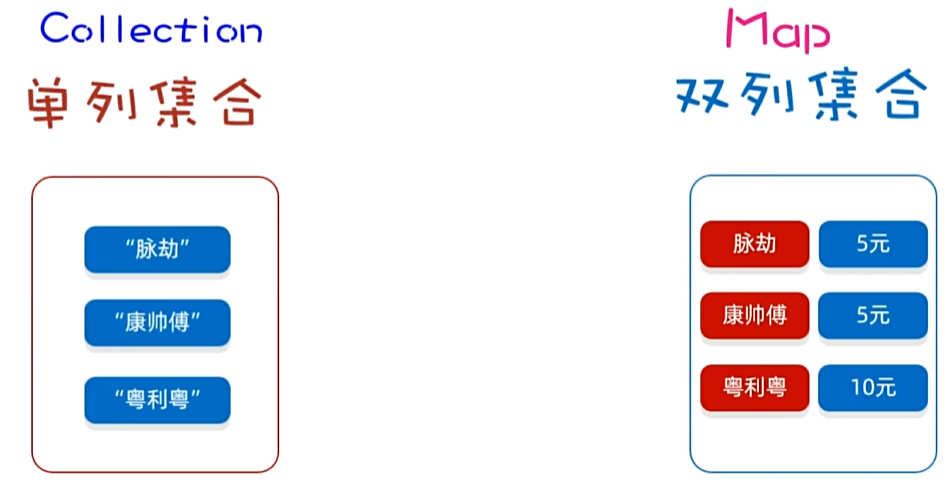
Map集合也被叫做“键值对集合”,格式:
-
Map集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值
-
使用场景:简易购物系统,存商品和购买数量之间存键值
Map集合的体系

- Map集合体系的特点
- 注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap(由键决定特点):无序、不重复、无索引、键值对都可以是null,值不做要求;(用的最多)
- LinkedHashMap(由键决定特点)::有序、不重复、无索引、键值对都可以是null,值不做要求。
- TreeMap(由键决定特点):按照大小默认升序排序、不重复、无索引、不可以是null,无法比较
Map集合的常用方法
-
Map是双列集合的祖宗,它的功能是全部双列集合都可以继承过来使用

Map集合的遍历方式
方法一:键找值
-
先获取Map集合全部的键,再通过遍历键来找值
-
需要用到Map的如下方法

方法二:键值对
-
把“键值对”看成一个整体进行遍历(难度较大)

方法三:Lambda表达式(jdk8开始)
-
需要用到如下Map的方法

-
示例

- 简化

Map集合的实现类
- 实际上,Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键的数据,不要值的数据
- 所以Map系列底层原理和Set一样
- 比较器设置也和Set一样
Stream流
- Stream流是jdk8开始新增的一套API(java.util.stream.*),可以用于操作集合或者数组的数据
- 优势:Stream流大量的结合了Lambda的语法风格来编程,功能强大,性能搞笑,代码简洁,可读性好
Stream流的使用步骤

获取Stream流
-
获取集合的Stream流


-
获取数组的Stream流


- of函数的那个形参是可变参数,可以获取零个、一个、多个参数。例如这里的字符串,也可以传入字符串数组。
-
Map集合怎么拿Stream流?
-
获取键流或值流或键值对流

-
Stream流的常用方法(中间方法)
-
中间方法指的是调用完成后会返回新的Stream流,可以继续使用(支持链式编程)

-
示例


- 注意合并流操作,如果合并的两个流不是同一类型,那么返回参数应该用公共父类接,例如这里的String和Integer合并用Object接
Stream流的终结方法
-
终结方法指的是调用完成后,不会返回新Stream了,没法继续使用流了

-
示例

收集Stream流
-
收集Stream流:就是把Stream流操作后的结果转回到集合或者数组中去返回
-
流只能收集一次!!!!!!!
-
Stream流只是方便操作集合、数组的手段;集合/数组:才是开发中的目的

-
示例

方法中的可变参数
-
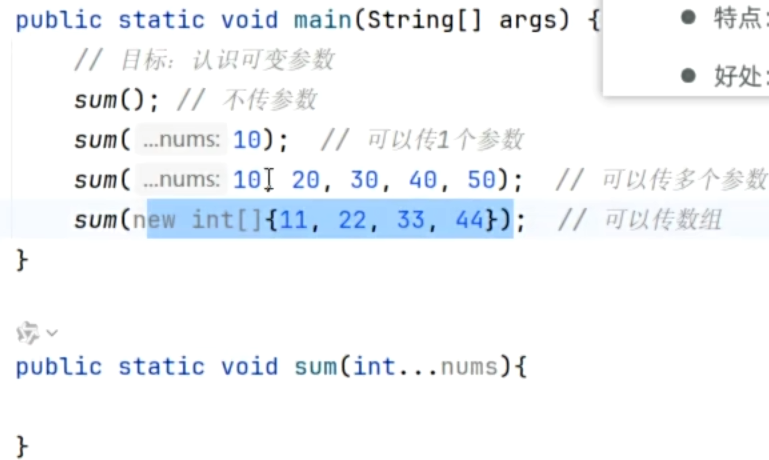
就是一种特殊形参,定义在方法、构造器的形参列表中,格式是:
数据类型...参数名称 -
特点与好处
- 特点:可以不传数据给它;可以传一个或多个数据给它;可以传一个数组给它
- 好处:尝尝用来灵活的接收数据
-
三个点和参数名称之间空不空格都可以
-
示例
-
内部怎么拿参数?
- 可变参数对内实际上就就是一个数组。这里nums就是数组
-
注意:
- 可变参数在形参列表中只能有一个
- 可变参数必须放在形参列表最后面
Collections工具类
-
是一个用来操作集合的工具类
-
Collections提供的静态方法

-
Collections只能支持对List集合进行排序


 浙公网安备 33010602011771号
浙公网安备 33010602011771号