
PLC:自动纠正数据集噪声,来洗洗数据集吧 | ICLR 2021 Spotlight
论文提出了更通用的特征相关噪声类别PMD,基于此类噪声构建了数据校准策略PLC来帮助模型更好地收敛,在生成数据集和真实数据集上的实验证明了其算法的有效性。论文提出的方案理论证明完备,应用起来十分简单,值得尝试
来源:晓飞的算法工程笔记 公众号
论文: Learning with Feature-Dependent Label Noise: A Progressive Approach

Introduction
在大型数据集中,由于标签的歧义以及标注者的大意,错误的标注是不可避免的。由于噪声对有监督训练的影响很大,所以在实际应用中研究如何处理错误的标注是至关重要的。
一些经典方法对噪声进行独立同分布(i.i.d.)的假设,认为噪声与数据特征无关,有其自身的规律。这些方法要么直接预测噪声分布来分辨噪声,要么引入额外的正则项/损失项来分辨噪声。而另外一些方法则证明,常用的损失项本身就能够抵抗这些独立同分布的噪声,不需要关心。
这些方法虽然有理论保证,但实际中表现都不佳,因为独立同分布的噪声假设是不真实的。这意味着,数据集的噪声是多样的,而且与数据特征相关,比如外表模糊的猫有可能被误认为狗。在光线不足或遮挡的情况下,图片失去了重要的视觉分辨线索,很容易被误标注。为了应对这个现实中的挑战,应对噪声的处理方法不仅需要有效,其通用性也是十分必要的。
SOTA方法多数采用数据重新校准(data-recalibrating)的策略来适应各种各样的数据噪声,该策略逐步确认可信的数据或逐步校正标签,然后使用这些数据进行训练。随着数据集更加准确,模型的准确率也会逐渐提高,最终收敛到高准确率。该策略很好地利用了深度网络的学习能力,在实践中获得不错的效果。
但目前这些策略的内在机制都没有完备的理论证明,解释为何这些策略可以使得模型收敛到理想的状态。这意味着这些策略都是case by case的,需要很小心地调整超参数,难以通用。
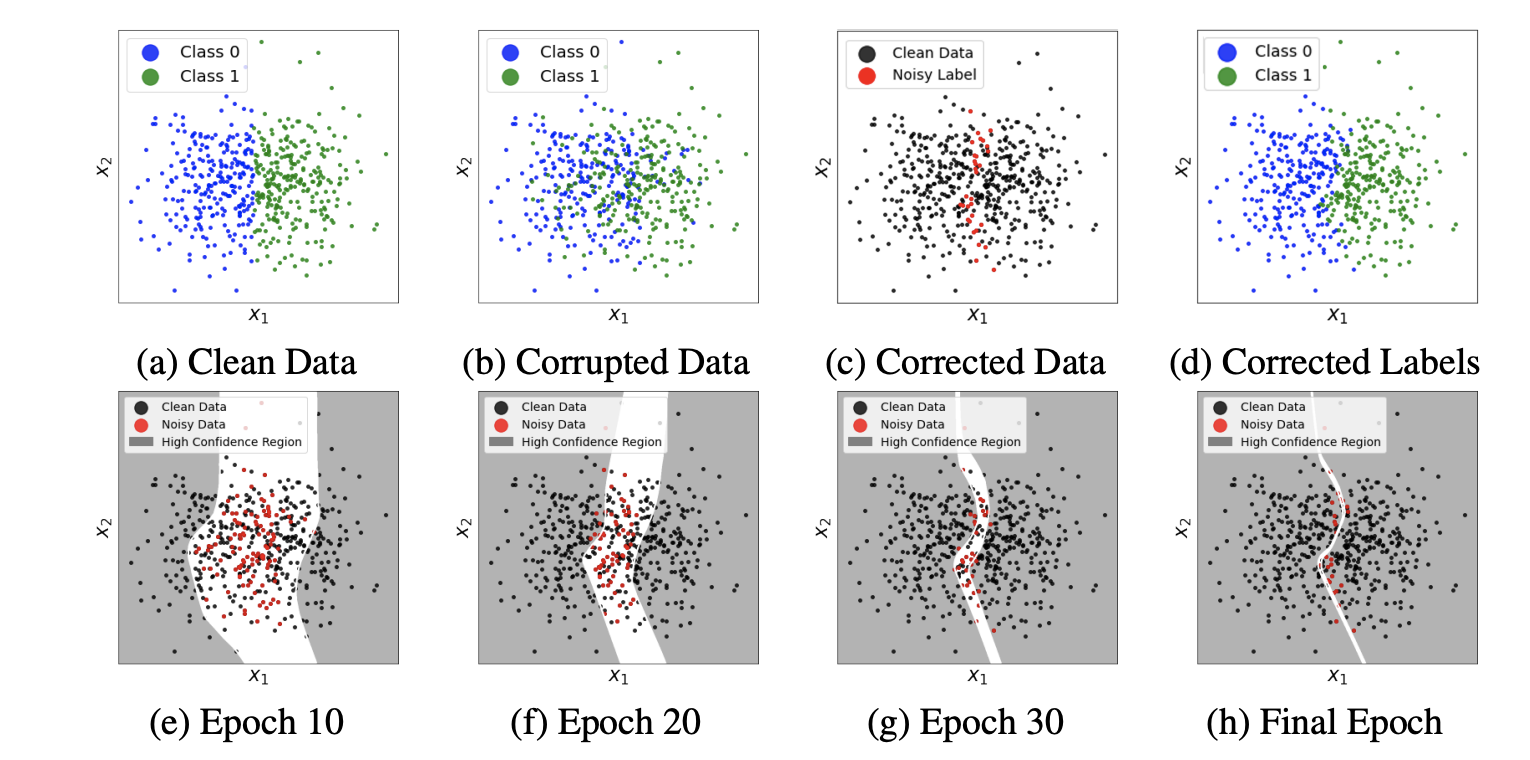
基于上面的分析,论文定义了更为常见的PMD噪声族(Polynomial Margin Dimishing Noise Family),包含除了显而易见的错误之外的任意类型噪声,更符合现实场景。基于PMD噪声族,论文提出了有理论保证的数据校准方法,根据噪声分类器的置信度逐步校准数据的标签。流程如图1所示,先从高置信度的数据开始,使用噪声分类器的预测结果校准这些数据,然后使用校准后的数据提升模型,交替进行标签校准和模型提升直到模型收敛。
Method
先定义一些数学符号,这里以二分类任务为例:
- 定义特征空间\(\mathcal{X}\),数据\((x,y)\)均从分布\(D=\mathcal{X}\times\{0,1\}\)采样而来。
- 定义\(\eta(x)=\mathbb{P}[y=1|x]\)为后验概率,值越大代表正标签越明显,而值越小则代表负标签越明显。
- 定义噪声函数\(\tau_{0,1}(x)=\mathbb{P}=[\tilde{y}=1 | y=0, x]\)和\(\tau_{1,0}(x)=\mathbb{P}=[\tilde{y}=0 | y=1, x]\),其中\(\tilde{y}\)为错误标签。假设数据\(x\)的真实标签为\(y=0\),则有\(\tau_{0,1}(x)\)概率错误地标注为1。
- 定义\(\tilde{\eta}(x)=\mathbb{P}[\tilde{y}=1|x]\)为噪声后验概率。
- 定义\(\eta^{*}(x)=\mathbb{I}_{\eta(x)\ge\frac{1}{2}}\)为贝叶斯最优分类器,当A为真时\(\mathbb{I}_A=1\),否则为0。
- 定义\(f(x):\mathcal{X}\to [0,1]\)为分类器打分函数,一般是网络的softmax输出。
Poly-Margin Diminishing Noise
PMD噪声只将噪声函数\(\tau\)约束在特定的\(\eta(x)\)中间区域,区域内的噪声函数\(\tau\)的值多大都无所谓。这样的形式不仅能够覆盖特征无关的场景,也能泛化到之前的一些噪声研究的特定场景中。
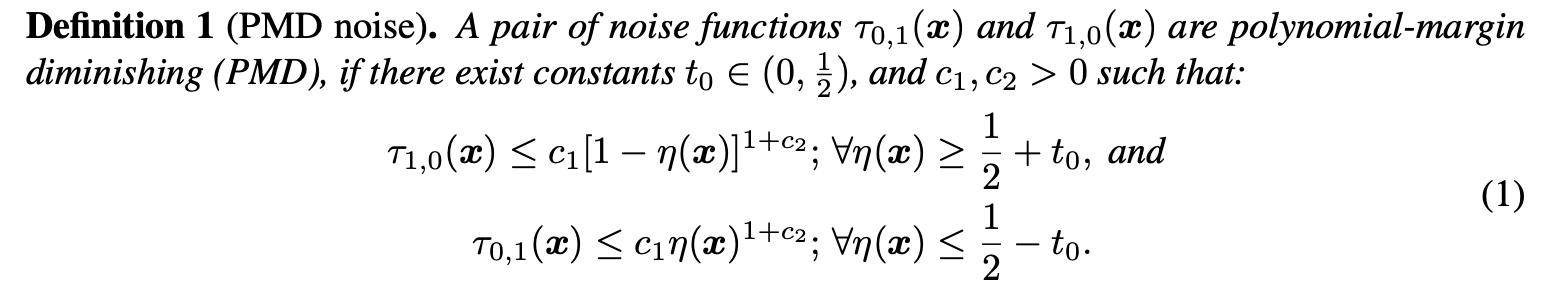
PMD噪声的定义如上所示,\(t_0\)可认为是左右两边的间隔(margin)。PMD条件只要求\(\tau\)的上界是多项式的并且在贝叶斯分类器置信的区域单调递减,而\(\tau_{0,1}(x)\)和\(\tau_{1,0}(x)\)在\(\{ x:|\eta(x)-\frac{1}{2}| < t_0 \}\)区域内可为任意值。
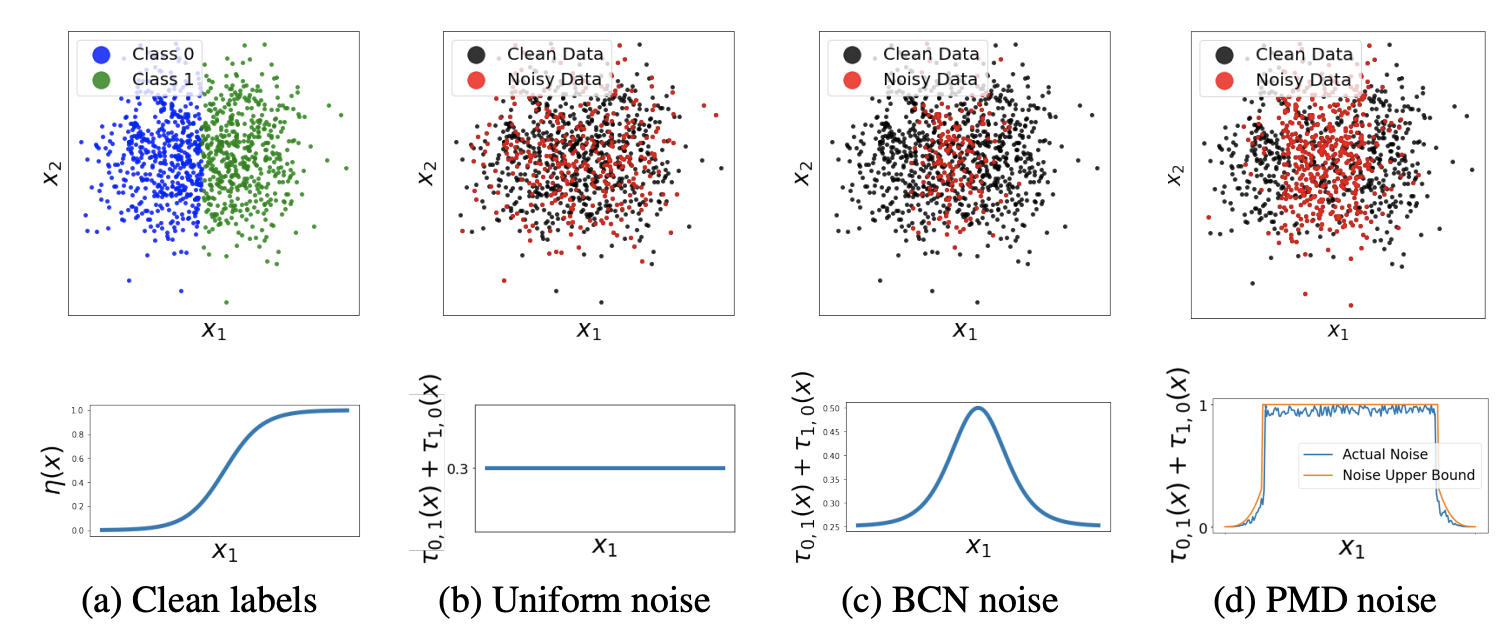
前面的PMD噪声描述可能比较抽象,论文提供了可视化图片来帮助大家理解:
- 图a是贝叶斯最优分类器的结果,即正确标签。从下面的\(\eta(x)\)曲线可以看出,两边数据的二分类概率差别较大,是容易区分的。而中间的数据的二分类概率比较接近,有较大的误标注的可能,也是我们需要重点关注的。
- 图b是均匀噪声,该噪声认为误分概率与特征无关,每个数据点都有相同的概率被误分。上图中黑色的是被认为是正确的数据,红色则是被认为属于噪声的数据,可以看到,经过均匀噪声处理后,数据分布比较乱。
- 图c是BCN噪声,噪声值随着\(\eta^{*}(x)\)的置信而下降。从上图可以看出,处理后的噪声数据基本都落在中间区域,也就是容易误识别的地方。但由于BCN噪声的边界与\(\eta^{*}(x)\)高度相关,而实践中一般要用模型的输出来近似\(\eta^{*}(x)\),在噪声程度较大的场景显然会有较大的出入。
- 图d是PMD噪声,约束噪声在\(\eta^{*}(x)\)的中间区域,区域内的噪声值随意。这样做的好处在于,可以通过调控区域大小来应对不同的噪声程度,只要不是显而易见的错误都可以(即在\(\eta\)较高和较低的地方标注错误)适用。从上图可以看出,处理后的干净数据基本都分布在两边,也就是比较置信的地方。
The Progressive Correction Algorithm

基于PMD噪声,论文提出逐步训练和纠正标签的PLC(Progressive Label Correction)算法。该算法首先使用原数据集进行warm-up阶段的训练,得到一个尚未拟合噪声的初步网络。接着,使用warm-up得到的初步网络对高置信度的数据进行标签的纠正,论文认为(也理论证明了)噪声分类器\(f\)的高置信度预测能与贝叶斯最优分类器\(\eta^{*}\)保持一致。
纠正标签时,先选择一个高阈值\(\theta\)。如果\(f\)预测标签跟标注标签\(\tilde{y}\)不同且预测置信度高于阈值,即\(|f(x)-1/2|>\theta\),则将\(\tilde{y}\)纠正为\(f\)的预测标签。重复进行标签的纠正以及用纠正的数据集进行模型的重新训练,直到没有标签被纠正为止。
接着,稍微降低阈值\(\theta\),使用降低的阈值进重复上述的步骤,直到模型收敛。为了方便后面的理论分析,论文定义了一个连续递增阈值\(T\),让\(\theta=1/2-T\),具体逻辑如算法1所示。
-
Generalizing to the multi-class scenario
上面的描述都是二分类的场景,在多分类场景中,先定义\(f_i(x)\)为分类器对标签\(i\)的预测概率,\(h_x=argmax_if_i(x)\)为分类器预测的标签。将\(|f(x)-\frac{1}{2}|\)的判断修改为|\(f_{h_x}(x)-f_{\tilde{y}}(x)|\),当结果大于阈值\(\theta\)时,将标签\(\tilde{y}\)修改为标签\(h_x\)。在实践过程中,将差值判断加上对数会更加鲁棒。
Analysis
这一块是论文的核心,主要从理论的角度验证论文提出方法的通用性和正确性。这里我们就不继续讲解了,有兴趣的可以去看看原文,我们只需要知道这个算法的用法就够了。
Experiment
数据集噪声问题目前还没有公开的数据集,所以需要生成数据集进行实验,论文主要在CIFAR-10和CIFAR-100上进行数据生成和实验。先在原数据上训练一个网络,用该网络的预测概率近似真实的后验概率\(\eta\)。基于\(\eta\)重新采样数据\(x\)的标签\(y_x\sim\eta(x)\)作为干净数据集,前面训练得到的网络作为贝叶斯最优分类器\(\eta^{*}:\mathcal{X}\to\{1,\cdots,C\}\),其中\(C\)为类别数。需要注意的是,多类别场景中,\(\eta(x)\)输出为向量,\(\eta_i(x)\)对应向量的第\(i\)个元素。
对于噪声的生成,有特征相关噪声和独立同分布噪声(i.d.d)两种:
- 对于特征相关噪声,为了增加噪声的挑战难度,每个数据\(x\)根据噪声函数均可能从最高置信分类\(u_x\)变为第二置信分类\(s_x\),其中噪声函数与\(\eta(x)\)的概率相关。\(s_x\)对于\(\eta^{*}(x)\)是混淆度最高的类别,最能影响模型的性能。另外,由于\(y_x\)是从\(\eta(x)\)采样而来的,是置信度最高的类别,所以可认为\(y_x\)就是\(u_x\)。总体而言,对于数据\(x\),生成数据时要么变为\(s_x\),要么保持\(u_x\)。特征相关噪声有以下三种PMD噪声族内的噪声函数:
![]()
由于\(\eta(x)\)是无法修改的,为了能够控制噪声程度,唯一能做的就是为噪声函数\(\tau_{u_x,s_x}\)加上常量因子,使得最终的噪声比例符合预期。对于PMD噪声,35%和70%的噪声程度即代表35%和70%的干净数据被修改成噪声。 - 独立同分布噪声通过构建噪声转换矩阵\(T\)来进行标签的修改,其中\(T_{ij}=P(\tilde{y}=j|y=i)=\tau_{ij}\)为真实标签\(y=i\)转换为标签\(j\)的概率。对于标签为\(i\)的数据,将其标签修改为从矩阵\(T\)的第\(i\)行的概率分布采样而来的标签。论文采用了常见两种独立同分布噪声:1)均匀噪声(Uniform noise),真实标签\(i\)转换成其它标签的概率相同,即\(T_{ij}=\tau/(C-1)\),其中\(i\ne j\),\(T_{ii}=1-\tau\),\(\tau\)为噪声程度。2)非对称噪声(Asymmetric noise),真实标签\(i\)有概率\(T_{ij}=\tau\)概率转换成标签\(j\),或\(T_{ii}=1-\tau\)概率保持不变。
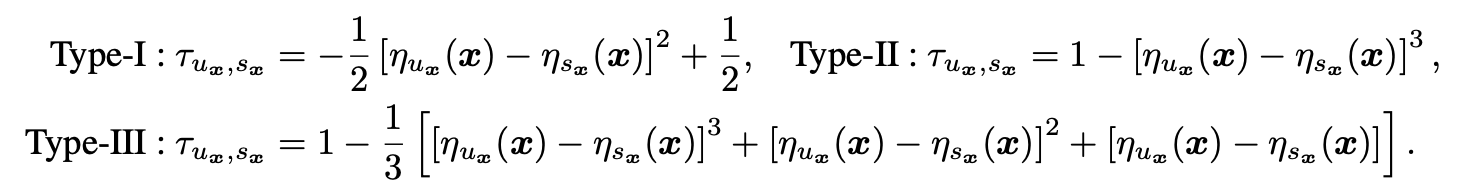
在实验的时候,部分实验会组合特征相关噪声和独立同分布噪声进行噪声数据集生成和实验,最后的验证标准取模型在验证集上的准确率。训练时,采用128 batch size、0.01学习率和SGD优化器,共训练180周期保证收敛,重复3次取均值和标准差。
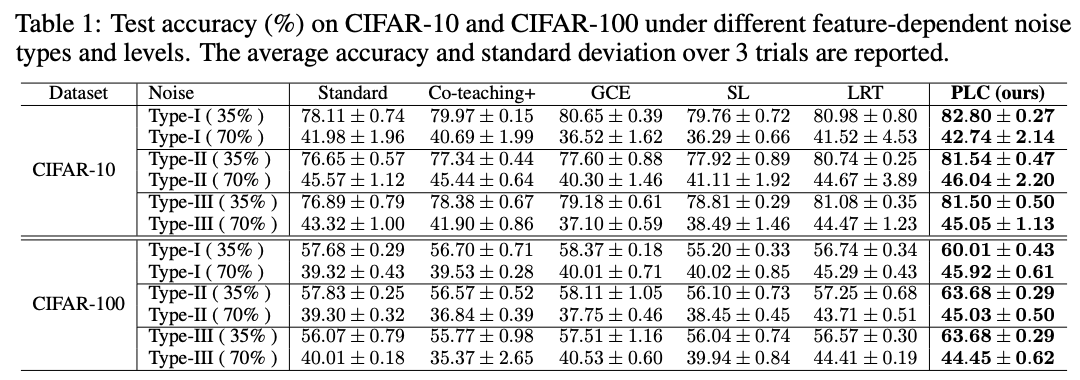
PMD噪声测试,在35%和70%噪声程度下的性能对比。
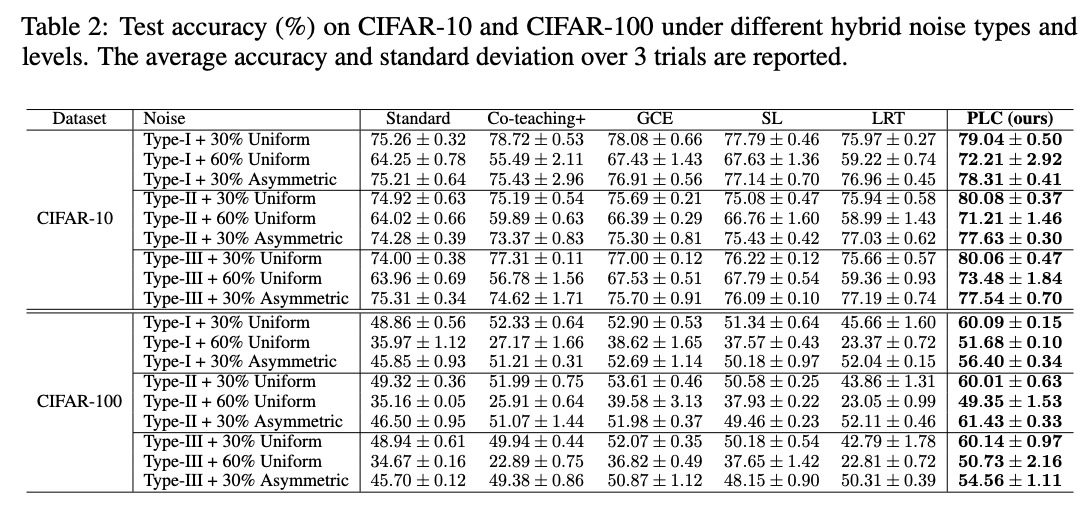
混合噪声测试,在50%-70%噪声程度下的性能对比。
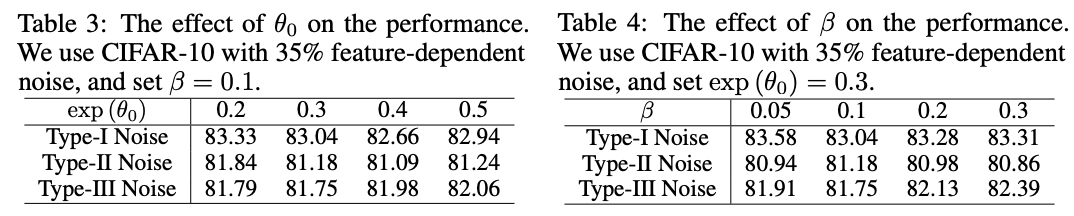
超参数对比实验。
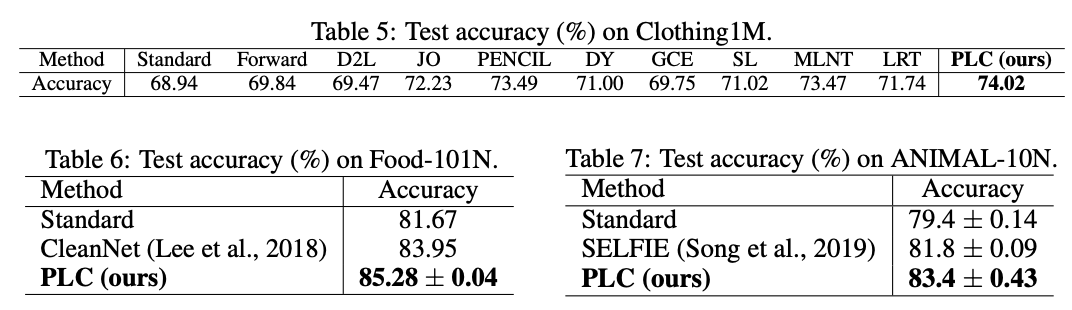
在真实数据集上的性能对比。
Conclusion
论文提出了更通用的特征相关噪声类别PMD,基于此类噪声构建了数据校准策略PLC来帮助模型更好地收敛,在生成数据集和真实数据集上的实验证明了其算法的有效性。论文提出的方案理论证明完备,应用起来十分简单,值得尝试。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号