

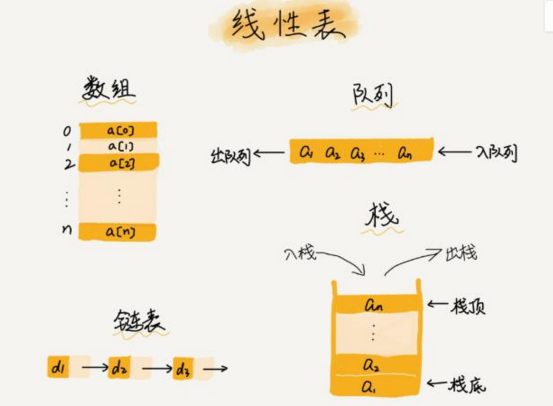
数组
1.数组定义
数组:是一种线性数据结构,用连续的内存空间,来存储相同类型的数据
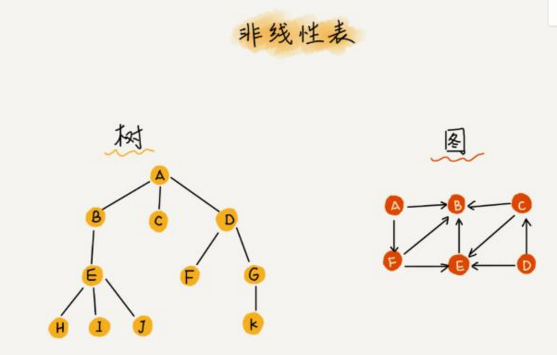
2.线性表与非线性表
线性表:数组、链表、队列、栈等
非线性表:二叉树、堆、图等
如下图
3.数组特性
3.1 随机访问
3.1.1 数组为什么支持随机访问
因为数组是线性并且占用连续的内存空间的相同类型的数据。
3.1.2 数组是如何实现根据下标随机访问数据元素的?
寻址公式:a[i]_address = base_address + i * data_type_size
注:内存块首地址为 base_address ,data_type_size表示数组中每个元素的大小
3.1.3 数组和链表的区别(??)
链表插入删除操作时,时间复杂度为O(1),查找时候的时间复杂度为O(n);
数组根据下标随机访问时,时间复杂度为O(1);而如果是直接查找,即便是排好序的数组,用二分查找,时间复杂度也是O(logn);
所以,注意,不要直接说数组的查找的时间复杂度为O(1),注意其中的区别
3.2 低效的插入和删除
数组为了保持内存的连续性,会导致插入和删除这两个操作比较低效;
在插入操作中,需要把插入元素之后的元素全部往后移动;
在删除 操作中,需要把删除元素之后的元素全部往前移动;
最好时间复杂度O(1),最坏时间复杂度O(n),平均时间复杂度都是O(n);
3.2.1 插入操作
注意:
① 如果数组中的数据是有序的,我们在某一个位置插入一个新的元素时,就必须按照刚才的方法,搬移k之后的数据(k表示插入元素的位置为k)。
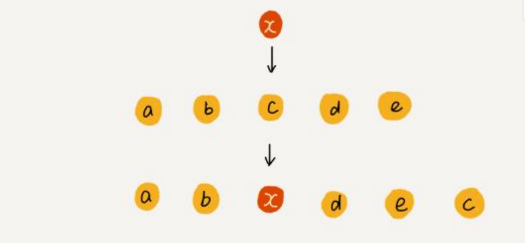
② 但是,如果数组中存储的数据并没有任何规律,数组只是作为一个存储数据的集合。
在第k个位置插入元素时,则为了避免大规模数据的移动,我们可以:直接将第k位的数据搬移到数组元素的最后,把新的元素直接放入第k个位置。
在特定场景下,②中的时间复杂度会降为O(1) ;这个处理思想在快排中会用到。
例如:
3.2.2 删除操作
如果我们要删除第k个位置的数据,为了内存的连续性,也需要搬移数据。
但是,实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。我们可以把多次删除操作集中在一起执行,来提高删除效率。
例如:数组a[10]中存储了8个元素:a,b,c,d,e,f,g,h 。现在,依次删除a,b,c三个元素。

为了避免d,e,f,g,h这几个数据被搬移三次,我们可以先记录下已经删除的数据。
每次删除操作并不是真正的搬移数据,只是记录数据已经删除,
当数组中没有更多空间存储数据时,再触发一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
JVM标记清除垃圾回收算法:就是用的这个思想。
4.数组访问越界问题
c语言中可能会造成逻辑错误,java中会抛出java.lang.ArrayIndexOutOfBoundsException错误。
很多计算机病毒也正是利用到了代码中的数组越界可以访问非法地址的漏洞,来攻击系统,所以写代码要警惕数组越界。
5.容器是否完全代替数组
针对数组类型,很多语言提供了容器类,例如java中的ArrayList,C++中的vector。
那么在项目开发中,什么时候适合用数组,什么时候适合用容器呢?
这里以java为例。
ArrayList最大的优势就是
- 可以将很多数组的操作的细节封装起来;例如:前面提到的数组插入,删除数据时需要搬移其他数据等。
- 支持动态扩展(每次存储空间不够时,自动扩容1.5倍)
数组本身在定义的时候需要预先指定大小,因为需要分配连续的内存空间。
而如果插入数据超过数据长度时,需要我们重新分配一块更大的空间,将原来的数据复制过去,然后再将新数据插入。
注:ArrayList:如果事先能确定需要存储的数据大小,最好在创建ArrayList的时候事先指定数据大小,因为扩容操作涉及内存的申请和数据搬移,比较耗时。
在使用过程中,下面一些情况下,数组可能更合适;
- Java ArrayList 无法存储基本类型,比如int、long ,需要封装为Integer,Long类,而Autoboxing、Unboxing则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,可以选用数组。
- 如果数据大小事先已知,并且对数据的操作非常简单,用不到ArrayList提供的大部分方法,也可以直接使用数组
- 当要表示多维数组时,用数组会更加直观。比如Object[][] array;而用容器的话:ArrayList<ArrayList> array
- 如果你是做一些非常底层的开发:例如开发网络框架、性能的优化需要做到极致,这个时候数组就会优于容器。成为首选。
6.在大多数编程语言中,数组为什么要从0开始编号,而不是从1开始编号?
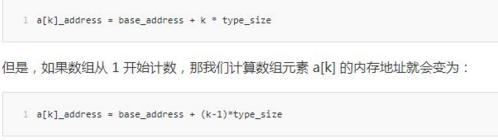
对比两个公式,我们发现,从1开始编号的话,每次随机访问数组元素都多了一次减法运算,对于CPU来说,就是多了一次减法指令。而我们要把效率尽可能做到极致。
思考题:
1.你理解的:JVM中的标记清除垃圾回收算法
2.类比一维数组内存寻址公式,思考二维数组的内存寻址公式是怎样的?
a[i][j] 的地址: base_address+(i*j+j)type_size

 浙公网安备 33010602011771号
浙公网安备 33010602011771号