


Flume的安装与单点数据采集
基于Flume的单点数据采集
1 安装Flume
1.1 复制Flume的下载镜像
https://flume.apache.org/download.html

复制Flume镜像地址

1.2 新建目录并切换到sortware目录下
sudo mkdir -p /usr/software
cd /usr/software
1.3 下载Flume安装包到此目录
以下代码中所列地址只作为格式说明,不能作为实际下载地址使用,实际地址从官网中复制
wget https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz
用国内镜像吧,国外镜像能把人逼疯
wget https://repo.huaweicloud.com:8443/artifactory/apache-local/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
1.4 解压 Flume文件
app为提前建好的目录
[root@hadoop01 usr]# mkdir app
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/app/
1.5 进入flume的配置目录并命名
cd /usr/app/apache-flume-1.9.0-bin/conf
将conf目录下的“flume-env.sh.template”文件复制并重命名
cp flume-env.sh.template flume-env.sh
打开复制重命名后的“flume-env.sh”文件
vi flume-env.sh
向文件中添加Java的安装位置(以下代码只做格式说明,实际安装位置根据自己安装的Java实际路径填写)
export JAVA_HOME=/opt/programs/jdk1.8.0_202
打开系统的环境配置文件
vi /etc/profile
在文件中追加以下内容
export FLUME_HOME=/usr/app/apache-flume-1.9.0-bin/
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
保存退出后执行以下命令,使更新后的环境变量生效
source /etc/profile
执行以下命令验证Flume是否安装成功
flume-ng version
执行成功会出现版本号例如:
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
2 单机操作Flume
切换到usr下新建一个test目录
mkdir test
在test目录下创建子目录flume-test
cd test
mkdir flume-test
2.1 单点采集数据到本地
进入flume-test目录
cd flume-test
在flume-test目录下创建子目录1,以及子1目录下的两个子目录input和output
mkdir -p 1/input
mkdir 1/output
进入目录1
cd 1
创建新文件file-logger.conf,编写采集方案
vi file-logger.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/test/flume-test/1/input
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /usr/test/flume-test/1/output
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
执行以下命令启动flume,此时进程不会退出
flume-ng agent -c conf/ -f file-logger.conf -n a1 -Dflume.root.logger=INFO,console
成功启动的话会有类似如下标志
2025-10-11 15:00:00,xxx INFO node.Application: Starting new configuration:{ sourceRunners:{r1=...} sinkRunners:{k1=SinkRunner: {...}} channels:{c1=...} }
2025-10-11 15:00:00,xxx INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started
2025-10-11 15:00:00,xxx INFO instrumentation.MonitoredCounterGroup: Component type: SOURCE, name: r1 started
2025-10-11 15:00:00,xxx INFO instrumentation.MonitoredCounterGroup: Component type: SINK, name: k1 started
在input目录创建测试目录
echo "Flume test data: Hello Flume!" > /usr/test/flume-test/1/input/test-data.txt
Flume采集会监控到input目录的变化,会出现如下反馈信息:
test-data.txt文件名后天机了一个尾部,采集到的数据会出现在output子目录中
poolingFileEventReader.java:497)] Preparing to move file /usr/test/flume-test/1/input/test-data.txt to /usr/test/flume-test/1/input/test-data.txt.COMPLETED
2.2 单点采集数据到HDFS
将hadoop中的“shar/hadoop/common/lib”子目录中的guava-27.0-jre.jar文件复制到flume的子目录lib中
cp /opt/programs/hadoop-3.3.6/share/hadoop/common/lib/guava-27.0-jre.jar /usr/app/apache-flume-1.9.0-bin/lib/
将flume子目录lib中的"guava-11.02.jar"文件重命名
mv /usr/app/apache-flume-1.9.0-bin/lib/guava-11.0.2.jar /usr/app/apache-flume-1.9.0-bin/lib/guava-11.0.2.jar.back
在所有节点上启动zookeeper
zkServer.sh start
在主节点上启动HDFS
start-dfs.sh
在主节点上启动YARN
start-yarn.sh
进入flume-test目录
cd /usr/test/flume-test
在flume-test目录下,一次创建好两级子目录2/input
mkdir -p 2/input
进入目录2
cd 2
创建新文件hdfs-logger.conf,编写采集方案
vi hdfs-logger.conf
向文件中写入方案
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir = /usr/test/flume-test/2/input
a1.sinks.k1.type=hdfs
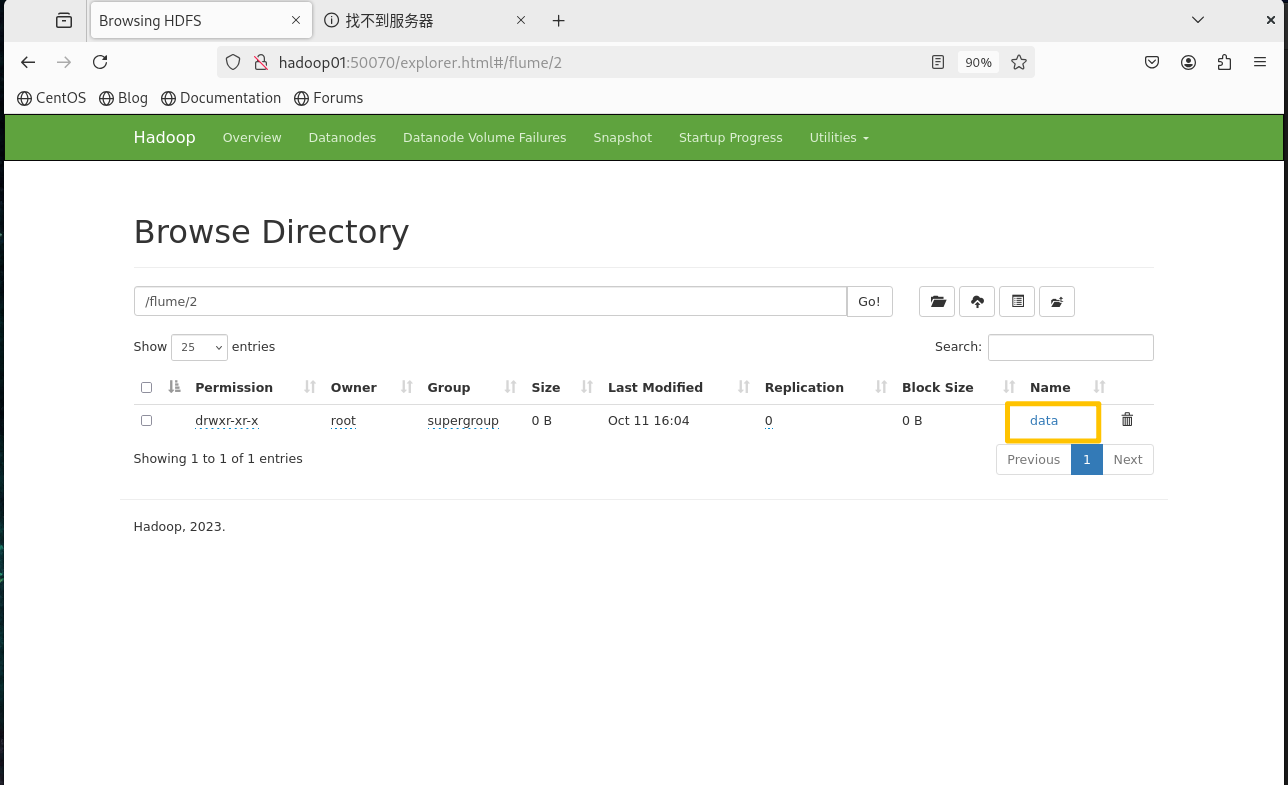
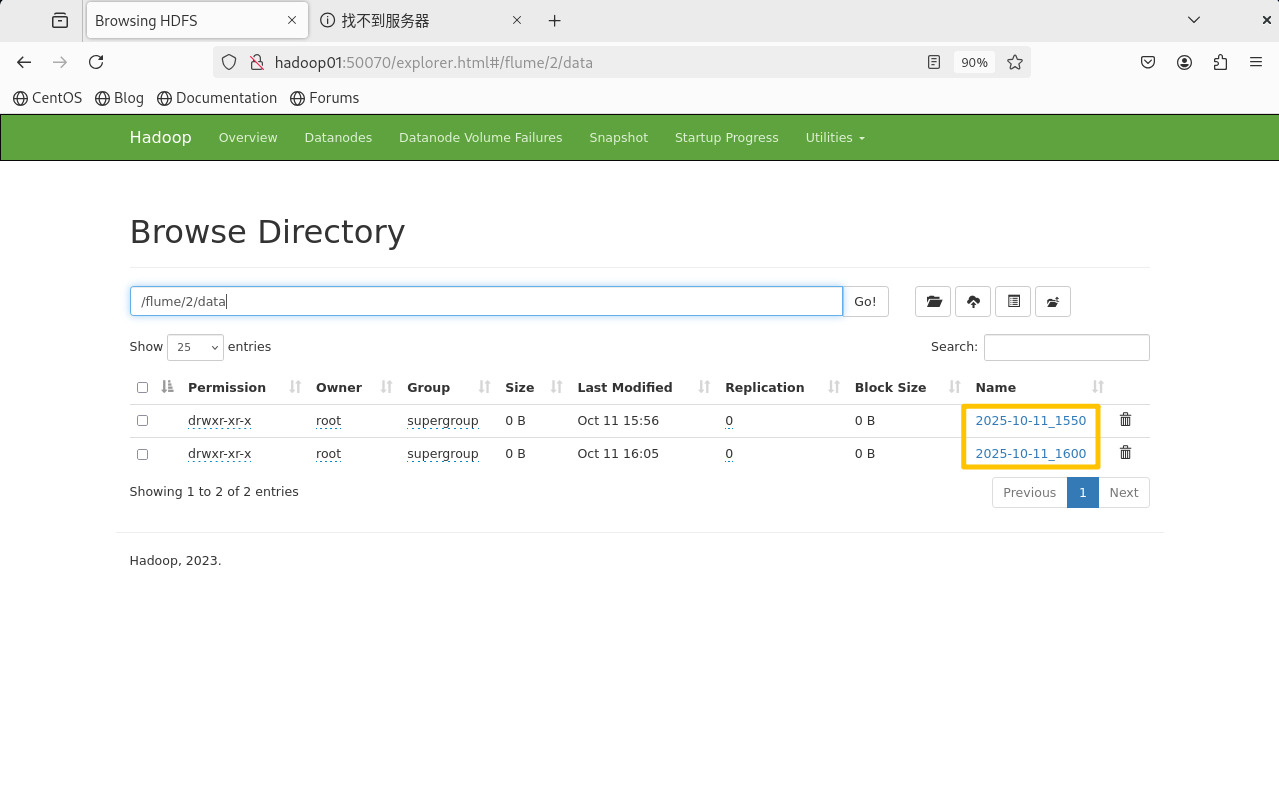
a1.sinks.k1.hdfs.path=hdfs://ns/flume/2/data/%Y-%m-%d%H%M
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240000
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit=minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动Flume
flume-ng agent -c conf/ -f hdfs-logger.conf -n a1 -Dflume.root.logger=INFO.console
在集群的另一个节点终端上执行ssh命令登录到主节点上(这里以hadoop02登录hadoop01为例)
ssh hadoop01
进入子目录"1"下的"input"目录
cd /usr/test/flume-test/2/input
在当前目录,采取以下命令的方式为"input"目录动态创建数据素材文件
echo "hello world" > test.log
创建后执行以下命令可以退出ssh登录
exit
Flume采集进程输出采集完成的提示信息例如:
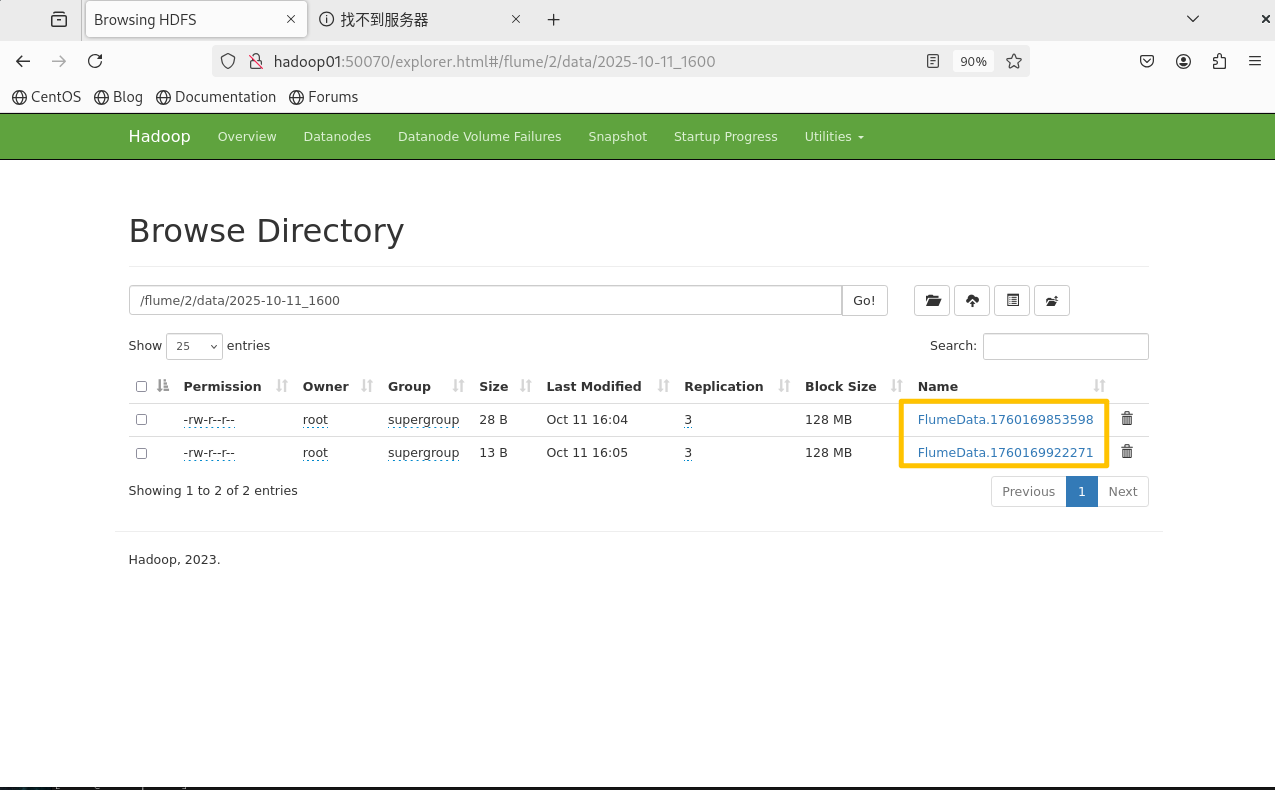
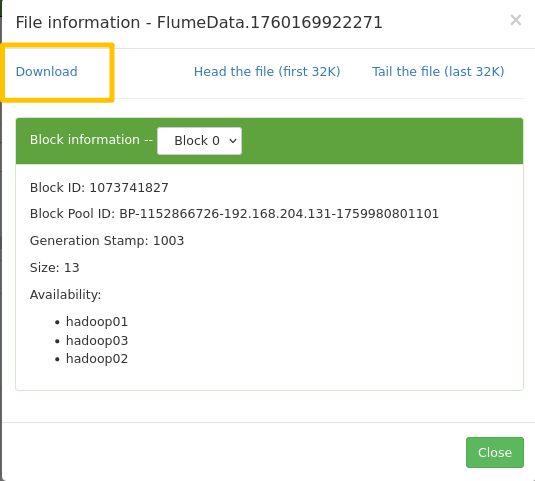
2025-10-11 16:05:28,446 INFO hdfs.BucketWriter: Renaming hdfs://ns/flume/2/data/2025-10-11_1600/FlumeData.1760169922271.tmp to hdfs://ns/flume/2/data/2025-10-11_1600/FlumeData.1760169922271
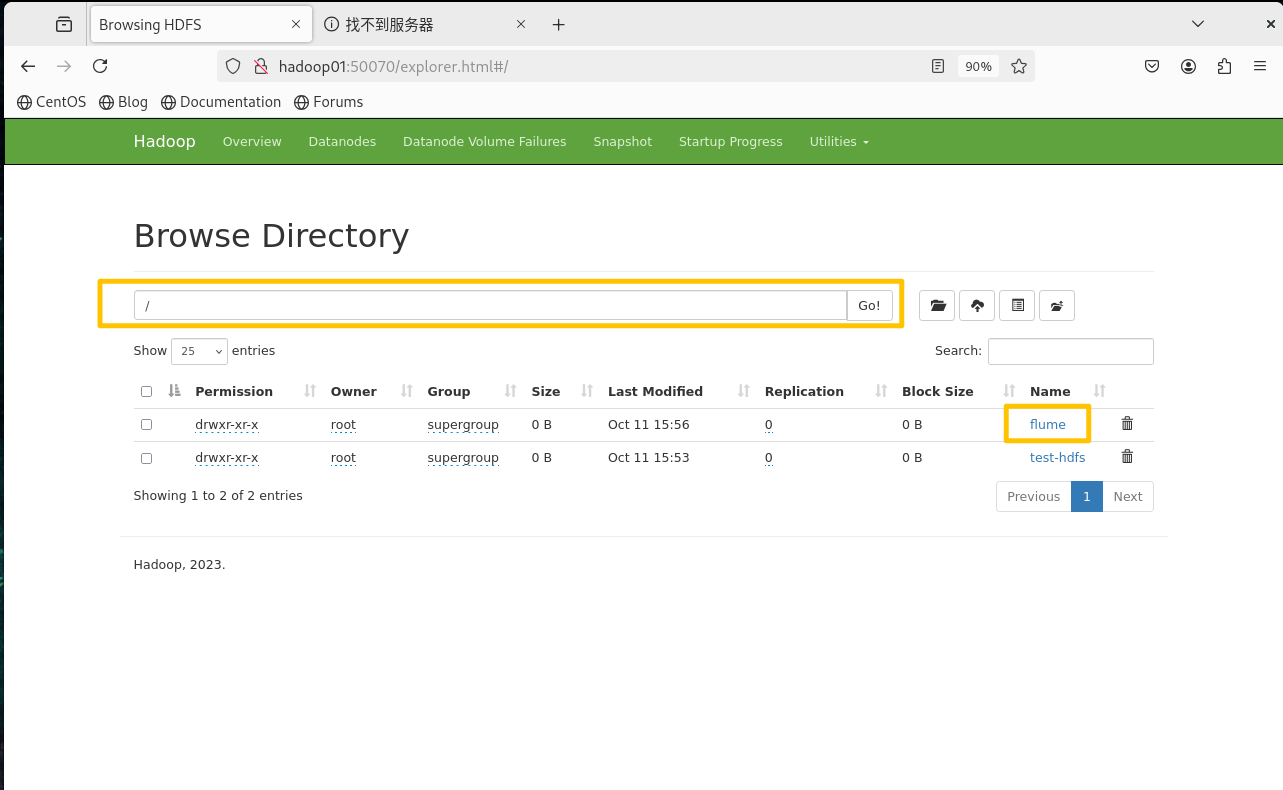
在浏览器的地址栏中输入HDFS的地址,在页面的菜单栏选择"Utilities"菜单栏列表,选择第一个子菜单选项"Browse the file system",使页面跳转到"Browse Directory"页面
HDFS的地址是根据hadoop目录里面的hdfs-site.xml里面的内容:
```
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:50070</value>
</property>
```

flume -> 2 -> data -> 日期 -> 时间

2.3 采集持续增加的内容,保存到HDFS
进入"flume-test"目录
cd /usr/test/flume-test
在"flume-test"目录下,一次创建好两级子目录"3/input"
mkdir -p 3/input
进入目录"3"
cd 3
将原来目录"2"下的配置采集方案复制到目录"3"中,并重命名
cp ../2/hdfs-logger.conf increase-logger.conf
vi increase-logger.conf
打开"increase-logger.conf"文件(注:以下只列出了被修改处代码)
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=exec
a1.sources.r1.spoolDir = /usr/test/flume-test/3/input
a1.sources.r1.command = tail -F /usr/test/flume-test/3/input/test.log
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path = hdfs://ns/flume/3/data/%Y-%m-%d_%H%M
a1.sinks.k1.hdfs.rollInterval=600
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=10000
a1.sinks.k1.hdfs.filePrefix=transaction_log
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit=minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/usr/test/flume-test/3/dataCheckpointDir
a1.channels.c1.dataDirs=/usr/test/flume-test/3/data
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动Flume
flume-ng agent -c conf/ -f increase-logger.conf -n a1 -Dflume.root.logger=INFO,console
开启另一个主节点终端,进入"3"目录的子目录"input",创建"test.log"文件
cd /usr/test/flume-test/3/input
vi test.log
向"test.log"文件中写入新的内容,写入后关闭。进入HDFS页面检测结果。
2.4 对持续增加内容的第二种采集方式
进入"flume-test"目录
cd /usr/test/flume-test
在"flume-test"目录下,一次创建好两级子目录"4/input"
mkdir -p 4/input
进入目录"4"
cd 4
将原来目录"2"下的配置采集方案复制到目录"4"中,并重命名
cp ../2/hdfs-logger.conf tail-logger.conf
打开"tail-logger.conf"文件
vi tail-logger.conf
在文件中修改以下内容(注:以下只列出了被修改处代码)
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=TAILDIR
#a1.sources.r1.spoolDir = /usr/test/flume-test/4/input
a1.sources.r1.positionFile=/usr/test/flume-test/4/record/taildir_position.json
a1.sources.r1.filegroups=f1 f2
a1.sources.r1.filegroups.f1=/usr/test/flume-test/4/input/test.txt
a1.sources.r1.filegroups.f2=/usr/test/flume-test/4/input/.*log.*
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path = hdfs://ns/flume/2/data/%Y-%m-%d_%H%M
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240000
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit=minute
a1.sinks.k1.hdfs.useLocalTimeStamp=true
#a1.channels.c1.type=memory
#a1.channels.c1.capacity=1000
#a1.channels.c1.transactionCapacity=100
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/usr/test/flume-test/4/dataCheckpointDir
a1.channels.c1.dataDirs=/usr/test/flume-test/4/data
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动Flume
flume-ng agent -c conf/ -f tail-logger.conf -n a1 -Dflume.root.logger=INFO,console
另开启一个主节点终端进入"4"目录的子目录"input",创建"test.log"文件。并将"test.log"文件多次打开、关闭、并在打开后添加不同的新内容
cd /usr/test/flume-test/4/input
vi test.log
在"input"目录下,再创建一个"test.txt"文件
vi test.txt
像"test.log"文件操作一样,也多次打开、关闭"test.txt"文件并在打开后添加不同的新内容,最后登录HDFS页面检测结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号