


CentOS9配置Hadoop群集
配置Hadoop群集环境
前情提要:
用到的虚拟机版本为CentOS9
以下是需要按照自己本机内容进行修改的,以及它们的查询方法:
-
网卡名:ens160
命 令:ip addr

-
IP地址:192.168.2040131
子网掩码:
255.255.255.0(即/24)命 令:ifconfig

网关:192.168.204.2(我的在ifconfig命令里面没有显示出来)
命令:ip route

DNS:192.168.204.2
命令:nmcli device show ens160 | grep DNS(这里的ens160是自己的网卡名)

1 修改主机名和设置固定IP
1.1 设置静态IP、网关、DNS(删除多余连接后执行)
nmcli con mod ens160 ipv4.method manual \
ipv4.addresses 192.168.204.131/24 \
ipv4.gateway 192.168.204.2 \
ipv4.dns "192.168.204.2"
如果出现以下情况要删除多余的连接

方法如下:
- 查看UUID
nmcli con show
输出示例:

注意:DEVICE 列为 -- 表示该连接当前未激活
- 指定UUID进行修改(如果需要保留那条同名的连接的情况下)
nmcli con mod 41e8c1bb-9d61-403d-91aa-3583eeac544f ipv4.method manual \
ipv4.addresses 192.168.204.131/24 \
ipv4.gateway 192.168.204.2 \
ipv4.dns "192.168.204.2"
不保留同名连接的情况:
使用如下命令删除那条未激活的连接,UUID得换成那条未激活的连接!
nmcli con delete uuid c859dbb3-1a79-4f7e-9152-de2c1d56ea80
再使用如下命令:
nmcli con mod ens160 ipv4.method manual \
ipv4.addresses 192.168.204.131/24 \
ipv4.gateway 192.168.204.2 \
ipv4.dns "192.168.204.2"
- 让配置生效
nmcli con down ens160 && nmcli con up ens160

- 验证配置是否成功
nmcli device show ens160 | grep -E "IP4.ADDRESS|IP4.GATEWAY|IP4.DNS"

1.2 配置连接开机自启
nmcli con mod ens160 connection.autoconnect yes
1.3 重启网络生效
nmcli con down ens160 && nmcli con up ens160
1.4 验证配置(确认IP、网关、DNS正确)
nmcli device show ens160 | grep -E "IP4.ADDRESS|IP4.GATEWAY|IP4.DNS"
1.5 进一步验证(确保网络完全可用)
- 测试网关连通性(确保能访问外部 / 跨网段)
ping 192.168.204.2 -c 3 # ping 网关,3次后停止

- 测试与其他节点互通(确保集群内部能连)
ping hadoop02 -c 3
ping hadoop03 -c 3

1.6 安装Xshell
网上教程:XShell免费版的安装配置教程以及使用教程(超级详细、保姆级)-CSDN博客
2 关闭防火墙和新建安装目录
2.1关闭防火墙
- 查看当前防火墙状态
systemctl status firewalld

- 关闭防火墙使其状态变为not running
临时关闭防火墙(立即生效,重启失效)
systemctl stop firewalld
禁止防火墙开机启动
systemctl disable firewalld
如果显示 inactive (dead) 说明防火墙已关闭。

2.2 新建安装目录
- 目录“/opt”通常用来存放第三方包和数据文件
mkdir /opt/pakages
mkdir /opt/programs
- 验证是否安装新目录
cd /opt #切换到opt目录下
ls #查看当前目录下的内容
3 安装和配置JDK
- 下载JDK8
cd /opt/pakages
wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz
-
解压到当前目录下
tar -zxvf jdk-8u202-linux-x64.tar.gz -
配置JDK系统环境变量
vim /etc/profile
export JAVA_HOME=/opt/programs/jdk1.8.0_202
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存退出后,刷新文件让配置生效:
source /etc/profile
- 验证配置是否生效
java -version
javac -version
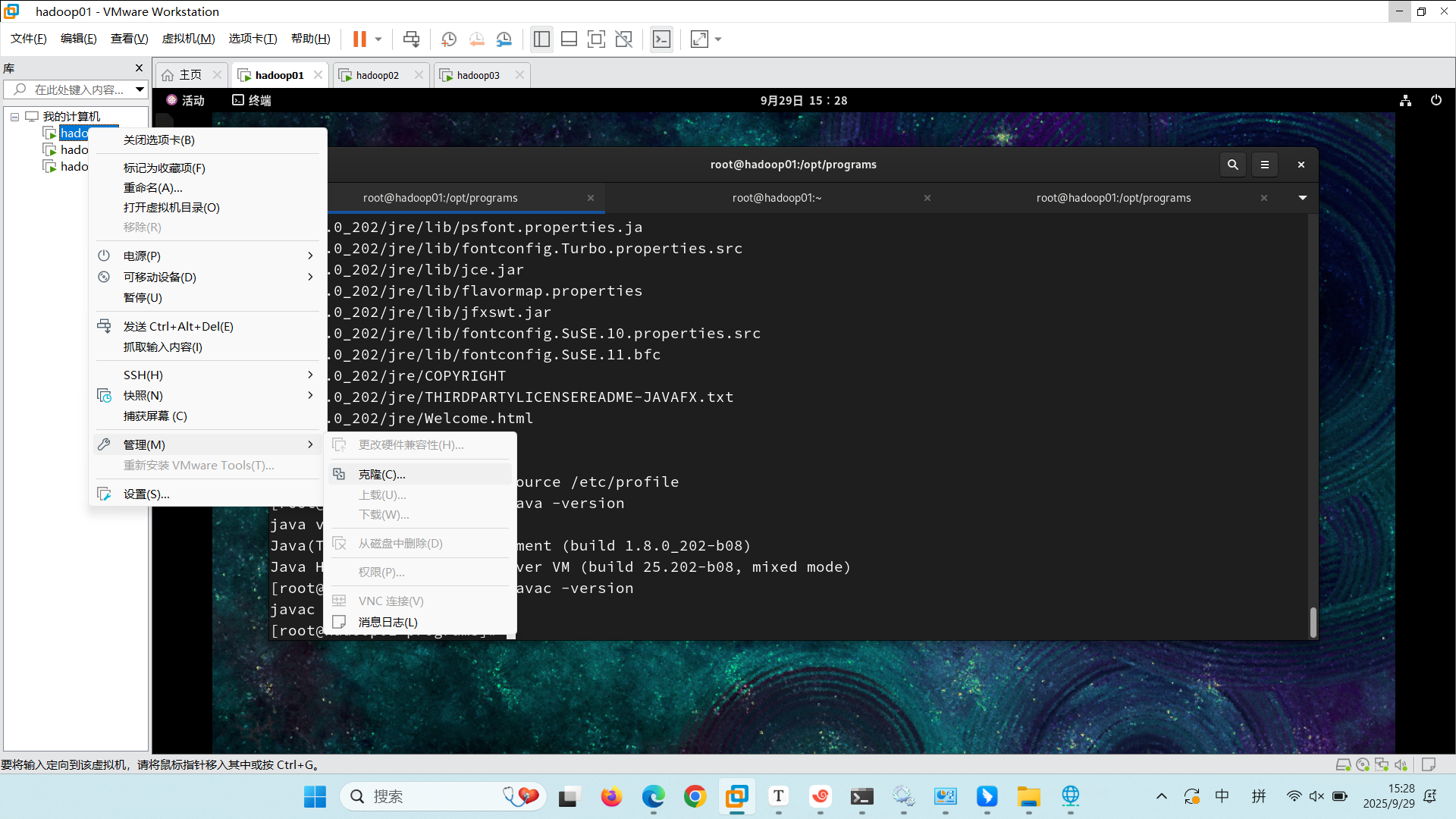
4 克隆虚拟机和配置主机IP映射
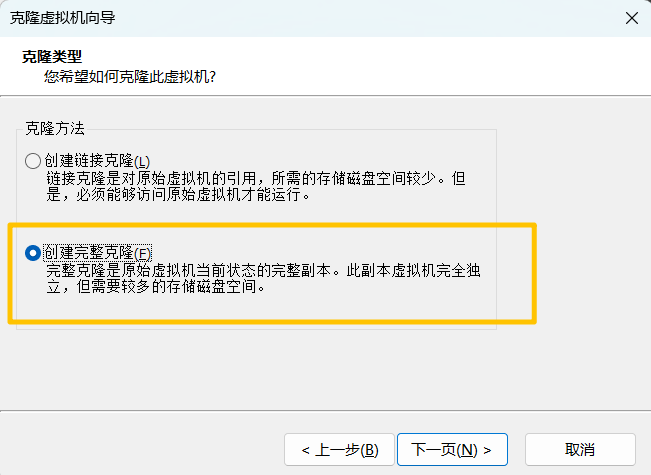
4.1 克隆虚拟机


4.2配置主机IP映射(每个节点都要)
- 查看当前主机名
hostname
- 修改hosts文件
vi /etc/hosts
-
添加映射关系
IP地址 主机名 别名(可选)
- 验证配置
ping hadoop01
ping hadoop02
4.3 配置集群各节点SSH免密码登录
- 分别在每个节点(虚拟机)生成密钥文件
ssh-keygen #连续按3个enter不设置密码
- 分别在每个节点执行以下命令,将自身的公钥信息复制并追加到全部节点的授权文件authorized_keys中(在命令执行过程中需要确认连接及输入用户密码):
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
- 会出现密码不正确的情况进行如下操作
# 在当前的 localhost 上执行,复制公钥内容
cat ~/.ssh/id_ed25519.pub
# 在 hadoop02 上执行,创建 .ssh 目录(如果没有)
mkdir -p ~/.ssh
# 把刚才复制的 localhost 公钥添加到 hadoop02 的授权列表
echo "刚才复制的公钥完整内容" >> ~/.ssh/authorized_keys
# 修复权限(必须执行,否则密钥认证会失败)
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
- 在各节点用以下命令测试SSH免密码登录:
ssh hadoop01
ssh hadoop02
ssh hadoop03
4.4 安装和配置ZooKeeper
- 下载 ZooKeeper
cd /opt/pakages
wget https://downloads.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz
这个下载链接我显示404,我换成官网下载了:https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.7.2/apache-zookeeper-3.7.2-bin.tar.gz

移动:
下载完后的文件一般都会在这里,复制一下目录名再复制一下文件名就是一个完整的路径
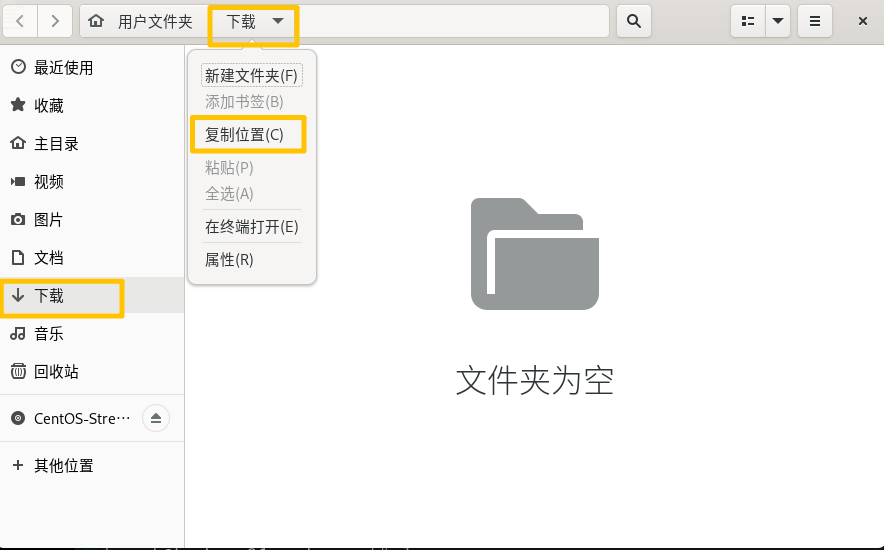
mv /root/下载/apache-zookeeper-3.7.2-bin.tar.gz /opt/programs
- 解压
tar -zxvf apache-zookeeper-3.8.4-bin.tar.gz
- 进入ZooKeeper的安装目录
cd apache-zookeeper-3.7.2-bin
- 在该目录下分别创建“data”和“logs”文件夹
mkdir data
mkdir logs
- 进入data文件夹
cd data
- 新建一个名为“myid”的文件,并写入id号“1”
echo '1'>myid
- 进入ZooKeeper安装目录下的“conf”文件夹,将zoo_sample.cfg文件复制一份并重命名为zoo.cfg
cd /opt/programs/apache-zookeeper-3.7.2-bin
cp zoo_sample.cfg zoo.cfg
- 执行以下命令修改zoo.cfg
vim zoo.cfg
- 先将文件中的dataDir修改为:
dataDir=/opt/programs/apache-zookeeper-3.7.2-bin/data
- 再在文件末尾加入以下内容:
dataLogDir=/opt/programs/apache-zookeeper-3.7.2-bin/log
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
- 将hadoop01节点的整个ZooKeeper安装目录远程复制到hadoop02和hadoop03节点:
scp -r /opt/programs/apache-zookeeper-3.7.2-bin root@hadoop02:/opt/programs
scp -r /opt/programs/apache-zookeeper-3.7.2-bin root@hadoop03:/opt/programs
- 分别进入hadoop02和hadoop03两个节点的data目录中
cd /opt/programs/apache-zookeeper-3.7.2-bin/data
13.修改myid文件,将里面的值修分别改为2和3
vim myid
- 在三个节点上分别执行以下命令,修改文件“/etc/profile”,配置ZooKeeper环境变量:
vim /etc/profile
在文件末尾加上以下内容:
export ZOOKEEPER_HOME=/opt/programs/apache-zookeeper-3.7.2-bin
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
然后在三个节点上分别执行以下命令刷新profile文件,使修改生效:
source /etc/profile
- 在三个节点上分别执行:
zkServer.sh start
若出现以下信息则启动成功:

- 在三个节点上分别执行以下命令,查看ZooKeeper集群状态
zkServer.sh status
5 安装与配置Hadoop
- 切换到pakages目录下
cd /opt/pakages
- 使用国内镜像下载压缩包(题外话:官网非常慢下了一个晚上不了了之)
wget https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
- 解压文件
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/programs
- 进入“/opt/programs/hadoop-3.3.6/etc/hadoop”目录下
(1)修改core-site.xml文件
将
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/programs/hadoop-3.3.6/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
(2)修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop01:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/programs/hadoop-3.3.6/journal/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
(3)修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)修改yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ========== 补充配置(解决网页打不开问题) ========== -->
<!-- RM1 Web UI 地址(关键:绑定 8088 端口) -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop01:8088</value>
</property>
<!-- RM2 Web UI 地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop02:8088</value>
</property>
<!-- RM1 RPC 通信端口 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop01:8032</value>
</property>
<!-- RM2 RPC 通信端口 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop02:8032</value>
</property>
<!-- RM1 管理端口 -->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop01:8033</value>
</property>
<!-- RM2 管理端口 -->
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop02:8033</value>
</property>
<!-- 关闭内存检查(防止学习环境启动失败) -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
(5)修改workers文件
将localhost修改为:
hadoop01
hadoop02
hadoop03
(6)修改配置文件hadoop-env.sh、mapred-env.sh和yarn-env.sh,在末尾追加:
export JAVA_HOME=/opt/programs/jdk1.8.0_202
- 执行以下命令,将hadoop01节点的整个Hadoop安装目录远程复制到hadoop02和hadoop03节点:
scp -r /opt/programs/hadoop-3.3.6 root@hadoop02:/opt/programs
scp -r /opt/programs/hadoop-3.3.6 root@hadoop03:/opt/programs
- 在三个节点上分别执行以下命令,修改文件/etc/profile,配置Hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/opt/programs/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile #刷新
- 启动ZooKeeper 集群(三个节点)
zkServer.sh start
6启动与测试hadoop
6.1启动Journalnode
hdfs --daemon start journalnode
测试是否有在运行
jps
如果有 JournalNode,说明它确实已经启动成功了。

6.2格式化 NameNode(在hadoop01上执行)
hdfs namenode -format
出现下面这一句即成功

6.3 进入Hadoop安装目录
cd /opt/programs/hadoop-3.3.6
将hadoop01节点Hadoop安装目录下的tmp文件夹远程复制到hadoop02节点的Hadoop安装目录下:
scp -r tmp/ root@hadoop02:/opt/programs/hadoop-3.3.6
6.4格式化ZKFC(只需在hadoop01上执行一次)
hdfs zkfc -formatZK
成功的标志:

6.5启动HDFS和YARN(在hadoop01上)
start-dfs.sh
start-yarn.sh
如果启动时出现error可以考虑看看是不是因为当前用户是root,做以下修改:
vim /opt/programs/hadoop-3.3.6/sbin/start-dfs.sh #编辑start-dfs.sh文件
在文件顶端#!/usr/bin/env bash下面添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
同样操作在stop-dfs.sh里面添加相同的内容
修改完后重新执行命令,用 jps 检查进程(应该能看到 NameNode、DataNode、JournalNode 等)
接着修改start-yarn.sh和stop-yarn.sh文件,在文件顶端#!/usr/bin/env bash下面添加
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
用jsp检查进程(确认 ResourceManager 和 NodeManager 已启动)

这样就可以访问,若网页正常显示即表示成功
http://[hadoop01IP地址]:8088/cluster

http://[hadoop01IP地址]:50070

http://[hadoop02IP地址]:50070

注:hadoop01和hadoop02其中一个是active状态一个是standby状态

 浙公网安备 33010602011771号
浙公网安备 33010602011771号