会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
Uriel-w
博客园
首页
新随笔
联系
订阅
管理
2023年5月18日
Transformer中FFN和自注意力的计算量和参数量
摘要: ### 注意力参数量和计算量: 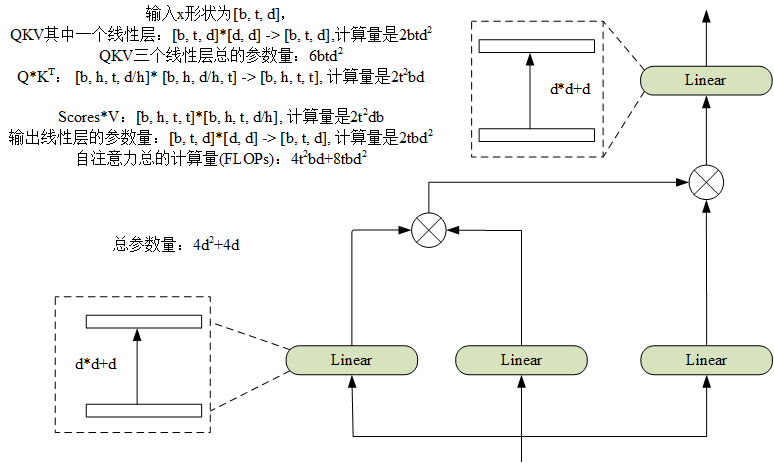 ### FFN计算量和参数量 
评论(0)
推荐(0)
2023年1月18日
tensorboard 同时显示多个event文件
摘要: 1.在logs文件夹中创建分类文件,将不同的event分别放在这些文件夹中,比如 2.在终端输入 tensorboard --logdir “logs” --host=127.0.0.1 3.打开 http://127.0.0.1:6006/网址即可在一张图中显示不同模型的曲线此外还可以选择所显示的
阅读全文
posted @ 2023-01-18 16:43 Uriel-w
阅读(3098)
评论(0)
推荐(0)
2023年1月9日
Overleaf常用符号总结
摘要: 1、指数和下标可以用^和_后加相应字符来实现。比如: 2、平方根(square root)的输入命令为:\sqrt,n 次方根相应地为: \sqrt[n]。方根符号的大小由LATEX自动加以调整。也可用\surd 仅给出符号。比如: 3、命令\overline 和\underline 在表达式的上、
阅读全文
posted @ 2023-01-09 19:18 Uriel-w
阅读(35461)
评论(0)
推荐(0)
2023年1月8日
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(论文)
摘要: Transformer模型能够学习长范围依赖,但是在语言模型中受到固定长度上下文限制,本文提出了一个新的结构:Transformer-XL。能够学习超过固定长度的依赖,同时保持了时间的连贯性,整体创新包括一个循环机制和一个新的位置编码方法。 存在的问题以及解决的方案: 在语言模型中构建长范围依赖是至
阅读全文
posted @ 2023-01-08 20:34 Uriel-w
阅读(195)
评论(0)
推荐(0)
2022年12月13日
多GPU监测
摘要: 相信大家在跑实验时都希望让GPU二十四小时跑,但有时候实验在半夜才结束,为了避免晚上接着跑实验需要半夜起床,同时为了不浪费计算资源,我们可以对多个GPU进行实时监测,当监测到GPU空闲时可以接着跑其他实验。 import os import sys import time cmd0 = 'CUDA_
阅读全文
posted @ 2022-12-13 23:11 Uriel-w
阅读(140)
评论(0)
推荐(1)
2022年11月24日
WeNet中注意力重打分(attention rescoring decoding)
摘要: 我们知道CTC是非自回归,而像transformer中解码是自回归的,所以transformer很大的一个缺陷就是解码速度慢。 在最近几年CTC和注意力机制联合训练得到的性能效果得到极大的提升,在训练过程中主要的操作就是将encoder的输出分别作为decoder的输入和CTC的输入, 通过两种不同
阅读全文
posted @ 2022-11-24 22:43 Uriel-w
阅读(1051)
评论(0)
推荐(0)
WeNet和ESPnet中下采样模块(Conv2dSubsampling)
摘要: 关于WeNet和ESPnet两个工具下采样模块都是相同的操作, 首先将输入序列扩充一个维度(因为要使用二维卷积), 然后通过两个二维卷积,其中第一个卷积的输入通道为“1”,输出通道为odim(ESPnet中默认为256,WeNet默认为512),卷积核大小为3x3。 第二个卷积输入通道是odim,输
阅读全文
posted @ 2022-11-24 22:07 Uriel-w
阅读(428)
评论(0)
推荐(0)
2022年11月20日
ipdb在debug中常用命令
摘要: 下载安装ipdb: pip install ipdb ipdb的使用: 方法一:在终端使用ipdb调试代码时,加入断点仅需要import ipdb,然后在任意行插入ipdb.set_trace()即可,在执行文件时当遇到断点进入debug模式。 方法二:通过命令调试代码: python -m ipd
阅读全文
posted @ 2022-11-20 20:12 Uriel-w
阅读(578)
评论(0)
推荐(0)
2022年11月11日
nn.Embedding 的理解
摘要: Embedding是将输入向量化,参数包括: nn.Embedding(vocab_size, emb_size) vocab_size:词典大小(不是每个batch size的长度,而是数据集词库的大小)emb_size:每个词需要嵌入多少维来表示(也就是输入维度)构造一个(假装)vocab si
阅读全文
posted @ 2022-11-11 23:42 Uriel-w
阅读(1578)
评论(0)
推荐(1)
数据降噪处理--python实现
摘要: 原文链接:https://blog.csdn.net/qq_38342510/article/details/121227880 一、均值滤波 1)算法思想 给定均值滤波窗口长度,对窗口内数据求均值,作为窗口中心点的数据的值,之后窗口向后滑动1,相邻窗口之间有重叠;边界值不做处理,即两端wid_le
阅读全文
posted @ 2022-11-11 20:19 Uriel-w
阅读(517)
评论(0)
推荐(0)
2022年11月8日
标签平滑的作用以及实现过程
摘要: 原文链接:https://blog.csdn.net/qq_44015059/article/details/109479164
阅读全文
posted @ 2022-11-08 22:44 Uriel-w
阅读(44)
评论(0)
推荐(0)
2022年9月18日
Fastformer: Additive Attention Can Be All You Need
摘要: 创新点: 本文根据transformer模型进行改进,提出了一个高效的模型,模型复杂度呈线性。 主要改进了注意力机制,出发点在于降低了注意力矩阵的重要程度,该方法采用一个(1*T)一维向量替换了原始T*T大小的注意力矩阵。 注意力结构图: 在这里,输入同样通过不同的线性映射得到Q,K,V,然后通过Q
阅读全文
posted @ 2022-09-18 13:48 Uriel-w
阅读(200)
评论(0)
推荐(0)
2022年9月17日
Branchformer
摘要: 创新点: 为了改善模型性能,在ASR任务中一种有效的方法是融合全局和局部特征,为了使模型更加灵活,本文提出的方法不同与Comformer。 通过实验发现,模型对局部和全局特征提取在每一层发挥了不同的作用,并发现不同层局部和全局重要程度不同。 模型结构图: 通过模型结构图可以发现,Branchform
阅读全文
posted @ 2022-09-17 20:22 Uriel-w
阅读(631)
评论(0)
推荐(0)
关于对Comformer中卷积层的理解
摘要: """ConvolutionModule definition.""" from torch import nn class ConvolutionModule(nn.Module): """ConvolutionModule in Conformer model. Args: channels (
阅读全文
posted @ 2022-09-17 20:00 Uriel-w
阅读(248)
评论(0)
推荐(0)
一维卷积
摘要: torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) 主要参数说明: in_channels:在文本应用中,即为词向量的维度 out_
阅读全文
posted @ 2022-09-17 17:21 Uriel-w
阅读(535)
评论(0)
推荐(0)
下一页
公告
 浙公网安备 33010602011771号
浙公网安备 33010602011771号