


Selenium自动化测试
一、认识Selenium
-
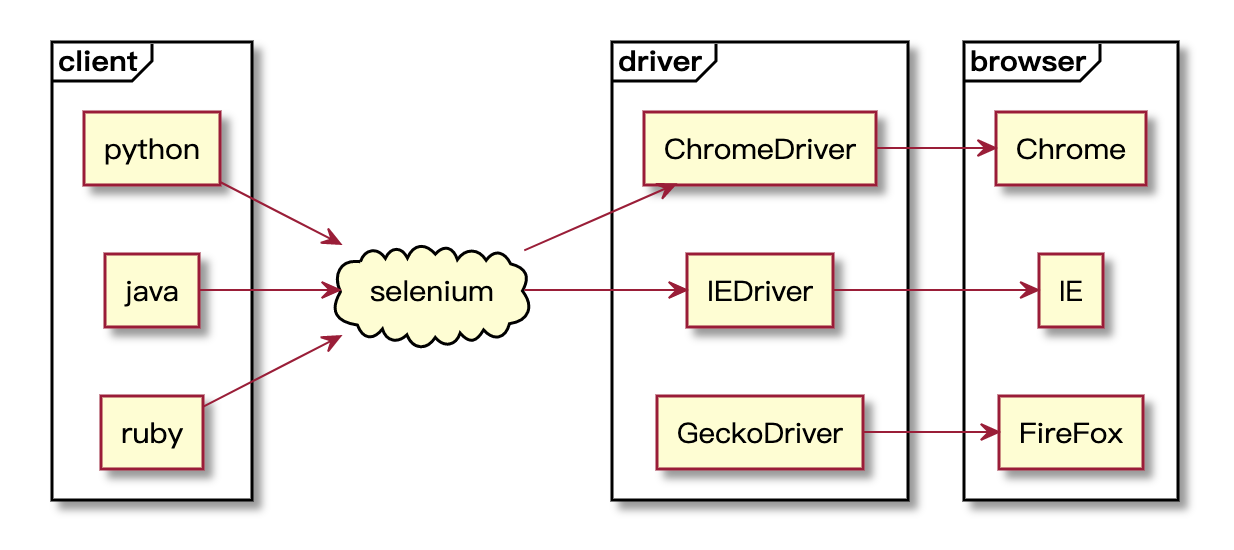
Selenium架构
![]()
-
Selenium核心组件
1.selenium webdriver client
2.selenium drivers
3.selenium IDE
4.selenium grid
需要同一时间在多个浏览器和操作系统上进行测试时;
要节省测试套件的执行时间时。
二、搭建测试环境
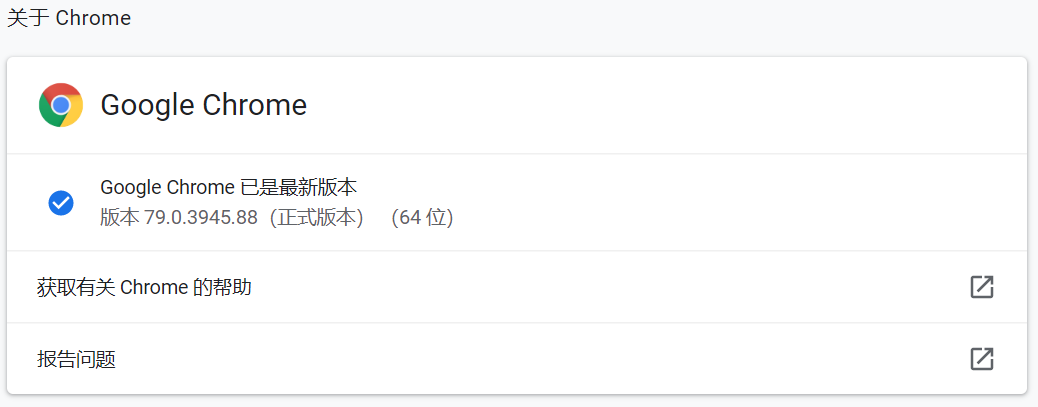
安装Chrome
查看Chrome的版本,需要安装适合版本的Chromedriver。
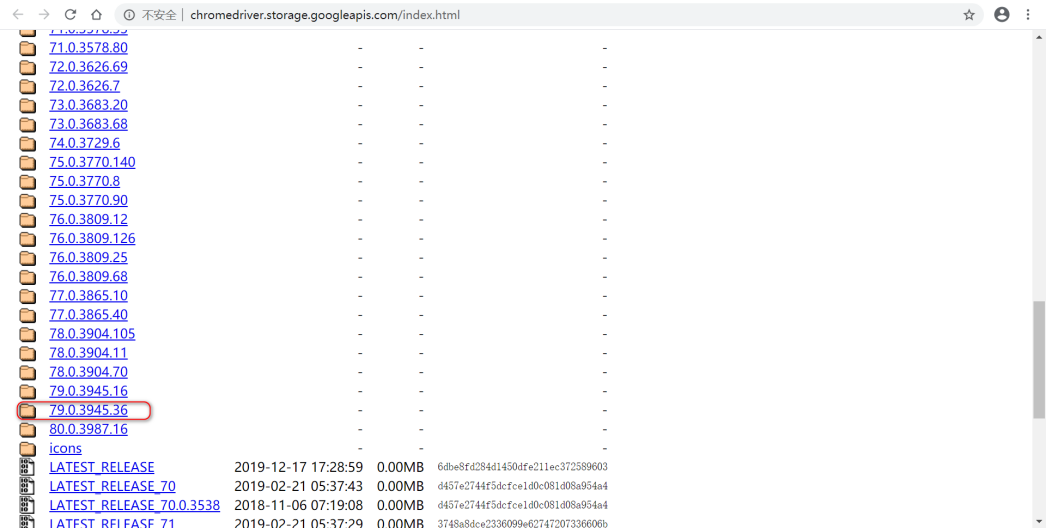
安装Chromedriver
-
第三⽅浏览器驱动下载
https://www.seleniumhq.org/download/
https://npm.taobao.org/mirrors/chromedriver -
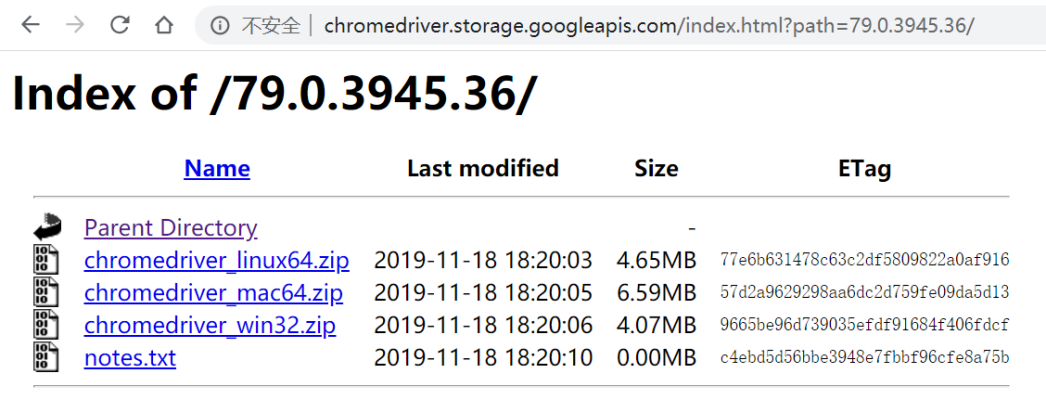
找到与本机电脑Chrome版本最接近Chromedriver版本
![]()
![]()
-
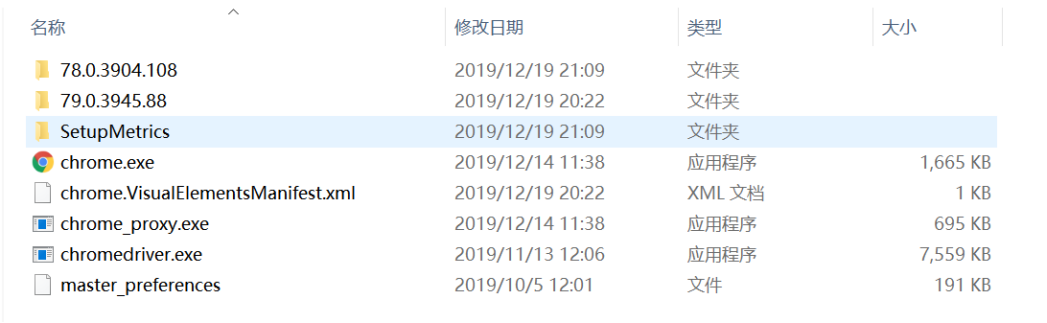
解压并把chromedriver复制到chrome安装目录下
![]()
-
chromedriver添加PATH环境变量
![]()
-
查看chromedriver版本
![]()

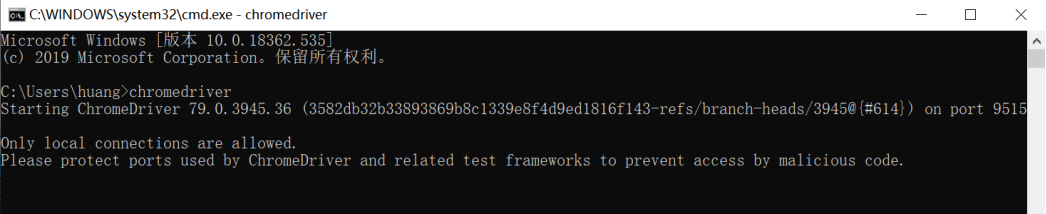
ps:设置环境变量后如果没有生效,尝试重启电脑。
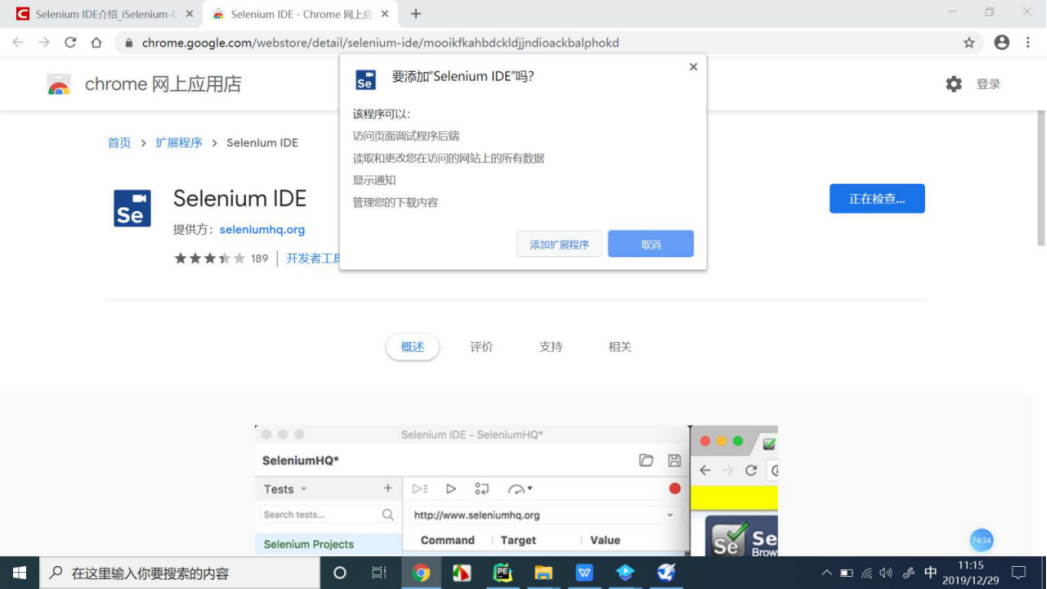
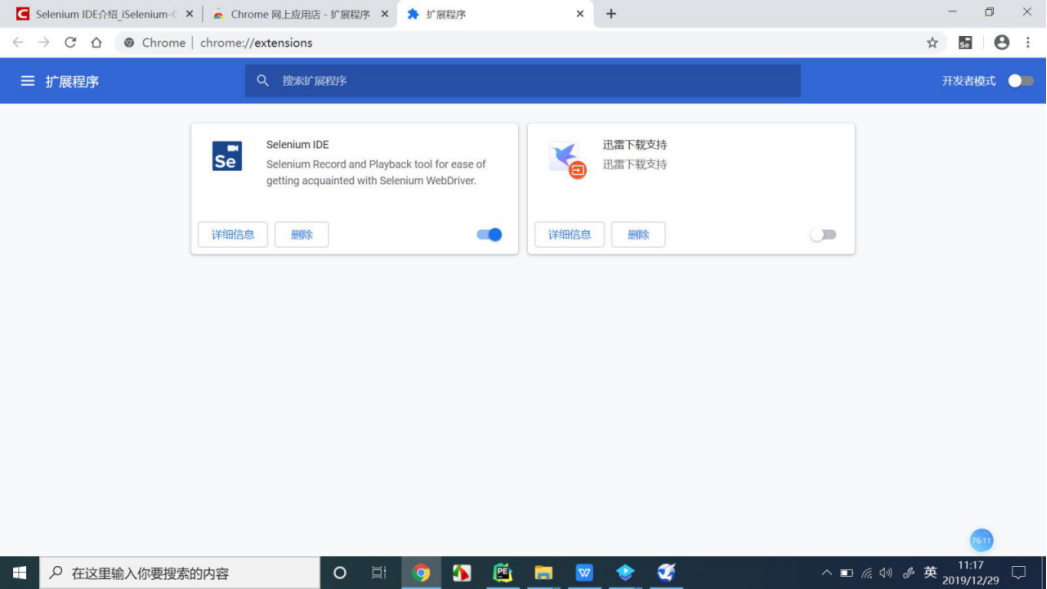
安装Selenium的IDE
ps:安装需要梯子。
IDE是入门的好工具。
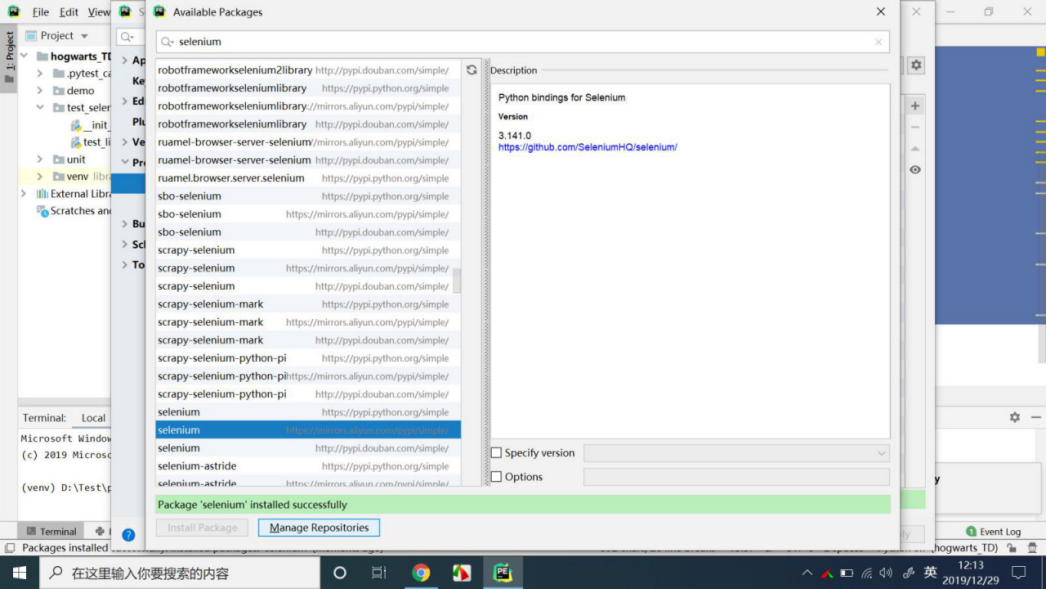
安装selenium库
Pychram安装selenium库,创建项目,做为client。

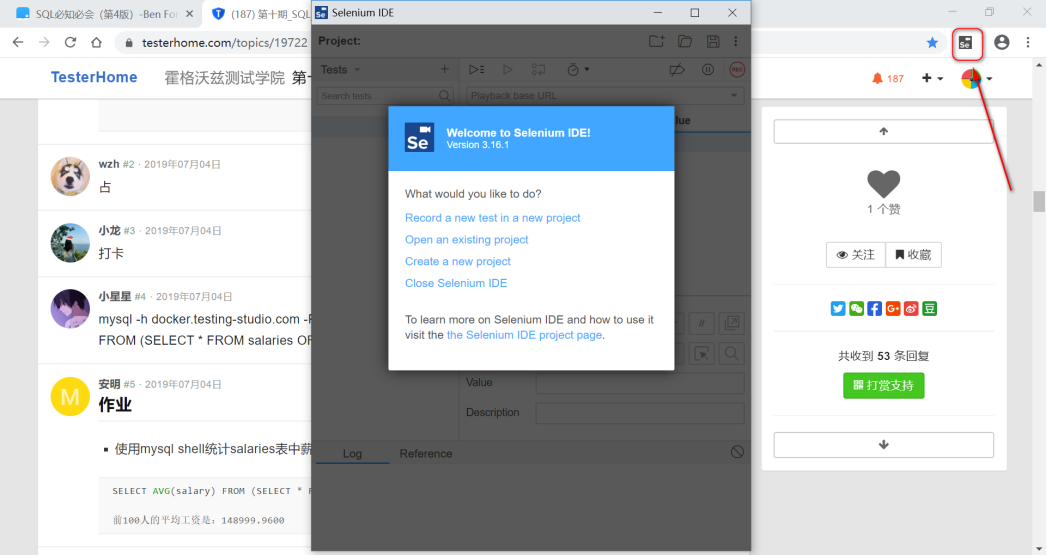
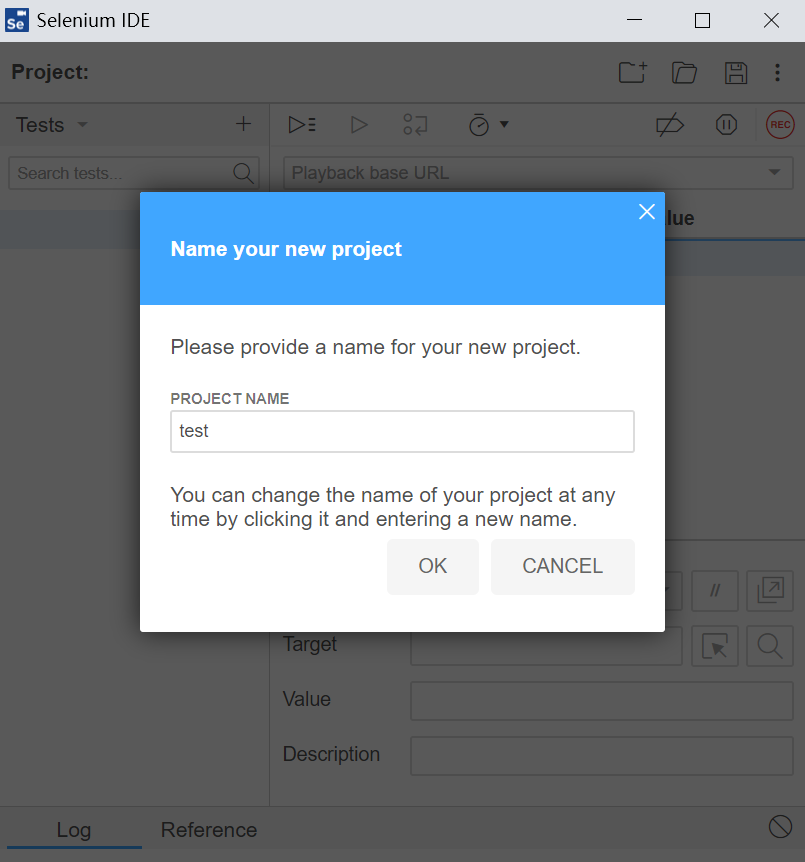
三、IDE录制脚本
- 录制脚本
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
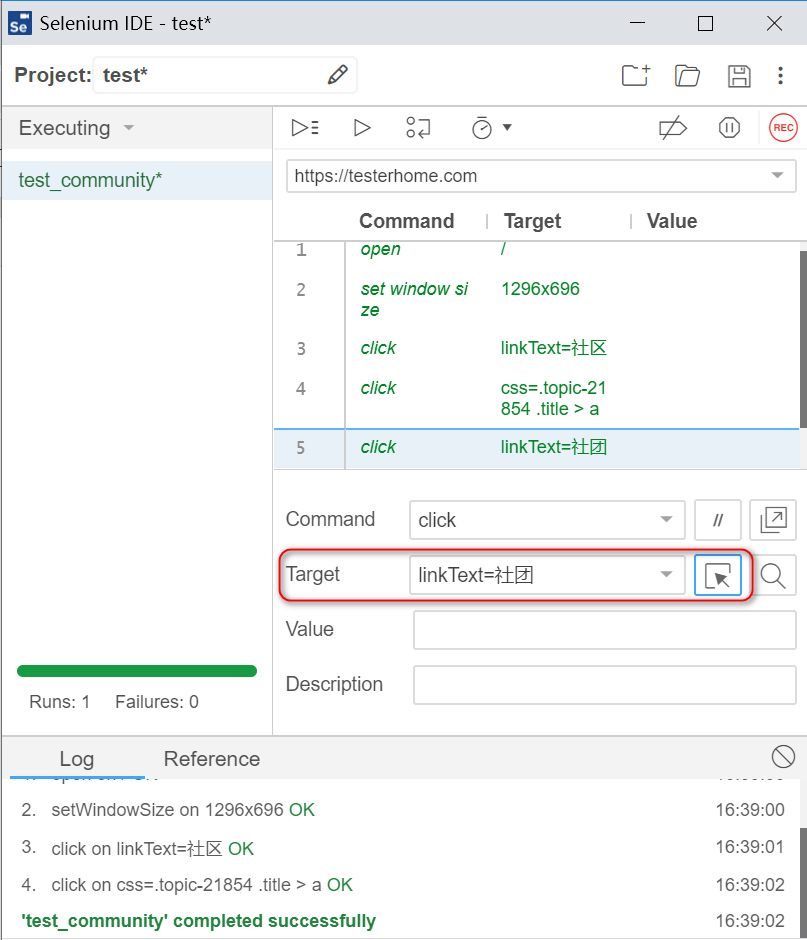
- 分析定位符
先执行录制的脚本,在此基础上,可以分析定位符。
![]()
![]()
在页面上点击“社团”
![]()
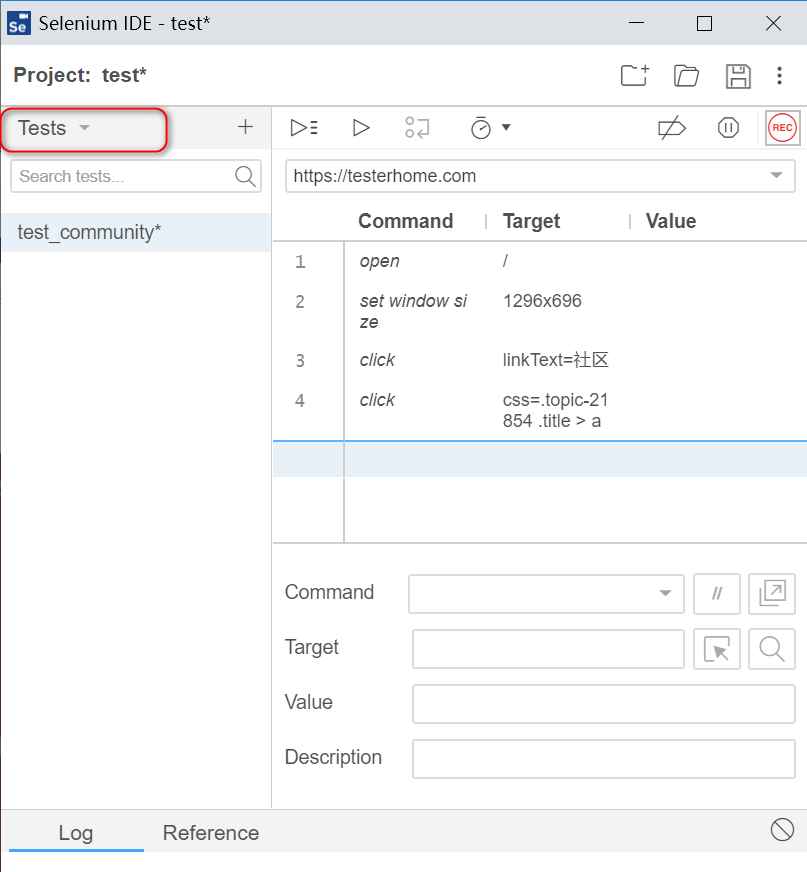

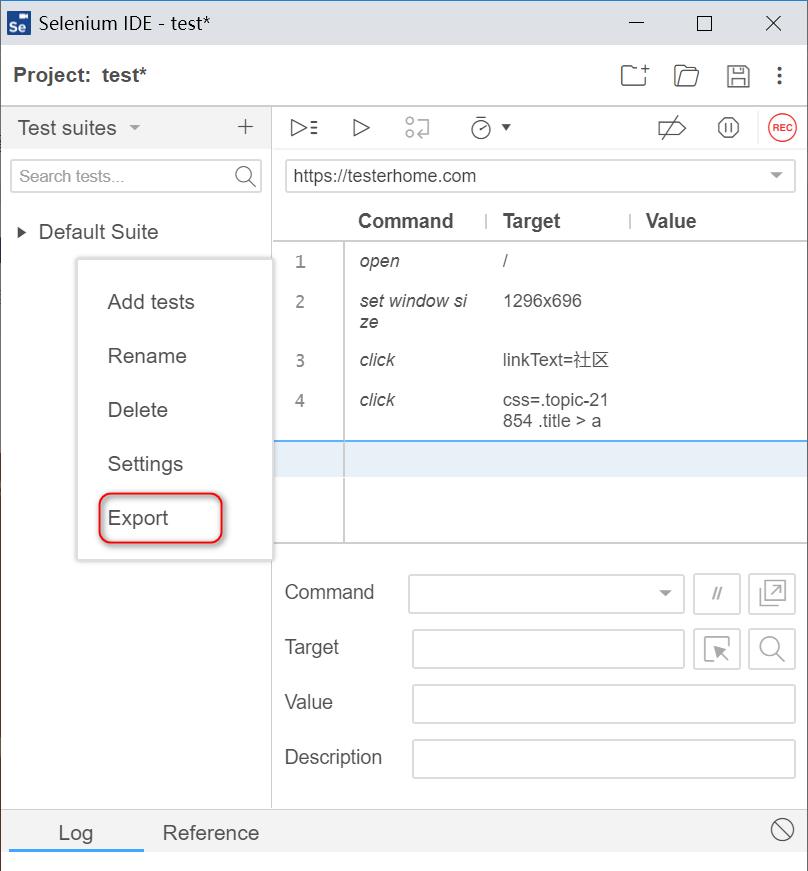
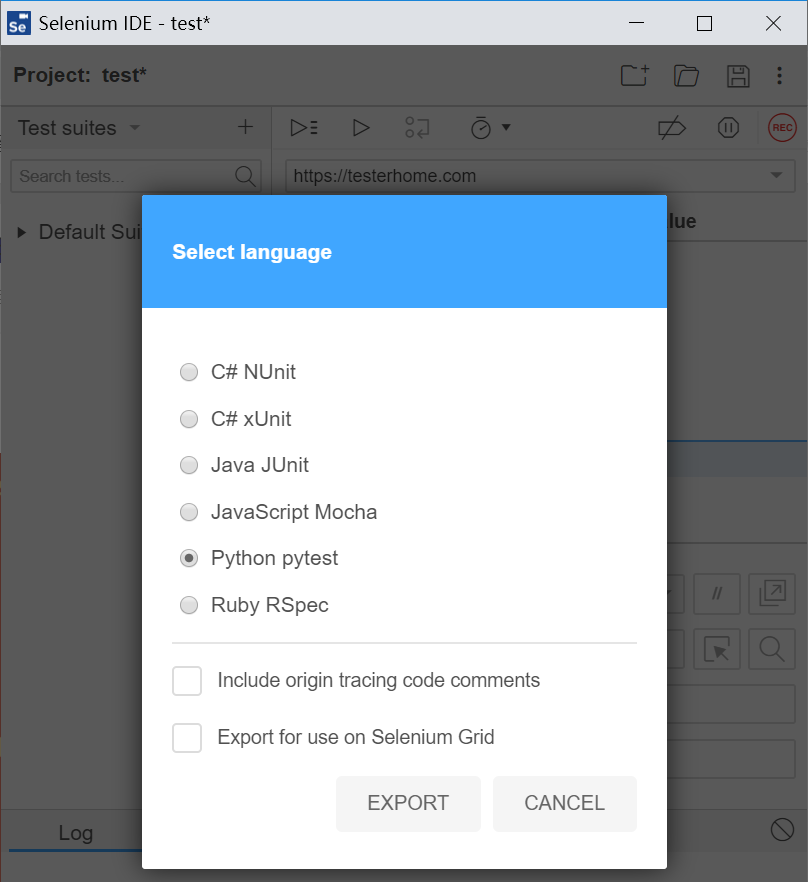
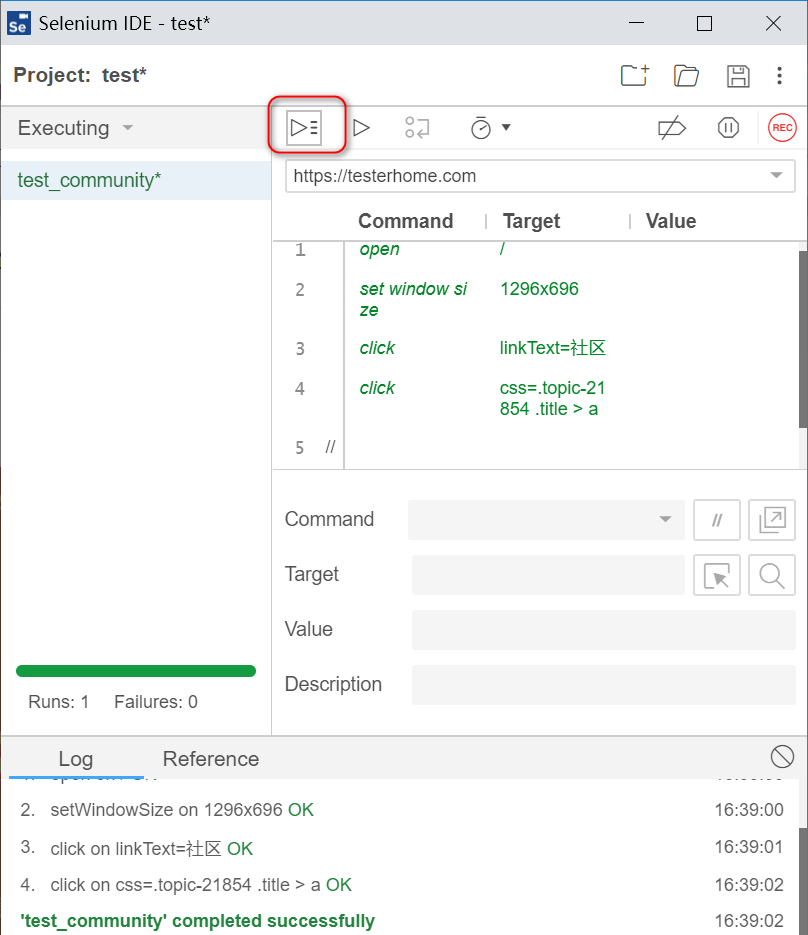
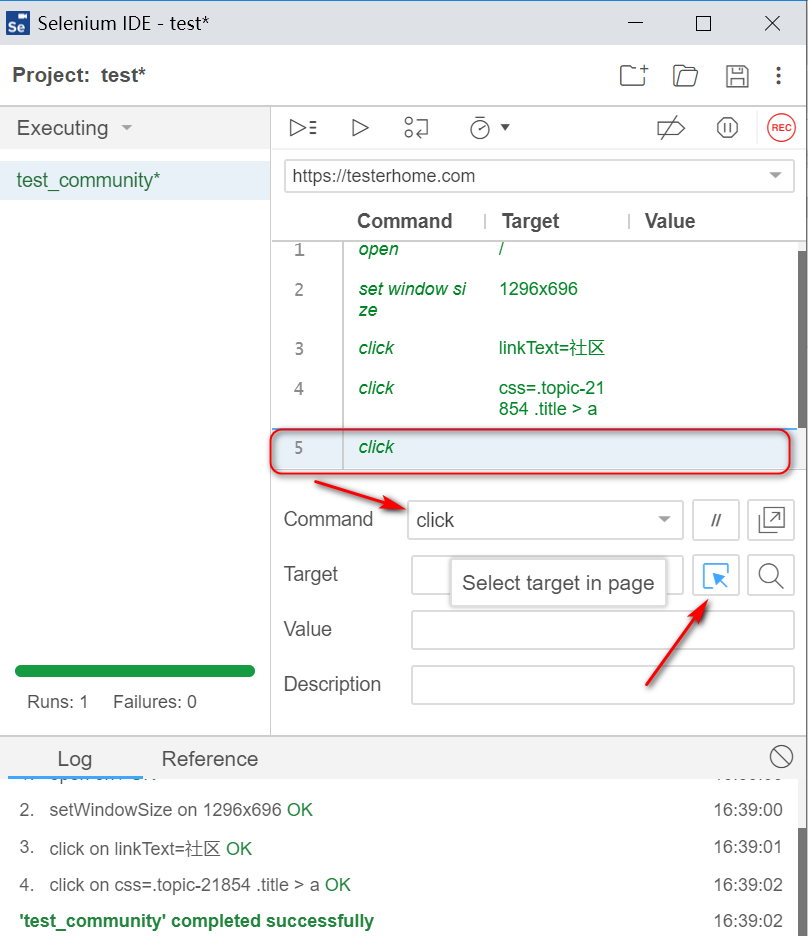

回到ide,发现有css定位表达式
四、编写用例
- 导入依赖
from selenium import webdriver - 初始化driver
driver = webdriver.Chrome()
driver = webdriver.Firefox()
driver = webdriver.Ie()
driver = webdriver.Edge()
driver = webdriver.Opera() - 具体步骤
- 断言assert
- 退出
五、 WebDriver对象操作(API)
对WebDriver对象的操作可以抽象成你怎么去控制浏览器,主要方法有:
1.访问URL
driver.get("https://www.baidu.com/")
2.窗口大小调整
- 设置宽800px 高600px
driver.set_window_size(800,600) - 设置最大,最小
driver.maximize_window()
driver.minimize_window()
3.刷新页面
driver.refresh()
4.前进后退
driver.forward()
driver.back()
5.关闭浏览器或窗口
- 关闭浏览器
driver.quit() - 关闭窗口
driver.close()
有多个窗口的时候,只会关闭当前窗口。
6.返回当前的一些属性
- 返回当前url
driver.current_url - 返回当前窗口句柄
driver.current_window_handle - 返回所有窗口句柄
driver.window_handles
# 在新浪登录页面点击注册,在注册页面邮箱地址输入框中输入邮箱地址,再次跳转到登录页面。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('http://mail.sina.com.cn/')
#获取当前窗口句柄
now_handle = driver.current_window_handle
time.sleep(1)
#点击注册链接
driver.find_element_by_link_text('注册').click()
time.sleep(1)
#获取所有窗口句柄
handles = driver.window_handles
#对所有窗口句柄循环处理
for handle in handles:
if handle != now_handle:
#窗口变化之后需要定位当前窗口
driver.switch_to.window(handle)
time.sleep(2)
driver.find_element_by_name('email').send_keys('bing')
time.sleep(2)
#关闭注册页面
driver.close()
driver.switch_to.window(now_handle)
time.sleep(2)
#在账号输入框输入邮箱
driver.find_element_by_id('freename').send_keys('bing')
time.sleep(2)
driver.quit()
- 返回title
driver.title - 获取当前页面代码
driver.page_source
7.查找元素,返回Element对象
driver.find_element_by_css_selector()
driver.find_element_by_name()
driver.find_element_by_id()
driver.find_element_by_tag_name()
driver.find_element_by_class_name()
driver.find_element_by_link_text()
driver.find_element_by_partial_link_text()
driver.find_element_by_xpath()
8.切换窗口
driver.switch_to_window(handle)
9.切换frame
切换框架,直接输入iframe的name或id属性,或者传入定位的元素
driver.switch_to_frame(frame_reference)
10.截图保持为文件
driver.get_screenshot_as_file(img_path_name)
img_path_name为文件路径,只支持.png格式,文件名注意带上后缀,如“/Screenshots/foo.png”
11.执行js
- 简单执行
driver.execute_script(script, *args)
script:要执行的JavaScript。
*args:JavaScript的所有适用参数。 - 异步执行
driver.execute_async_script(script, *args)
12.操作cookie
- 获取cookie
driver.get_cookies() - 添加cookie
driver.add_cookie(cookie_dict) - 删除全部cookie
driver.delete_all_cookies() - 删除一个指定cookie
driver.delete_cookie(name)
六、元素定位
-
元素定位本质上分为三大类
![]()
-
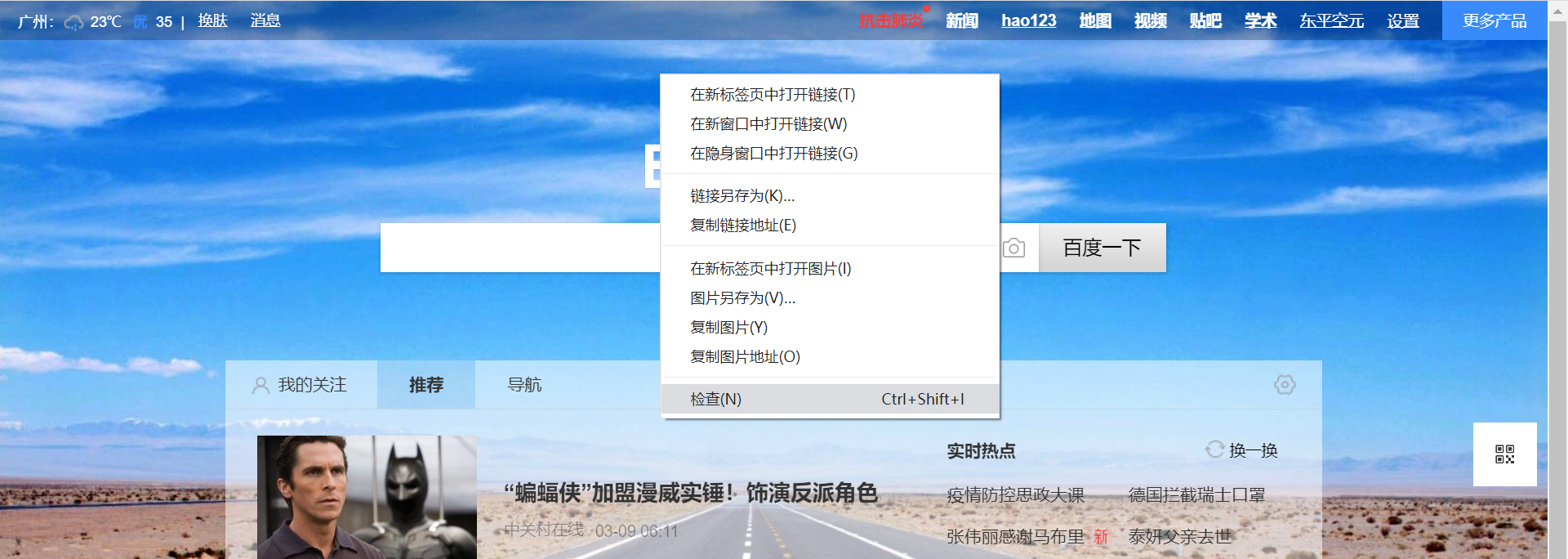
使用Chrome验证元素定位表达式
右键点击“检查”
![]()
查看HTML
![]()

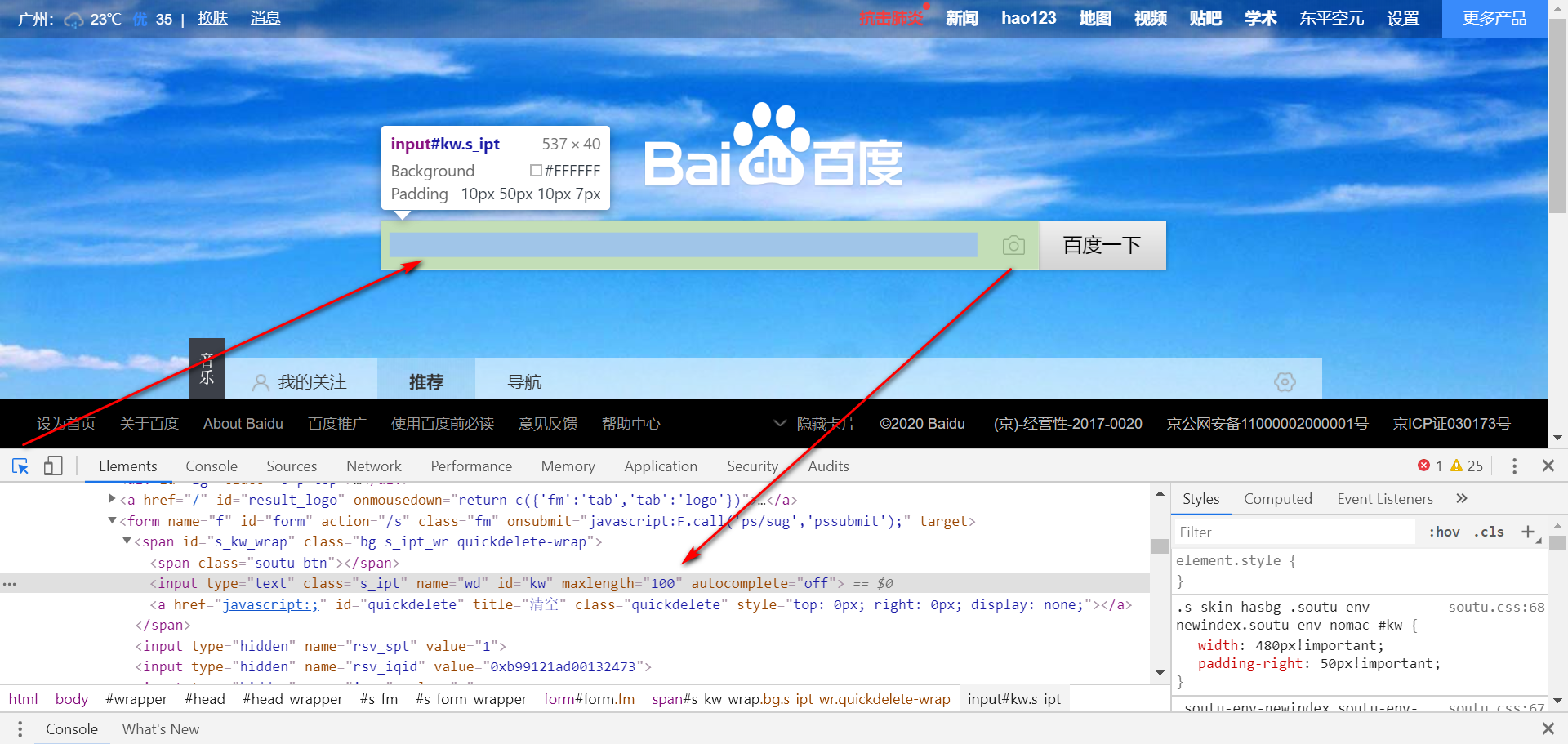
进入Console验证定位表达式
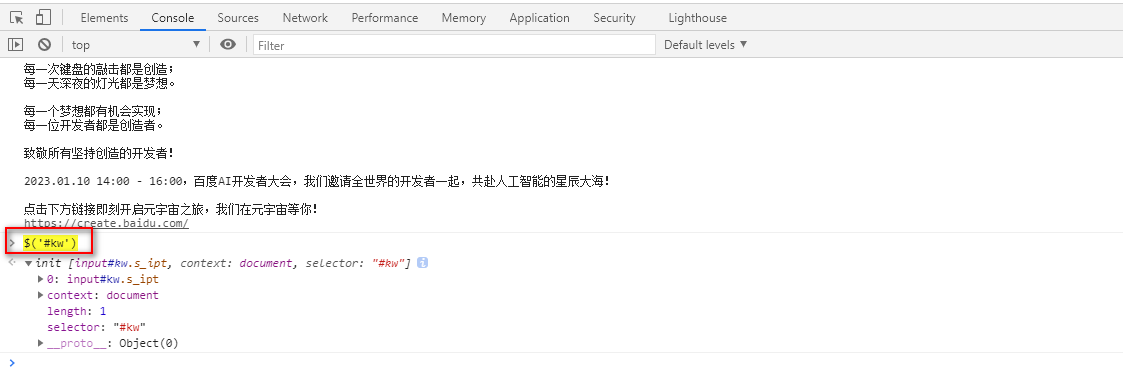
输入表达式后,按回车,会找到对应的元素,检查是不是自己要定位的元素
输入$()可以验证css定位
输入$x()可以验证xpath定位
-
元素定位常见错误
1.element is not attached to the page document
selenium.common.exceptions.StaleElementReferenceException: Message: stale element reference: element is not attached to the page document
2.NoSuchElementException -
元素定位思路
1.直接定位,有id、name,优先使用这两个定位,不行再尝试class、属性、标签定位。
2.相对定位,就是根据层级关系定位。层级定位,先找到全局层级,再找下面的层级。
CSS定位
1.CSS常用属性定位
css可以通过元素的id、class、标签这三个常规属性直接定位元素。
# 百度搜索框HTML如下:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
- css用#号表示id属性
# chrome中验证定位表达式:$('#kw')
driver.find_element(By.CSS_SELECTOR,'#kw')
driver.find_element_by_css_selector('#kw')
- css用.表示class属性
# chrome中验证定位表达式:$('.s_ipt')
driver.find_element(By.CSS_SELECTOR,'.s_ipt')
driver.find_element_by_css_selector('.s_ipt')
- css直接用标签名称,无任何标示符
$('input')
![]()

2.CSS其它属性定位
css除了可以通过标签、class、id这三个常规属性定位外,也可以通过其它属性定位。
通过其他属性定位,得把属性放在方括号里。
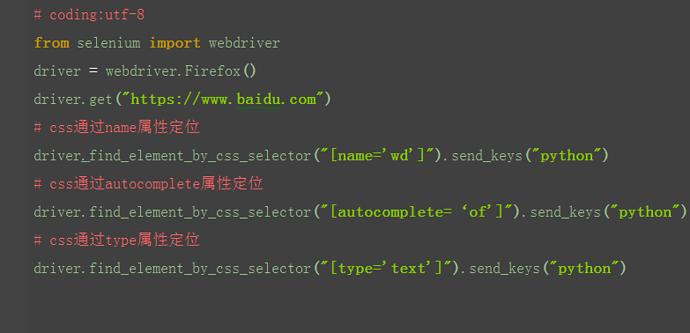
# chrome中验证定位表达式:$('[type="text"]')
driver.find_element(By.CSS_SELECTOR,'[type="text"]')
driver.find_element_by_css_selector('[type="text"]')
3.通过标签与属性的组合来定位元素
- 标签+class属性定位
# chrome中验证定位表达式:$('input.s_ipt')
driver.find_element(By.CSS_SELECTOR,'input.s_ipt')
driver.find_element_by_css_selector('input.s_ipt')
- 标签+id属性定位
# chrome中验证定位表达式:$('input#kw')
driver.find_element(By.CSS_SELECTOR,'input#kw')
driver.find_element_by_css_selector('input#kw')
- 标签+其他属性定位
# chrome中验证定位表达式:$('input[type="text"]')
driver.find_element(By.CSS_SELECTOR,'input[type="text"]')
driver.find_element_by_css_selector('input[type="text"]')
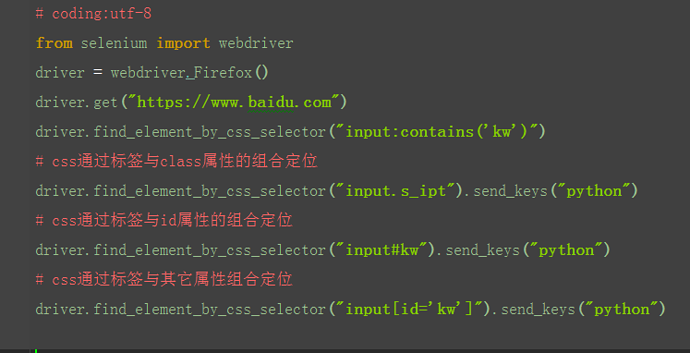
看这里都是把标签放在前面,如果开始不是标签可以吗?把标签放在属性后面呢?
4.CSS层级关系定位
元素不能直接定位的时候,才考虑使用层级关系定位。
观察HTML的结构,一层一层找到包含要定位元素的父元素、父父元素,然后一层一层定位。
层级可以跳跃吗?
div>p:选择父元素为 <div> 元素的所有 <p> 元素。
$('form>span>[type="text"]')
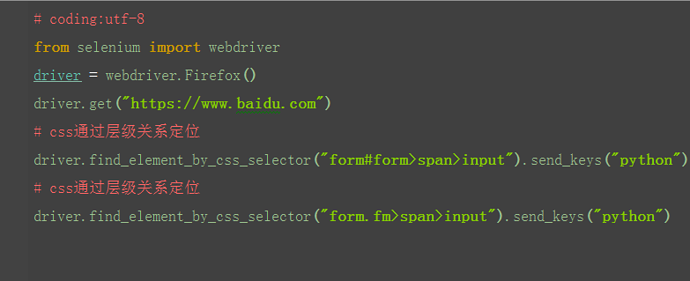
5.CSS索引定位
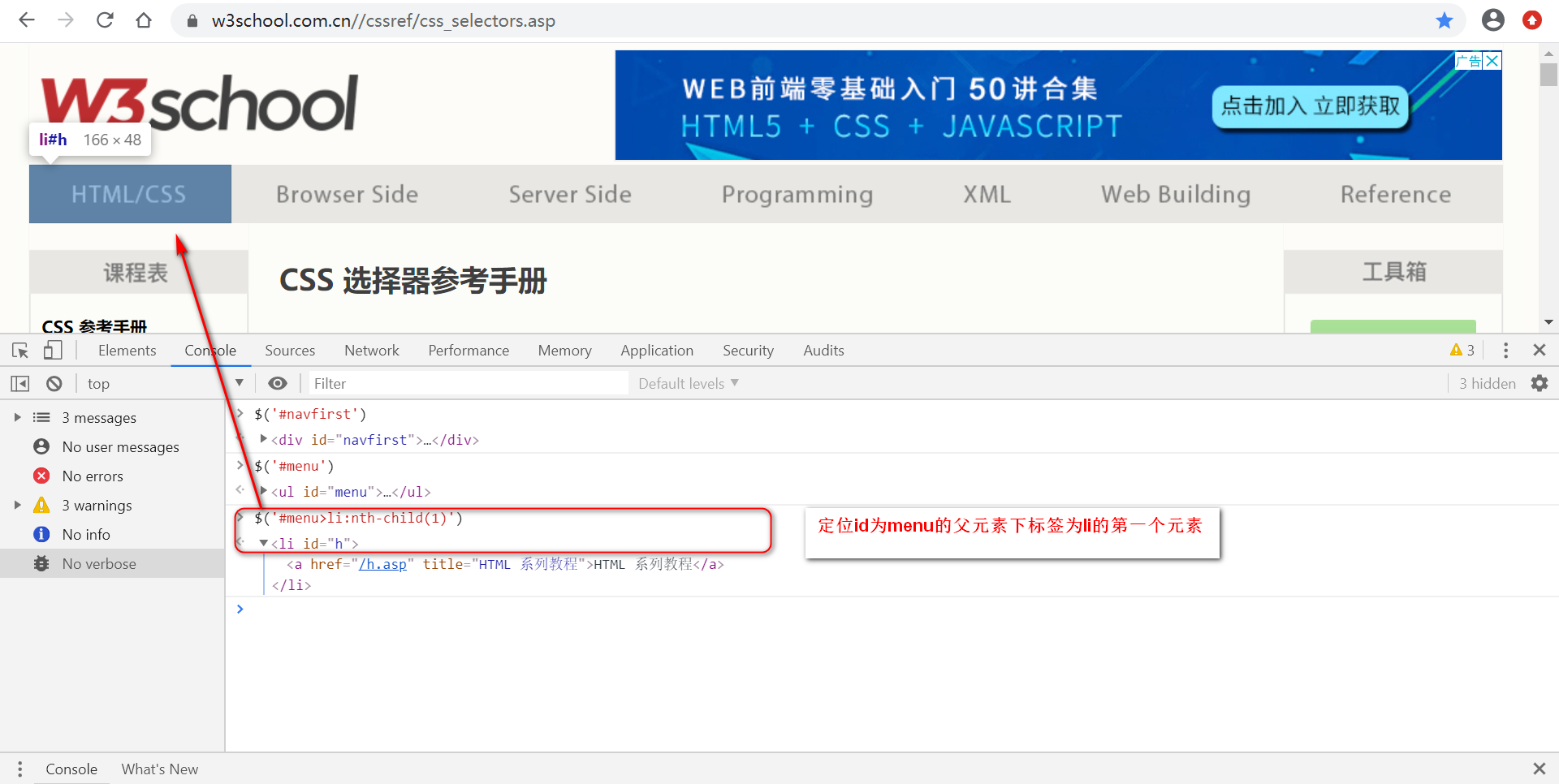
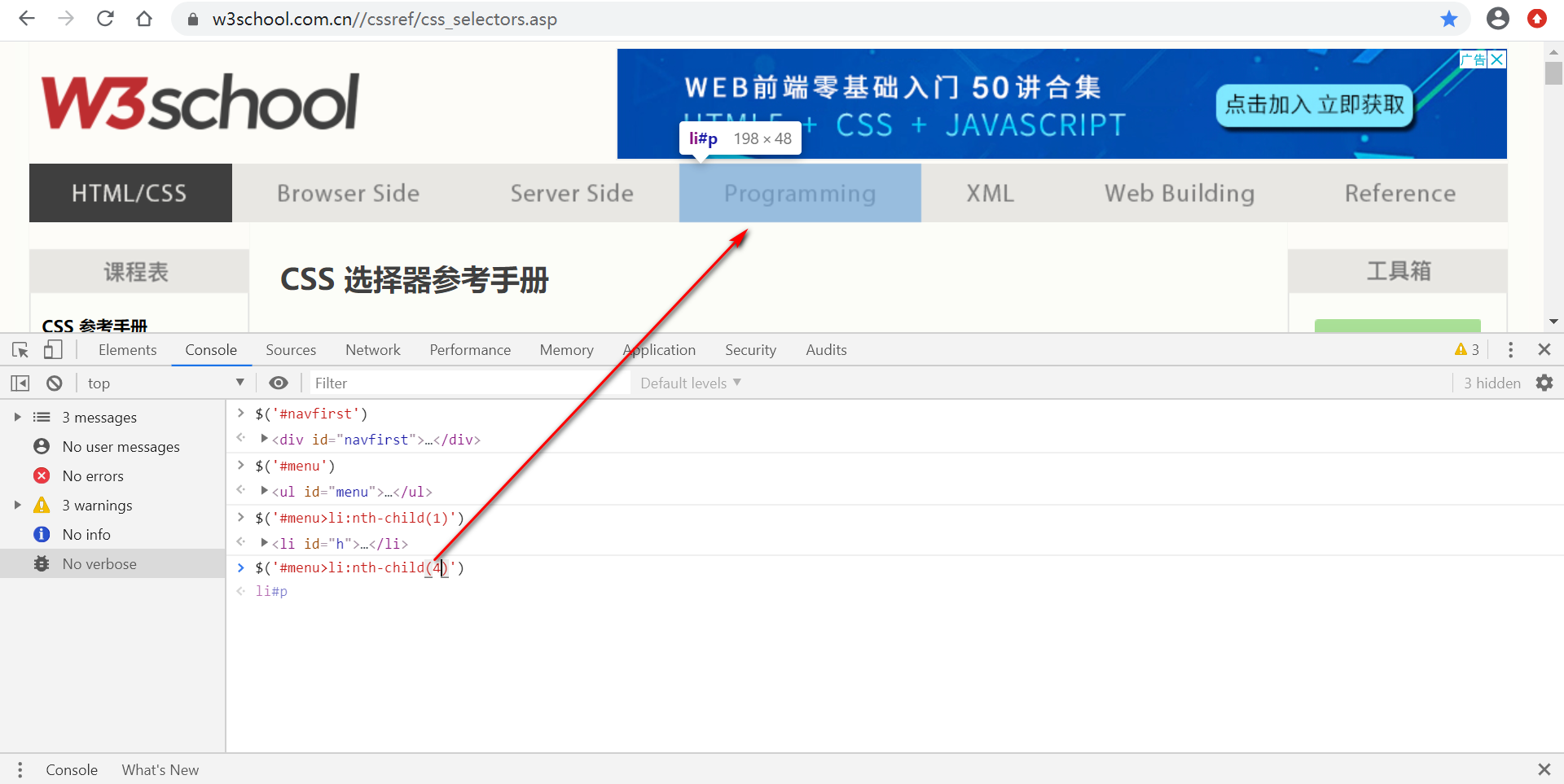
p:nth-child(2):选择属于其父元素的第二个子元素的每个 <p> 元素。
input:nth-child(2) :选择属于 input 父元素的第2个子元素的每个 input 元 素

定位页面如下:

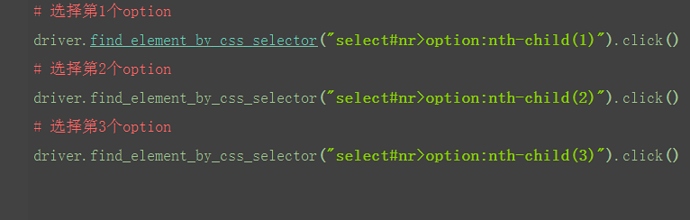
定位id为menu的父元素下标签为li的元素
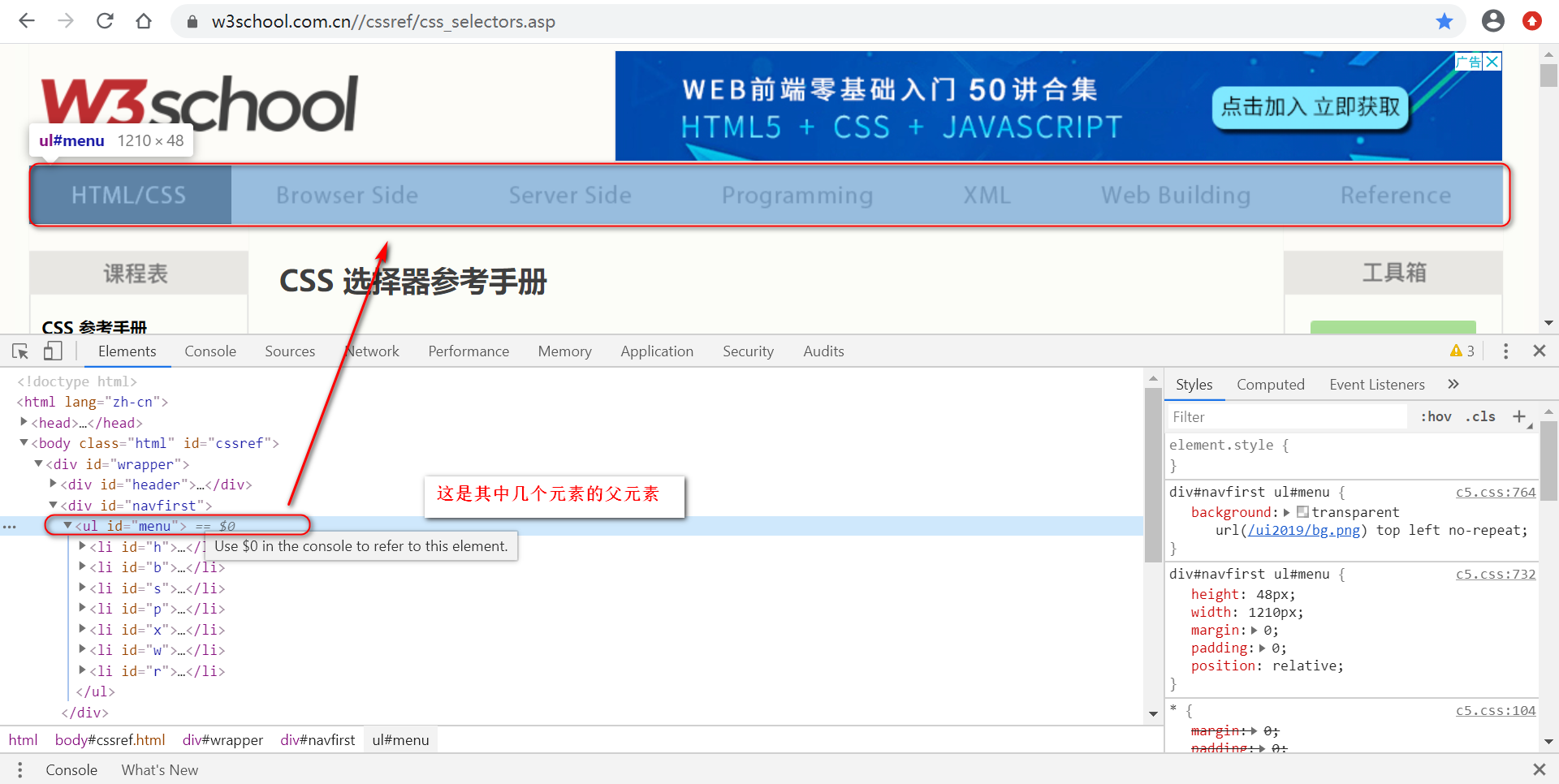
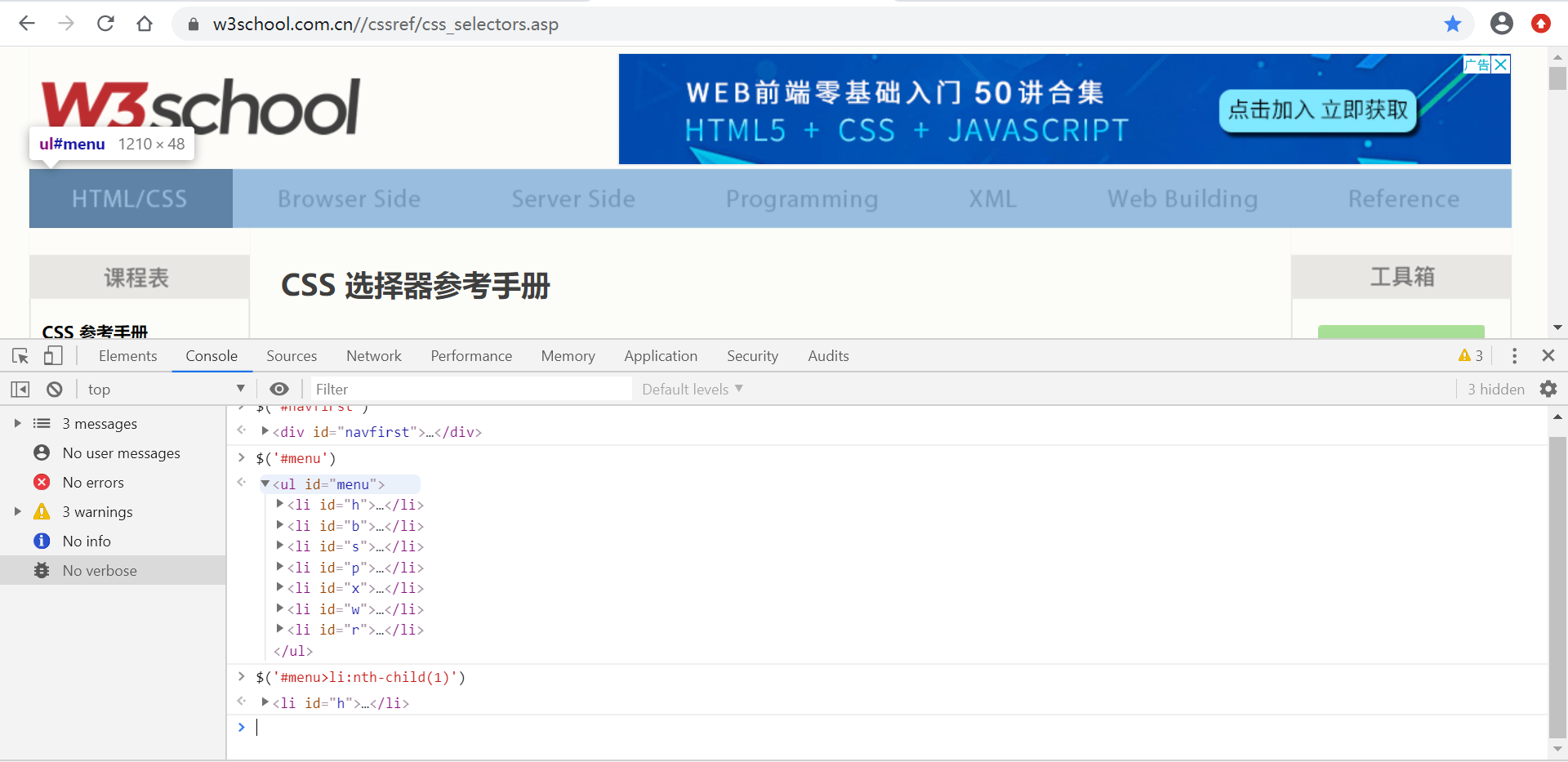
练习地址:https://www.w3school.com.cn//cssref/css_selectors.asp
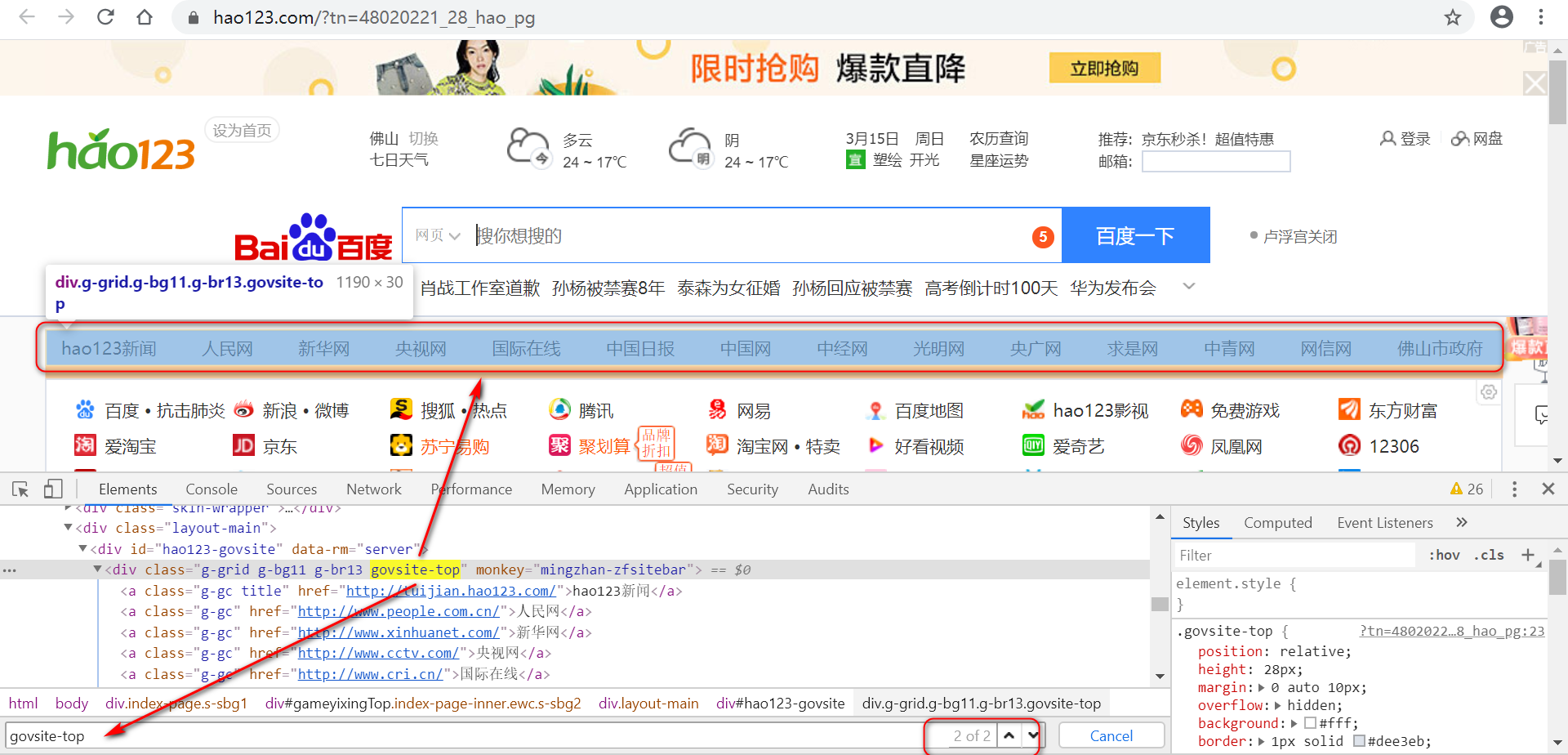
$('.govsite-top>a:nth-child(2)')
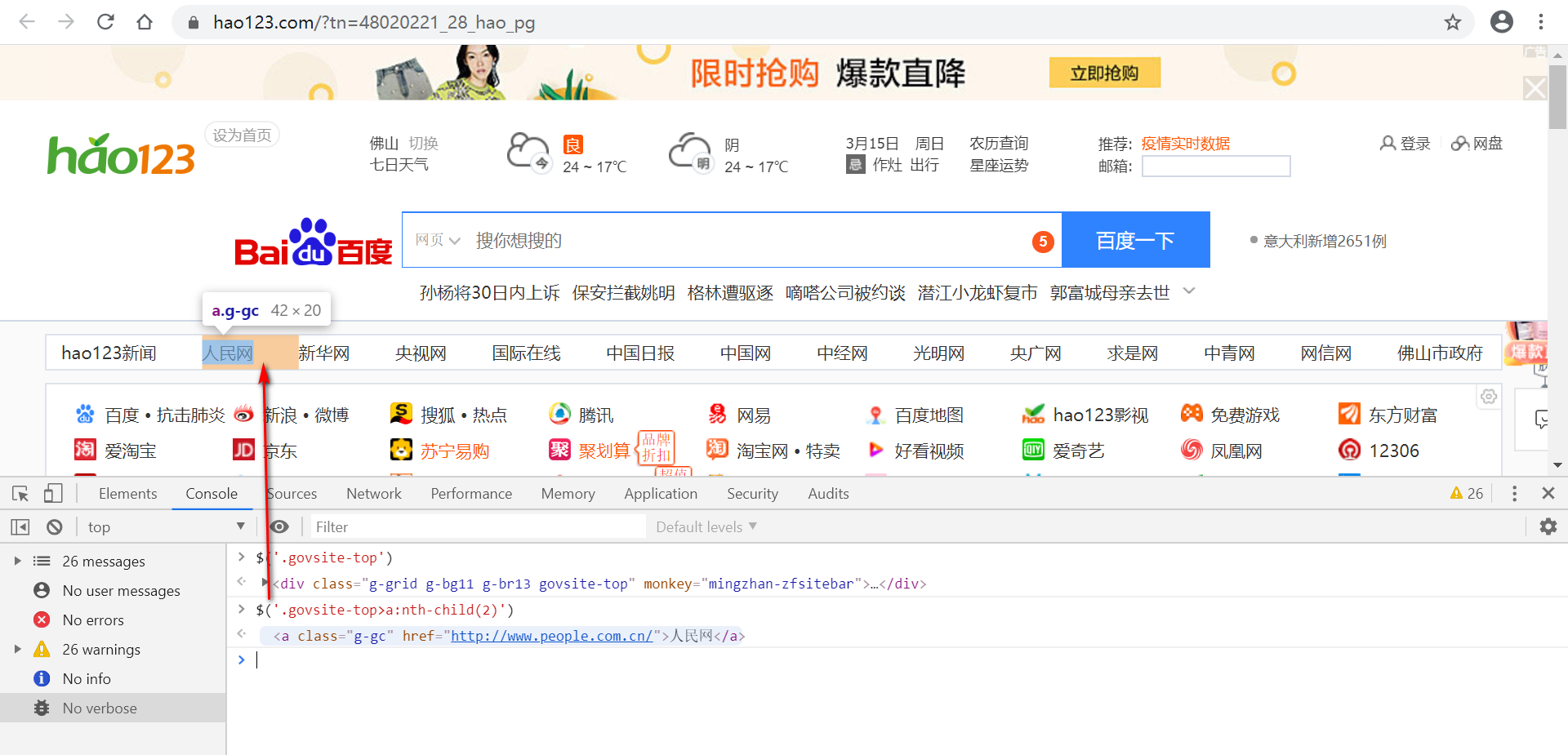
6.CSS逻辑运算定位
css同样也可以实现逻辑运算,同时匹配两个属性,但跟xpath不一样,无需写and关键字。
$('input[type="text"][autocomplete="off"]')
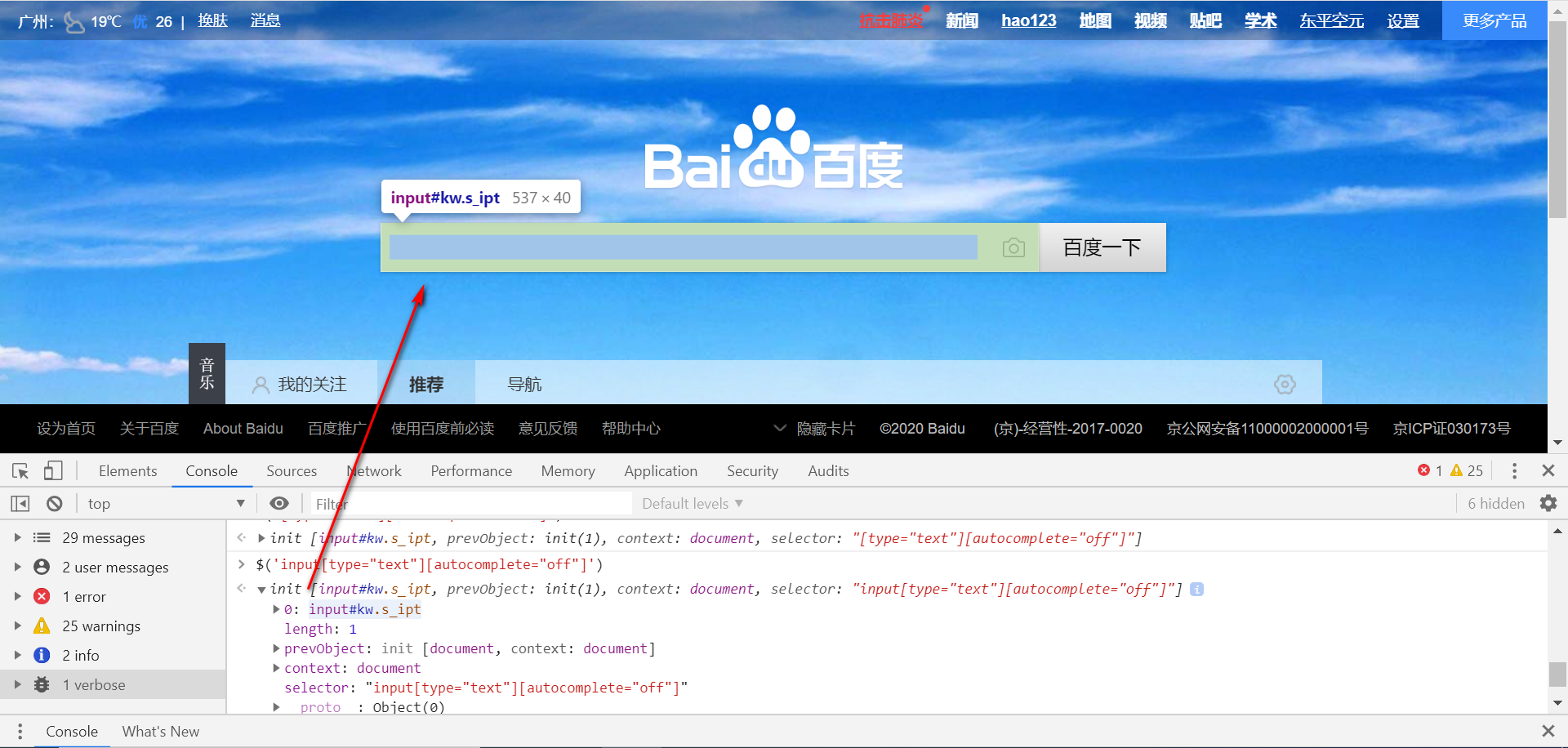
$('[type="text"][autocomplete="off"]')
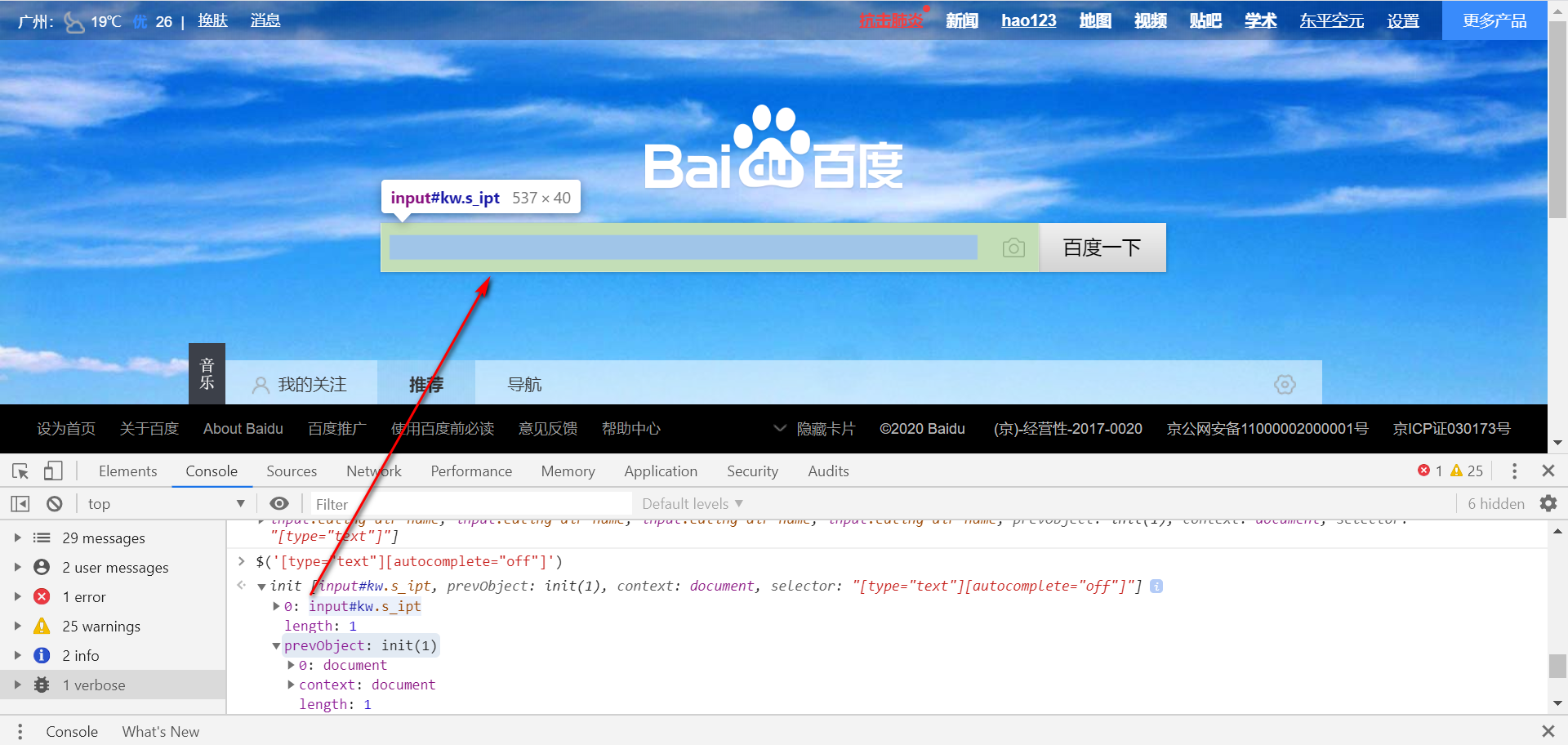
$('.s_ipt[type="text"][autocomplete="off"]')

XPATH定位
1.xpath概念相关
xpath是什么?XML路径语言。用来在HTML/XML文档中查找信息的语言。
xpath使用路径表达式来获取节点/节点集,和常规电脑文件路径类似。
绝对路径 / :/从根节点开始;
相对路径//://相对路径(推荐用),相对于整个源码查找。




2.xpath定位方式(路径表达式+索引+属性)
-
利用标签内的属性进行定位
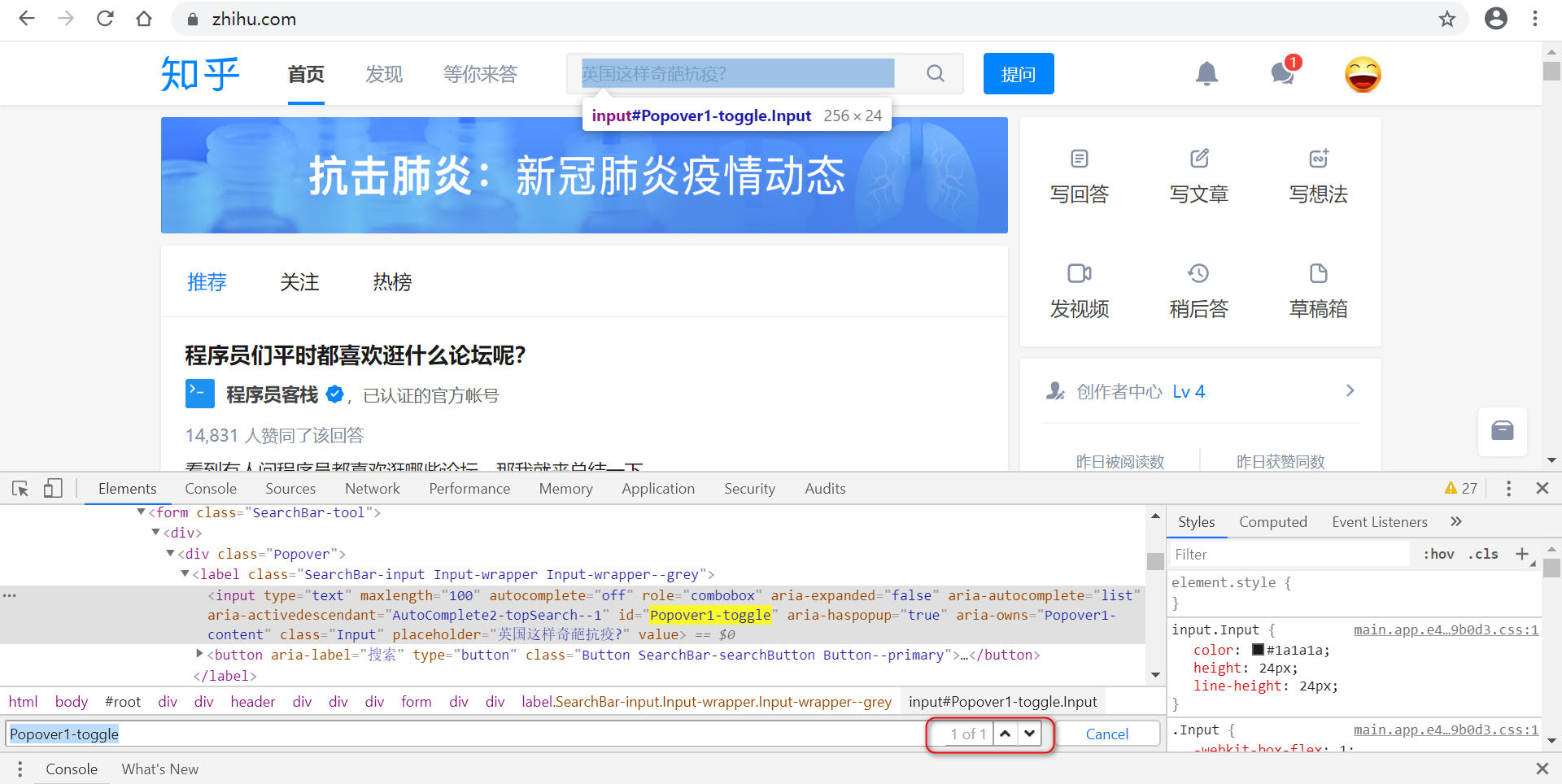
(1)通过id属性(标签+id)
$x('//input[@id="Popover1-toggle"]')
![]()
![]()
(2)通过name属性定位
小结:xpath = "//标签名[@属性='属性值']"
属性判断条件:最常见为id,name,class等等,属性的类别没有特殊限制,只要能够唯一标识一个元素即可。
当某个属性不足以唯一区别某一个元素时,也可以采取多个条件组合的方式,如下:
xpath= "//input[@type='XX' and @name='XX']"
$x('//input[@class="Input" and @type="text"]')
![]()
-
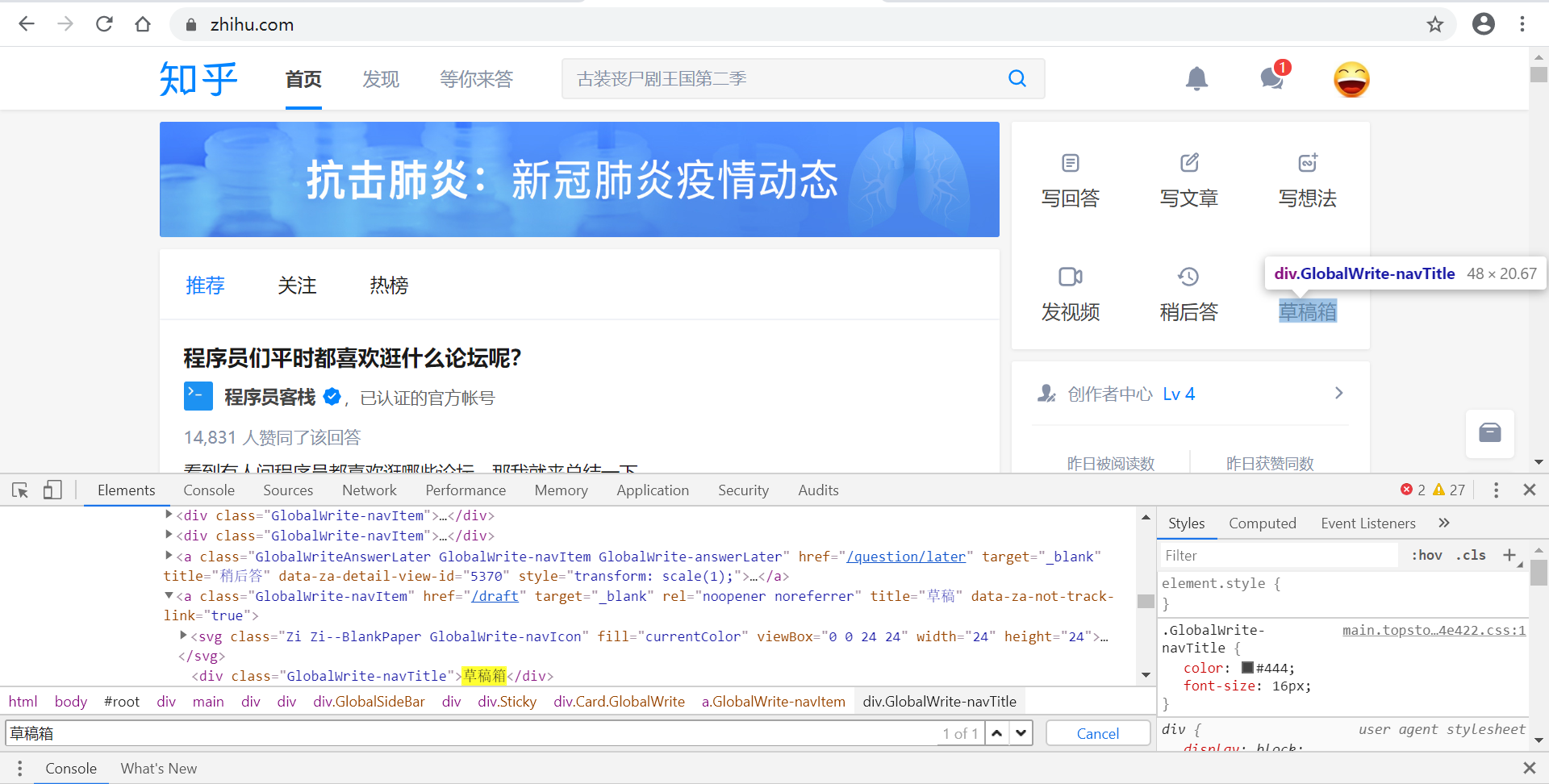
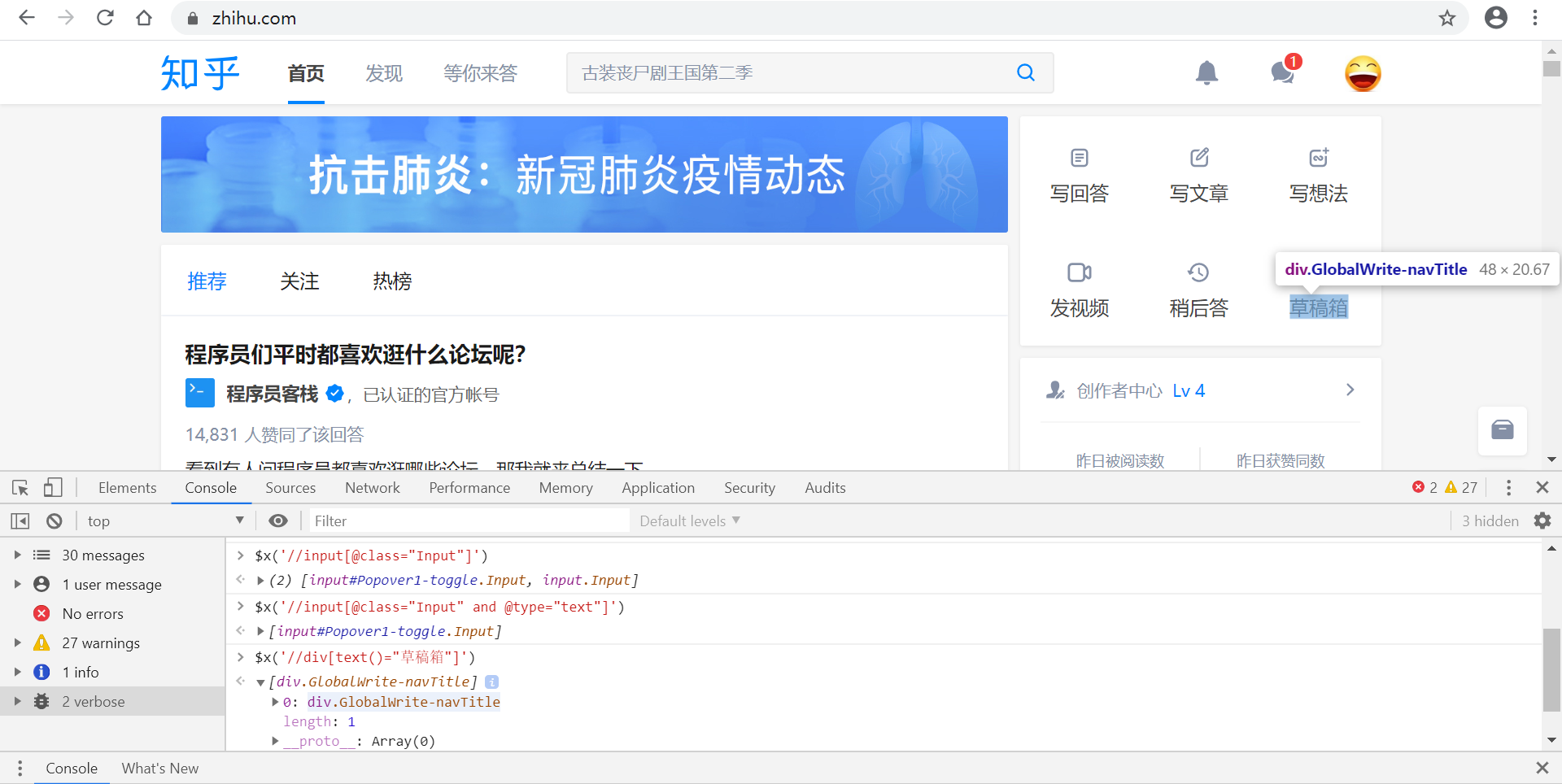
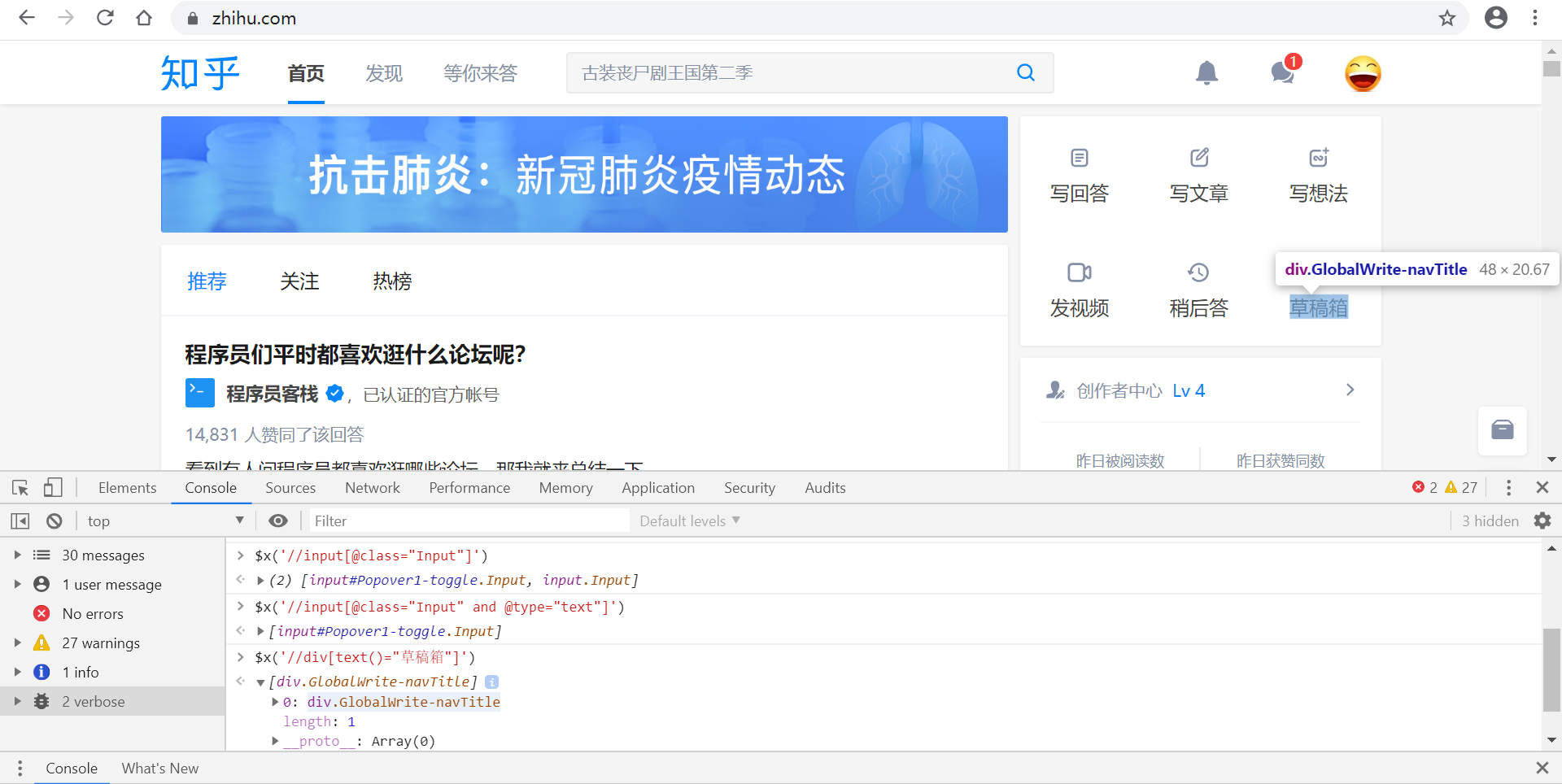
利用text()方法定位
$x('//div[text()="草稿箱"]')
![]()
![]()
-
利用contains()方法定位,也叫模糊定位
xpath = "//标签名[contains(@属性, '属性值')]"
![]()
![]()
-
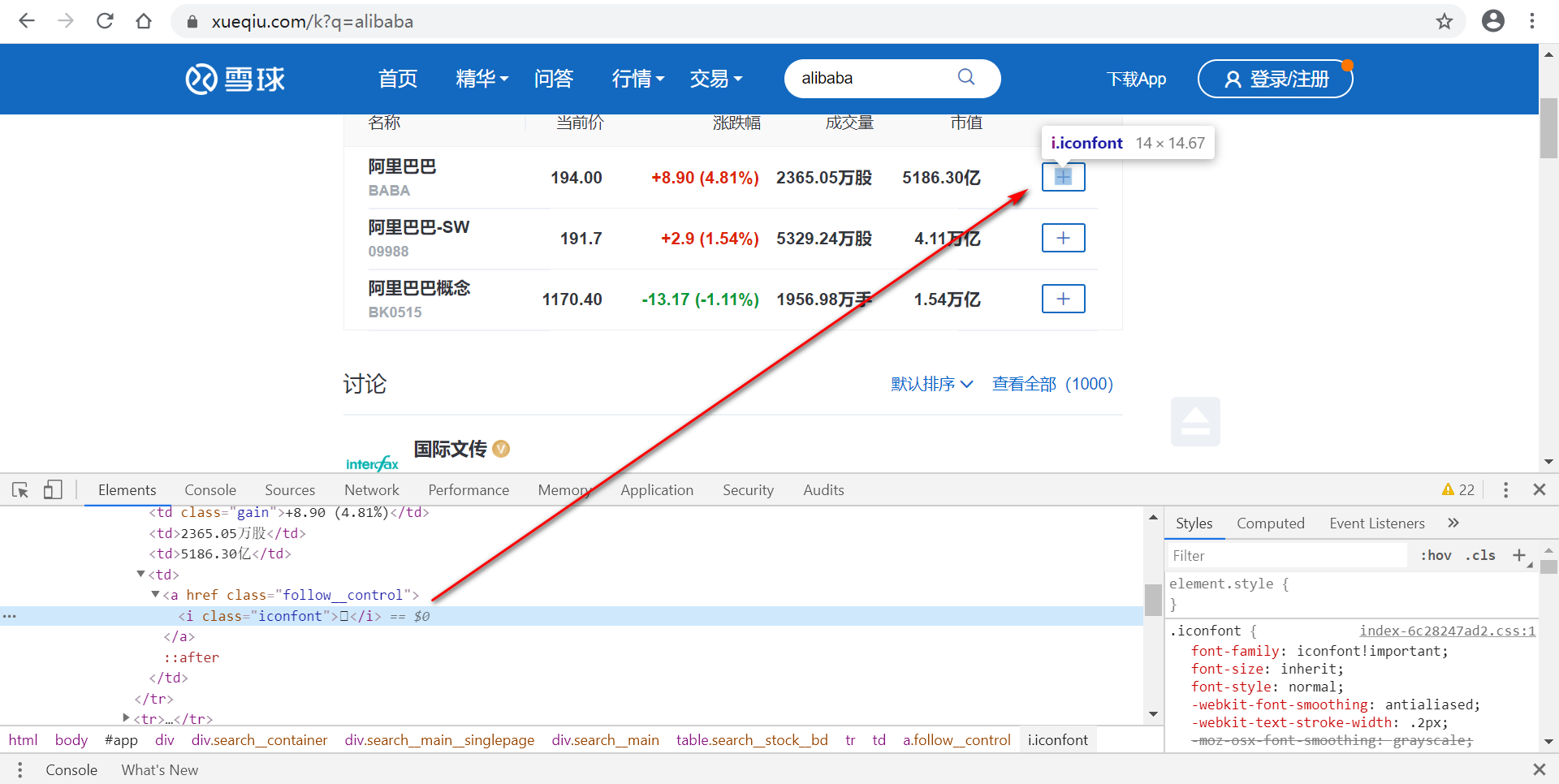
利用相对空间定位
如果一个元素无法通过自身属性直接定位到,则可以先定位它的父(或父的父,它爷爷)元素,然后再找下一级即可。
例如要定位如下元素:
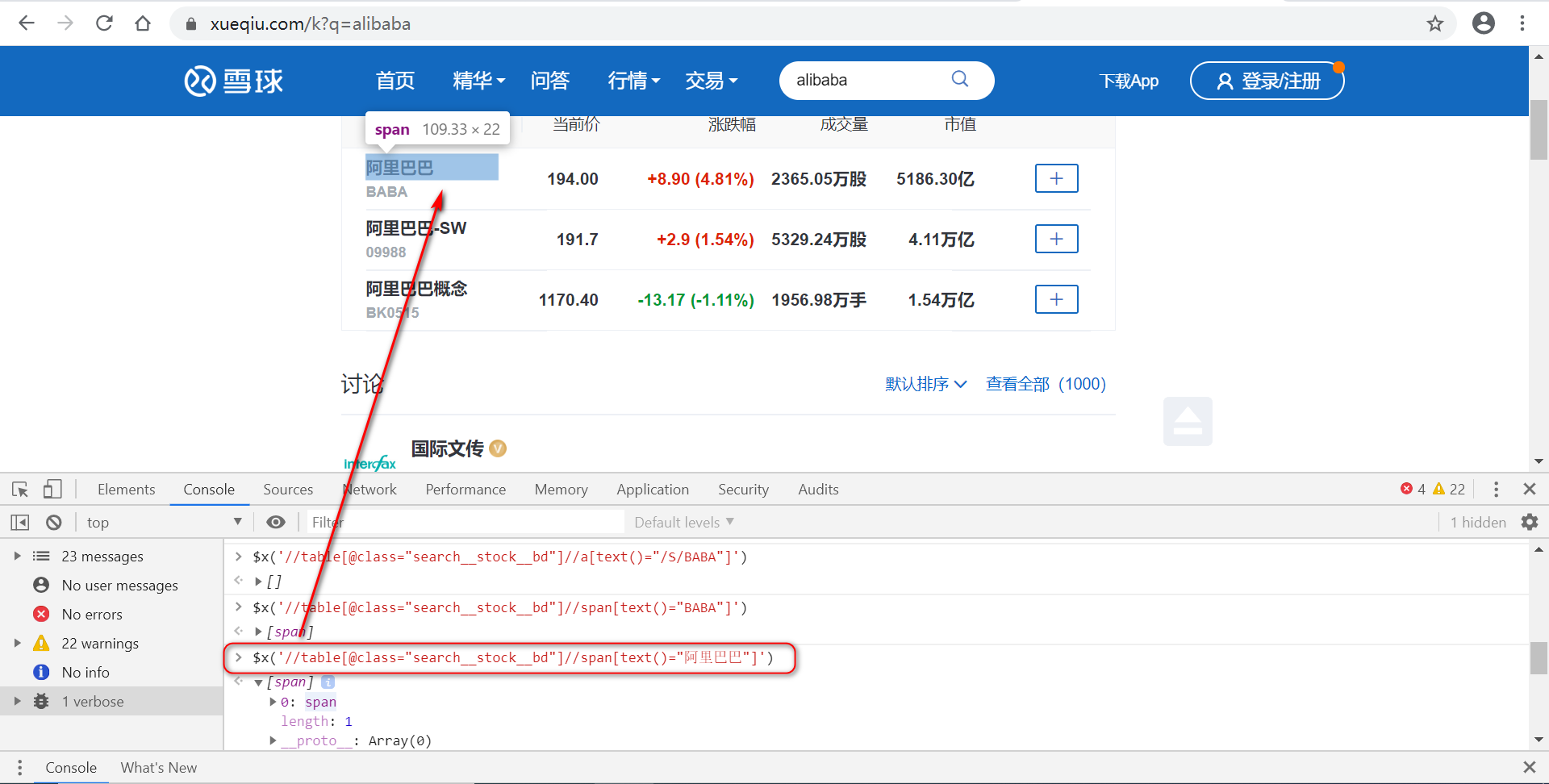
![]()
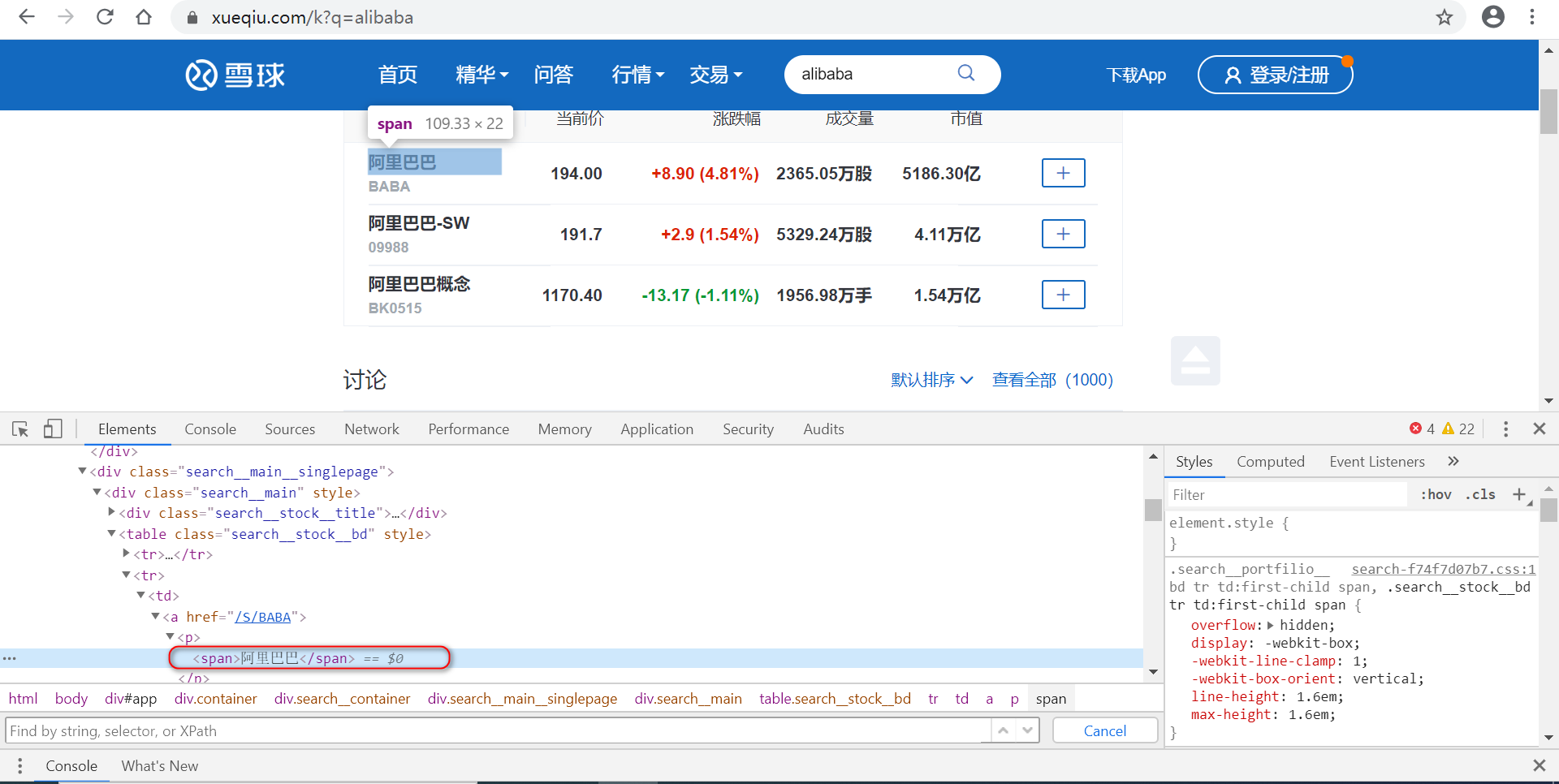
首先定位到“阿里巴巴”
![]()
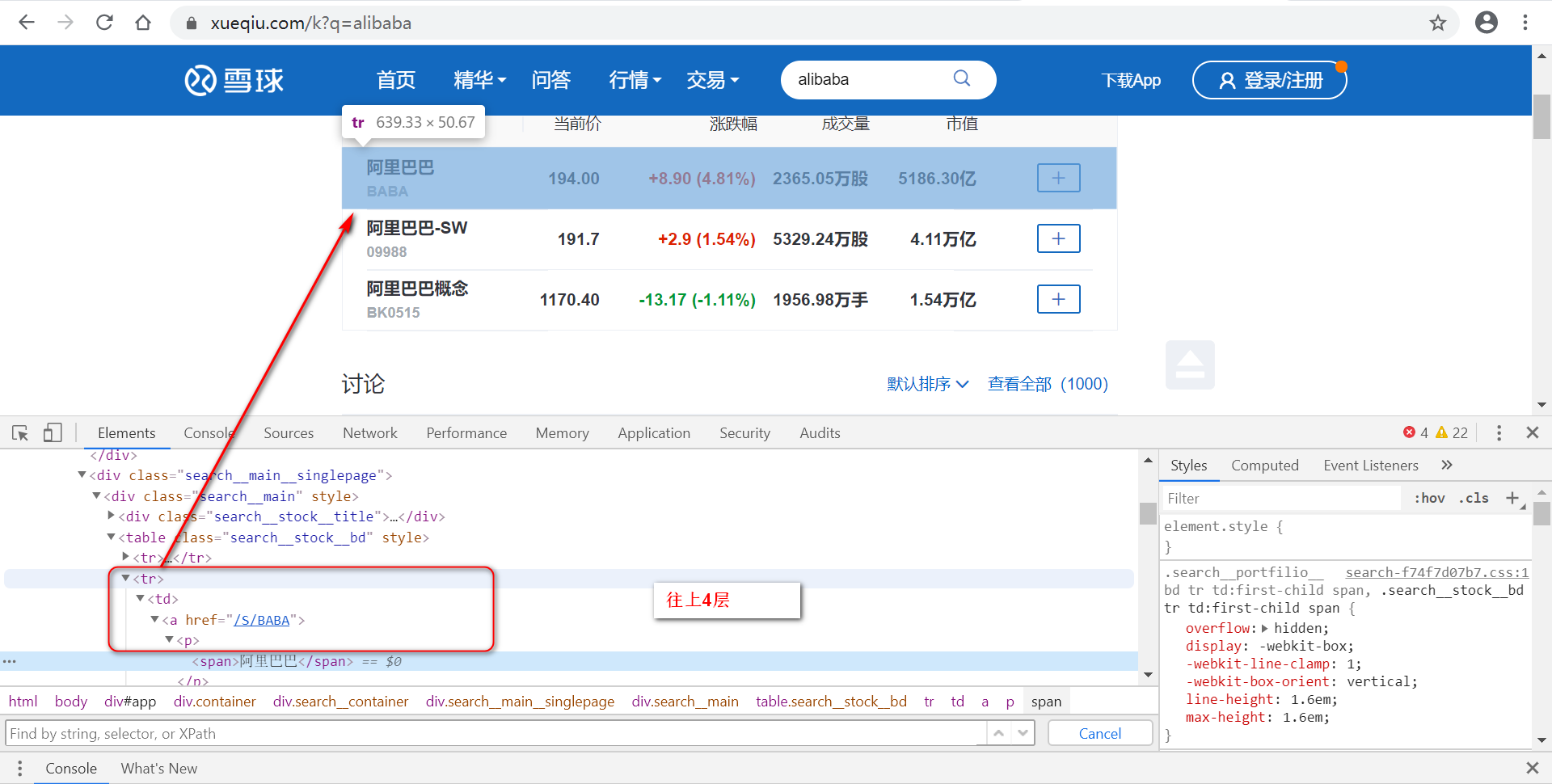
看到“阿里巴巴”要往上4层才与定位的元素在同一父类元素下
![]()
![]()
![]()
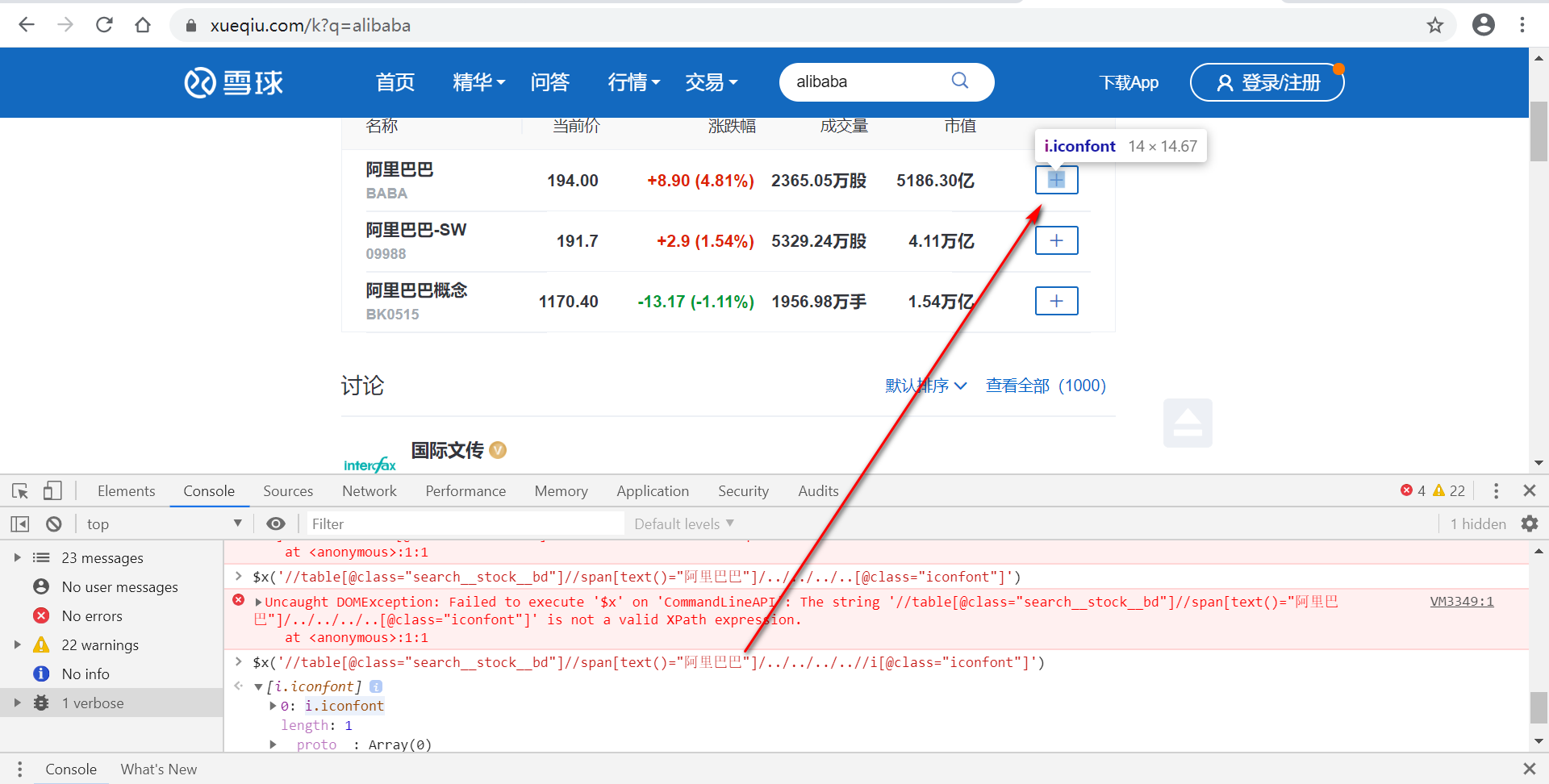
$x('//table[@class="search__stock__bd"]//span[text()="阿里巴巴"]/../../../..//i[@class="iconfont"]')
![]()
-
逻辑定位
//*[@text="交易" and contains(@resuorce-id,'current_price')]




其他定位
通过id属性定位
driver.find_element_by_id(‘loginForm’)
#定位<form id="loginForm">
#简单写法,导入By模块
from selenium.webdriver.common.by import By
driver.find_element(By.ID,"loginForm")
通过name属性定位
driver.find_element_by_name(‘username’)
#定位<input name="username" type="text" />
driver.find_element(By.NAME,"username")
通过class名定位
driver.find_element_by_class_name(‘content’)
#定位<p class="content">Site content goes here.</p>
driver.find_element(By.CLASS_NAME,"content")
通过TagName标签名定位
driver.find_element_by_tag_name(‘input’)
#定位<input name="username" type="text" />,如果匹配了多个,默认只选第一个
driver.find_element(By.TAG_NAME,"input")
通过link text定位,就是通过a标签的text内容定位
driver.find_element_by_link_text(‘Continue’) #全匹配
driver.find_element_by_partial_link_text(‘Con’) #部分匹配
#定位<a href="continue.html">Continue</a>
driver.find_element(By.LINK_TEXT,‘Continue’)
driver.find_element(By.PARTIAL_LINK_TEXT,‘Con’)
元素Element事件
元素定位是返回元素,需要对元素进行操作才可以实现自动化测试。
Element对象有一系列的方法,可以操作定位的元素。
1.Element.click() 点击元素
driver.find_elements_by_link_text(‘Continue’).click()
2.输入文本
# 有些输入框中原有的文本不会被自动清除掉,需要使用clear()方法清除 driver.find_element_by_name(‘username’).clear()
# 输入内容 driver.find_element_by_name(‘username’).send_keys("username")
3.获取参数
# 获取对应特性值
Element.get_attribute(name)
# 获取对应属性值
Element.get_property(name)
# property是DOM中的属性,是JavaScript里的对象;attribute是HTML标签上的特性,它的值只能够是字符串。一般用 attr就行
# 获取当前元素的内容
Element.text
# 获取当前元素标签名
Element.tag_name
# 获取当前元素尺寸
Element.size
# 获取当前元素坐标
Element.location
4.判断方法
#判断当前元素是否可见
Element.is_displayed()
#判断当前元素是否被启用
Element.is_enabled()
#判断当前元素是否被选中
Element.is_selected()
等待
现在的网页,基本都是使用ajax异步的加载各种资源的,所以可能我们需要定位的元素不会第一时间就加载出 来,这时候是无法定位的,也就会抛出异常。而解决这个问题的方法,就是等待。
定时等待
不推荐使用定时等待,在正式脚本中很少使用,可在调试脚本的时候使用。
import time
time.sleep(10)
隐式等待
一种全局的设置,设置一个最大时长,如果定位的元素没有出现就会循环查找元素直到超时或者元素出现,相比于定时等待,这个更加弹性,元素出现了就不会等待了。
from time import sleep
from selenium import webdriver # driver需要的依赖
from selenium.webdriver.common.by import By # 元素定位
class TestBiying:
# 做初始化的操作
def setup_method(self):
# 实例化webdriver对象
self.driver = webdriver.Chrome()
# 打开url
self.driver.get('https://baidu.com/')
# 隐式等待
self.driver.implicitly_wait(5)
显式等待
显式等待就是设定一个条件,同时设置一个时间,在这个时间范围内,如果网页出现符合的条件的元素,就不等待继续执行,如果没有则循环查找元素直到超时报错。
from selenium import webdriver from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delay_loading")
try:
element=WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,"myDynamicElement")))
finally:
driver.quit()
这段代码主要讲的是:
- 实例化WebDriverWait类,传入driver与最大等待时长10秒 ,默认poll_frequency(扫描频率)为0.5秒。
- until()是WebDriverWait类的一个方法,参数是一个等待条件(expected_conditions),如果满足等待条件,则WebDriverWait类停止等待,并且返回expected_conditions的值,否则当等待时间到将抛出 TimeoutException异常。
- WebDriverWait类还有个方法until_not(),如果不满足等待条件,就停止等待。
- 等待条件(expected_conditions)如果成功则返回element对象,或有些是返回布尔值,或者其它不为 null的值。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
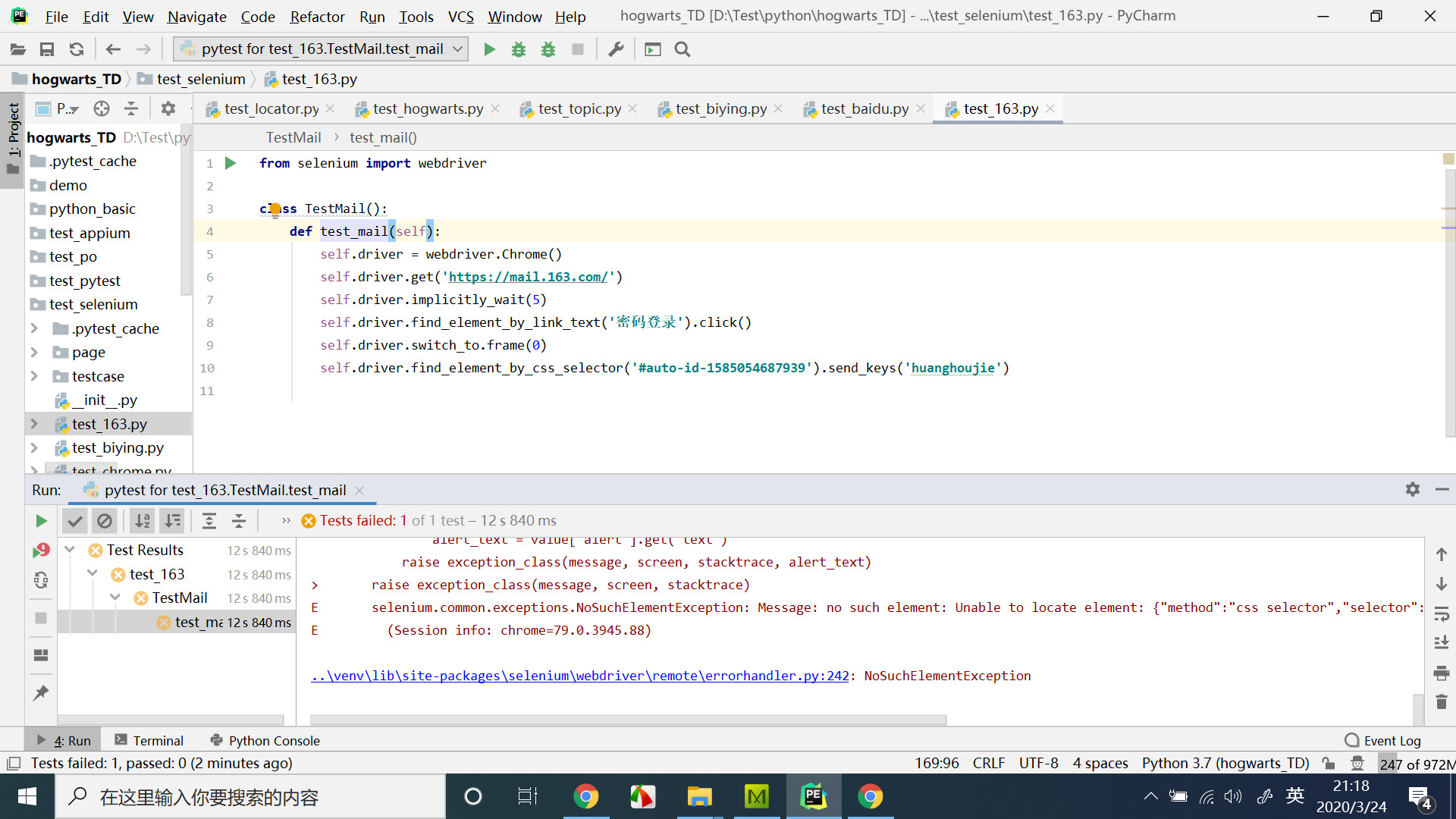
class TestMail():
def setup(self):
self.driver = webdriver.Chrome()
def test_window(self):
self.driver.get('https://testerhome.com/topics/21805')
self.driver.implicitly_wait(5)
self.driver.find_element_by_link_text('第六届中国互联网测试开发大会').click()
# 打印窗口,可以观察到出现了多个窗口
print(self.driver.window_handles)
# 切换窗口
self.driver.switch_to.window(self.driver.window_handles[1])
ele = (By.LINK_TEXT,'演讲申请')
WebDriverWait(self.driver,10).until(EC.element_to_be_clickable(ele))
self.driver.find_element(*ele ).click()
等待条件(expected_conditions)内置的方法主要有:
- title_is : #验证 driver 的 title 是否与传入的 title 一致,返回布尔值。
- title_contains : #验证 driver 的 title 中是否包含传入的 title,返回布尔值。
- presence_of_element_located :# 验证页面中是否存在传入的元素,传入元素的格式是 locator 元组,如 (By.ID, "id1"),返回element对象。
- visibility_of_element_located : #验证页面中传入的元素( locator 元组格式 )是否可见,这里的可见不仅仅是 display 属性非 None ,还意味着宽高均大于0,返回element对象或false。
- visibility_of : #验证页面中传入的元素( WebElement 格式 )是否可见。返回element对象或false。
- presence_of_all_elements_located : #验证页面中是否存在传入的所有元素,传入元素的格式是 locator 元组构成 的 list,如 [(By.ID, "id1"), (By.NAME, "name1"),返回element或false。
- text_to_be_present_in_element : #验证在指定页面元素的text中是否包含传入的文本,返回布尔值。
- text_to_be_present_in_element_value : #验证在指定页面元素的value中是否包含传入的文本,返回布尔值。
- frame_to_be_available_and_switch_to_it : #验证frame是否可切入,传入 locator 元组 或 WebElement,返回布尔值。
- invisibility_of_element_located : #验证页面中传入的元素( locator 元组格式 )是否可见,返回布尔值。
- element_to_be_clickable : #验证页面中传入的元素( WebElement 格式 )是否点击,返回element。
- staleness_of : #判断传入元素(WebElement 格式)是否仍在DOM中,返回布尔值。
- element_to_be_selected : #判断传入元素(WebElement 格式)是否被选中,返回布尔值。
- element_located_to_be_selected :# 判断传入元素(locator 元组格式)是否被选中,返回布尔值。
- element_selection_state_to_be :# 验证传入的可选择元素(WebElement 格式)是否处于某传入状态,返回布尔值。
- element_located_selection_state_to_be : #验证传入的可选择元素(WebElement 格式)是否处于某传入状态,返回布尔值。
- alert_is_present : #验证是否有 alert 出现,返回alert对象。
一般使用:检查元素是否存在、检查元素是否可见、检查元素是否可点击。
1.presence_of_element_located :# 验证页面中是否存在传入的元素,传入元素的格式是 locator 元组,如 (By.ID, "id1"),返回element对象 。2.visibility_of_element_located : #验证页面中传入的元素( locator 元组格式 )是否可见,这里的可见不仅仅是 display 属性非 None ,还意味着宽高均大于0,返回element对象或false。
3.visibility_of : #验证页面中传入的元素( WebElement 格式 )是否可见。返回element对象或false。
4.invisibility_of_element_located : #验证页面中传入的元素( locator 元组格式 )是否可见,返回布尔值。
5.element_to_be_clickable : #验证页面中传入的元素( WebElement 格式 )是否点击,返回element。
ps:具体的区别不是很明白。
ps:传入格式?
元素状态大概这样区分
title出现
dom出现 presence
css出现 visibility
js执行 clickable
应用场景
隐式等待尽量默认都加上,时间限定在3-6s,不要太长,这是为了所有的findElemen方法都有一个很好的缓冲。
显式等待用来处理隐式等待无法解决的一些问题,比如文件上传。
定时等待一般不推荐,除非特殊情况。
Action Chains类模拟鼠标行为
ActionChains简介
Actionchains是selenium里面专门处理鼠标相关的操作如:鼠标移动,鼠标按钮操作,按键和上下文菜单(鼠标右键)交互。
这对于做更复杂的动作非常有用,比如悬停和拖放。
Actionchains也可以和快捷键结合起来使用,如ctrl,shif,alt结合鼠标一起使用。
当你使用actionchains对象方法,行为事件是存储在actionchains对象队列。当你使用perform(),事件按顺序执行。
方法一:可以写一长串
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
方法二:可以分几步写
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
actions = ActionChains(driver)
actions.move_to_element(menu)
actions.click(hidden_submenu)
actions.perform()
使用Actionchains首先需要实例化,然后调用其中的方法,完成相应的操作。
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
browser =webdriver.Firefox()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 切换frame,id = 'iframeResult'
browser.switch_to.frame('iframeResult')
# 被拖拽的对象
source = browser.find_element_by_css_selector('#draggable')
# 目标对象
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
time.sleep(3)
browser.close()
常见的鼠标操作
click(on_element=None)
鼠标单击
click_and_hold(on_element=None)
鼠标单击并且按住不放
context_click(on_element=None)
右击
double_click(on_element=None)
双击
drag_and_drop(source, target)
拖拽
drag_and_drop_by_offset(source, xoffset, yoffset)
将目标拖动到指定的位置
key_down(value, element=None)
按住某个键,使用这个方法可以方便的实现某些快捷键,比如下面按下Ctrl+c键
ActionsChains(browser).key_down(Keys.CONTROL).send_keys('c').perform()
key_up(value, element=None)
松开某个键,可以配合上面的方法实现按下Ctrl+c并且释放。
ActionsChains(browser).key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform()
move_by_offset(xoffset, yoffset)
指定鼠标移动到某一个位置,需要给出两个坐标位置
move_to_element(to_element)
将鼠标移动到指定的某个元素的位置
move_to_element_with_offset(to_element, xoffset, yoffset)
移动鼠标到某个元素位置的偏移位置
perform()
将之前的一系列的ActionChains执行
release(on_element=None)
释放按下的鼠标
send_keys(*keys_to_send)
向某个元素位置输入值
send_keys_to_element(element, *keys_to_send)
向指定的元素输入数据
Frames与多窗⼝处理
官方把selenium.webdriver包中的switch方法全部封装成了witch_to包。
switch_to包的方法详解

- driver.switch_to.parent_frame()
是switch_to中独有的方法,可以切换到上一层的frame,对于层层嵌套的frame很有用。
switch_to.frame
![]()
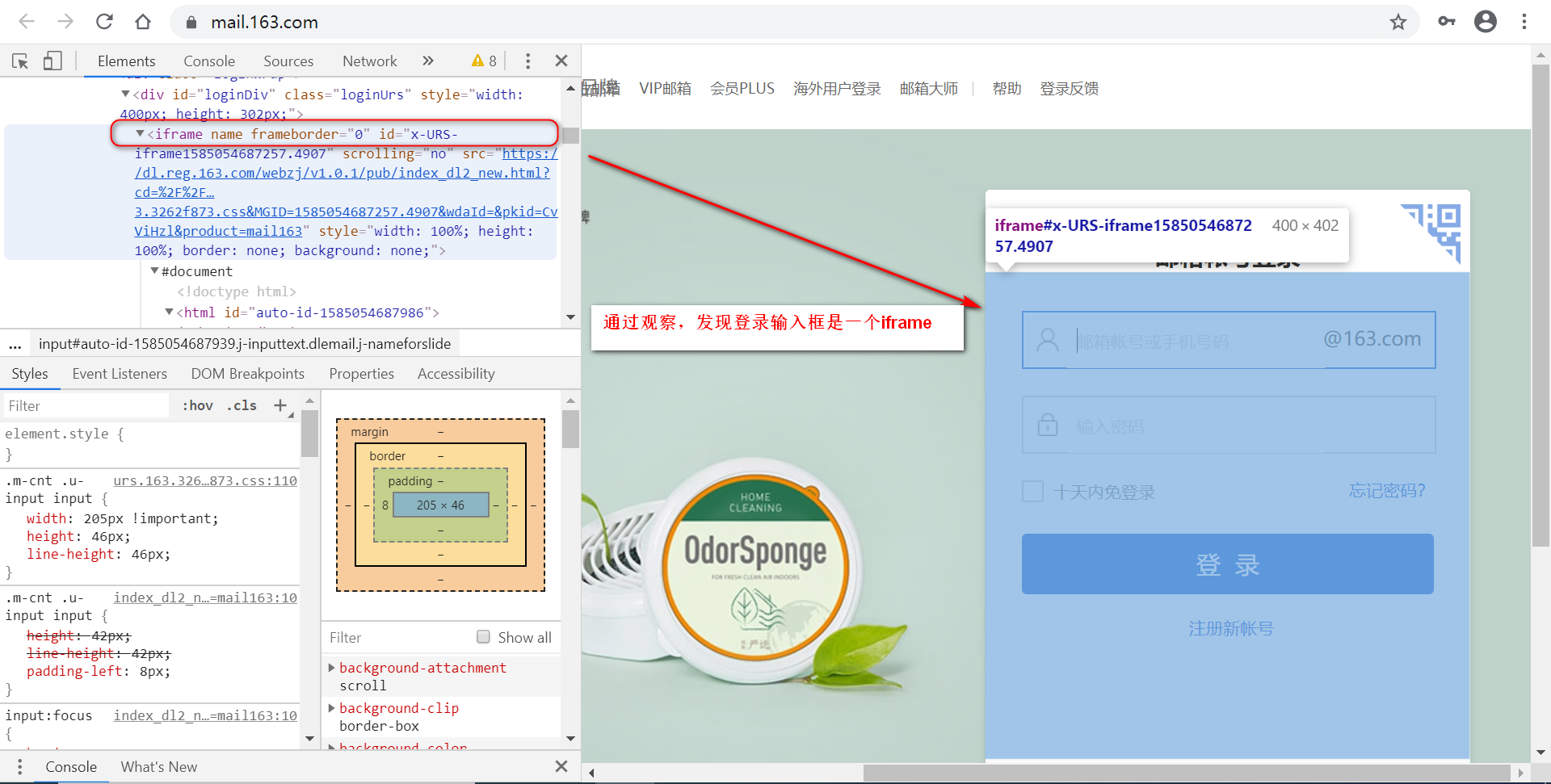
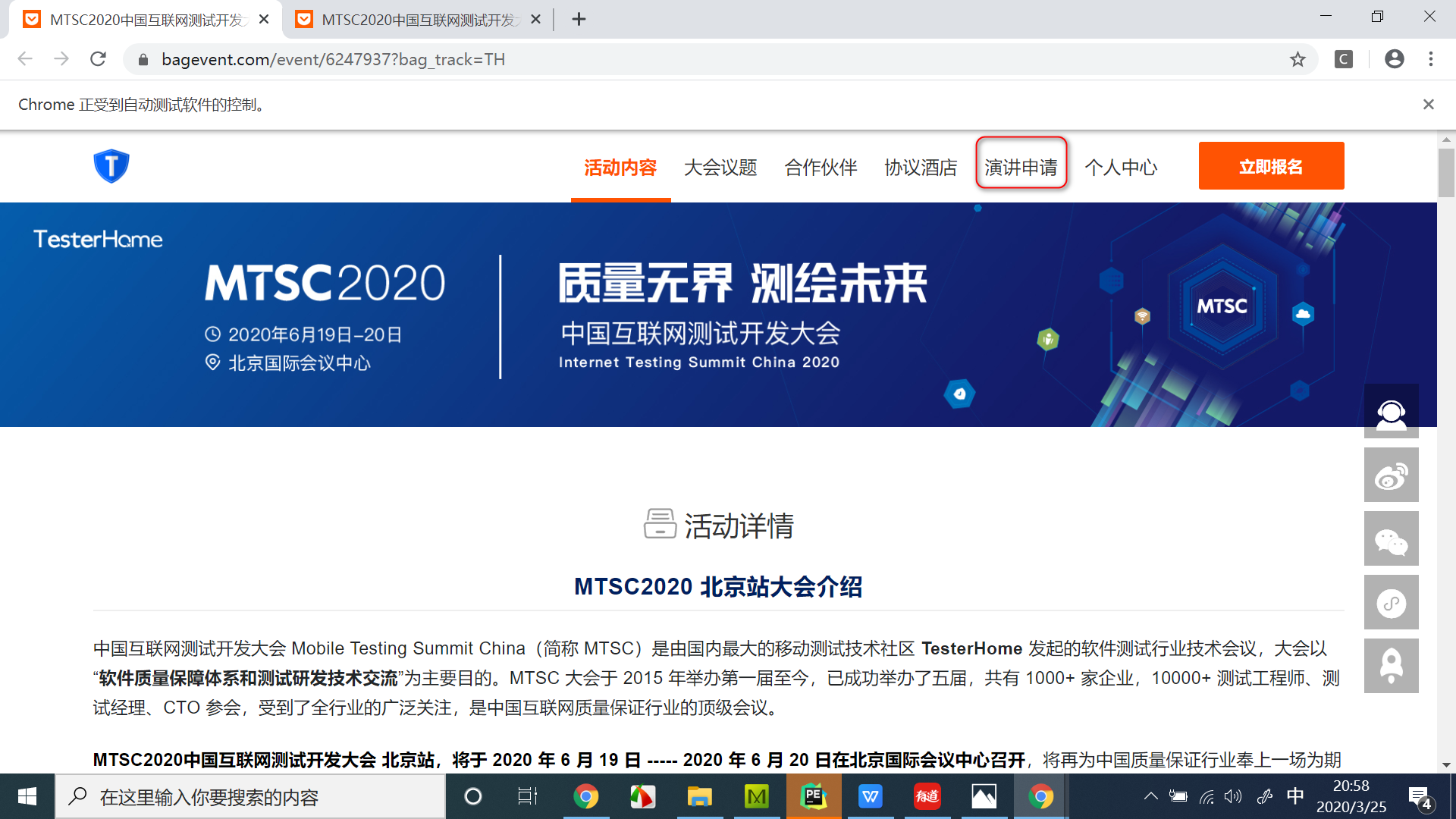
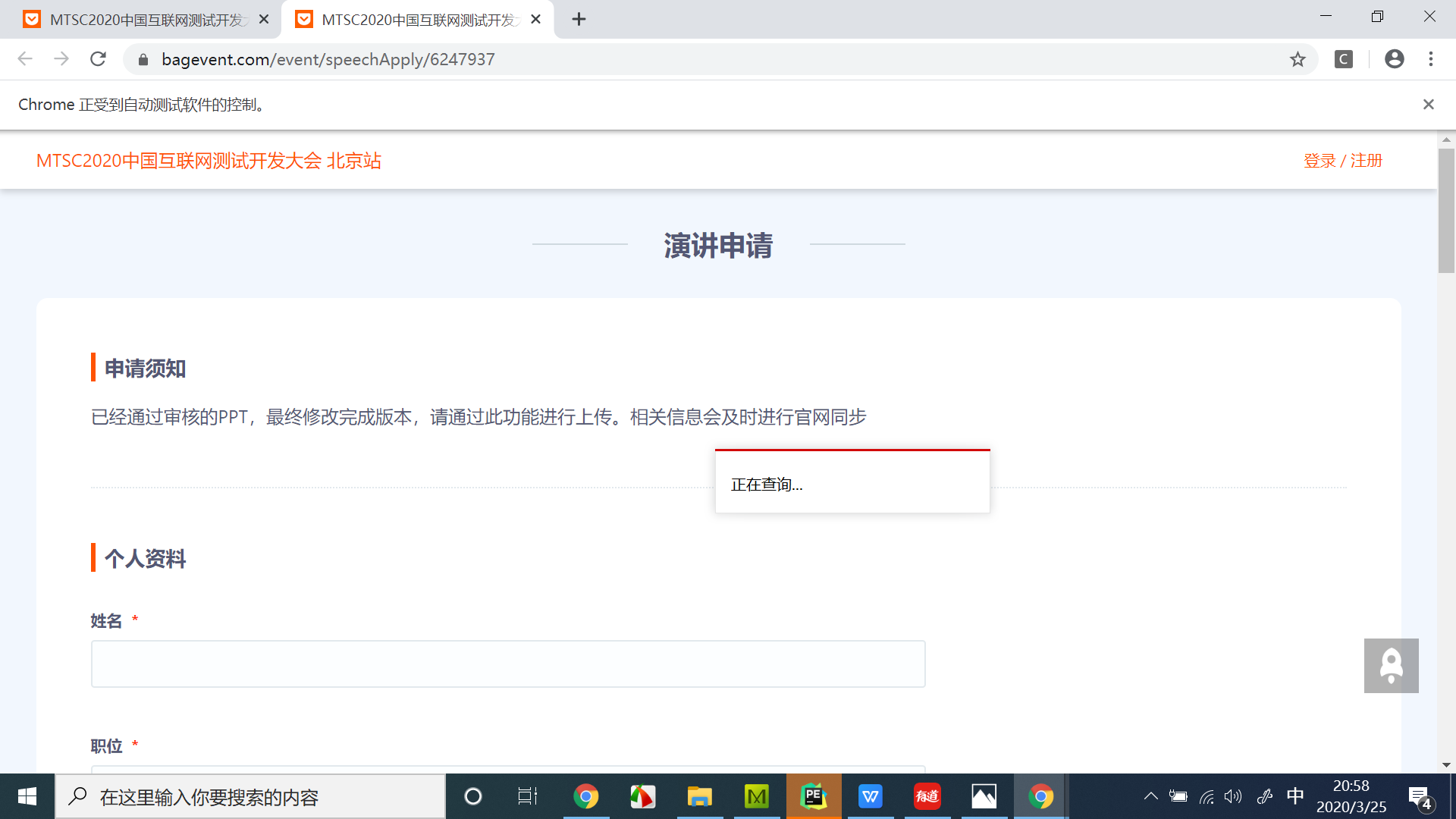
switch_to.window
例如,访问https://testerhome.com/topics/21805,点击“第六届中国互联网测试开发大会”,会弹出一个新的窗口,然后在新的窗口再点击“演讲申请”。
![]()
![]()
![]()

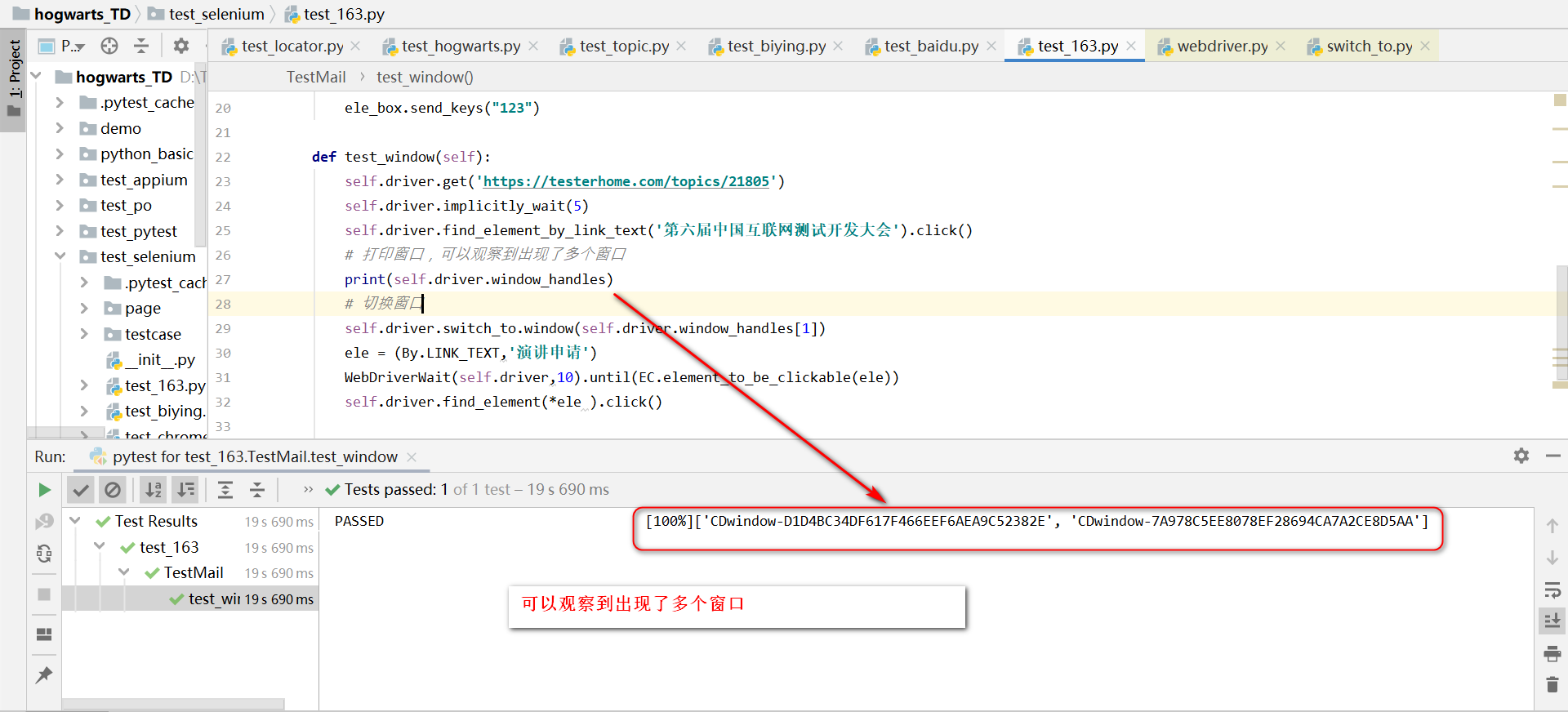
def test_window(self):
self.driver.get('https://testerhome.com/topics/21805')
self.driver.implicitly_wait(5)
self.driver.find_element_by_link_text('第六届中国互联网测试开发大会').click()
print(self.driver.window_handles)
self.driver.switch_to.window(self.driver.window_handles[1])
ele = (By.LINK_TEXT,'演讲申请')
WebDriverWait(self.driver,10).until(EC.element_to_be_clickable(ele))
self.driver.find_element(*ele ).click()
复用浏览器
通过设置Chrome options参数来复用浏览器。
Chrome Options是一个配置chrome启动时属性的类,通过这个参数我们可以为Chrome添加参数,以实现一些功能,如设置默认编码、设置代理、设置无头模式等。
首先打开一个调试的浏览器,需要在环境变量中PATH里将chrome的路径添加进去。
chrome --remote-debugging-port=9222
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
class TestHome():
def setup(self):
chromeOptions = Options()
#9222是端口号,只要是不被占用的端口号都可以
chromeOptions.add_experimental_option('debuggerAddress', '127.0.0.1:9222')
# 使用webdriver,需要from selenium import webdriver
self.driver = webdriver.Chrome(options=chromeOptions)
# 隐式等待,是全局生效的
self.driver.implicitly_wait(3)

实例化webdriver下的ChromeOptions
设置浏览器的调试地址
复用浏览器
这两种形式的区别?
cookie处理
如何获取cookie?
执行JavaScript
在打开一个网页的时候,可以执行JS获取一些数据,特别是性能数据。
一般只会用到execute_script,源代码如下:
def execute_script(self, script, *args):
"""
Synchronously Executes JavaScript in the current window/frame.
:Args:
- script: The JavaScript to execute.
- \*args: Any applicable arguments for your JavaScript.
:Usage:
driver.execute_script('return document.title;')
"""
converted_args = list(args)
command = None
if self.w3c:
command = Command.W3C_EXECUTE_SCRIPT
else:
command = Command.EXECUTE_SCRIPT
return self.execute(command, {
'script': script,
'args': converted_args})['value']
在Chrome中也可以执行JS,可以先在Chrome中验证,再copy到脚本中。
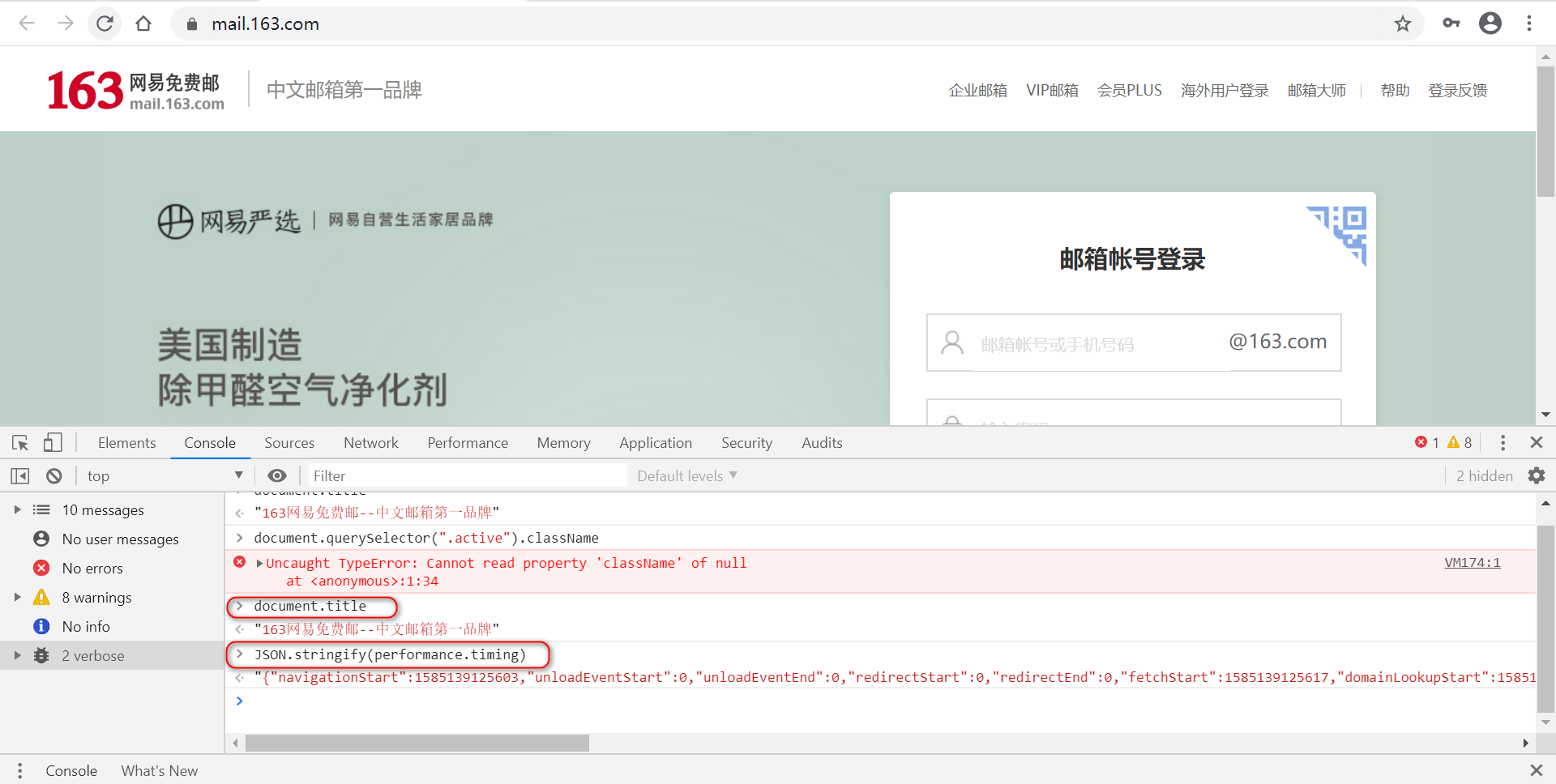
如打开网站,获取性能数据。
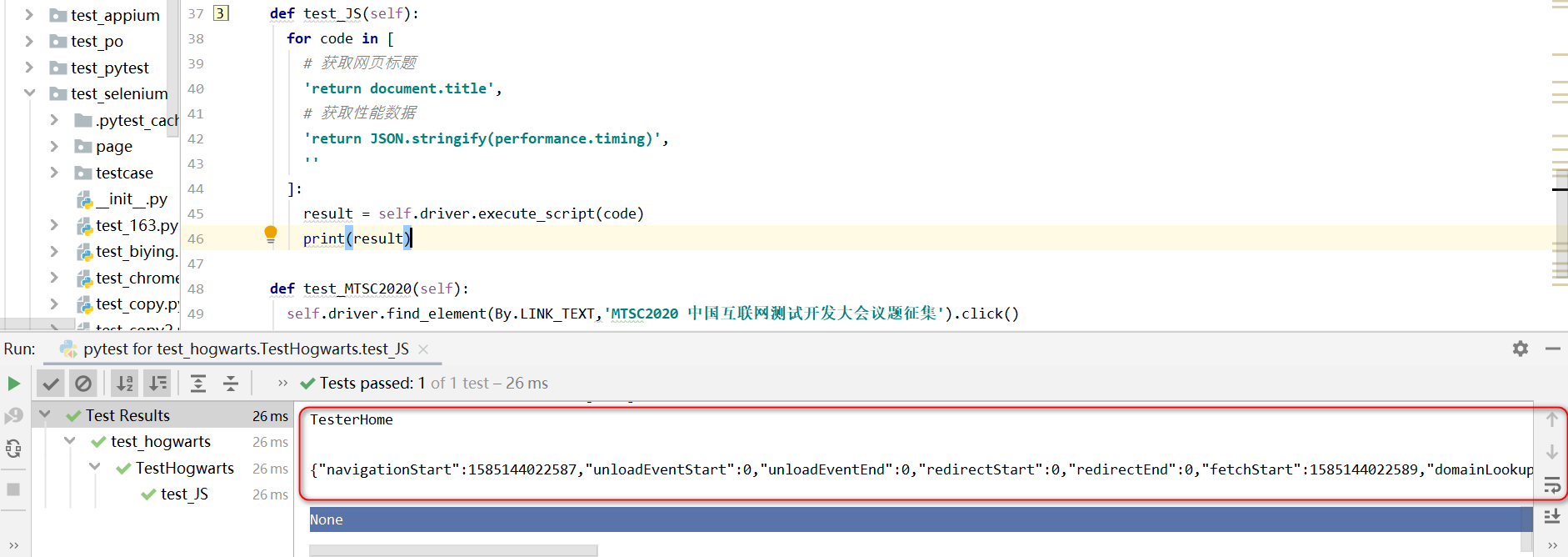
def test_JS(self):
for code in [
# 获取网页标题
'return document.title',
# 获取性能数据
'return JSON.stringify(performance.timing)',
]:
result = self.driver.execute_script(code)
print(result)
结果如下:
多浏览器测试
通过参数传入浏览器,使用命令行执行脚本。
无UI执行测试用例
1.phantomJS
这个项目已经没有维护了。
2.chrome的headless模式
通过设置Chrome options参数
options.add_argument('--headless')
文件上传和下载
PO
PO是什么
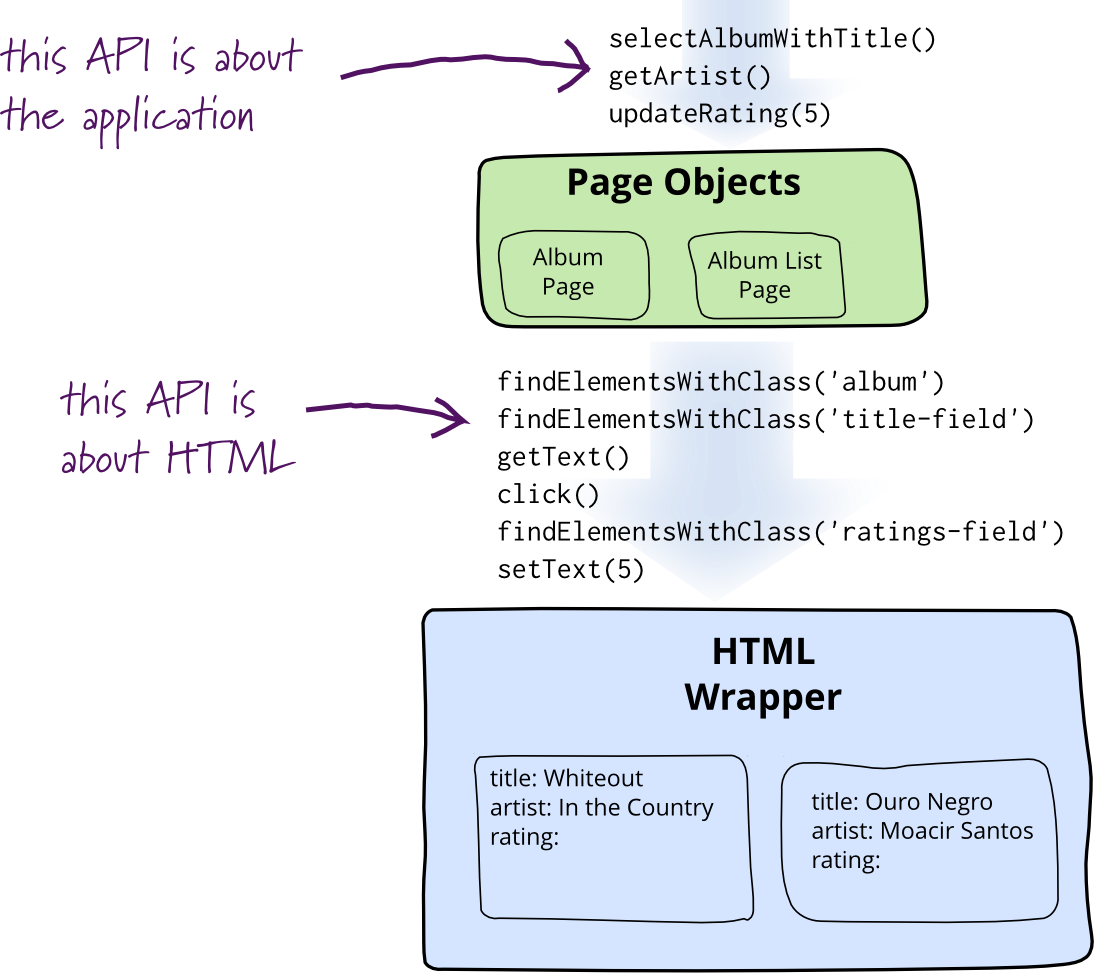
PageObject,顾名思义,页面对象。
PO适用于UI自动化测试。
2013年马丁·福勒提出PageObject思想
https://martinfowler.com/bliki/PageObject.html
selenium引入PO
https://github.com/SeleniumHQ/selenium/wiki/PageObjects
为什么需要使用PO
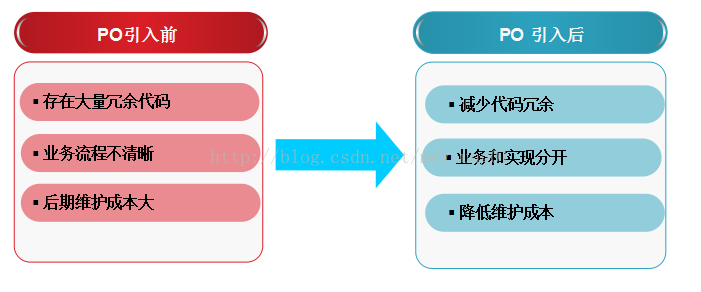
在做UI自动化测试的时候,让人很头疼的一个问题是页面元素经常变化,这时候测试用例也得跟着改变。为了让测试用例保持稳定,可以把元素定位、元素操作与测试用例进行分离。把元素定位、元素操作具体操作细节封装成一个方法,测试用例直接调用这个方法,编写测试用例的时候就无需关注操作细节。在业务流程没有变化的情况下,页面元素发生了变化,那只需要对封装方法进行修改,测试用例可以保持不变。
方便分工与合作
方便从业务角度理解测试用例
PO的原则
- ⽅法意义
❖ ⽤公共⽅法代表UI所提供的功能
❖ ⽅法应该返回其他的PageObject或者返回⽤于断⾔的数据
❖ 同样的⾏为不同的结果可以建模为不同的⽅法
❖ 不要在⽅法内加断⾔ - 字段意义
❖ 不要暴露页⾯内部的元素给外部
❖ 不需要建模UI内的所有元素
如何使用PO
首页
注册页
登录页

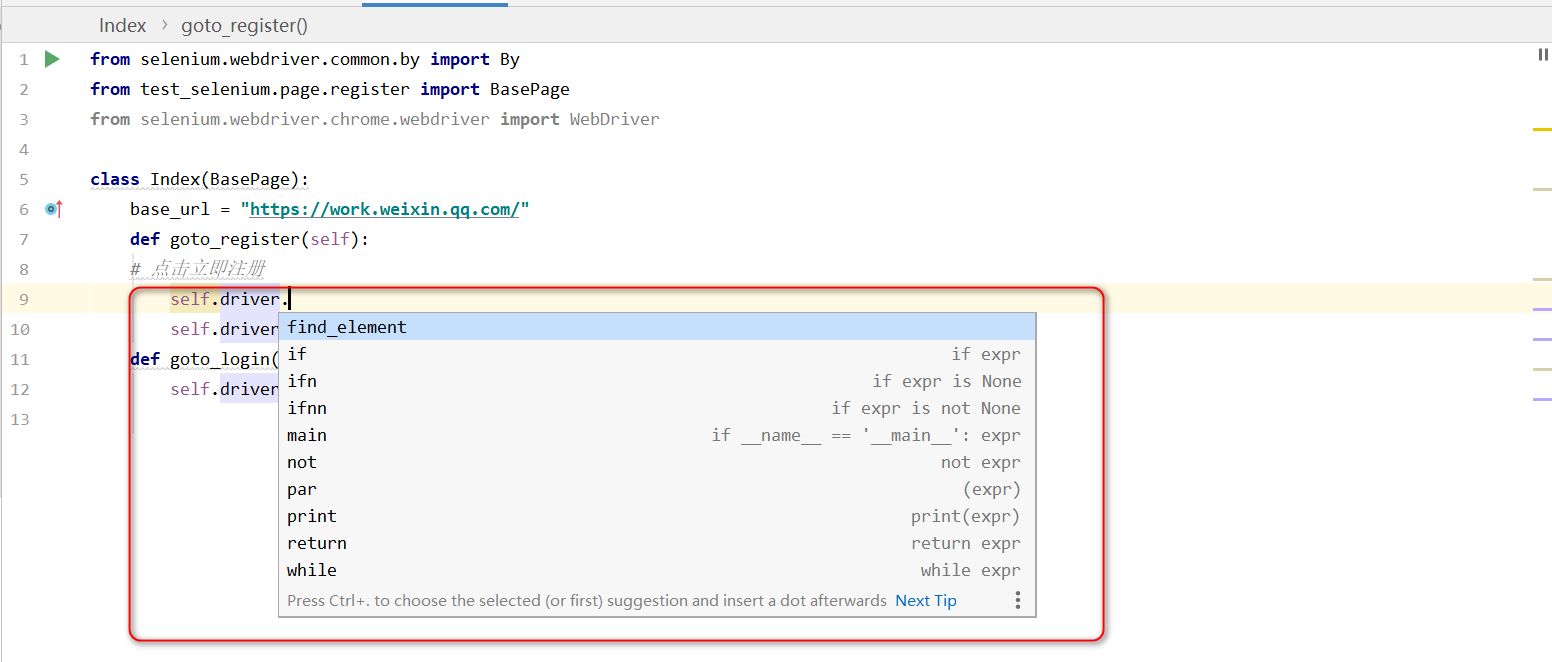
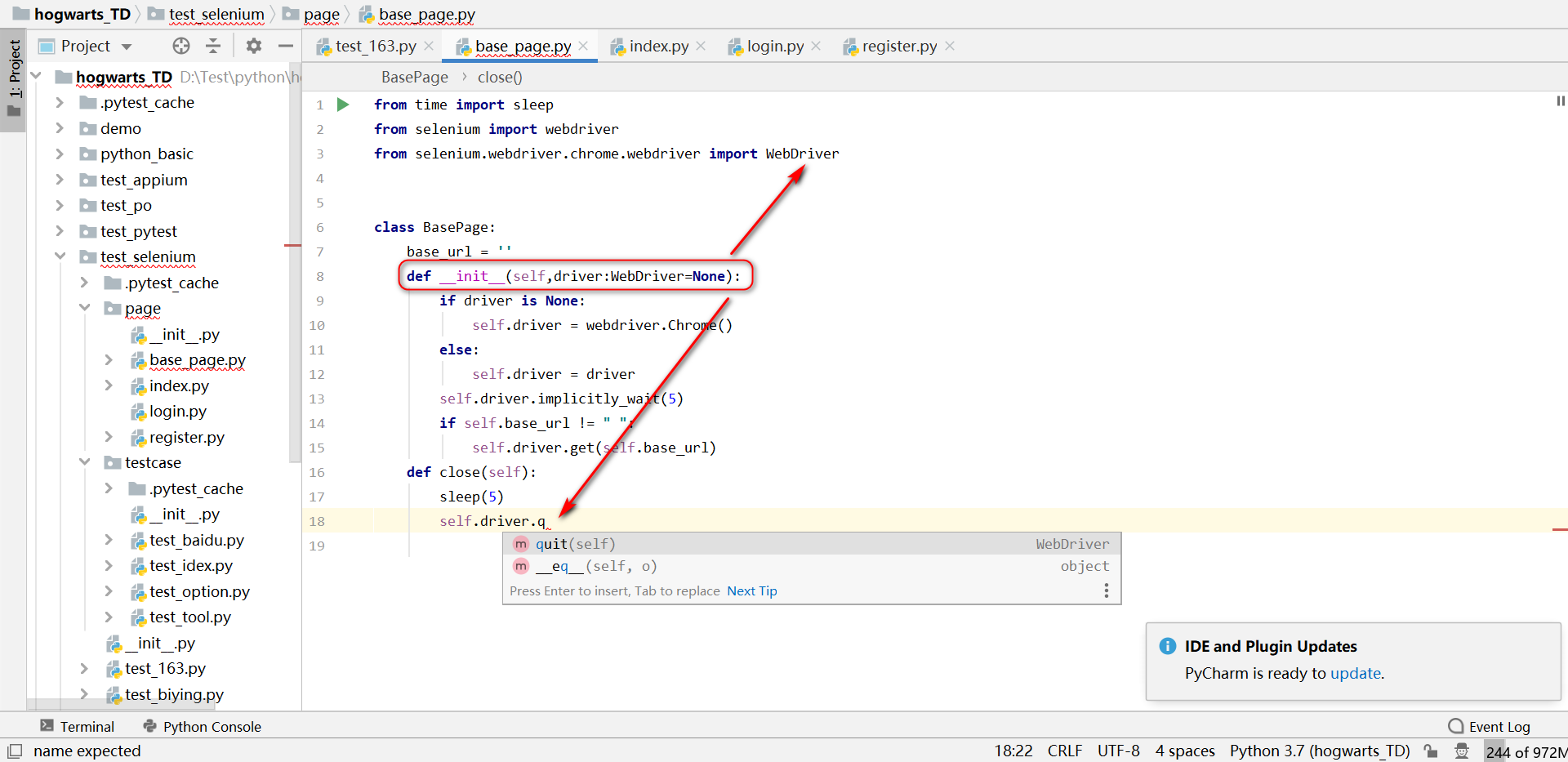
BasePage声明driver的类型为WebDriver,不然继承BasePage后不能自动带出driver的方法。


参数化
Selenium自动化测试遇到的问题
-
[Pycharm] AttributeError: module 'selenium.webdriver' has no attribute 'Firefox'
https://www.jianshu.com/p/2409c638665a
重新创建一个虚拟环境,创建一个项目 -
element is not attached to the page document
-
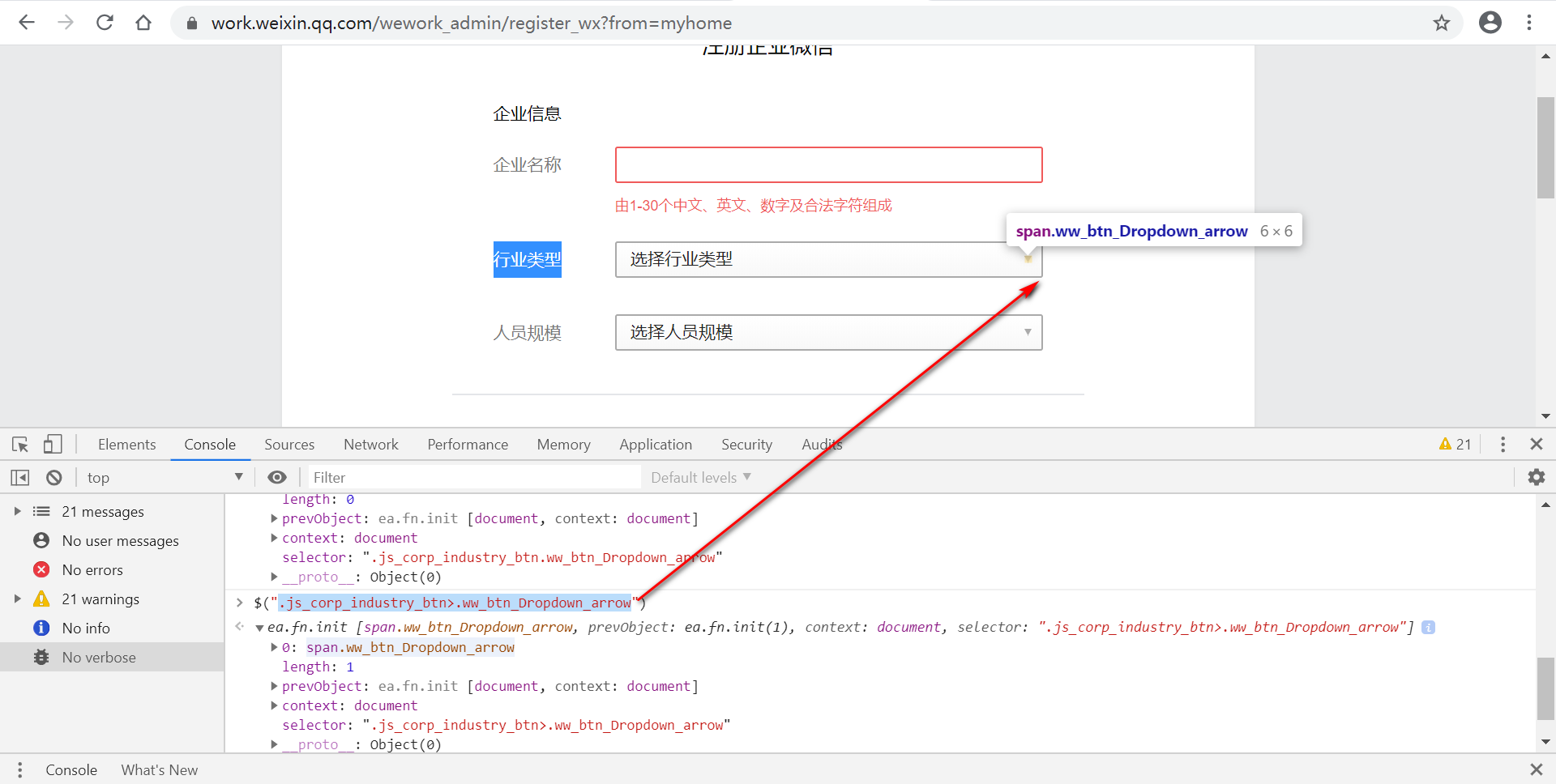
NoSuchElementException
![]()
常见控件
单选框、复选框、下拉框、表格


 浙公网安备 33010602011771号
浙公网安备 33010602011771号