GPT
2018 年,OpenAI 提出了基于 Transformer Decoder 架构的语言模型 GPT,并将在 5 年后轰动全世界……
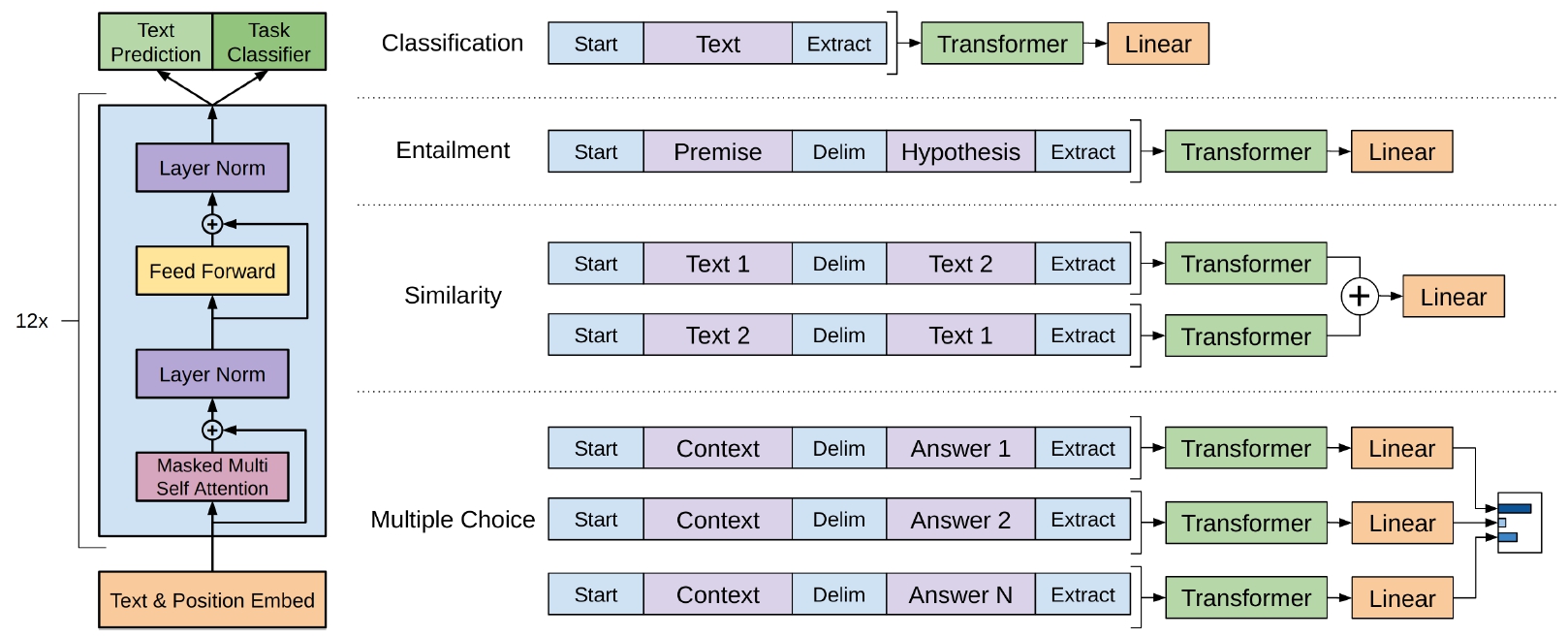
- 论文:Improving Language Understanding by Generative Pre-Training
- 博客:Improving language understanding with unsupervised learning | OpenAI
模型定义
import torch as th
import torch.nn as nn
# 字符表和映射
vocab = list("abcdefghijklmnopqrstuvwxyz ,.!?") # 简单字符表
stoi = {ch: i for i, ch in enumerate(vocab)}
itos = {i: ch for i, ch in enumerate(vocab)}
# 超参数
vocab_size = len(vocab)
embed_dim = 32
num_heads = 2
num_layers = 2
block_size = 16 # 最大输入长度
class SimpleGPT(nn.Module):
def __init__(self):
super().__init__()
self.token_emb = nn.Embedding(vocab_size, embed_dim)
self.pos_emb = nn.Embedding(block_size, embed_dim)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, batch_first=True),
num_layers=num_layers
)
self.ln = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, vocab_size)
def forward(self, idx):
N = idx.shape[1]
token_emb = self.token_emb(idx) # (B, N, D)
pos = th.arange(N, device=idx.device)
pos_emb = self.pos_emb(pos) # (N, D)
x = token_emb + pos_emb # (B, N, D)
mask = nn.Transformer.generate_square_subsequent_mask(N)
x = self.transformer(x, mask=mask)
x = self.ln(x)
logits = self.head(x) # (B, N, vocab_size)
return logits
构造数据
# 超参数
batch_size = 8
num_epochs = 500
lr = 1e-2
# 构造训练数据
text = "hello world. hello world. hello world."
data = [stoi[c] for c in text]
def get_batch():
# 随机采样 batch
ix = th.randint(0, len(data) - block_size - 1, (batch_size,))
x = th.stack([th.tensor(data[i:i+block_size]) for i in ix])
y = th.stack([th.tensor(data[i+1:i+block_size+1]) for i in ix])
return x, y
训练
import torch.nn.functional as F
# 实例化模型和优化器
device = th.device("cuda" if th.cuda.is_available() else "cpu")
model = SimpleGPT().to(device)
optimizer = th.optim.Adam(model.parameters(), lr=lr)
# 训练循环
for epoch in range(num_epochs):
model.train()
x, y = get_batch()
x, y = x.to(device), y.to(device)
logits = model(x)
loss = F.cross_entropy(logits.view(-1, vocab_size), y.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 50 == 0 or epoch == 0:
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")
生成
# 推理函数:给定前缀,生成后续字符
def generate(model, prefix, max_new_tokens=20):
model.eval()
idx = th.tensor([[stoi[c] for c in prefix]], dtype=th.long, device=device)
for _ in range(max_new_tokens):
idx_cond = idx[:, -block_size:] # 只保留最后 block_size 个 token
logits = model(idx_cond)
next_id = th.argmax(logits[0, -1], dim=-1, keepdim=True)
idx = th.cat([idx, next_id.view(1, 1)], dim=1)
return ''.join([itos[i] for i in idx[0].tolist()])
output = generate(model, "hello", max_new_tokens=20)
print(output)
运行:
$ python main.py
hello world. hello world.
可以看到 SimpleGPT 成功学会了说 "hello world"!
参见:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号