正则化
简介
在深度学习领域,正则化是一种用于减小模型方差(避免过拟合)的方法。
- 偏差(bias):欠拟合
- 方差(variance):过拟合
正则化的方法是在成本函数中加入正则化项。
\(L_2\) 正则化
\[J(w, b) = \frac{1}{m} \sum_{i=1}^m \mathcal{L}(\hat y^{(i)}, y^{(i)}) + \frac{\lambda}{2m} \| w \|_2^2
\]
其中,\(\lambda\) 是正则化参数。通常使用开发集来配置这个参数。\(L_2\) 正则化有时也被称作权重衰减。
正则化项 \(\| w \|_2^2\) 有时也写作 \(\| w \|_F^2\),称为 Frobenius 范数。
\(L_1\) 正则化
\[J(w, b) = \frac{1}{m} \sum_{i=1}^m \mathcal{L}(\hat y^{(i)}, y^{(i)}) + \frac{\lambda}{m} \| w \|_1
\]
使用 L1 正则化会导致 \(w\) 变得稀疏(包含很多 0)
Dropout
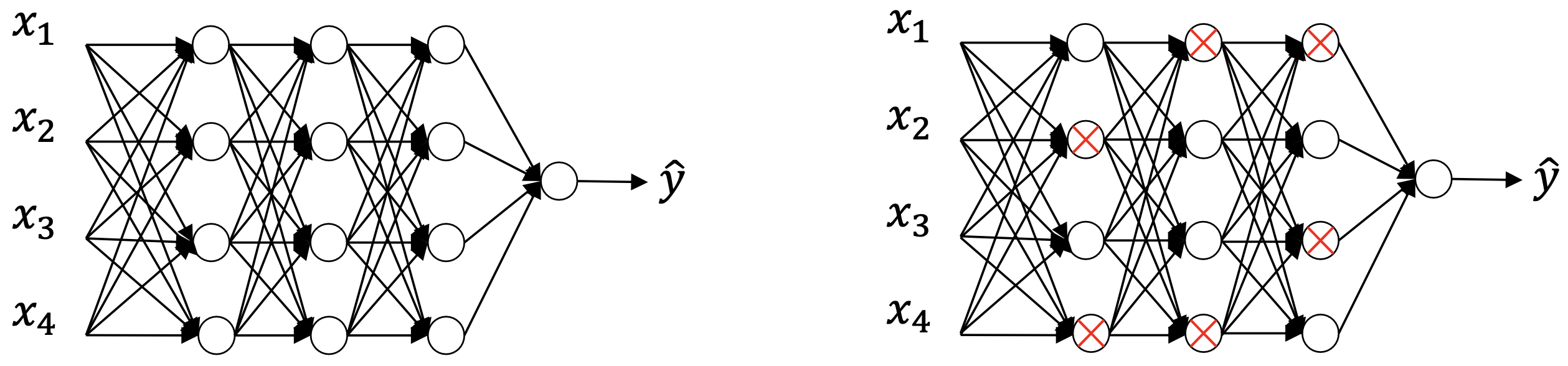
以一定概率将网络中的一部分神经元置零,从而避免下一层的某个神经元过于依赖上一层的某个神经元。这种正则化方法会使权重均匀地分散到每个神经元,其效果和 \(L_2\) 正则化类似。
参考:Dropout Regularization | Coursera
初始化权重
\[W^{[l]} = \texttt{np.random.randn(shape) * np.sqrt(}\frac{1}{n^{[l-1]}}\texttt{)}
\]
可以通过初始化合适的权重使神经网络不那么容易出现梯度爆炸和梯度消失的情况。
预处理数据集
如果数据集是图像,那么可以通过对图像进行旋转、缩放等处理来填充数据集,这样也能使模型不容易过拟合。这也可以看作一种正则化方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号