硬件加速器
NVIDIA
- CUDA 核心:通用计算
- Tensor 核心:AI 张量运算加速
- RT 核心:光线追踪专用加速
RTX PRO 6000
- 发布日期:2025 年 3 月 18 日
- 架构:NVIDIA Blackwell
- CUDA 核心:24,064
- Tensor 核心:752(第 5 代)
- RT 核心:188(第 4 代)
- 显存:96GB GDDR7,带宽 1,597 GB/s
- FP32 性能:117 TFLOPs
- FP16 性能:126 TFLOPs
- 多实例 GPU (MIG):最高 4 MIGs @ 24 GB
- 功耗:600W
- CUDA 计算能力:12.0
RTX PRO 6000 是单卡性能较强的 GPU,但它与其他数据中心 GPU 的区别在于只能使用 PCIe 进行多卡通信,通信带宽小很多。因此这款显卡适合单卡训练而不适合多卡训练。根据测试,在 BF16 精度 8 卡并行训练的情况下 RTX PRO 6000 的单卡算力与 A100 基本持平,但是多卡通信带宽只有 A100 的 1/18,导致最终吞吐量只有 A100 的 1/7。
NVIDIA H100 GPU
- 发布日期:2022 年 3 月 22 日
- 架构:Hopper
- CUDA 核心:16,896
- Tensor 核心:528
- 显存:80GB HBM3,带宽 3,352 GB/s
- FP32 性能:67 TFLOPs,989 TFLOPs(Tensor 核心)
- FP16 性能:1,979 TFLOPs(Tensor 核心)
- 多实例 GPU (MIG):最高 7 MIGs @ 10GB
- Transformer Engine:专门优化 Transformer 模型的性能,加速自然语言处理任务。
- 功耗:700W
- CUDA 计算能力:9.0
NVIDIA H20 GPU
- 发布日期:2022 年 3 月 22 日
- 架构:Hopper
- CUDA 核心:16,896
- Tensor 核心:528
- 显存:80GB HBM3,带宽 3,352 GB/s
- FP32 性能:67 TFLOPs,989 TFLOPs(Tensor 核心)
- FP16 性能:1,979 TFLOPs(Tensor 核心)
- 多实例 GPU (MIG):最高 7 MIGs @ 10GB
- Transformer Engine:专门优化 Transformer 模型的性能,加速自然语言处理任务。
- 功耗:700W
- CUDA 计算能力:9.0
NVIDIA A100 GPU
- 发布日期:2020 年 5 月 14 日
- 架构:Ampere
- 制程工艺:7nm
- CUDA 核心:6912
- Tensor 核心:432
- 显存:40GB 或 80GB HBM2e,带宽 1,935GB/s
- FP32 性能:19.5 TFLOPs
- TF32 性能:156 TFLOPs
- BP16 性能:312 TFLOPs(Tensor 核心)
- NVLink 带宽:600 GB/s(双向,使用 NVLink 3.0)
- 多实例 GPU (MIG):最高 7 MIGs @ 10GB
- 功耗:300-400W
- CUDA 计算能力:8.0
A800 是英伟达公司为了应对美国政府禁止向中国、俄罗斯销售 A100 和 H100 的禁令而定制的特殊版本。A800 性能和 A100 是相同的,只是功能上有些许差异。
NVIDIA A10 GPU
- 发布日期:2021 年 4 月 12 日。
- 显存:24GB GDDR6,带宽 600 GB/s
- FP32 性能:31.2 TFLOPs,62.5 TFLOPs(Tensor 核心)
- FP16 性能:125 TFLOPs(Tensor 核心)
- 功耗:150W
- CUDA 计算能力:8.6
NVIDIA L40 GPU
- 发布日期:2022 年 10 月 13 日
- 架构:Ada Lovelace
- 显存:48GB GDDR6,带宽 864 GB/s
- CUDA 核心:18,176
- Tensor 核心:568
- FP32 性能:90.5 TFLOPs
- FP16 性能:181.05 TFLOPs(Tensor 核心)
- 功耗:300W
- CUDA 计算能力:8.9
NVIDIA L4 GPU
- 发布日期:2023 年 3 月 21 日
- 架构:Ada Lovelace
- 显存:24GB GDDR6,带宽 300 GB/s
- FP32 性能:30.3 TFLOPs,120 TFLOPs(Tensor 核心,稀疏模式)
- FP16 性能:242 TFLOPs(Tensor 核心,稀疏模式)
- 功耗:72W
- CUDA 计算能力:8.9
NVIDIA T4 GPU
- 发布日期:2018 年 9 月 12 日
- 架构:Turing
- CUDA 核心:2,560
- Tensor 核心:320
- 显存:16GB GDDR6,带宽 320 GB/s
- FP32 性能:8.1 TFLOPs
- FP16/FP32 性能:65 TFLOPs
- 功耗:70W
- CUDA 计算能力:7.5
NVIDIA P100 GPU
- 发布日期:2016 年 4 月 5 日
- 架构:Pascal
- CUDA 核心:3584
- 显存:16GB HBM2,带宽 732 GB/s
- 峰值 FP32 性能:9.3 TFLOPs
- 峰值 FP16 性能:18.7 TFLOPs
- 功耗:250W
- CUDA 计算能力:6.0
参见:
- List of Nvidia graphics processing units | Wikipedia
- NVIDIA Datacenter GPUs | NVIDIA.com
- CUDA GPU Compute Capability | NVIDIA Developer
显卡算力排行榜(源自 Lambda.AI):
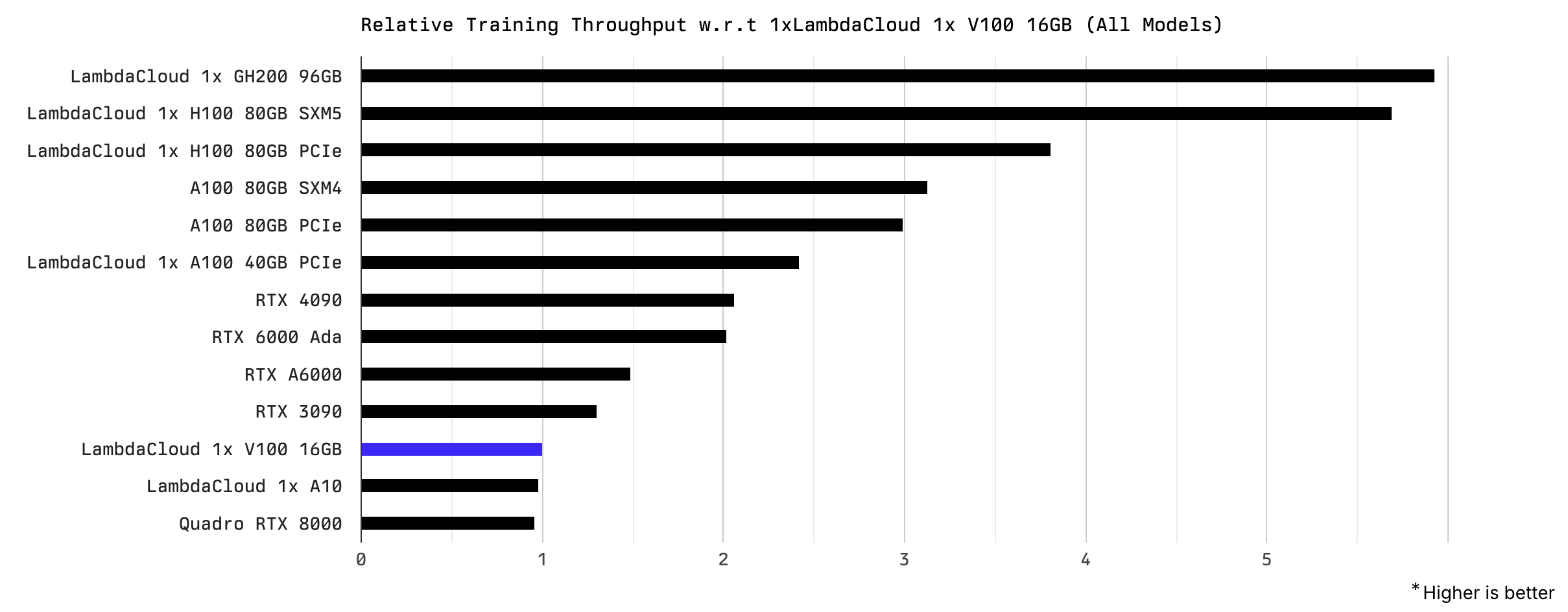
参见:Compare GPU Performance on AI Workloads | Runpod
Google TPU 是 Google 对自家 TensorFlow 框架优化的硬件加速器。
Google TPU v6e
- 发布日期:2024 年
- 内存:32GB,带宽 1640 GB/s
- BF16 性能:918 TFLOPs
Google TPU v5e
- 发布日期:2023 年
- 内存:16 GB HBM2,带宽 819 GB/s
- BF16 性能:197 TFLOPs
Google TPU v2
- 发布日期:2017 年
- 内存:16 GB HBM,带宽 600 GB/s
- FP32 性能:45 TFLOPs(8个芯片总计)
- BF16 性能:90 TFLOPs
- 功耗:280W
参见:
杂项
PCIe
PCIe 是通用的主板扩展总线标准,绝大多数服务器和工作站都支持。
- GPU 以标准显卡形式插在 PCIe 插槽,安装灵活,兼容性好。
- 带宽受 PCIe 代际限制,通常低于 NVLink。
- 数据中心级 GPU 可以通过安装 NVLink 桥接器以支持 NVLink。

SXM
SXM(Server PCI Express Module)是 NVIDIA 专为数据中心设计的 GPU 接口标准。
- GPU 模块直接焊接/永久安装在 HGX 基板上。
- 支持更高功耗和更强散热。
- 通常与 NVLink 高速互联配合,带宽远超 PCIe。

NVL(NVLink)
- NVIDIA 专有的 GPU 互联总线,支持多 GPU 之间的高速通信。
- 通过 NVLink Bridge 或主板集成,连接多块 GPU,实现更高带宽和更低延迟。
- SXM 模块通常原生支持 NVLink,PCIe 卡部分型号也支持。
- 适合需要多卡协同的 AI 训练、科学计算等场景。

HGX 是 NVIDIA 推出的 GPU 基板,载有 4 块或 8 块 SXM 接口 GPU。
参考:A100 HGX compared to A100 | Reddit
DGX 是 NVIDIA 推出的 GPU 服务器,通过 HGX 基板提供计算加速功能。
Introducing NVIDIA DGX A100 | YouTube

 浙公网安备 33010602011771号
浙公网安备 33010602011771号