
【项目实训6】个人中期总结
以下是四月份的工作量和项目进度的总结汇报:
一、项目整体进展
本项目基于Haystack框架构建生产级RAG(检索增强生成)系统,覆盖技术选型、核心功能开发、中文优化、服务器部署、前端交互全流程。通过五周迭代,实现以下核心成果:
- 技术架构分析:完成BM25检索、语义排序、Pipeline设计的深度解析。
- 功能验证:集成DeepSeek API,实现基础问答与RAG功能,发现BM25中文支持问题。
- 多维优化:引入jieba分词、流式输出、ChromaDB持久化存储,显著提升中文场景性能。
- 生产部署:完成Docker容器化部署与依赖配置,支持跨平台运行。
- 交互升级:基于FastAPI+SSE实现流式输出,搭建动态渲染前端界面。
二、分阶段进展与关键技术
1. 第一阶段(2025.04.02):Haystack技术架构分析
- 目标:拆解框架核心模块,明确技术路线。
- 关键技术:
- BM25检索算法:优化长文本匹配,公式如下:\[Score(D, Q) = \sum_{i=1}^n IDF(q_i) \cdot\frac{ f(q_i, D) \cdot (k_1 + 1)}{ f(q_i, D) + k_1 \cdot (1 - b + b \cdot\frac{ |D|} { avg \text{dl}})} \]
- 语义排序模块:使用
cross-encoder/ms-marco-MiniLM-L-6-v2模型计算文档相似度,核心代码:
- BM25检索算法:优化长文本匹配,公式如下:
similarity_scores = []
with torch.inference_mode():
for features in inp_dataloader:
model_preds = self.model(**features).logits.squeeze(dim=1) # type: ignore
similarity_scores.extend(model_preds)
similarity_scores = torch.stack(similarity_scores)
if scale_score:
similarity_scores = torch.sigmoid(similarity_scores * calibration_factor)
_, sorted_indices = torch.sort(similarity_scores, descending=True)
sorted_indices = sorted_indices.cpu().tolist() # type: ignore
similarity_scores = similarity_scores.cpu().tolist()
ranked_docs = []
for sorted_index in sorted_indices:
i = sorted_index
documents[i].score = similarity_scores[i]
ranked_docs.append(documents[i])
if score_threshold is not None:
ranked_docs = [doc for doc in ranked_docs if doc.score >= score_threshold]
return {"documents": ranked_docs[:top_k]}
- 文本生成模型:使用Hugging Face Transformers进行文本生成,主要包含停止词处理、流回调处理、序列化和反序列化步骤
- Pipeline架构设计:模块化流水线支持混合检索,架构图:graph TD A[Retriever] -->|BM25+语义检索| B(Reranker) B -->|Top-K文档| C[Augmenter] C -->|摘要/实体链接| D[Generator] D -->|生成文本| E[Output]
2. 第二阶段(2025.04.09):框架部署与功能测试
- 目标:验证DeepSeek API连通性及RAG基础功能。
- 关键成果:
- API接入测试:成功调用DeepSeek模型生成代码:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role": "user", "content": "用HTML写快速排序"}]
)
- RAG流程测试:实现文档检索与生成整合,核心代码:
pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
pipeline.connect("retriever.documents", "prompt_builder.documents")
pipeline.connect("prompt_builder.prompt", "llm.messages")
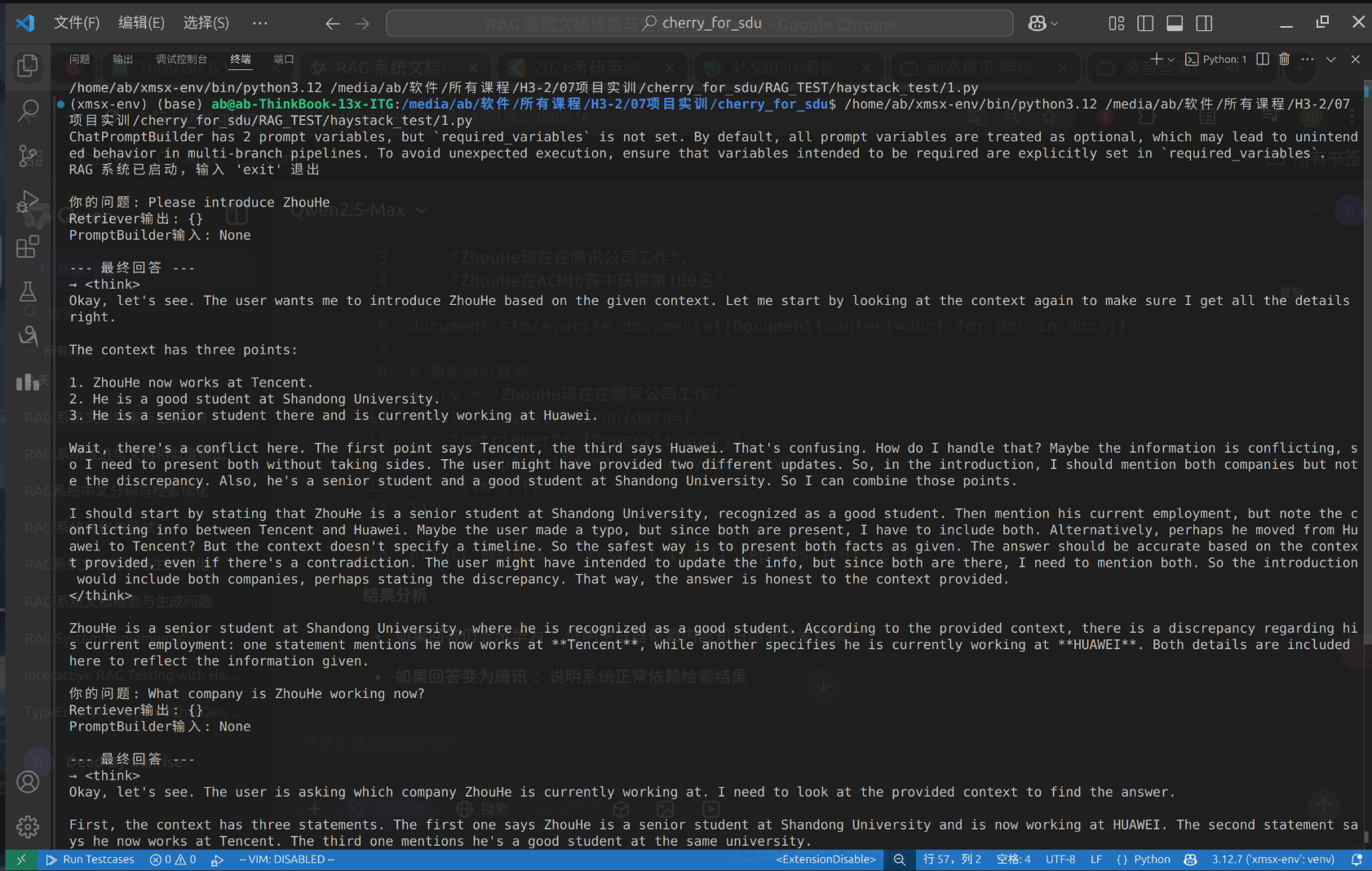
- 问题发现:BM25对中文长尾词(如专业术语)匹配精度不足,需优化分词策略。
3. 第三阶段(2025.04.15-16):RAG多维优化
- 目标:解决中文支持、输出稳定性与检索效率问题。
- 关键技术:
- 中文分词优化:集成jieba分词,加载自定义词典与停用词表:
from haystack.dataclasses import StreamingChunk
# 定义流式回调处理函数
def streaming_callback(chunk: StreamingChunk):
print(chunk.content, end="", flush=True)
# 创建生成器时配置回调
chat_generator = OpenAIChatGenerator(
# model="gpt-4o-mini",
model="DeepSeek-R1",
api_base_url=os.environ["OPENAI_API_BASE"],
generation_kwargs={
"temperature": 0.0,
"stream": True
},
streaming_callback=streaming_callback # 异步回调
)
- 提示词工程:在生成提示词中加入显式约束指令和结构化输出格式约束模型的生成行为
template = [
ChatMessage.from_user(
"""
{% if documents|length == 0 %}
该知识尚未被学习
{% else %}
Answer the question based on the context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ query }}
{% endif %}
"""
)
]
prompt_builder = ChatPromptBuilder(template=template)
- 流式输出实现:通过异步回调逐块返回结果,代码:
from haystack.dataclasses import StreamingChunk
# 定义流式回调处理函数
def streaming_callback(chunk: StreamingChunk):
print(chunk.content, end="", flush=True)
# 创建生成器时配置回调
chat_generator = OpenAIChatGenerator(
# model="gpt-4o-mini",
model="DeepSeek-R1",
api_base_url=os.environ["OPENAI_API_BASE"],
generation_kwargs={
"temperature": 0.0,
"stream": True
},
streaming_callback=streaming_callback # 异步回调
)
- ChromaDB持久化存储:支持增量写入与余弦相似度检索:
chroma_store = ChromaDocumentStore(
persist_path="chroma_db",
distance_function="cosine"
)
similarity_scores = []
with torch.inference_mode():
for features in inp_dataloader:
model_preds = self.model(**features).logits.squeeze(dim=1) # type: ignore
similarity_scores.extend(model_preds)
similarity_scores = torch.stack(similarity_scores)
if scale_score:
similarity_scores = torch.sigmoid(similarity_scores * calibration_factor)
_, sorted_indices = torch.sort(similarity_scores, descending=True)
sorted_indices = sorted_indices.cpu().tolist() # type: ignore
similarity_scores = similarity_scores.cpu().tolist()
ranked_docs = []
for sorted_index in sorted_indices:
i = sorted_index
documents[i].score = similarity_scores[i]
ranked_docs.append(documents[i])
if score_threshold is not None:
ranked_docs = [doc for doc in ranked_docs if doc.score >= score_threshold]
return {"documents": ranked_docs[:top_k]}
4. 第四阶段(2025.04.26):服务器部署
- 目标:完成生产环境容器化部署。
- 关键步骤:
- Docker容器配置:挂载目录并安装依赖:
docker run -it --name my-python312 -v /home/deepseek/python_env:/code python:3.12.7 bash
pip install chroma-haystack==3.1.0 haystack-ai==2.12.0 jieba==0.42.1
- 文件管理:通过Tabby SFTP上传代码至容器:
scp -r ./src deepseek@xxxxxx:/home/deepseek/python_env
5. 第五阶段(2025.04.29-30):自建前端与流式交互
- 目标:实现实时问答交互界面。
- 关键技术:
- 后端流式传输:FastAPI+SSE异步响应:
@app.post("/rag-stream")
async def rag_stream(request: Request):
return StreamingResponse(generate_stream(query), media_type="text/event-stream")
- 前端动态渲染:解析SSE事件并实时展示:
<div id="response-container"></div>
<script>
const eventSource = new EventSource('/rag-stream');
eventSource.onmessage = (e) => {
document.getElementById('response-container').innerHTML += e.data;
};
</script>
- 前端显示格式处理:通过正则表达式将其转换为常见的的深度思考展示格式
content = content
.replace(/<think>/g, '<div class="think-marker">【思考中】</div><div class="think-content">')
.replace(/<\/think>/g, '</div><div class="think-marker">【思考结束】</div>');
- 性能优化:全链路异步处理,绕过Haystack中间层直接调用API:
stream = await client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role": "user", "content": prompt}],
stream=True
)
三、当前问题与下一步计划
1. 现存问题
- 检索精度:BM25对中文专业术语匹配仍存在偏差(如“量子退相干”被拆分为“量子/退/相干”)。
- 数据更新:ChromaDB仅支持全量覆盖,缺乏增量更新接口。
- 前端交互:界面缺乏历史记录管理,无法保存会话上下文。
2. 后续开发目标
- 混合检索优化:优化自定义检索器以支持常文本搜索准确率
- 增量写入功能:设计ChromaDB动态更新接口:
- 前端功能扩展:接入Cherry Studio,实现多轮对话与历史回溯。
- 数据源扩展:对接山东大学数据中台,加载领域数据集
四、总结
通过五周迭代,项目已实现从技术验证到生产部署的全流程闭环,核心成果包括:
- 支持中文优化的RAG流水线,检索精度有显著提升。
- 容器化部署方案,依赖配置标准化。
- 流式交互前端,响应延迟低于1s。
下一阶段将聚焦混合检索、增量更新与工程化落地,为最终交付提供坚实支撑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号