



CS:APP--Chapter05 : optimizing program performance (part 2)
8. loop uprolling
Without further ado, one sentence concludes what it is :
Loop uprolling reduces the number of overall iterations by increasing the number of elements computed on each iteration.


The result of gauging its performance reveals that it is closer to the latency bounds. One thing highlighted here is also latency bounds because the number of iterations also is n, But the idea of parallelism just hits these bounds.
9. enhancing parallelism
The modern processor allows multiple operations of the same type to be executed simultaneously, denoted by capacity.
what we are going to do is break the data dependency and get performance better than the latency bounds.
9.1 multiple accumulators
In the I7 core processor, it provides two function units for float multiplication. We can take full advantage of them to execute two float multiplication simultaneously.


One knowledge point emphasized here: float arithmetic operation corresponds to associative and communitive law.
9.2 reassociation transformation
what a beauty it is! 我直呼好家伙!

just a subtle change by shifting parenthesis order makes a fundamental difference at the assembly language level.
multiple accumulators just break data dependency between the successive value of acc(multiply in parallel), but reassociation transformation also changes the data dependency between the value pointed by pointer i here(read data from memory in parallel).
10. some limit factors
the previous factors are relevant to exploit the processor to its full extent, But there are some factors limiting performance depending on the actual machine where the number of functional units is more than our reference machine.
10.1 registers spilling
The parallelism of several operations of the same type always is limited by the number of registers.
What if the number of registers is less than the processor provides?
register spilling
=> just put some temporary values into memory, especially in the allocated run-time stack.
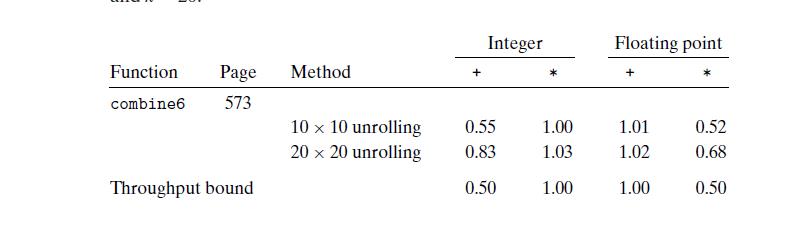
An interesting phenomenon arises, the latency value increases at last.
10.2 branch prediction and misprediction penalties
Other than the prediction taken by the branch prediction unit, any value computed before will be flushed when the prediction is wrong. There is a bit of delay followed by instruction fetch by a new address.
This delay is just the limiting source to slow down the whole performance. Because of the huge difficulty of this topic, we understand the following principle :
- do not be overly concerned about predictable branches
- write code suitable for implementation with conditional moves
11 understanding memory performance
I will be back here after chapter 6.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号