1. BERT
1. 什么是BERT?
丢一段句子进去,然后BERT处理一个一个token到一个一个embedding
“词”跟“字”的差别,就如“潮水”和“潮”,“水”的差别,因此中文bert更多的用的是字,而不是词,因为中文的词无法穷举
结构是多个transformer encoder部分的堆叠
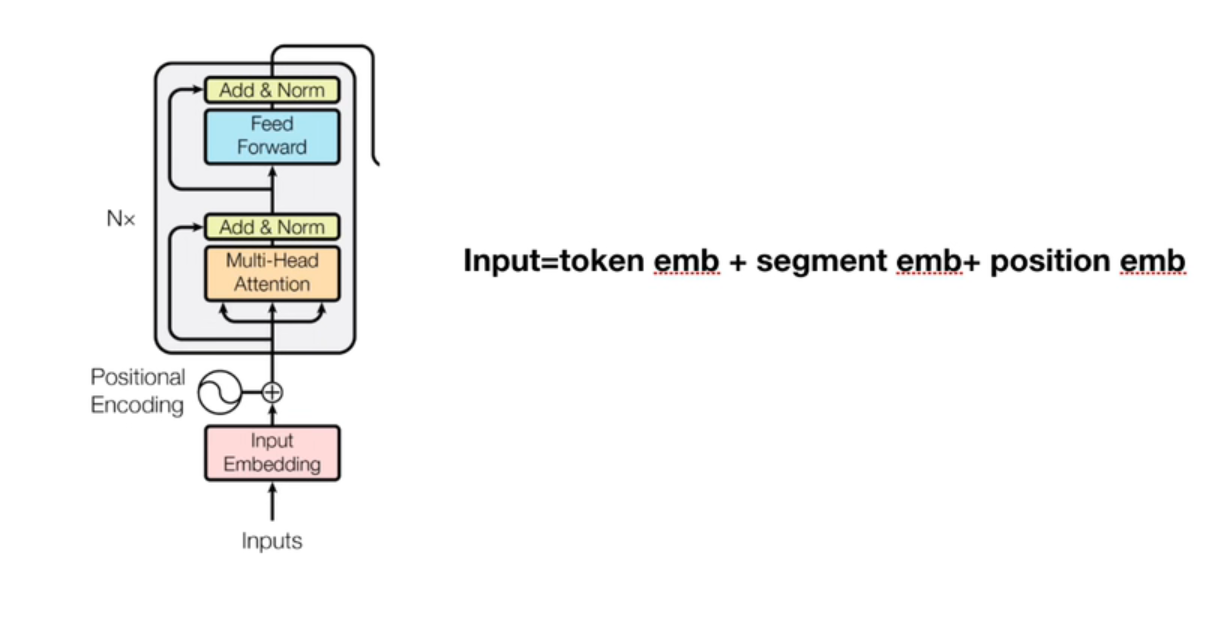
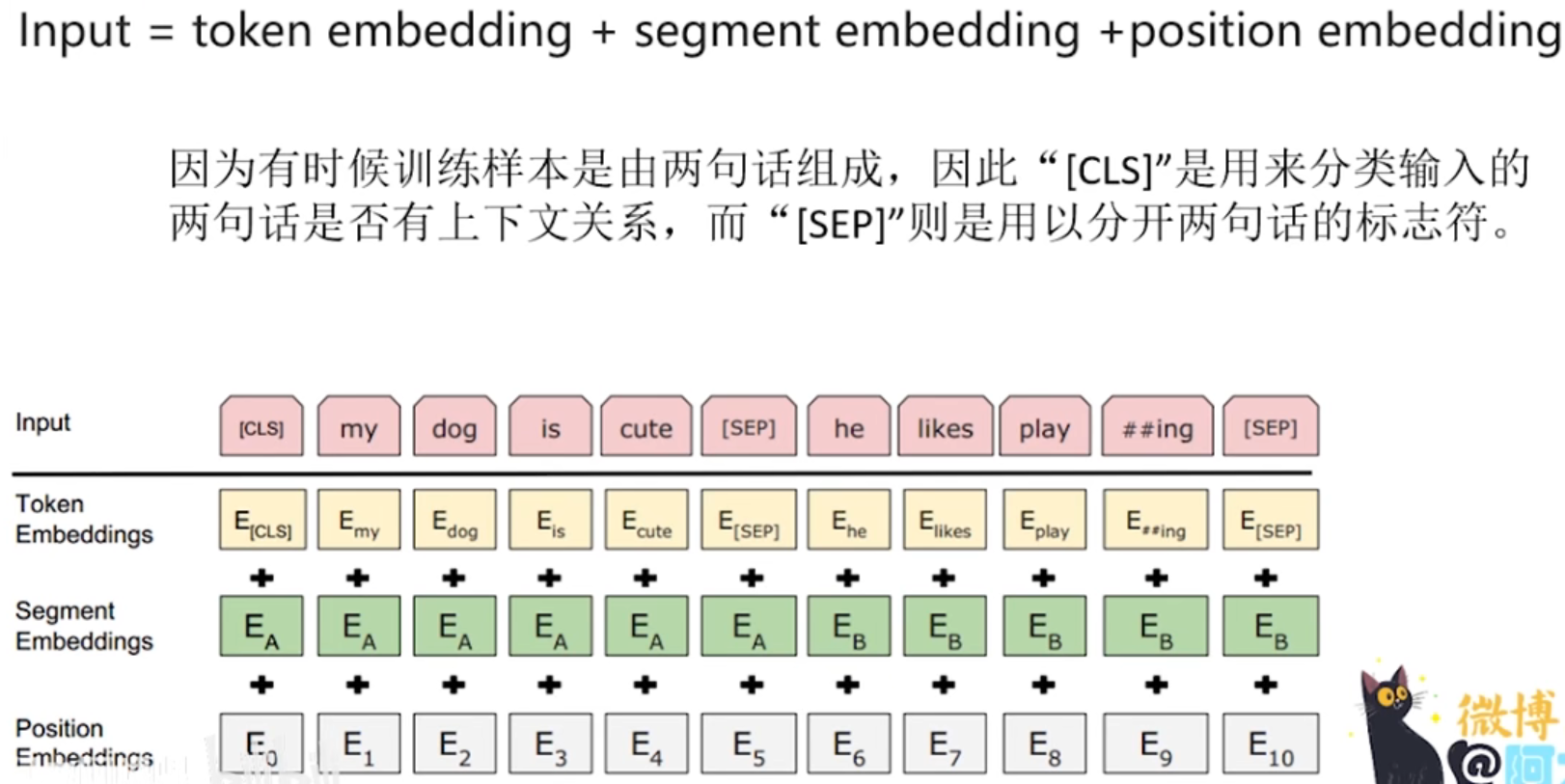
因为这里的input是英文单词,所以在灌入模型之前,需要用bert源码tokenization工具对每一个单词进行分词,分词后的形式:"Palying"转换为"Play"+"##ing",因为英文词汇表是通过词根与词缀的组合来新增单词语义的,所以选择采用分词方法可以减少整体的词汇表长度
模型是无法处理文本字符的,所以不管是英文还是中文,都需要通过预训练BERT自带的字典vocab.txt将每一个字或者单词转换为字典索引(即id)输入
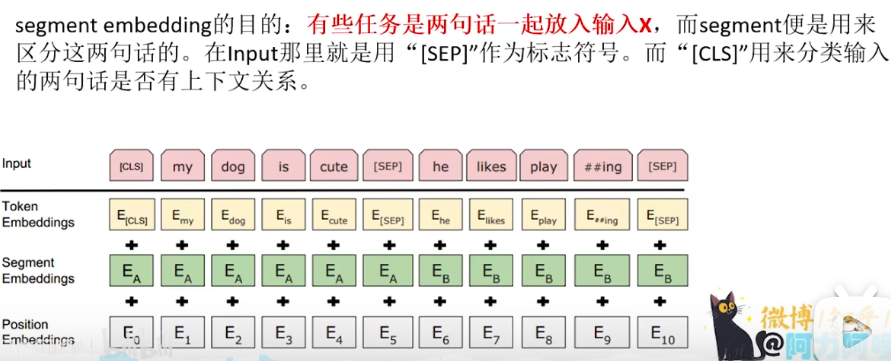
position embedding的目的:因为我们的网络结构没有RNN或者LSTM,因此无法得到序列的位置信息,所以需要构建一个position embedding

2. 训练BERT
序列长度一般有512或者1024,不足用
2.1 MLM(masked language model)
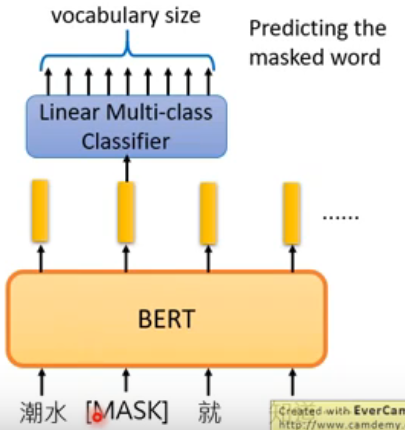
input中随机有15%的词汇会被置换为[MASK],让BERT去填空,如果两个词汇填在同一个地方没有违和感,那他们就有类似的embedding,对于输入的X,15%的字或者英文单词采用随机掩盖策略,对于这15%的字或者英文单词,10%概率替换序列中的某个字或者英文单词,10%的概率不做任何变换
BERT自带字典vocab.txt的每一个字或者单词都被768维度的embedding所表示
pre-train,两种训练同时进行
(1). 预测被掩盖的字或者英文单词(MaskLM)
(2). 预测两句话之间是否有顺序关系(NSP)
fine-tune
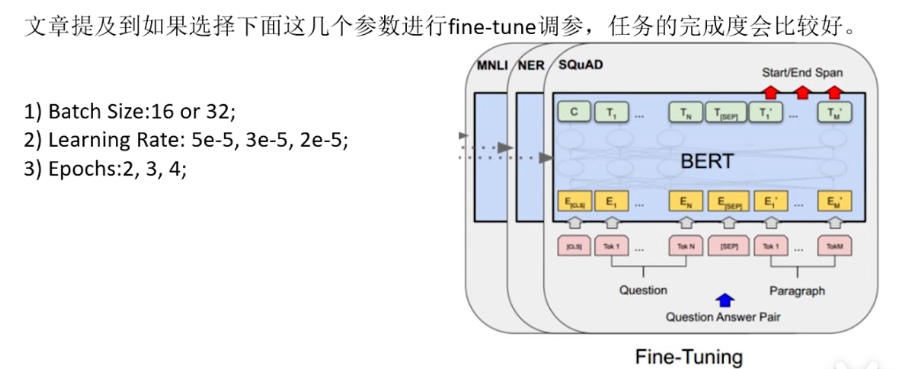
2.2 NSP(next sentence prediction)
给两个句子,让bert预测这两个句子是接在一起的,还是不是接在一起的
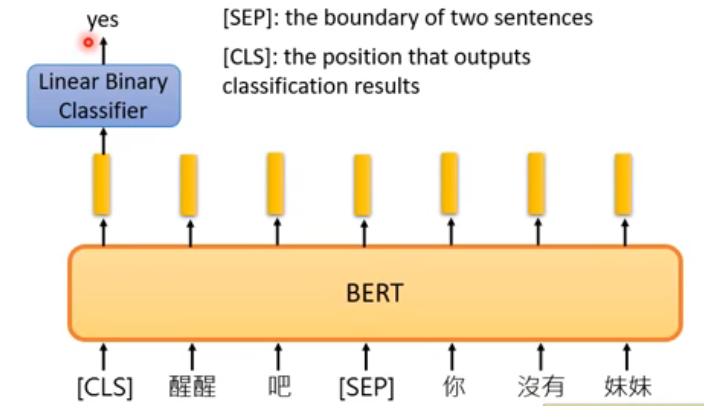
其中[CLS]放在句子开头还是句子其他位置,因为bert内部是self-attention,对于自注意力机制来说,如果不考虑position-encoding带来的影响的话,两个距离近和距离远,是没有差别的
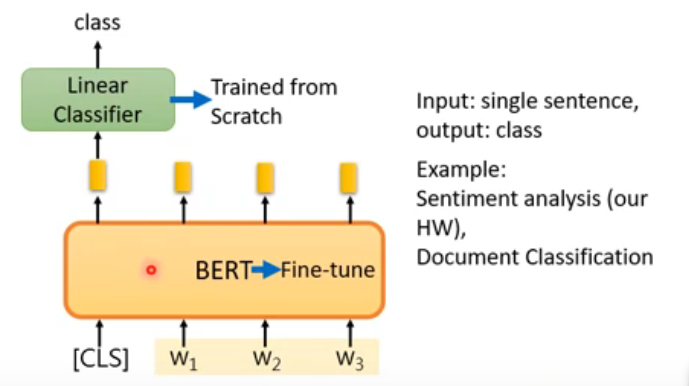
2.3 情感分析
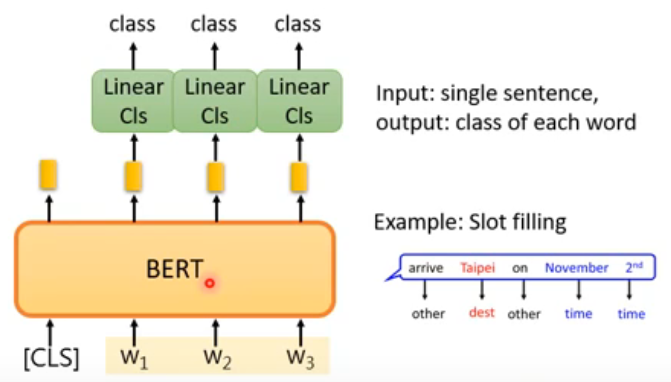
2.4 class of each word
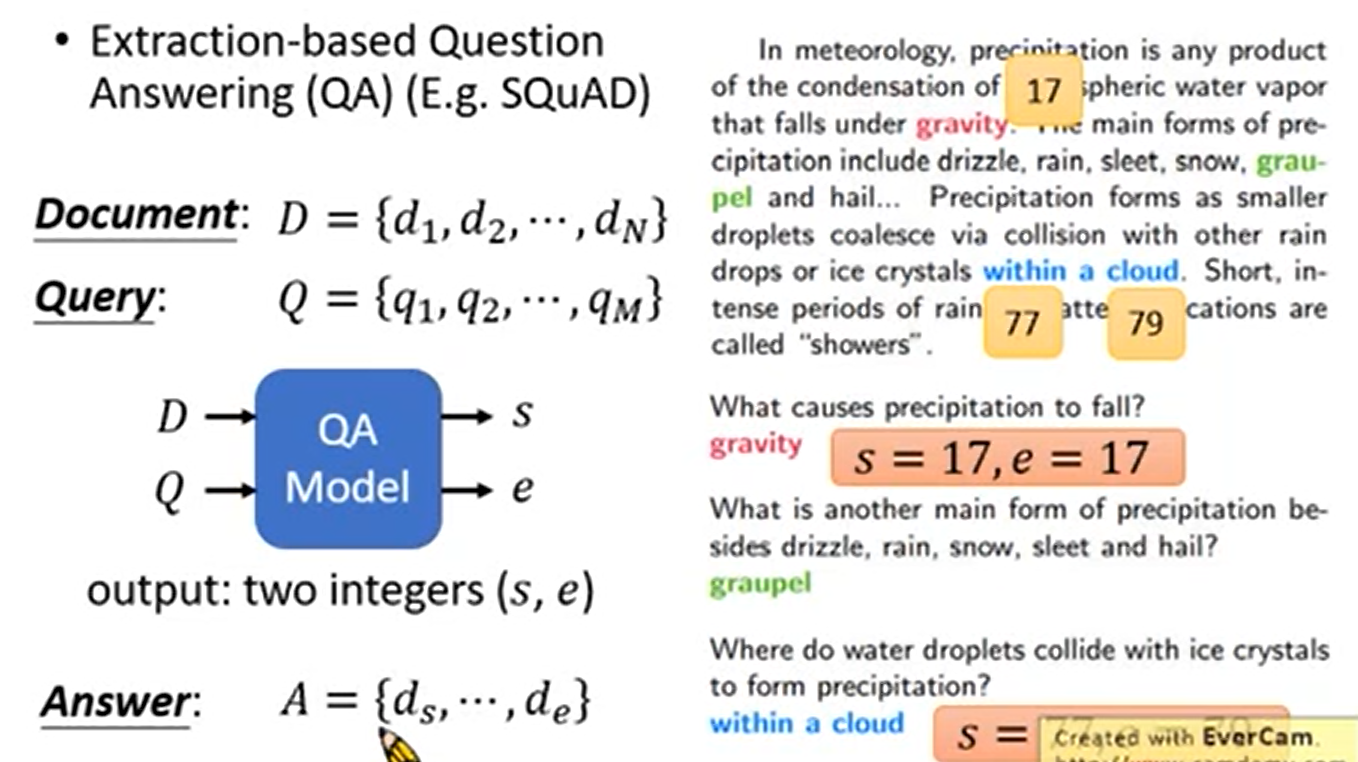
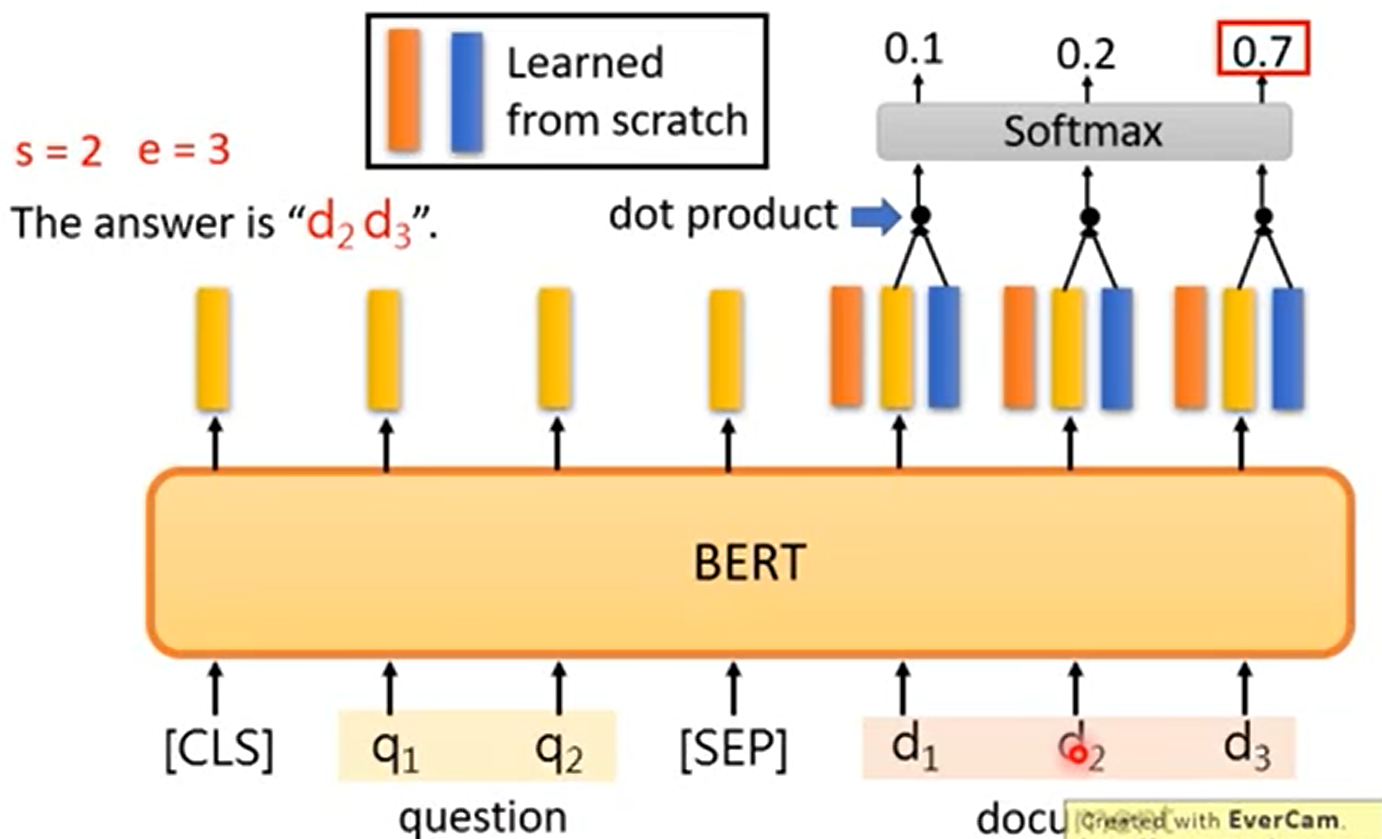
2.5 Extraction-based Question Answering(基于抽取,也就是答案一定在原文中)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号